 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevitalize Region Feature for Democratizing Video-Language Pre-training
Mar 19, 2022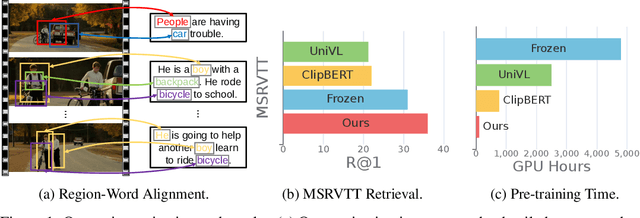
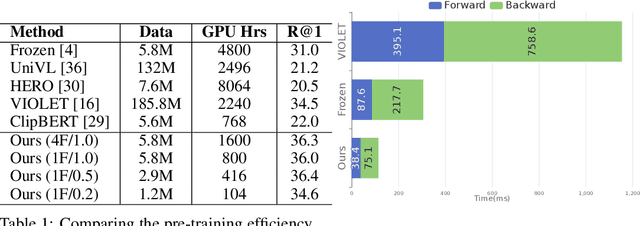
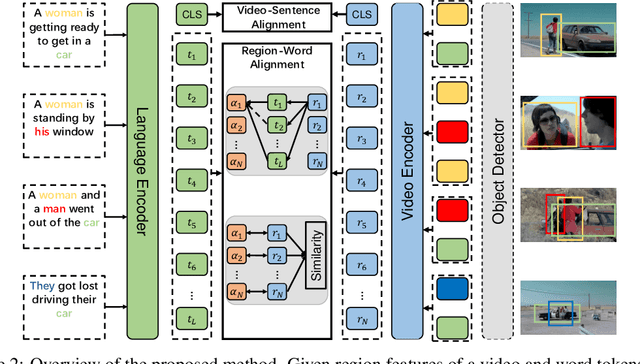

Recent dominant methods for video-language pre-training (VLP) learn transferable representations from the raw pixels in an end-to-end manner to achieve advanced performance on downstream video-language tasks. Despite the impressive results, VLP research becomes extremely expensive with the need for massive data and a long training time, preventing further explorations. In this work, we revitalize region features of sparsely sampled video clips to significantly reduce both spatial and temporal visual redundancy towards democratizing VLP research at the same time achieving state-of-the-art results. Specifically, to fully explore the potential of region features, we introduce a novel bidirectional region-word alignment regularization that properly optimizes the fine-grained relations between regions and certain words in sentences, eliminating the domain/modality disconnections between pre-extracted region features and text. Extensive results of downstream text-to-video retrieval and video question answering tasks on seven datasets demonstrate the superiority of our method on both effectiveness and efficiency, e.g., our method achieves competing results with 80\% fewer data and 85\% less pre-training time compared to the most efficient VLP method so far. The code will be available at \url{https://github.com/showlab/DemoVLP}.
All in One: Exploring Unified Video-Language Pre-training
Mar 14, 2022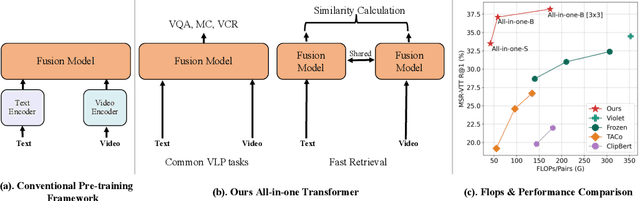
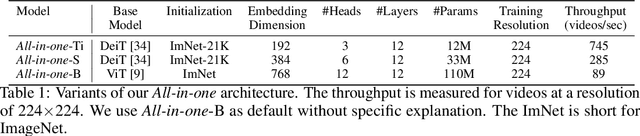
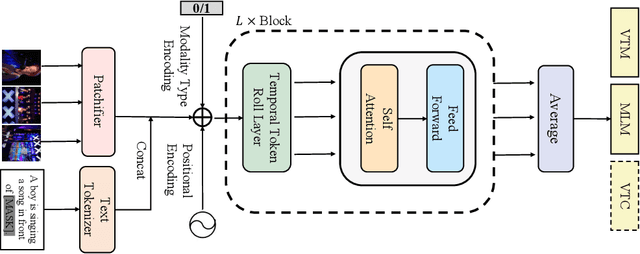
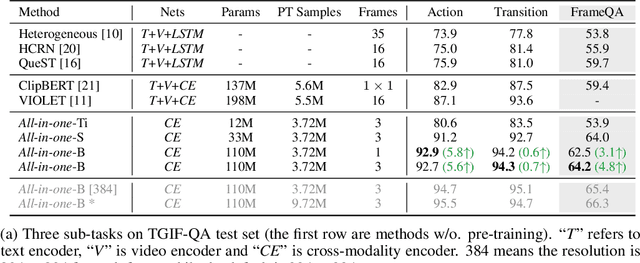
