 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunAudio-ASR Technical Report
Sep 15, 2025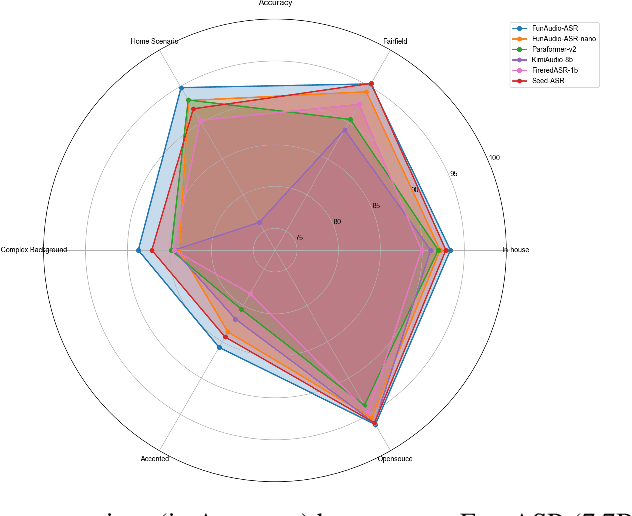
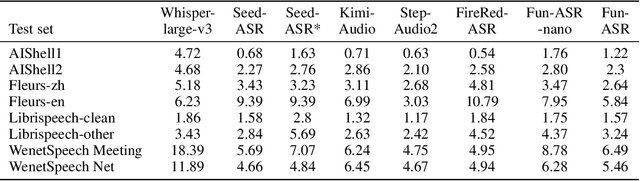
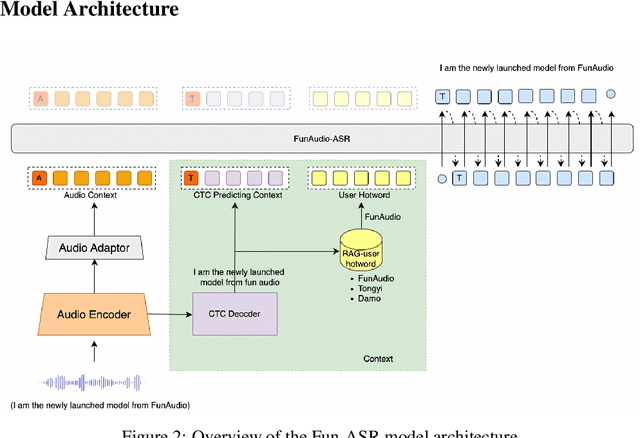
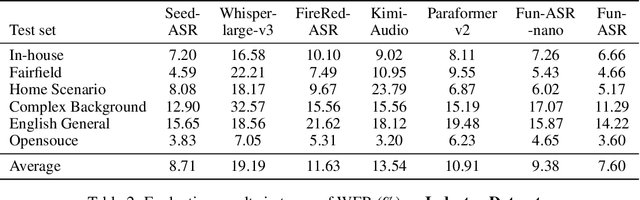
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
Sep 11, 2025Vision-Language-Action (VLA) models typically bridge the gap between perceptual and action spaces by pre-training a large-scale Vision-Language Model (VLM) on robotic data. While this approach greatly enhances performance, it also incurs significant training costs. In this paper, we investigate how to effectively bridge vision-language (VL) representations to action (A). We introduce VLA-Adapter, a novel paradigm designed to reduce the reliance of VLA models on large-scale VLMs and extensive pre-training. To this end, we first systematically analyze the effectiveness of various VL conditions and present key findings on which conditions are essential for bridging perception and action spaces. Based on these insights, we propose a lightweight Policy module with Bridge Attention, which autonomously injects the optimal condition into the action space. In this way, our method achieves high performance using only a 0.5B-parameter backbone, without any robotic data pre-training. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that VLA-Adapter not only achieves state-of-the-art level performance, but also offers the fast inference speed reported to date. Furthermore, thanks to the proposed advanced bridging paradigm, VLA-Adapter enables the training of a powerful VLA model in just 8 hours on a single consumer-grade GPU, greatly lowering the barrier to deploying the VLA model. Project page: https://vla-adapter.github.io/.
Boosting Embodied AI Agents through Perception-Generation Disaggregation and Asynchronous Pipeline Execution
Sep 11, 2025Embodied AI systems operate in dynamic environments, requiring seamless integration of perception and generation modules to process high-frequency input and output demands. Traditional sequential computation patterns, while effective in ensuring accuracy, face significant limitations in achieving the necessary "thinking" frequency for real-world applications. In this work, we present Auras, an algorithm-system co-designed inference framework to optimize the inference frequency of embodied AI agents. Auras disaggregates the perception and generation and provides controlled pipeline parallelism for them to achieve high and stable throughput. Faced with the data staleness problem that appears when the parallelism is increased, Auras establishes a public context for perception and generation to share, thereby promising the accuracy of embodied agents. Experimental results show that Auras improves throughput by 2.54x on average while achieving 102.7% of the original accuracy, demonstrating its efficacy in overcoming the constraints of sequential computation and providing high throughput.
