 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMillion-scale Object Detection with Large Vision Model
Dec 19, 2022Over the past few years, developing a broad, universal, and general-purpose computer vision system has become a hot topic. A powerful universal system would be capable of solving diverse vision tasks simultaneously without being restricted to a specific problem or a specific data domain, which is of great importance in practical real-world computer vision applications. This study pushes the direction forward by concentrating on the million-scale multi-domain universal object detection problem. The problem is not trivial due to its complicated nature in terms of cross-dataset category label duplication, label conflicts, and the hierarchical taxonomy handling. Moreover, what is the resource-efficient way to utilize emerging large pre-trained vision models for million-scale cross-dataset object detection remains an open challenge. This paper tries to address these challenges by introducing our practices in label handling, hierarchy-aware loss design and resource-efficient model training with a pre-trained large model. Our method is ranked second in the object detection track of Robust Vision Challenge 2022 (RVC 2022). We hope our detailed study would serve as an alternative practice paradigm for similar problems in the community. The code is available at https://github.com/linfeng93/Large-UniDet.
Activating the Discriminability of Novel Classes for Few-shot Segmentation
Dec 02, 2022Despite the remarkable success of existing methods for few-shot segmentation, there remain two crucial challenges. First, the feature learning for novel classes is suppressed during the training on base classes in that the novel classes are always treated as background. Thus, the semantics of novel classes are not well learned. Second, most of existing methods fail to consider the underlying semantic gap between the support and the query resulting from the representative bias by the scarce support samples. To circumvent these two challenges, we propose to activate the discriminability of novel classes explicitly in both the feature encoding stage and the prediction stage for segmentation. In the feature encoding stage, we design the Semantic-Preserving Feature Learning module (SPFL) to first exploit and then retain the latent semantics contained in the whole input image, especially those in the background that belong to novel classes. In the prediction stage for segmentation, we learn an Self-Refined Online Foreground-Background classifier (SROFB), which is able to refine itself using the high-confidence pixels of query image to facilitate its adaptation to the query image and bridge the support-query semantic gap. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ datasets demonstrates the advantages of these two novel designs both quantitatively and qualitatively.
Semantic-Aware Local-Global Vision Transformer
Nov 27, 2022



Vision Transformers have achieved remarkable progresses, among which Swin Transformer has demonstrated the tremendous potential of Transformer for vision tasks. It surmounts the key challenge of high computational complexity by performing local self-attention within shifted windows. In this work we propose the Semantic-Aware Local-Global Vision Transformer (SALG), to further investigate two potential improvements towards Swin Transformer. First, unlike Swin Transformer that performs uniform partition to produce equal size of regular windows for local self-attention, our SALG performs semantic segmentation in an unsupervised way to explore the underlying semantic priors in the image. As a result, each segmented region can correspond to a semantically meaningful part in the image, potentially leading to more effective features within each of segmented regions. Second, instead of only performing local self-attention within local windows as Swin Transformer does, the proposed SALG performs both 1) local intra-region self-attention for learning fine-grained features within each region and 2) global inter-region feature propagation for modeling global dependencies among all regions. Consequently, our model is able to obtain the global view when learning features for each token, which is the essential advantage of Transformer. Owing to the explicit modeling of the semantic priors and the proposed local-global modeling mechanism, our SALG is particularly advantageous for small-scale models when the modeling capacity is not sufficient for other models to learn semantics implicitly. Extensive experiments across various vision tasks demonstrates the merit of our model over other vision Transformers, especially in the small-scale modeling scenarios.
UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition
Nov 21, 2022



Multimodal sentiment analysis (MSA) and emotion recognition in conversation (ERC) are key research topics for computers to understand human behaviors. From a psychological perspective, emotions are the expression of affect or feelings during a short period, while sentiments are formed and held for a longer period. However, most existing works study sentiment and emotion separately and do not fully exploit the complementary knowledge behind the two. In this paper, we propose a multimodal sentiment knowledge-sharing framework (UniMSE) that unifies MSA and ERC tasks from features, labels, and models. We perform modality fusion at the syntactic and semantic levels and introduce contrastive learning between modalities and samples to better capture the difference and consistency between sentiments and emotions. Experiments on four public benchmark datasets, MOSI, MOSEI, MELD, and IEMOCAP, demonstrate the effectiveness of the proposed method and achieve consistent improvements compared with state-of-the-art methods.