Mainstream Video-Language Pre-training models \cite{actbert,clipbert,violet} consist of three parts, a video encoder, a text encoder, and a video-text fusion Transformer. They pursue better performance via utilizing heavier unimodal encoders or multimodal fusion Transformers, resulting in increased parameters with lower efficiency in downstream tasks. In this work, we for the first time introduce an end-to-end video-language model, namely \textit{all-in-one Transformer}, that embeds raw video and textual signals into joint representations using a unified backbone architecture. We argue that the unique temporal information of video data turns out to be a key barrier hindering the design of a modality-agnostic Transformer. To overcome the challenge, we introduce a novel and effective token rolling operation to encode temporal representations from video clips in a non-parametric manner. The careful design enables the representation learning of both video-text multimodal inputs and unimodal inputs using a unified backbone model. Our pre-trained all-in-one Transformer is transferred to various downstream video-text tasks after fine-tuning, including text-video retrieval, video-question answering, multiple choice and visual commonsense reasoning. State-of-the-art performances with the minimal model FLOPs on nine datasets demonstrate the superiority of our method compared to the competitive counterparts. The code and pretrained model have been released in https://github.com/showlab/all-in-one.
Video-Text Pre-training with Learned Regions
Dec 06, 2021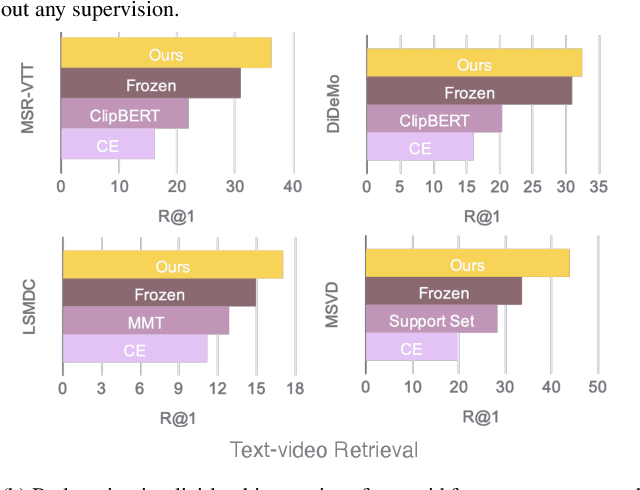
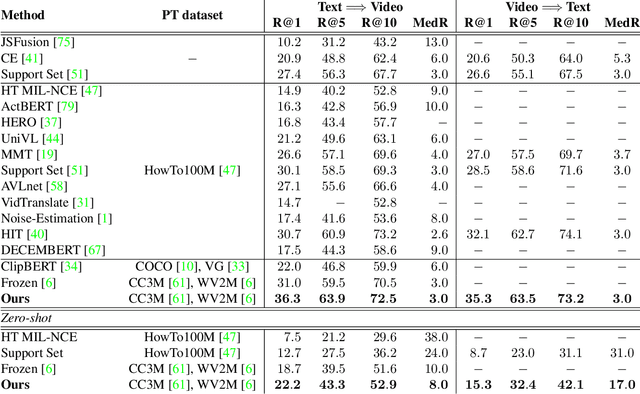
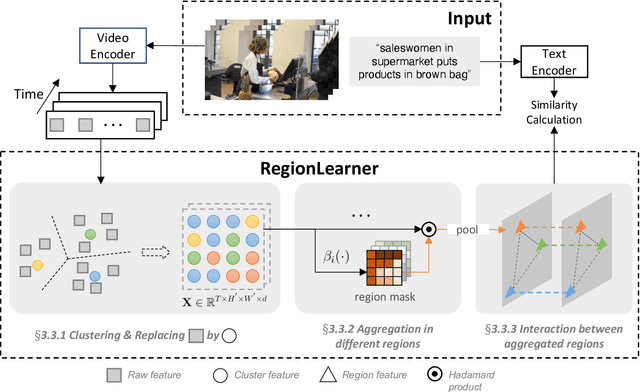
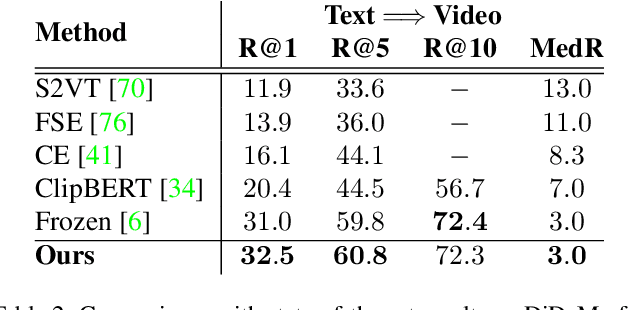
Video-Text pre-training aims at learning transferable representations from large-scale video-text pairs via aligning the semantics between visual and textual information. State-of-the-art approaches extract visual features from raw pixels in an end-to-end fashion. However, these methods operate at frame-level directly and thus overlook the spatio-temporal structure of objects in video, which yet has a strong synergy with nouns in textual descriptions. In this work, we propose a simple yet effective module for video-text representation