Omne-R1: Learning to Reason with Memory for Multi-hop Question Answering
Aug 24, 2025This paper introduces Omne-R1, a novel approach designed to enhance multi-hop question answering capabilities on schema-free knowledge graphs by integrating advanced reasoning models. Our method employs a multi-stage training workflow, including two reinforcement learning phases and one supervised fine-tuning phase. We address the challenge of limited suitable knowledge graphs and QA data by constructing domain-independent knowledge graphs and auto-generating QA pairs. Experimental results show significant improvements in answering multi-hop questions, with notable performance gains on more complex 3+ hop questions. Our proposed training framework demonstrates strong generalization abilities across diverse knowledge domains.
ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver
Aug 14, 2025Recent advances in Vision-Language-Action (VLA) models have enabled robotic agents to integrate multimodal understanding with action execution. However, our empirical analysis reveals that current VLAs struggle to allocate visual attention to target regions. Instead, visual attention is always dispersed. To guide the visual attention grounding on the correct target, we propose ReconVLA, a reconstructive VLA model with an implicit grounding paradigm. Conditioned on the model's visual outputs, a diffusion transformer aims to reconstruct the gaze region of the image, which corresponds to the target manipulated objects. This process prompts the VLA model to learn fine-grained representations and accurately allocate visual attention, thus effectively leveraging task-specific visual information and conducting precise manipulation. Moreover, we curate a large-scale pretraining dataset comprising over 100k trajectories and 2 million data samples from open-source robotic datasets, further boosting the model's generalization in visual reconstruction. Extensive experiments in simulation and the real world demonstrate the superiority of our implicit grounding method, showcasing its capabilities of precise manipulation and generalization. Our project page is https://zionchow.github.io/ReconVLA/.
CEED-VLA: Consistency Vision-Language-Action Model with Early-Exit Decoding
Jun 16, 2025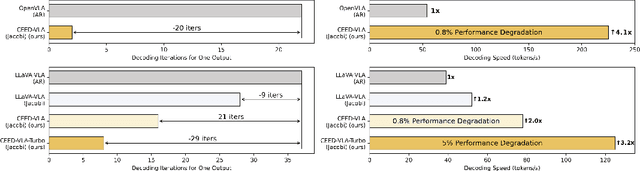

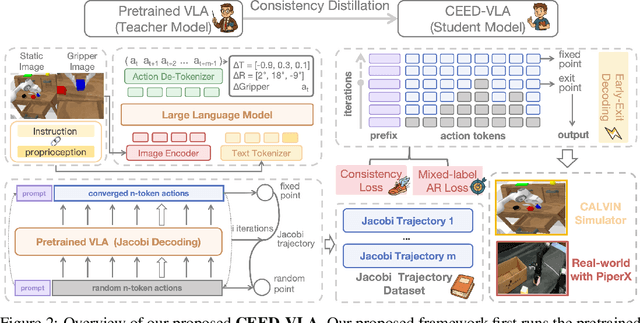
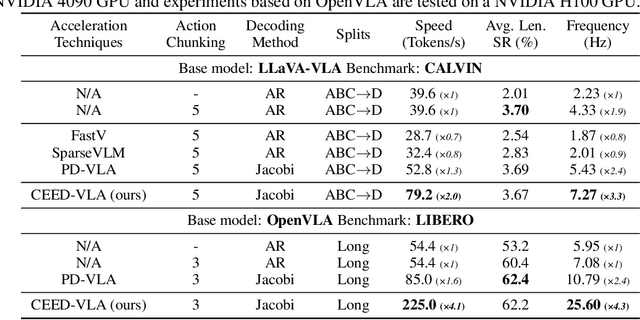
In recent years, Vision-Language-Action (VLA) models have become a vital research direction in robotics due to their impressive multimodal understanding and generalization capabilities. Despite the progress, their practical deployment is severely constrained by inference speed bottlenecks, particularly in high-frequency and dexterous manipulation tasks. While recent studies have explored Jacobi decoding as a more efficient alternative to traditional autoregressive decoding, its practical benefits are marginal due to the lengthy iterations. To address it, we introduce consistency distillation training to predict multiple correct action tokens in each iteration, thereby achieving acceleration. Besides, we design mixed-label supervision to mitigate the error accumulation during distillation. Although distillation brings acceptable speedup, we identify that certain inefficient iterations remain a critical bottleneck. To tackle this, we propose an early-exit decoding strategy that moderately relaxes convergence conditions, which further improves average inference efficiency. Experimental results show that the proposed method achieves more than 4 times inference acceleration across different baselines while maintaining high task success rates in both simulated and real-world robot tasks. These experiments validate that our approach provides an efficient and general paradigm for accelerating multimodal decision-making in robotics. Our project page is available at https://irpn-eai.github.io/CEED-VLA/.
