 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggregated Expert Parallelism
Apr 03, 2025



Mixture-of-Experts (MoE) showcases tremendous potential to scale large language models (LLMs) with enhanced performance and reduced computational complexity. However, its sparsely activated architecture shifts feed-forward networks (FFNs) from being compute-intensive to memory-intensive during inference, leading to substantially lower GPU utilization and increased operational costs. We present MegaScale-Infer, an efficient and cost-effective system for serving large-scale MoE models. MegaScale-Infer disaggregates attention and FFN modules within each model layer, enabling independent scaling, tailored parallelism strategies, and heterogeneous deployment for both modules. To fully exploit disaggregation in the presence of MoE's sparsity, MegaScale-Infer introduces ping-pong pipeline parallelism, which partitions a request batch into micro-batches and shuttles them between attention and FFNs for inference. Combined with distinct model parallelism for each module, MegaScale-Infer effectively hides communication overhead and maximizes GPU utilization. To adapt to disaggregated attention and FFN modules and minimize data transmission overhead (e.g., token dispatch), MegaScale-Infer provides a high-performance M2N communication library that eliminates unnecessary GPU-to-CPU data copies, group initialization overhead, and GPU synchronization. Experimental results indicate that MegaScale-Infer achieves up to 1.90x higher per-GPU throughput than state-of-the-art solutions.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025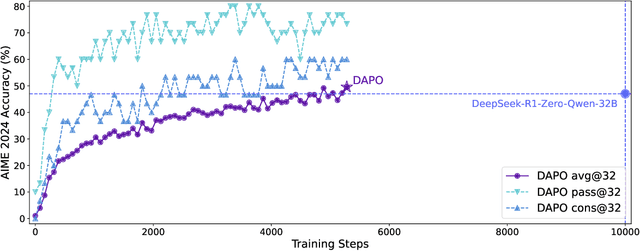

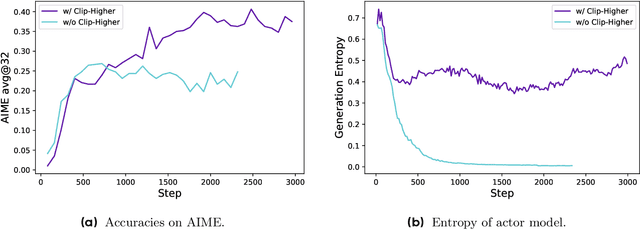

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
ByteScale: Efficient Scaling of LLM Training with a 2048K Context Length on More Than 12,000 GPUs
Feb 28, 2025Scaling long-context ability is essential for Large Language Models (LLMs). To amortize the memory consumption across multiple devices in long-context training, inter-data partitioning (a.k.a. Data Parallelism) and intra-data partitioning (a.k.a. Context Parallelism) are commonly used. Current training frameworks predominantly treat the two techniques as orthogonal, and establish static communication groups to organize the devices as a static mesh (e.g., a 2D mesh). However, the sequences for LLM training typically vary in lengths, no matter for texts, multi-modalities or reinforcement learning. The mismatch between data heterogeneity and static mesh causes redundant communication and imbalanced computation, degrading the training efficiency. In this work, we introduce ByteScale, an efficient, flexible, and scalable LLM training framework for large-scale mixed training of long and short sequences. The core of ByteScale is a novel parallelism strategy, namely Hybrid Data Parallelism (HDP), which unifies the inter- and intra-data partitioning with a dynamic mesh design. In particular, we build a communication optimizer, which eliminates the redundant communication for short sequences by data-aware sharding and dynamic communication, and further compresses the communication cost for long sequences by selective offloading. Besides, we also develop a balance scheduler to mitigate the imbalanced computation by parallelism-aware data assignment. We evaluate ByteScale with the model sizes ranging from 7B to 141B, context lengths from 256K to 2048K, on a production cluster with more than 12,000 GPUs. Experiment results show that ByteScale outperforms the state-of-the-art training system by up to 7.89x.
Comet: Fine-grained Computation-communication Overlapping for Mixture-of-Experts
Feb 27, 2025



