 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically-Based Rendering for Indoor Scene Understanding Using Convolutional Neural Networks
Jul 02, 2017
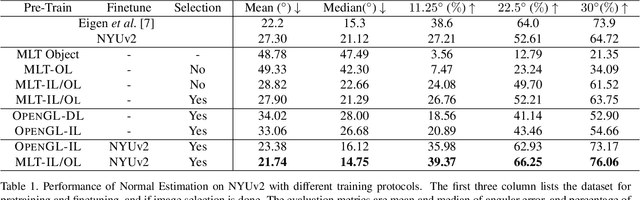


Indoor scene understanding is central to applications such as robot navigation and human companion assistance. Over the last years, data-driven deep neural networks have outperformed many traditional approaches thanks to their representation learning capabilities. One of the bottlenecks in training for better representations is the amount of available per-pixel ground truth data that is required for core scene understanding tasks such as semantic segmentation, normal prediction, and object edge detection. To address this problem, a number of works proposed using synthetic data. However, a systematic study of how such synthetic data is generated is missing. In this work, we introduce a large-scale synthetic dataset with 400K physically-based rendered images from 45K realistic 3D indoor scenes. We study the effects of rendering methods and scene lighting on training for three computer vision tasks: surface normal prediction, semantic segmentation, and object boundary detection. This study provides insights into the best practices for training with synthetic data (more realistic rendering is worth it) and shows that pretraining with our new synthetic dataset can improve results beyond the current state of the art on all three tasks.
Trimming and Improving Skip-thought Vectors
Jun 09, 2017

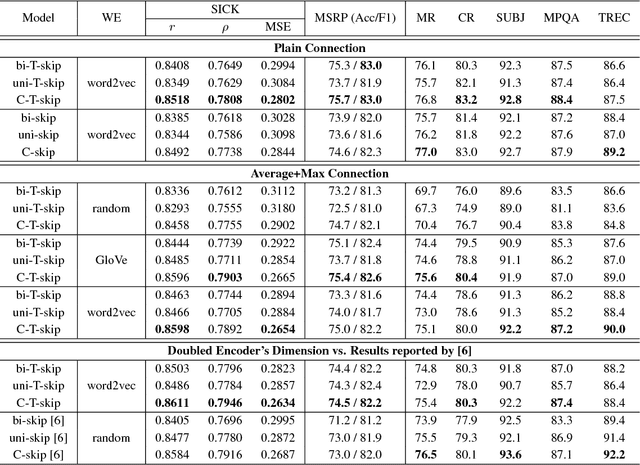
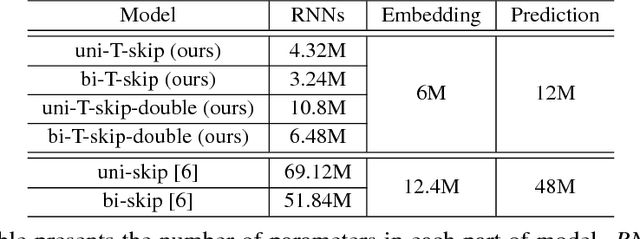
The skip-thought model has been proven to be effective at learning sentence representations and capturing sentence semantics. In this paper, we propose a suite of techniques to trim and improve it. First, we validate a hypothesis that, given a current sentence, inferring the previous and inferring the next sentence provide similar supervision power, therefore only one decoder for predicting the next sentence is preserved in our trimmed skip-thought model. Second, we present a connection layer between encoder and decoder to help the model to generalize better on semantic relatedness tasks. Third, we found that a good word embedding initialization is also essential for learning better sentence representations. We train our model unsupervised on a large corpus with contiguous sentences, and then evaluate the trained model on 7 supervised tasks, which includes semantic relatedness, paraphrase detection, and text classification benchmarks. We empirically show that, our proposed model is a faster, lighter-weight and equally powerful alternative to the original skip-thought model.
