 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVSum: A Benchmark for Timestamp-Aware Long Video Summarization
Apr 11, 2026Long video summarization presents significant challenges for current multimodal large language models (MLLMs), particularly in maintaining temporal fidelity over extended durations and producing summaries that are both semantically and temporally grounded. In this work, we present LVSum, a human-annotated benchmark designed specifically for evaluating long video summarization with fine-grained temporal alignment. LVSum comprises diverse long-form videos across 13 domains, each paired with human-generated summaries containing precise temporal references. We conduct a comprehensive evaluation of both proprietary and open-source MLLMs on LVSum, assessing performance using newly introduced LLM-based metrics for content relevance and modality coherence, alongside standard evaluation metrics. Our experiments reveal systematic gaps in temporal understanding among existing MLLMs and offer insights that establish a new foundation for advancing temporal reasoning in long video summarization.
Proactive Agent Research Environment: Simulating Active Users to Evaluate Proactive Assistants
Apr 01, 2026Proactive agents that anticipate user needs and autonomously execute tasks hold great promise as digital assistants, yet the lack of realistic user simulation frameworks hinders their development. Existing approaches model apps as flat tool-calling APIs, failing to capture the stateful and sequential nature of user interaction in digital environments and making realistic user simulation infeasible. We introduce Proactive Agent Research Environment (Pare), a framework for building and evaluating proactive agents in digital environments. Pare models applications as finite state machines with stateful navigation and state-dependent action space for the user simulator, enabling active user simulation. Building on this foundation, we present Pare-Bench, a benchmark of 143 diverse tasks spanning communication, productivity, scheduling, and lifestyle apps, designed to test context observation, goal inference, intervention timing, and multi-app orchestration.
Advancing Egocentric Video Question Answering with Multimodal Large Language Models
Apr 06, 2025Egocentric Video Question Answering (QA) requires models to handle long-horizon temporal reasoning, first-person perspectives, and specialized challenges like frequent camera movement. This paper systematically evaluates both proprietary and open-source Multimodal Large Language Models (MLLMs) on QaEgo4Dv2 - a refined dataset of egocentric videos derived from QaEgo4D. Four popular MLLMs (GPT-4o, Gemini-1.5-Pro, Video-LLaVa-7B and Qwen2-VL-7B-Instruct) are assessed using zero-shot and fine-tuned approaches for both OpenQA and CloseQA settings. We introduce QaEgo4Dv2 to mitigate annotation noise in QaEgo4D, enabling more reliable comparison. Our results show that fine-tuned Video-LLaVa-7B and Qwen2-VL-7B-Instruct achieve new state-of-the-art performance, surpassing previous benchmarks by up to +2.6% ROUGE/METEOR (for OpenQA) and +13% accuracy (for CloseQA). We also present a thorough error analysis, indicating the model's difficulty in spatial reasoning and fine-grained object recognition - key areas for future improvement.
MARRS: Multimodal Reference Resolution System
Nov 03, 2023



Successfully handling context is essential for any dialog understanding task. This context maybe be conversational (relying on previous user queries or system responses), visual (relying on what the user sees, for example, on their screen), or background (based on signals such as a ringing alarm or playing music). In this work, we present an overview of MARRS, or Multimodal Reference Resolution System, an on-device framework within a Natural Language Understanding system, responsible for handling conversational, visual and background context. In particular, we present different machine learning models to enable handing contextual queries; specifically, one to enable reference resolution, and one to handle context via query rewriting. We also describe how these models complement each other to form a unified, coherent, lightweight system that can understand context while preserving user privacy.