learning, namely RegionLearner, which can take into account the structure of objects during pre-training on large-scale video-text pairs. Given a video, our module (1) first quantizes visual features into semantic clusters, then (2) generates learnable masks and uses them to aggregate the features belonging to the same semantic region, and finally (3) models the interactions between different aggregated regions. In contrast to using off-the-shelf object detectors, our proposed module does not require explicit supervision and is much more computationally efficient. We pre-train the proposed approach on the public WebVid2M and CC3M datasets. Extensive evaluations on four downstream video-text retrieval benchmarks clearly demonstrate the effectiveness of our RegionLearner. The code will be available at https://github.com/ruiyan1995/Region_Learner.
Object-aware Video-language Pre-training for Retrieval
Dec 06, 2021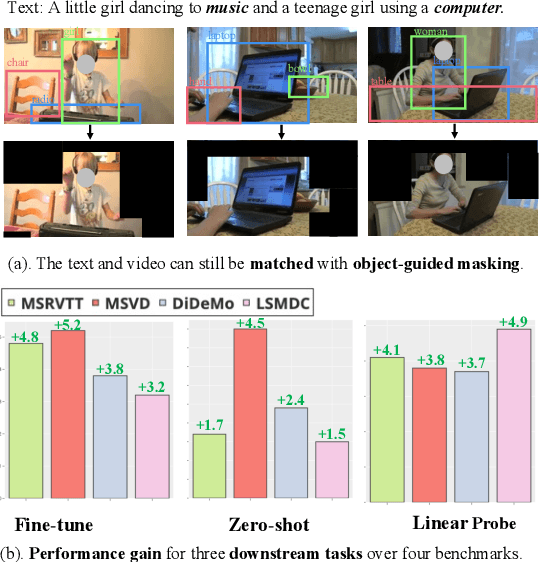
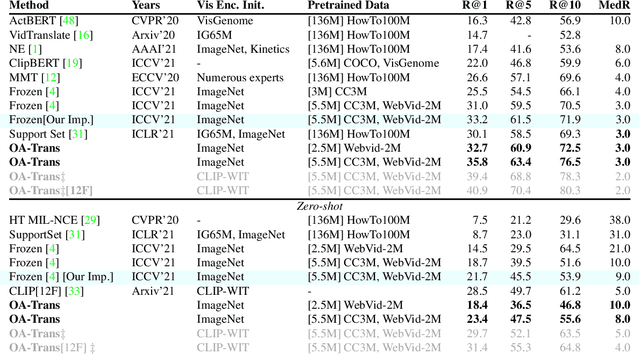
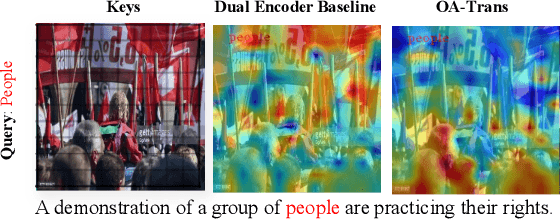
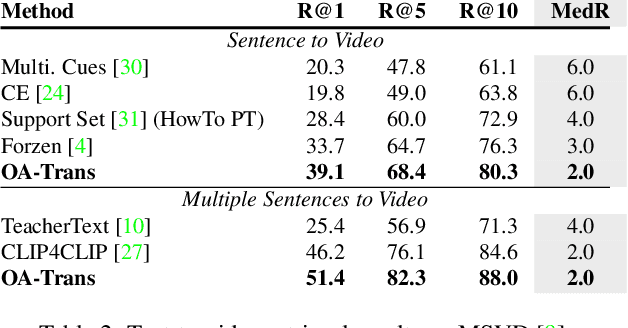
Recently, by introducing large-scale dataset and strong transformer network, video-language pre-training has shown great success especially for retrieval. Yet, existing video-language transformer models do not explicitly fine-grained semantic align. In this work, we present Object-aware Transformers, an object-centric approach that extends video-language transformer to incorporate object representations. The key idea is to leverage the bounding boxes and object tags to guide the training process. We evaluate our model on three standard sub-tasks of video-text matching on four widely used benchmarks. We also provide deep analysis and detailed ablation about the proposed method. We show clear improvement in performance across all tasks and datasets considered, demonstrating the value of a model that incorporates object representations into a video-language architecture. The code will be released at \url{https://github.com/FingerRec/OA-Transformer}.