Rethinking Skip-thought: A Neighborhood based Approach
Jun 09, 2017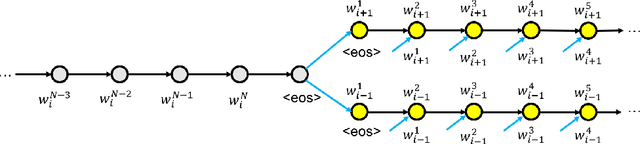
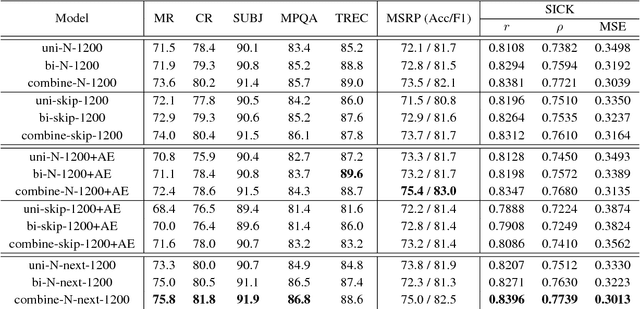
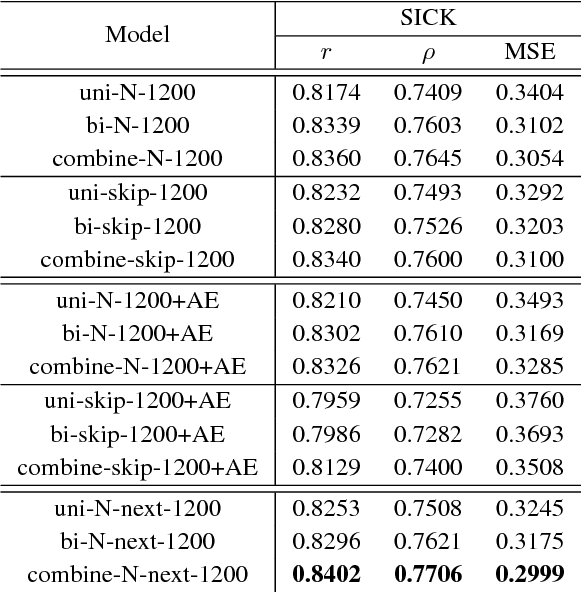

We study the skip-thought model with neighborhood information as weak supervision. More specifically, we propose a skip-thought neighbor model to consider the adjacent sentences as a neighborhood. We train our skip-thought neighbor model on a large corpus with continuous sentences, and then evaluate the trained model on 7 tasks, which include semantic relatedness, paraphrase detection, and classification benchmarks. Both quantitative comparison and qualitative investigation are conducted. We empirically show that, our skip-thought neighbor model performs as well as the skip-thought model on evaluation tasks. In addition, we found that, incorporating an autoencoder path in our model didn't aid our model to perform better, while it hurts the performance of the skip-thought model.
Building a Large Scale Dataset for Image Emotion Recognition: The Fine Print and The Benchmark
May 09, 2016

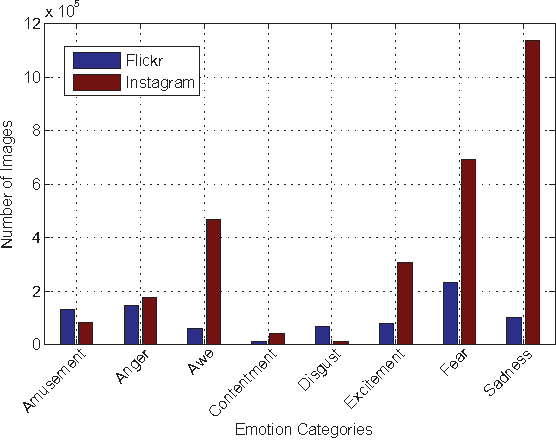

Psychological research results have confirmed that people can have different emotional reactions to different visual stimuli. Several papers have been published on the problem of visual emotion analysis. In particular, attempts have been made to analyze and predict people's emotional reaction towards images. To this end, different kinds of hand-tuned features are proposed. The results reported on several carefully selected and labeled small image data sets have confirmed the promise of such features. While the recent successes of many computer vision related tasks are due to the adoption of Convolutional Neural Networks (CNNs), visual emotion analysis has not achieved the same level of success. This may be primarily due to the unavailability of confidently labeled and relatively large image data sets for visual emotion analysis. In this work, we introduce a new data set, which started from 3+ million weakly labeled images of different emotions and ended up 30 times as large as the current largest publicly available visual emotion data set. We hope that this data set encourages further research on visual emotion analysis. We also perform extensive benchmarking analyses on this large data set using the state of the art methods including CNNs.