Learning Modal-Invariant and Temporal-Memory for Video-based Visible-Infrared Person Re-Identification
Aug 04, 2022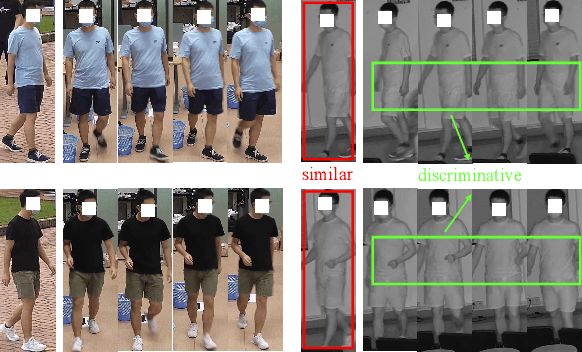


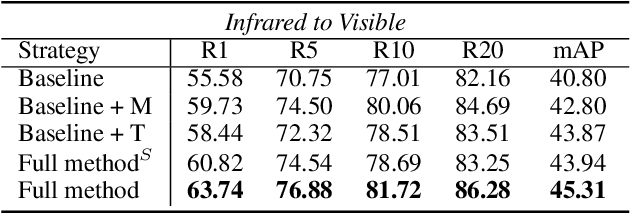
Thanks for the cross-modal retrieval techniques, visible-infrared (RGB-IR) person re-identification (Re-ID) is achieved by projecting them into a common space, allowing person Re-ID in 24-hour surveillance systems. However, with respect to the probe-to-gallery, almost all existing RGB-IR based cross-modal person Re-ID methods focus on image-to-image matching, while the video-to-video matching which contains much richer spatial- and temporal-information remains under-explored. In this paper, we primarily study the video-based cross-modal person Re-ID method. To achieve this task, a video-based RGB-IR dataset is constructed, in which 927 valid identities with 463,259 frames and 21,863 tracklets captured by 12 RGB/IR cameras are collected. Based on our constructed dataset, we prove that with the increase of frames in a tracklet, the performance does meet more enhancement, demonstrating the significance of video-to-video matching in RGB-IR person Re-ID. Additionally, a novel method is further proposed, which not only projects two modalities to a modal-invariant subspace, but also extracts the temporal-memory for motion-invariant. Thanks to these two strategies, much better results are achieved on our video-based cross-modal person Re-ID. The code and dataset are released at: https://github.com/VCMproject233/MITML.
Learning Generalizable Latent Representations for Novel Degradations in Super Resolution
Jul 25, 2022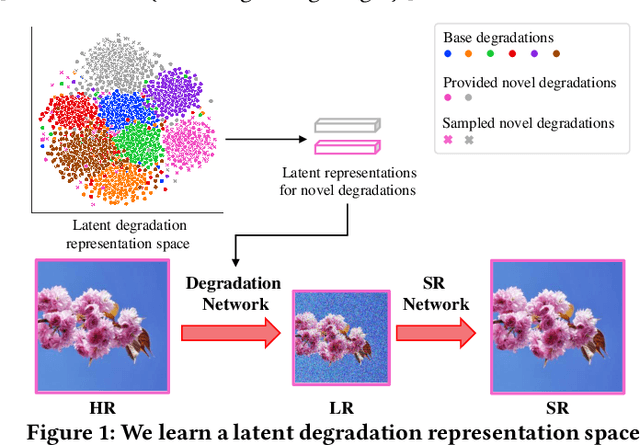

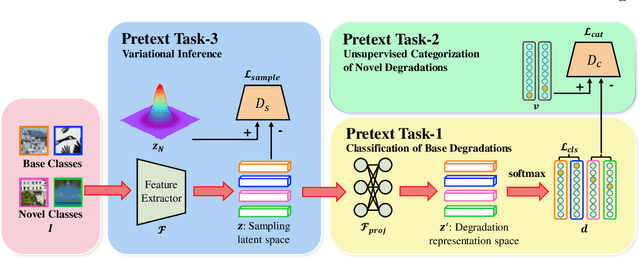
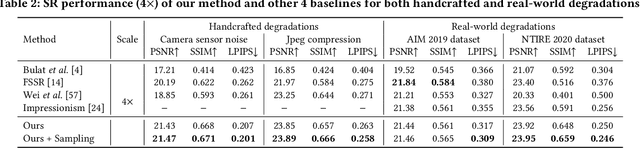
Typical methods for blind image super-resolution (SR) focus on dealing with unknown degradations by directly estimating them or learning the degradation representations in a latent space. A potential limitation of these methods is that they assume the unknown degradations can be simulated by the integration of various handcrafted degradations (e.g., bicubic downsampling), which is not necessarily true. The real-world degradations can be beyond the simulation scope by the handcrafted degradations, which are referred to as novel degradations. In this work, we propose to learn a latent representation space for degradations, which can be generalized from handcrafted (base) degradations to novel degradations. The obtained representations for a novel degradation in this latent space are then leveraged to generate degraded images consistent with the novel degradation to compose paired training data for SR model. Furthermore, we perform variational inference to match the posterior of degradations in latent representation space with a prior distribution (e.g., Gaussian distribution). Consequently, we are able to sample more high-quality representations for a novel degradation to augment the training data for SR model. We conduct extensive experiments on both synthetic and real-world datasets to validate the effectiveness and advantages of our method for blind super-resolution with novel degradations.