Unsupervised Adaptive Semantic Segmentation with Local Lipschitz Constraint
May 27, 2021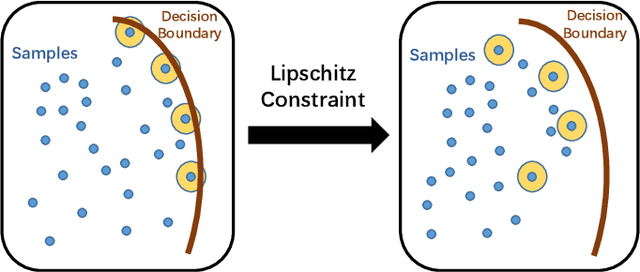
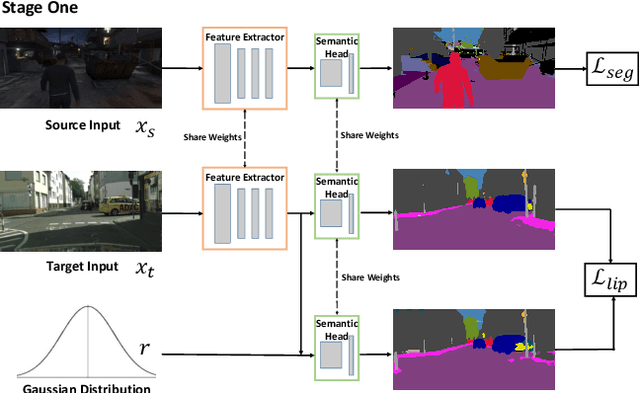
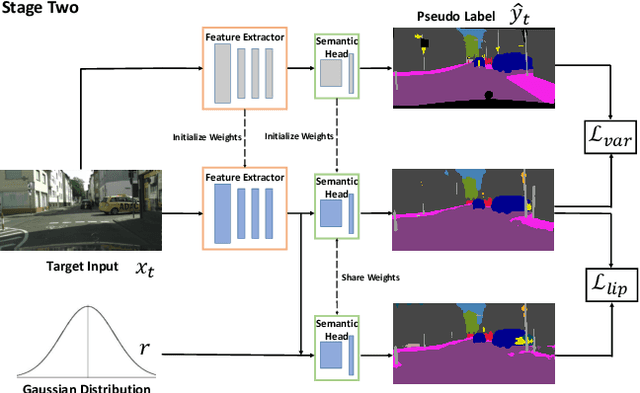

Recent advances in unsupervised domain adaptation have seen considerable progress in semantic segmentation. Existing methods either align different domains with adversarial training or involve the self-learning that utilizes pseudo labels to conduct supervised training. The former always suffers from the unstable training caused by adversarial training and only focuses on the inter-domain gap that ignores intra-domain knowledge. The latter tends to put overconfident label prediction on wrong categories, which propagates errors to more samples. To solve these problems, we propose a two-stage adaptive semantic segmentation method based on the local Lipschitz constraint that satisfies both domain alignment and domain-specific exploration under a unified principle. In the first stage, we propose the local Lipschitzness regularization as the objective function to align different domains by exploiting intra-domain knowledge, which explores a promising direction for non-adversarial adaptive semantic segmentation. In the second stage, we use the local Lipschitzness regularization to estimate the probability of satisfying Lipschitzness for each pixel, and then dynamically sets the threshold of pseudo labels to conduct self-learning. Such dynamical self-learning effectively avoids the error propagation caused by noisy labels. Optimization in both stages is based on the same principle, i.e., the local Lipschitz constraint, so that the knowledge learned in the first stage can be maintained in the second stage. Further, due to the model-agnostic property, our method can easily adapt to any CNN-based semantic segmentation networks. Experimental results demonstrate the excellent performance of our method on standard benchmarks.
