 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Alignment Improves Graph Test-Time Adaptation
Feb 25, 2025Graph-based learning has achieved remarkable success in domains ranging from recommendation to fraud detection and particle physics by effectively capturing underlying interaction patterns. However, it often struggles to generalize when distribution shifts occur, particularly those involving changes in network connectivity or interaction patterns. Existing approaches designed to mitigate such shifts typically require retraining with full access to source data, rendering them infeasible under strict computational or privacy constraints. To address this limitation, we propose a test-time structural alignment (TSA) algorithm for Graph Test-Time Adaptation (GTTA), a novel method that aligns graph structures during inference without revisiting the source domain. Built upon a theoretically grounded treatment of graph data distribution shifts, TSA integrates three key strategies: an uncertainty-aware neighborhood weighting that accommodates structure shifts, an adaptive balancing of self-node and neighborhood-aggregated representations driven by node representations' signal-to-noise ratio, and a decision boundary refinement that corrects remaining label and feature shifts. Extensive experiments on synthetic and real-world datasets demonstrate that TSA can consistently outperform both non-graph TTA methods and state-of-the-art GTTA baselines.
VLAS: Vision-Language-Action Model With Speech Instructions For Customized Robot Manipulation
Feb 19, 2025Vision-language-action models (VLAs) have become increasingly popular in robot manipulation for their end-to-end design and remarkable performance. However, existing VLAs rely heavily on vision-language models (VLMs) that only support text-based instructions, neglecting the more natural speech modality for human-robot interaction. Traditional speech integration methods usually involves a separate speech recognition system, which complicates the model and introduces error propagation. Moreover, the transcription procedure would lose non-semantic information in the raw speech, such as voiceprint, which may be crucial for robots to successfully complete customized tasks. To overcome above challenges, we propose VLAS, a novel end-to-end VLA that integrates speech recognition directly into the robot policy model. VLAS allows the robot to understand spoken commands through inner speech-text alignment and produces corresponding actions to fulfill the task. We also present two new datasets, SQA and CSI, to support a three-stage tuning process for speech instructions, which empowers VLAS with the ability of multimodal interaction across text, image, speech, and robot actions. Taking a step further, a voice retrieval-augmented generation (RAG) paradigm is designed to enable our model to effectively handle tasks that require individual-specific knowledge. Our extensive experiments show that VLAS can effectively accomplish robot manipulation tasks with diverse speech commands, offering a seamless and customized interaction experience.
Efficient Model Editing with Task Vector Bases: A Theoretical Framework and Scalable Approach
Feb 03, 2025



Task vectors, which are derived from the difference between pre-trained and fine-tuned model weights, enable flexible task adaptation and model merging through arithmetic operations such as addition and negation. However, existing approaches often rely on heuristics with limited theoretical support, often leading to performance gaps comparing to direct task fine tuning. Meanwhile, although it is easy to manipulate saved task vectors with arithmetic for different purposes, such compositional flexibility demands high memory usage, especially when dealing with a huge number of tasks, limiting scalability. This work addresses these issues with a theoretically grounded framework that explains task vector arithmetic and introduces the task vector bases framework. Building upon existing task arithmetic literature, our method significantly reduces the memory cost for downstream arithmetic with little effort, while achieving competitive performance and maintaining compositional advantage, providing a practical solution for large-scale task arithmetic.
Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond
Jan 19, 2025



Multi-objective optimization (MOO) in deep learning aims to simultaneously optimize multiple conflicting objectives, a challenge frequently encountered in areas like multi-task learning and multi-criteria learning. Recent advancements in gradient-based MOO methods have enabled the discovery of diverse types of solutions, ranging from a single balanced solution to finite or even infinite Pareto sets, tailored to user needs. These developments have broad applications across domains such as reinforcement learning, computer vision, recommendation systems, and large language models. This survey provides the first comprehensive review of gradient-based MOO in deep learning, covering algorithms, theories, and practical applications. By unifying various approaches and identifying critical challenges, it serves as a foundational resource for driving innovation in this evolving field. A comprehensive list of MOO algorithms in deep learning is available at \url{https://github.com/Baijiong-Lin/Awesome-Multi-Objective-Deep-Learning}.
Neural Probabilistic Circuits: Enabling Compositional and Interpretable Predictions through Logical Reasoning
Jan 13, 2025