Image Captioning with Semantic Attention
Mar 12, 2016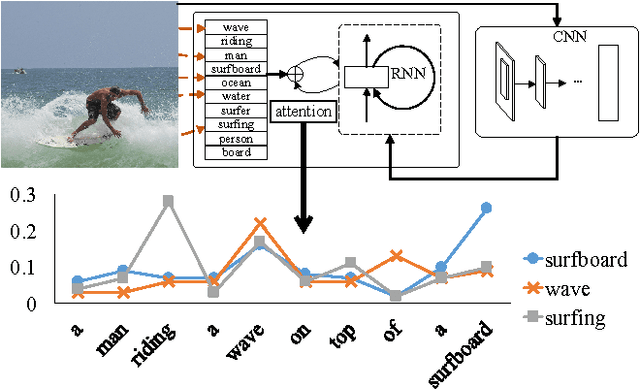
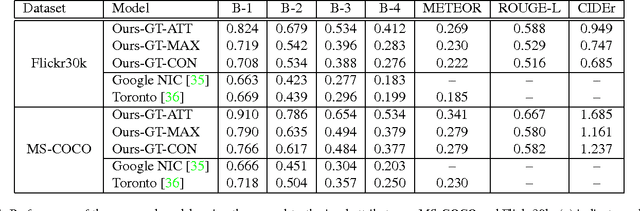
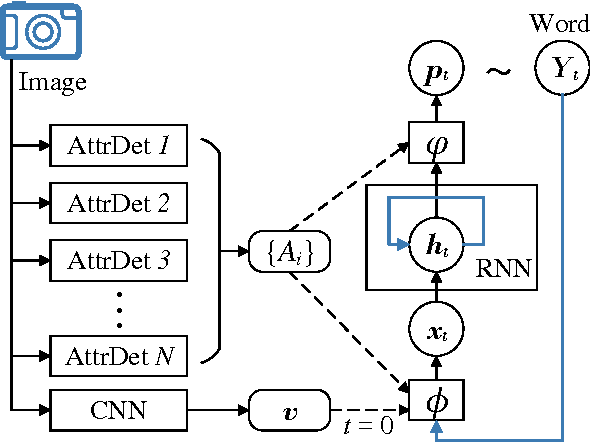
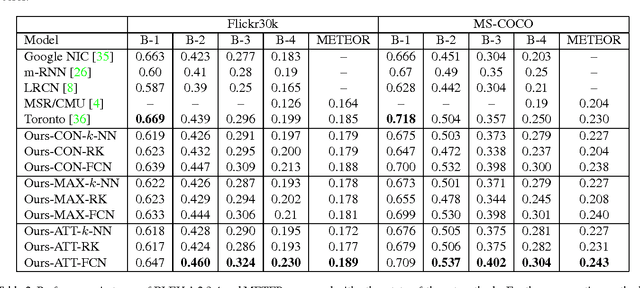
Automatically generating a natural language description of an image has attracted interests recently both because of its importance in practical applications and because it connects two major artificial intelligence fields: computer vision and natural language processing. Existing approaches are either top-down, which start from a gist of an image and convert it into words, or bottom-up, which come up with words describing various aspects of an image and then combine them. In this paper, we propose a new algorithm that combines both approaches through a model of semantic attention. Our algorithm learns to selectively attend to semantic concept proposals and fuse them into hidden states and outputs of recurrent neural networks. The selection and fusion form a feedback connecting the top-down and bottom-up computation. We evaluate our algorithm on two public benchmarks: Microsoft COCO and Flickr30K. Experimental results show that our algorithm significantly outperforms the state-of-the-art approaches consistently across different evaluation metrics.