Part2Whole: Iteratively Enrich Detail for Cross-Modal Retrieval with Partial Query
Mar 02, 2021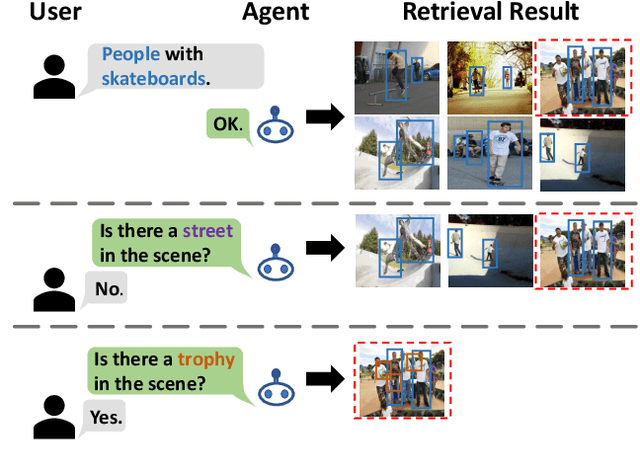

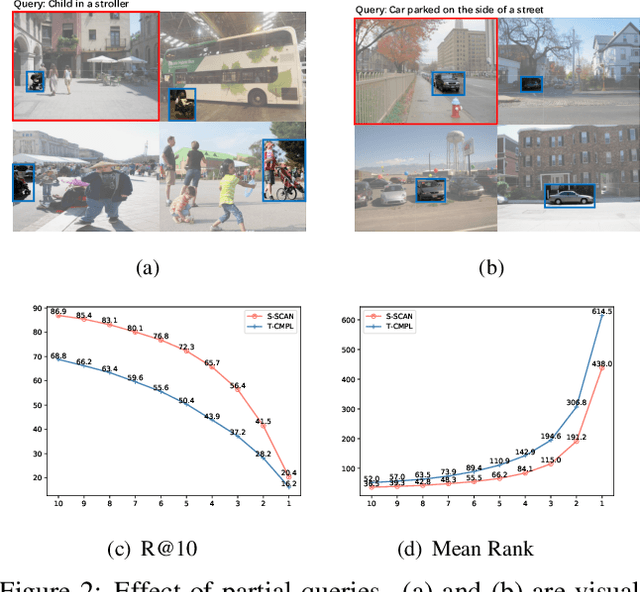
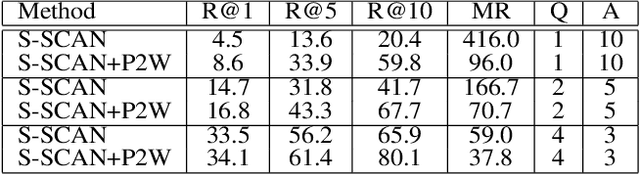
Text-based image retrieval has seen considerable progress in recent years. However, the performance of existing methods suffers in real life since the user is likely to provide an incomplete description of a complex scene, which often leads to results filled with false positives that fit the incomplete description. In this work, we introduce the partial-query problem and extensively analyze its influence on text-based image retrieval. We then propose an interactive retrieval framework called Part2Whole to tackle this problem by iteratively enriching the missing details. Specifically, an Interactive Retrieval Agent is trained to build an optimal policy to refine the initial query based on a user-friendly interaction and statistical characteristics of the gallery. Compared to other dialog-based methods that rely heavily on the user to feed back differentiating information, we let AI take over the optimal feedback searching process and hint the user with confirmation-based questions about details. Furthermore, since fully-supervised training is often infeasible due to the difficulty of obtaining human-machine dialog data, we present a weakly-supervised reinforcement learning method that needs no human-annotated data other than the text-image dataset. Experiments show that our framework significantly improves the performance of text-based image retrieval under complex scenes.