Mixture-of-experts (MoE) has been extensively employed to scale large language models to trillion-plus parameters while maintaining a fixed computational cost. The development of large MoE models in the distributed scenario encounters the problem of large communication overhead. The inter-device communication of a MoE layer can occupy 47% time of the entire model execution with popular models and frameworks. Therefore, existing methods suggest the communication in a MoE layer to be pipelined with the computation for overlapping. However, these coarse grained overlapping schemes introduce a notable impairment of computational efficiency and the latency concealing is sub-optimal. To this end, we present COMET, an optimized MoE system with fine-grained communication-computation overlapping. Leveraging data dependency analysis and task rescheduling, COMET achieves precise fine-grained overlapping of communication and computation. Through adaptive workload assignment, COMET effectively eliminates fine-grained communication bottlenecks and enhances its adaptability across various scenarios. Our evaluation shows that COMET accelerates the execution of a single MoE layer by $1.96\times$ and for end-to-end execution, COMET delivers a $1.71\times$ speedup on average. COMET has been adopted in the production environment of clusters with ten-thousand-scale of GPUs, achieving savings of millions of GPU hours.
Minder: Faulty Machine Detection for Large-scale Distributed Model Training
Nov 04, 2024



Large-scale distributed model training requires simultaneous training on up to thousands of machines. Faulty machine detection is critical when an unexpected fault occurs in a machine. From our experience, a training task can encounter two faults per day on average, possibly leading to a halt for hours. To address the drawbacks of the time-consuming and labor-intensive manual scrutiny, we propose Minder, an automatic faulty machine detector for distributed training tasks. The key idea of Minder is to automatically and efficiently detect faulty distinctive monitoring metric patterns, which could last for a period before the entire training task comes to a halt. Minder has been deployed in our production environment for over one year, monitoring daily distributed training tasks where each involves up to thousands of machines. In our real-world fault detection scenarios, Minder can accurately and efficiently react to faults within 3.6 seconds on average, with a precision of 0.904 and F1-score of 0.893.
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training
Oct 20, 2024



Recent years have witnessed a clear trend towards language models with an ever-increasing number of parameters, as well as the growing training overhead and memory usage. Distributed training, particularly through Sharded Data Parallelism (ShardedDP) which partitions optimizer states among workers, has emerged as a crucial technique to mitigate training time and memory usage. Yet, a major challenge in the scalability of ShardedDP is the intensive communication of weights and gradients. While compression techniques can alleviate this issue, they often result in worse accuracy. Driven by this limitation, we propose SDP4Bit (Toward 4Bit Communication Quantization in Sharded Data Parallelism for LLM Training), which effectively reduces the communication of weights and gradients to nearly 4 bits via two novel techniques: quantization on weight differences, and two-level gradient smooth quantization. Furthermore, SDP4Bit presents an algorithm-system co-design with runtime optimization to minimize the computation overhead of compression. In addition to the theoretical guarantees of convergence, we empirically evaluate the accuracy of SDP4Bit on the pre-training of GPT models with up to 6.7 billion parameters, and the results demonstrate a negligible impact on training loss. Furthermore, speed experiments show that SDP4Bit achieves up to 4.08$\times$ speedup in end-to-end throughput on a scale of 128 GPUs.
HybridFlow: A Flexible and Efficient RLHF Framework
Sep 28, 2024



Reinforcement Learning from Human Feedback (RLHF) is widely used in Large Language Model (LLM) alignment. Traditional RL can be modeled as a dataflow, where each node represents computation of a neural network (NN) and each edge denotes data dependencies between the NNs. RLHF complicates the dataflow by expanding each node into a distributed LLM training or generation program, and each edge into a many-to-many multicast. Traditional RL frameworks execute the dataflow using a single controller to instruct both intra-node computation and inter-node communication, which can be inefficient in RLHF due to large control dispatch overhead for distributed intra-node computation. Existing RLHF systems adopt a multi-controller paradigm, which can be inflexible due to nesting distributed computation and data communication. We propose HybridFlow, which combines single-controller and multi-controller paradigms in a hybrid manner to enable flexible representation and efficient execution of the RLHF dataflow. We carefully design a set of hierarchical APIs that decouple and encapsulate computation and data dependencies in the complex RLHF dataflow, allowing efficient operation orchestration to implement RLHF algorithms and flexible mapping of the computation onto various devices. We further design a 3D-HybridEngine for efficient actor model resharding between training and generation phases, with zero memory redundancy and significantly reduced communication overhead. Our experimental results demonstrate 1.53$\times$~20.57$\times$ throughput improvement when running various RLHF algorithms using HybridFlow, as compared with state-of-the-art baselines. HybridFlow source code is available at https://github.com/volcengine/verl.
Optimus: Accelerating Large-Scale Multi-Modal LLM Training by Bubble Exploitation
Aug 07, 2024