End-to-end deep neural networks have achieved remarkable success across various domains but are often criticized for their lack of interpretability. While post hoc explanation methods attempt to address this issue, they often fail to accurately represent these black-box models, resulting in misleading or incomplete explanations. To overcome these challenges, we propose an inherently transparent model architecture called Neural Probabilistic Circuits (NPCs), which enable compositional and interpretable predictions through logical reasoning. In particular, an NPC consists of two modules: an attribute recognition model, which predicts probabilities for various attributes, and a task predictor built on a probabilistic circuit, which enables logical reasoning over recognized attributes to make class predictions. To train NPCs, we introduce a three-stage training algorithm comprising attribute recognition, circuit construction, and joint optimization. Moreover, we theoretically demonstrate that an NPC's error is upper-bounded by a linear combination of the errors from its modules. To further demonstrate the interpretability of NPC, we provide both the most probable explanations and the counterfactual explanations. Empirical results on four benchmark datasets show that NPCs strike a balance between interpretability and performance, achieving results competitive even with those of end-to-end black-box models while providing enhanced interpretability.
QUART-Online: Latency-Free Large Multimodal Language Model for Quadruped Robot Learning
Dec 23, 2024



This paper addresses the inherent inference latency challenges associated with deploying multimodal large language models (MLLM) in quadruped vision-language-action (QUAR-VLA) tasks. Our investigation reveals that conventional parameter reduction techniques ultimately impair the performance of the language foundation model during the action instruction tuning phase, making them unsuitable for this purpose. We introduce a novel latency-free quadruped MLLM model, dubbed QUART-Online, designed to enhance inference efficiency without degrading the performance of the language foundation model. By incorporating Action Chunk Discretization (ACD), we compress the original action representation space, mapping continuous action values onto a smaller set of discrete representative vectors while preserving critical information. Subsequently, we fine-tune the MLLM to integrate vision, language, and compressed actions into a unified semantic space. Experimental results demonstrate that QUART-Online operates in tandem with the existing MLLM system, achieving real-time inference in sync with the underlying controller frequency, significantly boosting the success rate across various tasks by 65%. Our project page is https://quart-online.github.io.
Towards Understanding the Role of Sharpness-Aware Minimization Algorithms for Out-of-Distribution Generalization
Dec 06, 2024Recently, sharpness-aware minimization (SAM) has emerged as a promising method to improve generalization by minimizing sharpness, which is known to correlate well with generalization ability. Since the original proposal of SAM, many variants of SAM have been proposed to improve its accuracy and efficiency, but comparisons have mainly been restricted to the i.i.d. setting. In this paper we study SAM for out-of-distribution (OOD) generalization. First, we perform a comprehensive comparison of eight SAM variants on zero-shot OOD generalization, finding that the original SAM outperforms the Adam baseline by $4.76\%$ and the strongest SAM variants outperform the Adam baseline by $8.01\%$ on average. We then provide an OOD generalization bound in terms of sharpness for this setting. Next, we extend our study of SAM to the related setting of gradual domain adaptation (GDA), another form of OOD generalization where intermediate domains are constructed between the source and target domains, and iterative self-training is done on intermediate domains, to improve the overall target domain error. In this setting, our experimental results demonstrate that the original SAM outperforms the baseline of Adam on each of the experimental datasets by $0.82\%$ on average and the strongest SAM variants outperform Adam by $1.52\%$ on average. We then provide a generalization bound for SAM in the GDA setting. Asymptotically, this generalization bound is no better than the one for self-training in the literature of GDA. This highlights a further disconnection between the theoretical justification for SAM versus its empirical performance, with recent work finding that low sharpness alone does not account for all of SAM's generalization benefits. For future work, we provide several potential avenues for obtaining a tighter analysis for SAM in the OOD setting.
Learning Structured Representations with Hyperbolic Embeddings
Dec 02, 2024