Multi-Instance Visual-Semantic Embedding
Dec 22, 2015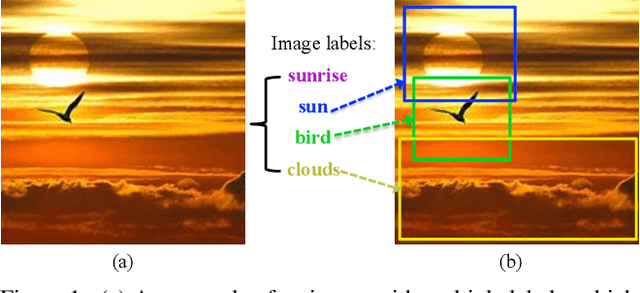
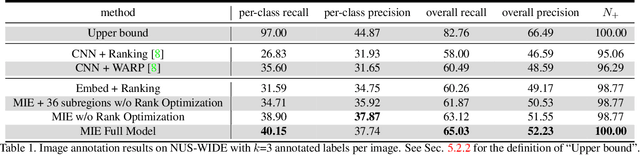
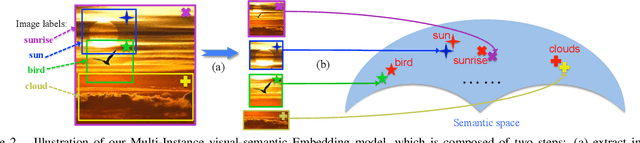
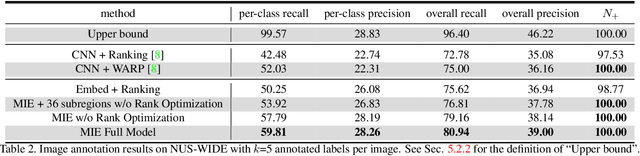
Visual-semantic embedding models have been recently proposed and shown to be effective for image classification and zero-shot learning, by mapping images into a continuous semantic label space. Although several approaches have been proposed for single-label embedding tasks, handling images with multiple labels (which is a more general setting) still remains an open problem, mainly due to the complex underlying corresponding relationship between image and its labels. In this work, we present Multi-Instance visual-semantic Embedding model (MIE) for embedding images associated with either single or multiple labels. Our model discovers and maps semantically-meaningful image subregions to their corresponding labels. And we demonstrate the superiority of our method over the state-of-the-art on two tasks, including multi-label image annotation and zero-shot learning.
Robust Image Sentiment Analysis Using Progressively Trained and Domain Transferred Deep Networks
Sep 20, 2015
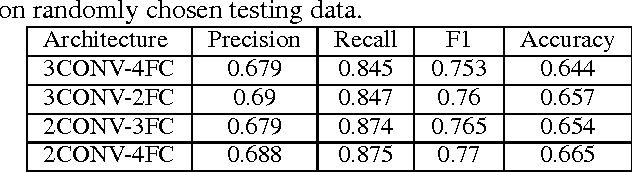
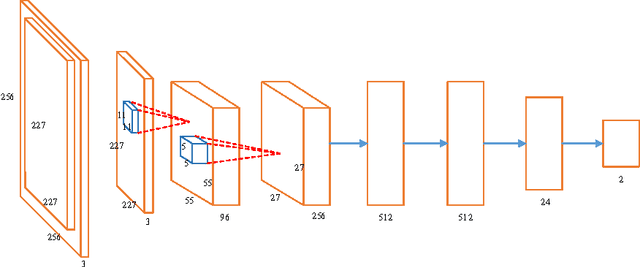
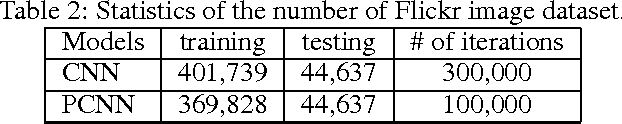
Sentiment analysis of online user generated content is important for many social media analytics tasks. Researchers have largely relied on textual sentiment analysis to develop systems to predict political elections, measure economic indicators, and so on. Recently, social media users are increasingly using images and videos to express their opinions and share their experiences. Sentiment analysis of such large scale visual content can help better extract user sentiments toward events or topics, such as those in image tweets, so that prediction of sentiment from visual content is complementary to textual sentiment analysis. Motivated by the needs in leveraging large scale yet noisy training data to solve the extremely challenging problem of image sentiment analysis, we employ Convolutional Neural Networks (CNN). We first design a suitable CNN architecture for image sentiment analysis. We obtain half a million training samples by using a baseline sentiment algorithm to label Flickr images. To make use of such noisy machine labeled data, we employ a progressive strategy to fine-tune the deep network. Furthermore, we improve the performance on Twitter images by inducing domain transfer with a small number of manually labeled Twitter images. We have conducted extensive experiments on manually labeled Twitter images. The results show that the proposed CNN can achieve better performance in image sentiment analysis than competing algorithms.