Few-Shot Object Detection by Knowledge Distillation Using Bag-of-Visual-Words Representations
Jul 25, 2022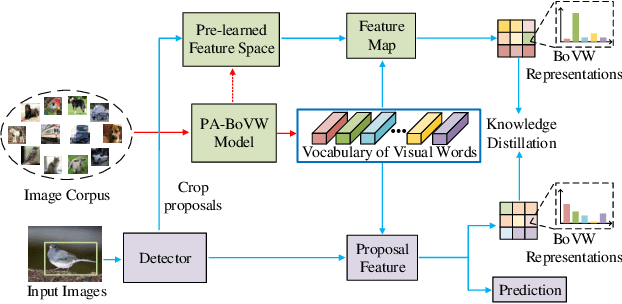
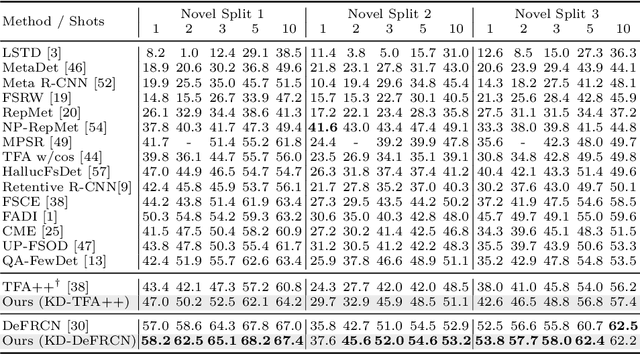
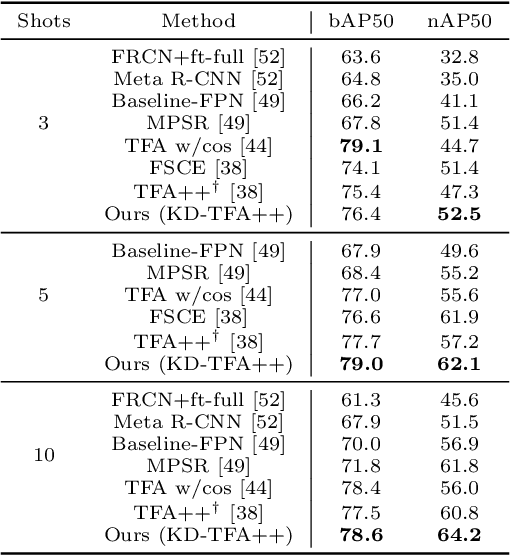

While fine-tuning based methods for few-shot object detection have achieved remarkable progress, a crucial challenge that has not been addressed well is the potential class-specific overfitting on base classes and sample-specific overfitting on novel classes. In this work we design a novel knowledge distillation framework to guide the learning of the object detector and thereby restrain the overfitting in both the pre-training stage on base classes and fine-tuning stage on novel classes. To be specific, we first present a novel Position-Aware Bag-of-Visual-Words model for learning a representative bag of visual words (BoVW) from a limited size of image set, which is used to encode general images based on the similarities between the learned visual words and an image. Then we perform knowledge distillation based on the fact that an image should have consistent BoVW representations in two different feature spaces. To this end, we pre-learn a feature space independently from the object detection, and encode images using BoVW in this space. The obtained BoVW representation for an image can be considered as distilled knowledge to guide the learning of object detector: the extracted features by the object detector for the same image are expected to derive the consistent BoVW representations with the distilled knowledge. Extensive experiments validate the effectiveness of our method and demonstrate the superiority over other state-of-the-art methods.