RationalVLA: A Rational Vision-Language-Action Model with Dual System
Jun 12, 2025A fundamental requirement for real-world robotic deployment is the ability to understand and respond to natural language instructions. Existing language-conditioned manipulation tasks typically assume that instructions are perfectly aligned with the environment. This assumption limits robustness and generalization in realistic scenarios where instructions may be ambiguous, irrelevant, or infeasible. To address this problem, we introduce RAtional MAnipulation (RAMA), a new benchmark that challenges models with both unseen executable instructions and defective ones that should be rejected. In RAMA, we construct a dataset with over 14,000 samples, including diverse defective instructions spanning six dimensions: visual, physical, semantic, motion, safety, and out-of-context. We further propose the Rational Vision-Language-Action model (RationalVLA). It is a dual system for robotic arms that integrates the high-level vision-language model with the low-level manipulation policy by introducing learnable latent space embeddings. This design enables RationalVLA to reason over instructions, reject infeasible commands, and execute manipulation effectively. Experiments demonstrate that RationalVLA outperforms state-of-the-art baselines on RAMA by a 14.5% higher success rate and 0.94 average task length, while maintaining competitive performance on standard manipulation tasks. Real-world trials further validate its effectiveness and robustness in practical applications. Our project page is https://irpn-eai.github.io/rationalvla.
Moment Alignment: Unifying Gradient and Hessian Matching for Domain Generalization
Jun 09, 2025Domain generalization (DG) seeks to develop models that generalize well to unseen target domains, addressing the prevalent issue of distribution shifts in real-world applications. One line of research in DG focuses on aligning domain-level gradients and Hessians to enhance generalization. However, existing methods are computationally inefficient and the underlying principles of these approaches are not well understood. In this paper, we develop the theory of moment alignment for DG. Grounded in \textit{transfer measure}, a principled framework for quantifying generalizability between two domains, we first extend the definition of transfer measure to domain generalization that includes multiple source domains and establish a target error bound. Then, we prove that aligning derivatives across domains improves transfer measure both when the feature extractor induces an invariant optimal predictor across domains and when it does not. Notably, moment alignment provides a unifying understanding of Invariant Risk Minimization, gradient matching, and Hessian matching, three previously disconnected approaches to DG. We further connect feature moments and derivatives of the classifier head, and establish the duality between feature learning and classifier fitting. Building upon our theory, we introduce \textbf{C}losed-Form \textbf{M}oment \textbf{A}lignment (CMA), a novel DG algorithm that aligns domain-level gradients and Hessians in closed-form. Our method overcomes the computational inefficiencies of existing gradient and Hessian-based techniques by eliminating the need for repeated backpropagation or sampling-based Hessian estimation. We validate the efficacy of our approach through two sets of experiments: linear probing and full fine-tuning. CMA demonstrates superior performance in both settings compared to Empirical Risk Minimization and state-of-the-art algorithms.
Taming Hyperparameter Sensitivity in Data Attribution: Practical Selection Without Costly Retraining
May 30, 2025Data attribution methods, which quantify the influence of individual training data points on a machine learning model, have gained increasing popularity in data-centric applications in modern AI. Despite a recent surge of new methods developed in this space, the impact of hyperparameter tuning in these methods remains under-explored. In this work, we present the first large-scale empirical study to understand the hyperparameter sensitivity of common data attribution methods. Our results show that most methods are indeed sensitive to certain key hyperparameters. However, unlike typical machine learning algorithms -- whose hyperparameters can be tuned using computationally-cheap validation metrics -- evaluating data attribution performance often requires retraining models on subsets of training data, making such metrics prohibitively costly for hyperparameter tuning. This poses a critical open challenge for the practical application of data attribution methods. To address this challenge, we advocate for better theoretical understandings of hyperparameter behavior to inform efficient tuning strategies. As a case study, we provide a theoretical analysis of the regularization term that is critical in many variants of influence function methods. Building on this analysis, we propose a lightweight procedure for selecting the regularization value without model retraining, and validate its effectiveness across a range of standard data attribution benchmarks. Overall, our study identifies a fundamental yet overlooked challenge in the practical application of data attribution, and highlights the importance of careful discussion on hyperparameter selection in future method development.
MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning
May 30, 2025Reward modeling is a key step in building safe foundation models when applying reinforcement learning from human feedback (RLHF) to align Large Language Models (LLMs). However, reward modeling based on the Bradley-Terry (BT) model assumes a global reward function, failing to capture the inherently diverse and heterogeneous human preferences. Hence, such oversimplification limits LLMs from supporting personalization and pluralistic alignment. Theoretically, we show that when human preferences follow a mixture distribution of diverse subgroups, a single BT model has an irreducible error. While existing solutions, such as multi-objective learning with fine-grained annotations, help address this issue, they are costly and constrained by predefined attributes, failing to fully capture the richness of human values. In this work, we introduce MiCRo, a two-stage framework that enhances personalized preference learning by leveraging large-scale binary preference datasets without requiring explicit fine-grained annotations. In the first stage, MiCRo introduces context-aware mixture modeling approach to capture diverse human preferences. In the second stage, MiCRo integrates an online routing strategy that dynamically adapts mixture weights based on specific context to resolve ambiguity, allowing for efficient and scalable preference adaptation with minimal additional supervision. Experiments on multiple preference datasets demonstrate that MiCRo effectively captures diverse human preferences and significantly improves downstream personalization.