Referring to Screen Texts with Voice Assistants
Jun 10, 2023



Voice assistants help users make phone calls, send messages, create events, navigate, and do a lot more. However, assistants have limited capacity to understand their users' context. In this work, we aim to take a step in this direction. Our work dives into a new experience for users to refer to phone numbers, addresses, email addresses, URLs, and dates on their phone screens. Our focus lies in reference understanding, which becomes particularly interesting when multiple similar texts are present on screen, similar to visual grounding. We collect a dataset and propose a lightweight general-purpose model for this novel experience. Due to the high cost of consuming pixels directly, our system is designed to rely on the extracted text from the UI. Our model is modular, thus offering flexibility, improved interpretability, and efficient runtime memory utilization.
MMIU: Dataset for Visual Intent Understanding in Multimodal Assistants
Oct 31, 2021
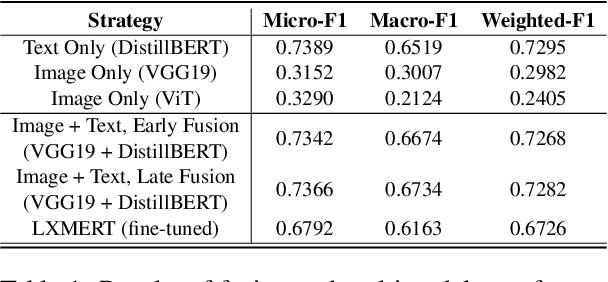


In multimodal assistant, where vision is also one of the input modalities, the identification of user intent becomes a challenging task as visual input can influence the outcome. Current digital assistants take spoken input and try to determine the user intent from conversational or device context. So, a dataset, which includes visual input (i.e. images or videos for the corresponding questions targeted for multimodal assistant use cases, is not readily available. The research in visual question answering (VQA) and visual question generation (VQG) is a great step forward. However, they do not capture questions that a visually-abled person would ask multimodal assistants. Moreover, many times questions do not seek information from external knowledge. In this paper, we provide a new dataset, MMIU (MultiModal Intent Understanding), that contains questions and corresponding intents provided by human annotators while looking at images. We, then, use this dataset for intent classification task in multimodal digital assistant. We also experiment with various approaches for combining vision and language features including the use of multimodal transformer for classification of image-question pairs into 14 intents. We provide the benchmark results and discuss the role of visual and text features for the intent classification task on our dataset.
Generating Natural Questions from Images for Multimodal Assistants
Nov 17, 2020
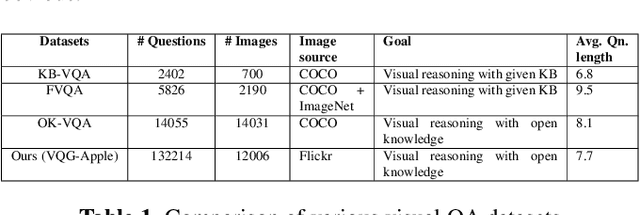

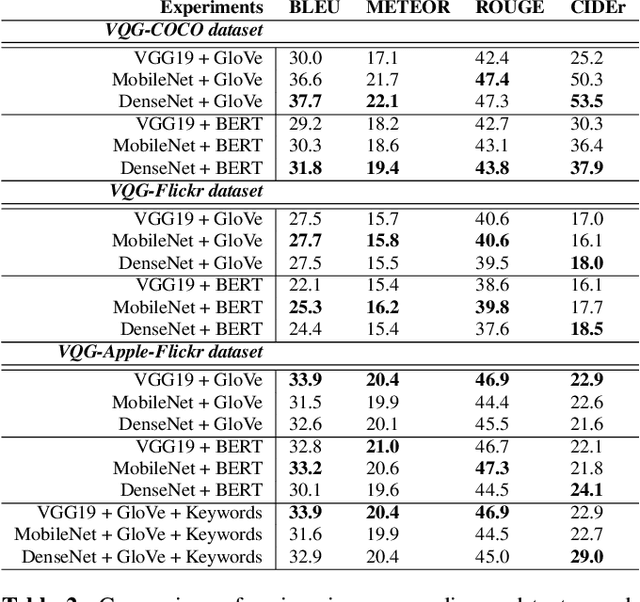
Generating natural, diverse, and meaningful questions from images is an essential task for multimodal assistants as it confirms whether they have understood the object and scene in the images properly. The research in visual question answering (VQA) and visual question generation (VQG) is a great step. However, this research does not capture questions that a visually-abled person would ask multimodal assistants. Recently published datasets such as KB-VQA, FVQA, and OK-VQA try to collect questions that look for external knowledge which makes them appropriate for multimodal assistants. However, they still contain many obvious and common-sense questions that humans would not usually ask a digital assistant. In this paper, we provide a new benchmark dataset that contains questions generated by human annotators keeping in mind what they would ask multimodal digital assistants. Large scale annotations for several hundred thousand images are expensive and time-consuming, so we also present an effective way of automatically generating questions from unseen images. In this paper, we present an approach for generating diverse and meaningful questions that consider image content and metadata of image (e.g., location, associated keyword). We evaluate our approach using standard evaluation metrics such as BLEU, METEOR, ROUGE, and CIDEr to show the relevance of generated questions with human-provided questions. We also measure the diversity of generated questions using generative strength and inventiveness metrics. We report new state-of-the-art results on the public and our datasets.