Multi-Faceted Distillation of Base-Novel Commonality for Few-shot Object Detection
Jul 22, 2022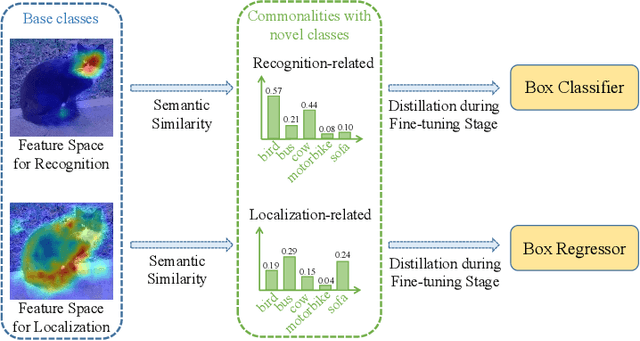
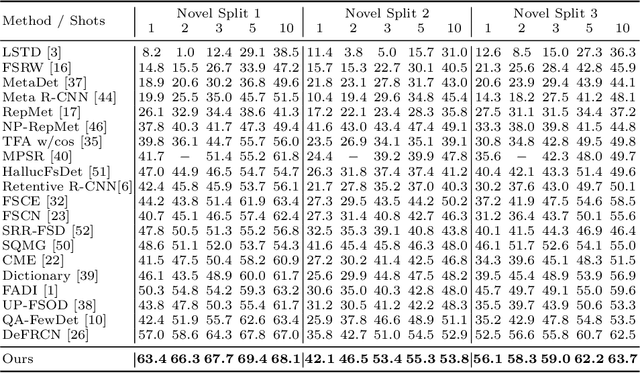
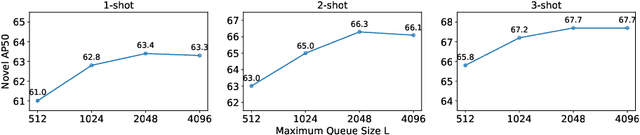
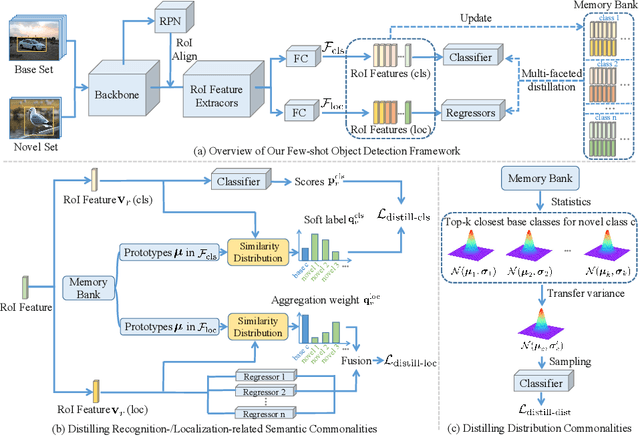
Most of existing methods for few-shot object detection follow the fine-tuning paradigm, which potentially assumes that the class-agnostic generalizable knowledge can be learned and transferred implicitly from base classes with abundant samples to novel classes with limited samples via such a two-stage training strategy. However, it is not necessarily true since the object detector can hardly distinguish between class-agnostic knowledge and class-specific knowledge automatically without explicit modeling. In this work we propose to learn three types of class-agnostic commonalities between base and novel classes explicitly: recognition-related semantic commonalities, localization-related semantic commonalities and distribution commonalities. We design a unified distillation framework based on a memory bank, which is able to perform distillation of all three types of commonalities jointly and efficiently. Extensive experiments demonstrate that our method can be readily integrated into most of existing fine-tuning based methods and consistently improve the performance by a large margin.