Multimodal large language models (MLLMs) have extended the success of large language models (LLMs) to multiple data types, such as image, text and audio, achieving significant performance in various domains, including multimodal translation, visual question answering and content generation. Nonetheless, existing systems are inefficient to train MLLMs due to substantial GPU bubbles caused by the heterogeneous modality models and complex data dependencies in 3D parallelism. This paper proposes Optimus, a distributed MLLM training system that reduces end-to-end MLLM training time. Optimus is based on our principled analysis that scheduling the encoder computation within the LLM bubbles can reduce bubbles in MLLM training. To make scheduling encoder computation possible for all GPUs, Optimus searches the separate parallel plans for encoder and LLM, and adopts a bubble scheduling algorithm to enable exploiting LLM bubbles without breaking the original data dependencies in the MLLM model architecture. We further decompose encoder layer computation into a series of kernels, and analyze the common bubble pattern of 3D parallelism to carefully optimize the sub-millisecond bubble scheduling, minimizing the overall training time. Our experiments in a production cluster show that Optimus accelerates MLLM training by 20.5%-21.3% with ViT-22B and GPT-175B model over 3072 GPUs compared to baselines.
ByteCheckpoint: A Unified Checkpointing System for LLM Development
Jul 29, 2024



The development of real-world Large Language Models (LLMs) necessitates checkpointing of training states in persistent storage to mitigate potential software and hardware failures, as well as to facilitate checkpoint transferring within the training pipeline and across various tasks. Due to the immense size of LLMs, saving and loading checkpoints often incur intolerable minute-level stalls, significantly diminishing training efficiency. Besides, when transferring checkpoints across tasks, checkpoint resharding, defined as loading checkpoints into parallel configurations differing from those used for saving, is often required according to the characteristics and resource quota of specific tasks. Previous checkpointing systems [16,3,33,6] assume consistent parallel configurations, failing to address the complexities of checkpoint transformation during resharding. Furthermore, in the industry platform, developers create checkpoints from different training frameworks[23,36,21,11], each with its own unique storage and I/O logic. This diversity complicates the implementation of unified checkpoint management and optimization. To address these challenges, we introduce ByteCheckpoint, a PyTorch-native multi-framework LLM checkpointing system that supports automatic online checkpoint resharding. ByteCheckpoint employs a data/metadata disaggregated storage architecture, decoupling checkpoint storage from the adopted parallelism strategies and training frameworks. We design an efficient asynchronous tensor merging technique to settle the irregular tensor sharding problem and propose several I/O performance optimizations to significantly enhance the efficiency of checkpoint saving and loading. Experimental results demonstrate ByteCheckpoint's substantial advantages in reducing checkpoint saving (by up to 529.22X) and loading (by up to 3.51X) costs, compared to baseline methods.
QSync: Quantization-Minimized Synchronous Distributed Training Across Hybrid Devices
Jul 02, 2024



A number of production deep learning clusters have attempted to explore inference hardware for DNN training, at the off-peak serving hours with many inference GPUs idling. Conducting DNN training with a combination of heterogeneous training and inference GPUs, known as hybrid device training, presents considerable challenges due to disparities in compute capability and significant differences in memory capacity. We propose QSync, a training system that enables efficient synchronous data-parallel DNN training over hybrid devices by strategically exploiting quantized operators. According to each device's available resource capacity, QSync selects a quantization-minimized setting for operators in the distributed DNN training graph, minimizing model accuracy degradation but keeping the training efficiency brought by quantization. We carefully design a predictor with a bi-directional mixed-precision indicator to reflect the sensitivity of DNN layers on fixed-point and floating-point low-precision operators, a replayer with a neighborhood-aware cost mapper to accurately estimate the latency of distributed hybrid mixed-precision training, and then an allocator that efficiently synchronizes workers with minimized model accuracy degradation. QSync bridges the computational graph on PyTorch to an optimized backend for quantization kernel performance and flexible support for various GPU architectures. Extensive experiments show that QSync's predictor can accurately simulate distributed mixed-precision training with <5% error, with a consistent 0.27-1.03% accuracy improvement over the from-scratch training tasks compared to uniform precision.