Noise-robust Named Entity Understanding for Virtual Assistants
May 29, 2020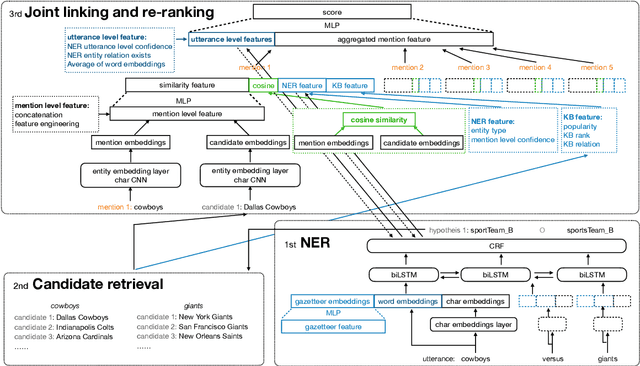
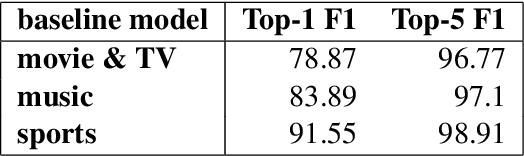
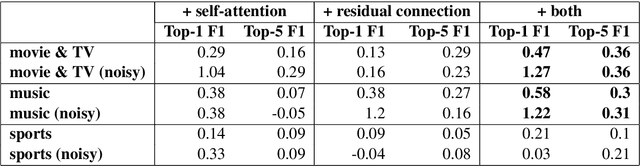
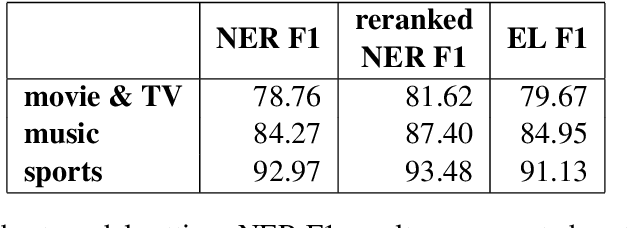
Named Entity Understanding (NEU) plays an essential role in interactions between users and voice assistants, since successfully identifying entities and correctly linking them to their standard forms is crucial to understanding the user's intent. NEU is a challenging task in voice assistants due to the ambiguous nature of natural language and because noise introduced by speech transcription and user errors occur frequently in spoken natural language queries. In this paper, we propose an architecture with novel features that jointly solves the recognition of named entities (a.k.a. Named Entity Recognition, or NER) and the resolution to their canonical forms (a.k.a. Entity Linking, or EL). We show that by combining NER and EL information in a joint reranking module, our proposed framework improves accuracy in both tasks. This improved performance and the features that enable it, also lead to better accuracy in downstream tasks, such as domain classification and semantic parsing.