Learning Sequence Representations by Non-local Recurrent Neural Memory
Jul 20, 2022
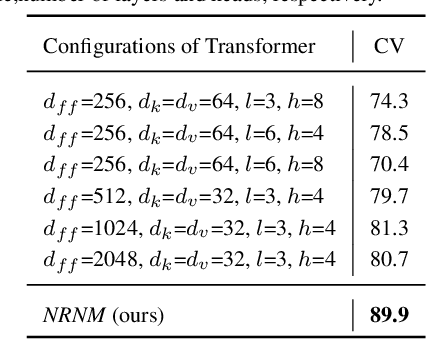
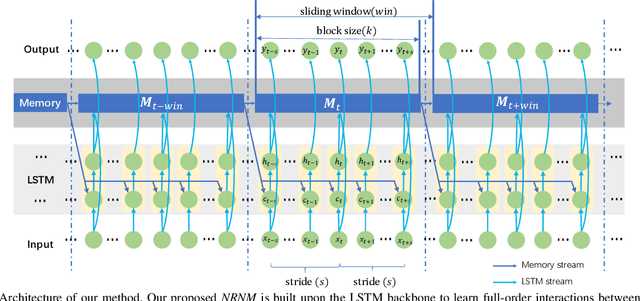
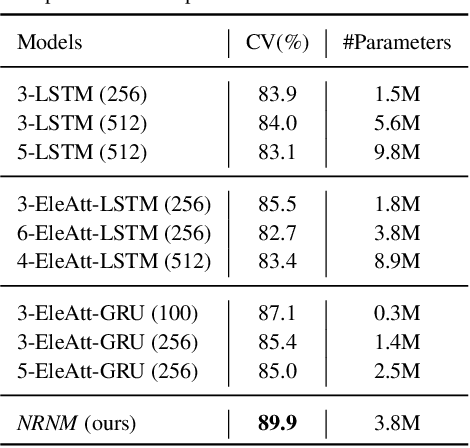
The key challenge of sequence representation learning is to capture the long-range temporal dependencies. Typical methods for supervised sequence representation learning are built upon recurrent neural networks to capture temporal dependencies. One potential limitation of these methods is that they only model one-order information interactions explicitly between adjacent time steps in a sequence, hence the high-order interactions between nonadjacent time steps are not fully exploited. It greatly limits the capability of modeling the long-range temporal dependencies since the temporal features learned by one-order interactions cannot be maintained for a long term due to temporal information dilution and gradient vanishing. To tackle this limitation, we propose the Non-local Recurrent Neural Memory (NRNM) for supervised sequence representation learning, which performs non-local operations \MR{by means of self-attention mechanism} to learn full-order interactions within a sliding temporal memory block and models global interactions between memory blocks in a gated recurrent manner. Consequently, our model is able to capture long-range dependencies. Besides, the latent high-level features contained in high-order interactions can be distilled by our model. We validate the effectiveness and generalization of our NRNM on three types of sequence applications across different modalities, including sequence classification, step-wise sequential prediction and sequence similarity learning. Our model compares favorably against other state-of-the-art methods specifically designed for each of these sequence applications.
Decoupling Recognition from Detection: Single Shot Self-Reliant Scene Text Spotter
Jul 18, 2022

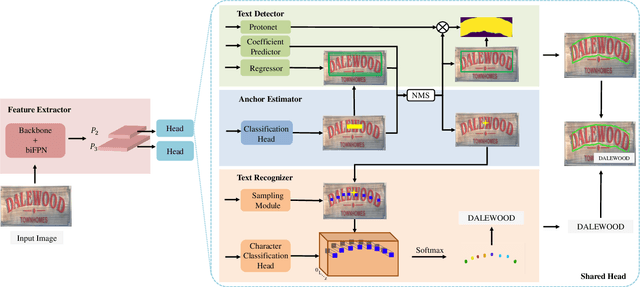

Typical text spotters follow the two-stage spotting strategy: detect the precise boundary for a text instance first and then perform text recognition within the located text region. While such strategy has achieved substantial progress, there are two underlying limitations. 1) The performance of text recognition depends heavily on the precision of text detection, resulting in the potential error propagation from detection to recognition. 2) The RoI cropping which bridges the detection and recognition brings noise from background and leads to information loss when pooling or interpolating from feature maps. In this work we propose the single shot Self-Reliant Scene Text Spotter (SRSTS), which circumvents these limitations by decoupling recognition from detection. Specifically, we conduct text detection and recognition in parallel and bridge them by the shared positive anchor point. Consequently, our method is able to recognize the text instances correctly even though the precise text boundaries are challenging to detect. Additionally, our method reduces the annotation cost for text detection substantially. Extensive experiments on regular-shaped benchmark and arbitrary-shaped benchmark demonstrate that our SRSTS compares favorably to previous state-of-the-art spotters in terms of both accuracy and efficiency.