Contextual Non-Local Alignment over Full-Scale Representation for Text-Based Person Search
Jan 08, 2021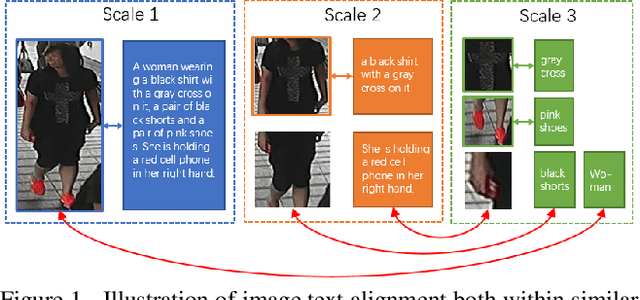
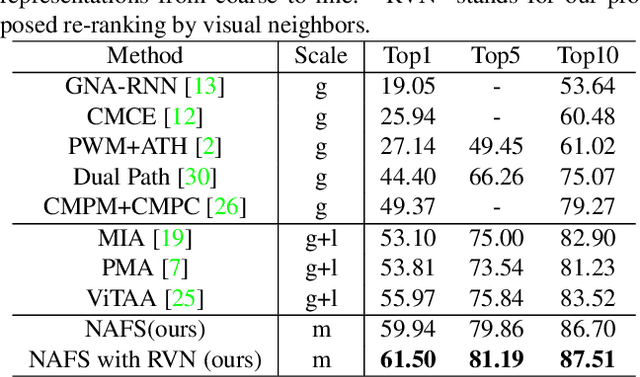
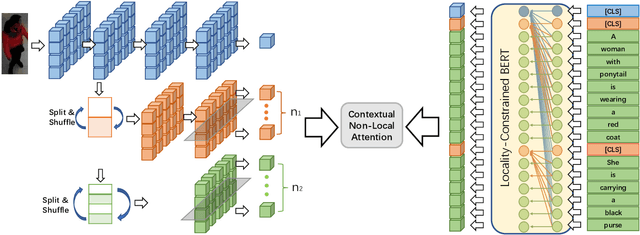
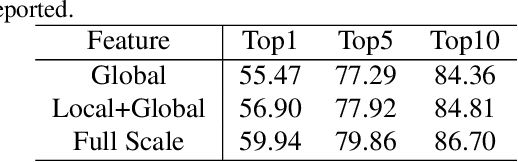
Text-based person search aims at retrieving target person in an image gallery using a descriptive sentence of that person. It is very challenging since modal gap makes effectively extracting discriminative features more difficult. Moreover, the inter-class variance of both pedestrian images and descriptions is small. So comprehensive information is needed to align visual and textual clues across all scales. Most existing methods merely consider the local alignment between images and texts within a single scale (e.g. only global scale or only partial scale) then simply construct alignment at each scale separately. To address this problem, we propose a method that is able to adaptively align image and textual features across all scales, called NAFS (i.e.Non-local Alignment over Full-Scale representations). Firstly, a novel staircase network structure is proposed to extract full-scale image features with better locality. Secondly, a BERT with locality-constrained attention is proposed to obtain representations of descriptions at different scales. Then, instead of separately aligning features at each scale, a novel contextual non-local attention mechanism is applied to simultaneously discover latent alignments across all scales. The experimental results show that our method outperforms the state-of-the-art methods by 5.53% in terms of top-1 and 5.35% in terms of top-5 on text-based person search dataset. The code is available at https://github.com/TencentYoutuResearch/PersonReID-NAFS
Learning Smooth Representation for Unsupervised Domain Adaptation
May 26, 2019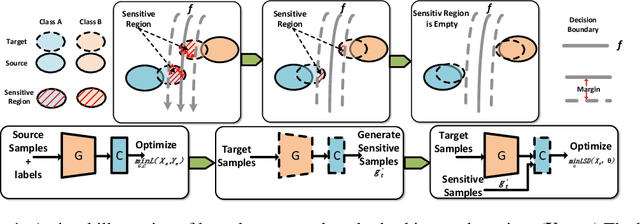
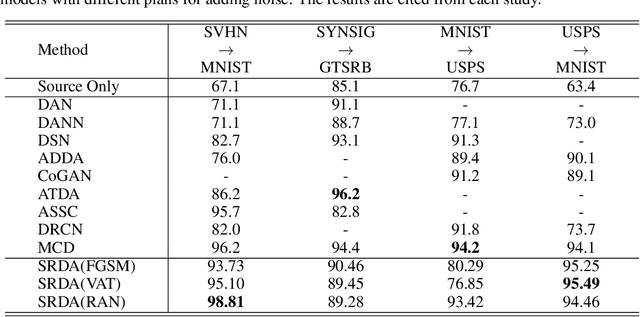
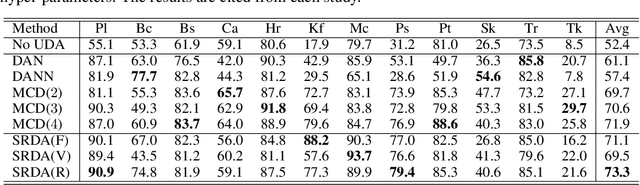
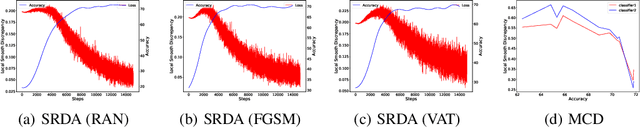