Most real-world datasets consist of a natural hierarchy between classes or an inherent label structure that is either already available or can be constructed cheaply. However, most existing representation learning methods ignore this hierarchy, treating labels as permutation invariant. Recent work [Zeng et al., 2022] proposes using this structured information explicitly, but the use of Euclidean distance may distort the underlying semantic context [Chen et al., 2013]. In this work, motivated by the advantage of hyperbolic spaces in modeling hierarchical relationships, we propose a novel approach HypStructure: a Hyperbolic Structured regularization approach to accurately embed the label hierarchy into the learned representations. HypStructure is a simple-yet-effective regularizer that consists of a hyperbolic tree-based representation loss along with a centering loss, and can be combined with any standard task loss to learn hierarchy-informed features. Extensive experiments on several large-scale vision benchmarks demonstrate the efficacy of HypStructure in reducing distortion and boosting generalization performance especially under low dimensional scenarios. For a better understanding of structured representation, we perform eigenvalue analysis that links the representation geometry to improved Out-of-Distribution (OOD) detection performance seen empirically. The code is available at \url{https://github.com/uiuctml/HypStructure}.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024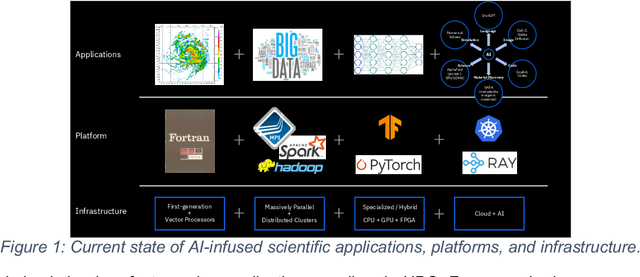
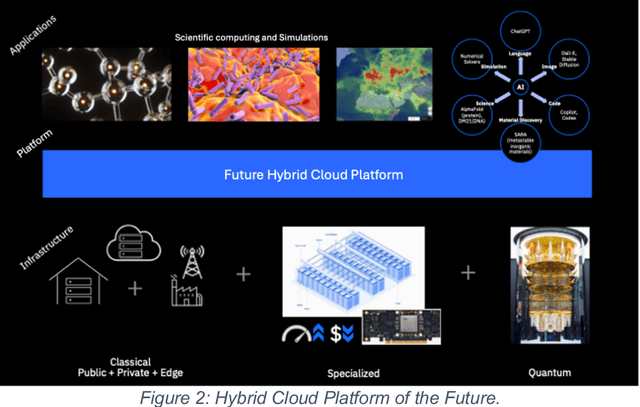
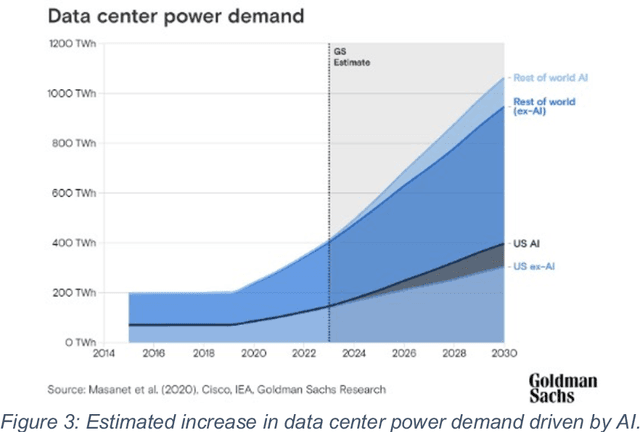
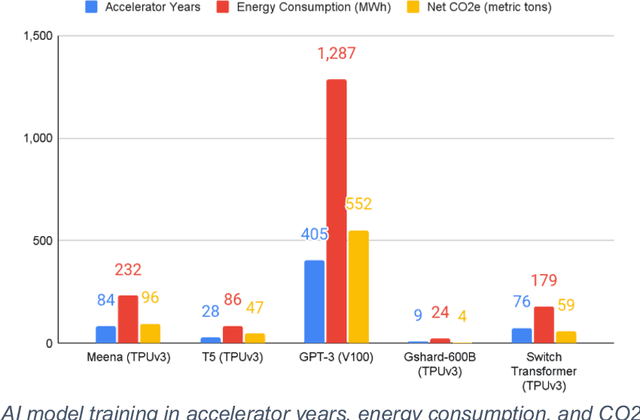
This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
Online Mirror Descent for Tchebycheff Scalarization in Multi-Objective Optimization
Oct 29, 2024The goal of multi-objective optimization (MOO) is to learn under multiple, potentially conflicting, objectives. One widely used technique to tackle MOO is through linear scalarization, where one fixed preference vector is used to combine the objectives into a single scalar value for optimization. However, recent work (Hu et al., 2024) has shown linear scalarization often fails to capture the non-convex regions of the Pareto Front, failing to recover the complete set of Pareto optimal solutions. In light of the above limitations, this paper focuses on Tchebycheff scalarization that optimizes for the worst-case objective. In particular, we propose an online mirror descent algorithm for Tchebycheff scalarization, which we call OMD-TCH. We show that OMD-TCH enjoys a convergence rate of $O(\sqrt{\log m/T})$ where $m$ is the number of objectives and $T$ is the number of iteration rounds. We also propose a novel adaptive online-to-batch conversion scheme that significantly improves the practical performance of OMD-TCH while maintaining the same convergence guarantees. We demonstrate the effectiveness of OMD-TCH and the adaptive conversion scheme on both synthetic problems and federated learning tasks under fairness constraints, showing state-of-the-art performance.