DeepFont: Identify Your Font from An Image
Jul 12, 2015
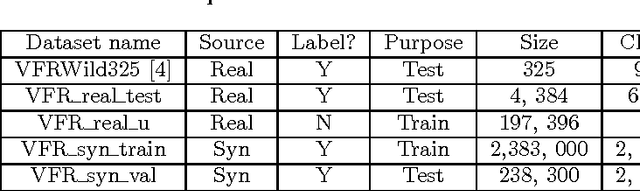


As font is one of the core design concepts, automatic font identification and similar font suggestion from an image or photo has been on the wish list of many designers. We study the Visual Font Recognition (VFR) problem, and advance the state-of-the-art remarkably by developing the DeepFont system. First of all, we build up the first available large-scale VFR dataset, named AdobeVFR, consisting of both labeled synthetic data and partially labeled real-world data. Next, to combat the domain mismatch between available training and testing data, we introduce a Convolutional Neural Network (CNN) decomposition approach, using a domain adaptation technique based on a Stacked Convolutional Auto-Encoder (SCAE) that exploits a large corpus of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. Moreover, we study a novel learning-based model compression approach, in order to reduce the DeepFont model size without sacrificing its performance. The DeepFont system achieves an accuracy of higher than 80% (top-5) on our collected dataset, and also produces a good font similarity measure for font selection and suggestion. We also achieve around 6 times compression of the model without any visible loss of recognition accuracy.
Collaborative Feature Learning from Social Media
Apr 09, 2015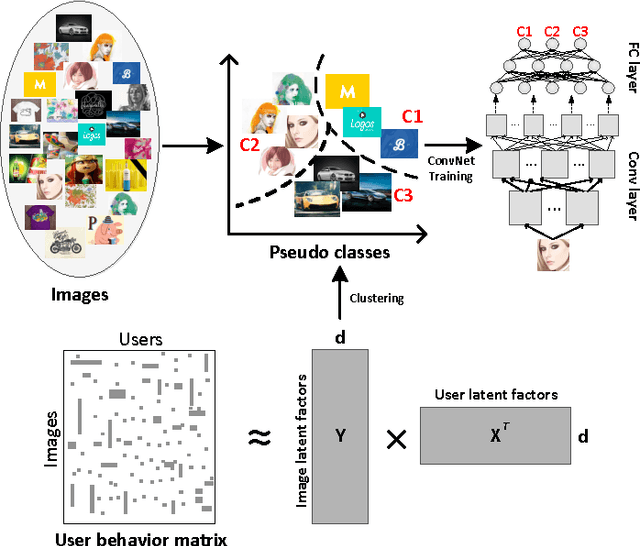
Image feature representation plays an essential role in image recognition and related tasks. The current state-of-the-art feature learning paradigm is supervised learning from labeled data. However, this paradigm requires large-scale category labels, which limits its applicability to domains where labels are hard to obtain. In this paper, we propose a new data-driven feature learning paradigm which does not rely on category labels. Instead, we learn from user behavior data collected on social media. Concretely, we use the image relationship discovered in the latent space from the user behavior data to guide the image feature learning. We collect a large-scale image and user behavior dataset from Behance.net. The dataset consists of 1.9 million images and over 300 million view records from 1.9 million users. We validate our feature learning paradigm on this dataset and find that the learned feature significantly outperforms the state-of-the-art image features in learning better image similarities. We also show that the learned feature performs competitively on various recognition benchmarks.
Decomposition-Based Domain Adaptation for Real-World Font Recognition
Apr 01, 2015

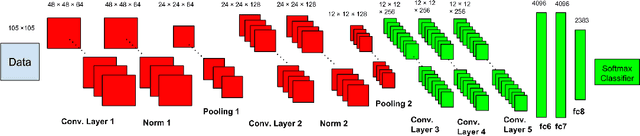

We present a domain adaption framework to address a domain mismatch between synthetic training and real-world testing data. We demonstrate our method on a challenging fine-grain classification problem: recognizing a font style from an image of text. In this task, it is very easy to generate lots of rendered font examples but very hard to obtain real-world labeled images. This real-to-synthetic domain gap caused poor generalization to new real data in previous font recognition methods (Chen et al. (2014)). In this paper, we introduce a Convolutional Neural Network decomposition approach, leveraging a large training corpus of synthetic data to obtain effective features for classification. This is done using an adaptation technique based on a Stacked Convolutional Auto-Encoder that exploits a large collection of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. The proposed DeepFont method achieves an accuracy of higher than 80% (top-5) on a new large labeled real-world dataset we collected.