In unsupervised domain adaptation, existing methods utilizing the boundary decision have achieved remarkable performance, but they lack analysis of the relationship between decision boundary and features. In our work, we propose a new principle that adaptive classifiers and transferable features can be obtained in the target domain by learning smooth representations. We analyze the relationship between decision boundary and ambiguous target features in terms of smoothness. Thereafter, local smooth discrepancy is defined to measure the smoothness of a sample and detect sensitive samples which are easily misclassified. To strengthen the smoothness, sensitive samples are corrected in feature space by optimizing local smooth discrepancy. Moreover, the generalization error upper bound is derived theoretically. Finally, We evaluate our method in several standard benchmark datasets. Empirical evidence shows that the proposed method is comparable or superior to the state-of-the-art methods and local smooth discrepancy is a valid metric to evaluate the performance of a domain adaptation method.
Virtual Conditional Generative Adversarial Networks
Jan 25, 2019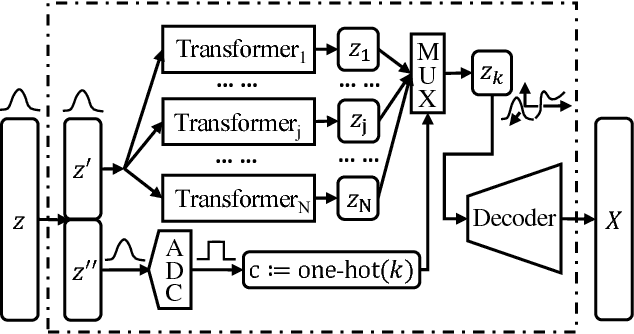
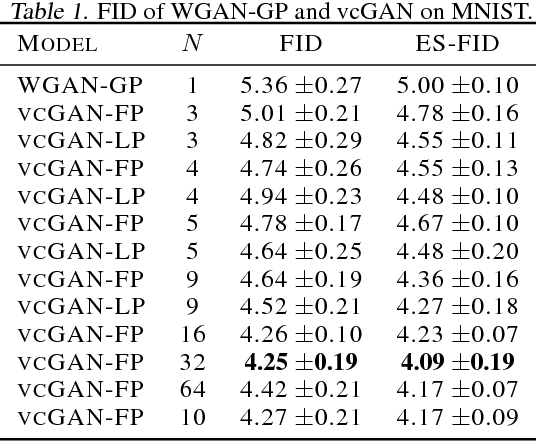
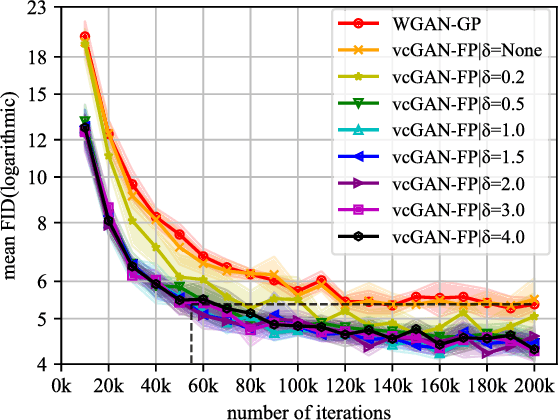
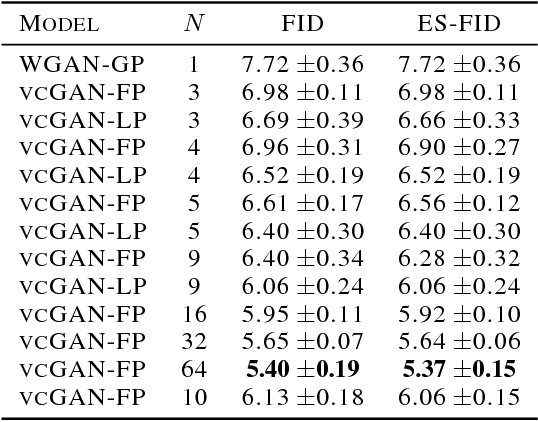
When trained on multimodal image datasets, normal Generative Adversarial Networks (GANs) are usually outperformed by class-conditional GANs and ensemble GANs, but conditional GANs is restricted to labeled datasets and ensemble GANs lack efficiency. We propose a novel GAN variant called virtual conditional GAN (vcGAN) which is not only an ensemble GAN with multiple generative paths while adding almost zero network parameters, but also a conditional GAN that can be trained on unlabeled datasets without explicit clustering steps or objectives other than the adversary loss. Inside the vcGAN's generator, a learnable ``analog-to-digital converter (ADC)" module maps a slice of the inputted multivariate Gaussian noise to discrete/digital noise (virtual label), according to which a selector selects the corresponding generative path to produce the sample. All the generative paths share the same decoder network while in each path the decoder network is fed with a concatenation of a different pre-computed amplified one-hot vector and the inputted Gaussian noise. We conducted a lot of experiments on several balanced/imbalanced image datasets to demonstrate that vcGAN converges faster and achieves improved Frech\'et Inception Distance (FID). In addition, we show the training byproduct that the ADC in vcGAN learned the categorical probability of each mode and that each generative path generates samples of specific mode, which enables class-conditional sampling. Codes are available at \url{https://github.com/annonnymmouss/vcgan}
Unsupervised Domain Adaptation with Adversarial Residual Transform Networks
Apr 25, 2018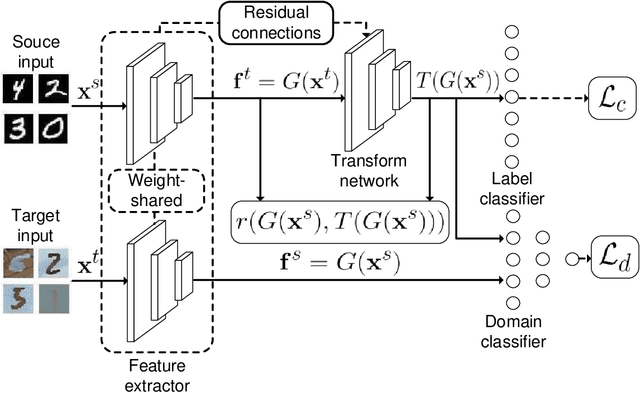
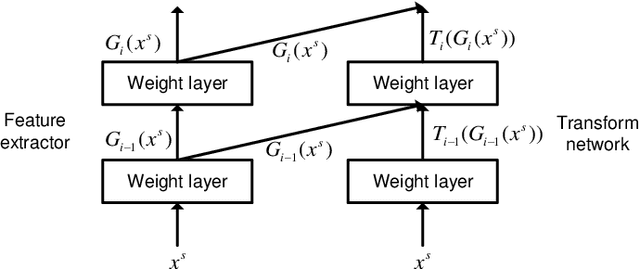

Domain adaptation is widely used in learning problems lacking labels. Recent researches show that deep adversarial domain adaptation models can make markable improvements in performance, which include symmetric and asymmetric architectures. However, the former has poor generalization ability whereas the latter is very hard to train. In this paper, we propose a novel adversarial domain adaptation method named Adversarial Residual Transform Networks (ARTNs) to improve the generalization ability, which directly transforms the source features into the space of target features. In this model, residual connections are used to share features and adversarial loss is reconstructed, thus making the model more generalized and easier to train. Moreover, regularization is added to the loss function to alleviate a vanishing gradient problem, which enables the training process stable. A series of experimental results based on Amazon review dataset, digits datasets and Office-31 image datasets show that the proposed ARTN method greatly outperform the methods of the state-of-the-art.