 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFlare: Scaling Up Draft Capacity for Block Diffusion Speculative Decoding
Jun 01, 2026Block diffusion speculative decoding accelerates LLM inference by predicting all tokens within a block simultaneously for the target model to verify in parallel. Predicting an entire block at once requires a sufficiently capable draft model and effective utilization of the target model's internal knowledge. However, the state-of-the-art method DFlash constrains all draft layers to share a single fused representation derived from only a few target layers, limiting per-layer expressiveness and hindering further scaling of draft capacity. In this paper, we present \modelname, which flares out the narrow conditioning bottleneck of DFlash through a lightweight layer-wise fusion mechanism: each draft layer attends to its own learnable combination of a broad set of target layers at negligible overhead, simultaneously injecting richer target knowledge and providing every draft layer with a distinct input. This enhanced per-layer expressiveness enables scaling the draft model to deeper architectures with consistent gains. We further scale training data from 800K to 2.4M samples to fully exploit the enlarged capacity. On six benchmarks spanning mathematical reasoning, code generation, and conversation, \modelname attains average wall-clock speedups of 5.52x on Qwen3-4B, 5.46x on Qwen3-8B, and 3.91x on GPT-OSS-20B, improving over DFlash by roughly 11\%, 8\%, and 5\% respectively. Our code is available at https://github.com/Tencent/AngelSlim.
Hy-MT2: A Family of Fast, Efficient and Powerful Multilingual Translation Models in the Wild
May 21, 2026Hy-MT2 is a family of fast-thinking multilingual translation models designed for complex real-world scenarios. It includes three model sizes: 1.8B, 7B, and 30B-A3B (MoE), all of which support translation among 33 languages and effectively follow translation instructions in multiple languages. For on-device deployment, with AngelSlim 1.25-bit extreme quantization, the 1.8B model requires only 440 MB of storage and improves inference speed by 1.5x. Multi-dimensional evaluations show that Hy-MT2 delivers outstanding performance across general, real-world business, domain-specific, and instruction-following translation tasks. The 7B and 30B models outperform open-source models such as DeepSeek-V4-Pro and Kimi K2.6 in fast-thinking mode, while the lightweight 1.8B model also surpasses mainstream commercial APIs from providers such as Microsoft and Doubao overall.
SOAR: Scale Optimization for Accurate Reconstruction in NVFP4 Quantization
May 12, 2026NVFP4 has recently emerged as an efficient 4-bit microscaling format for large language models (LLMs), offering superior numerical fidelity with native hardware support. However, existing methods often yield suboptimal performance due to inflexible scale selection and the coupled treatment of quantization and dequantization scales. To address these issues, we propose Scale Optimization for Accurate Reconstruction (SOAR), a novel post-training quantization framework that improves the accuracy of NVFP4 quantization. At its core, SOAR features Closed-form Joint Scale Optimization (CJSO), which jointly optimizes global and block-wise scales via analytical solutions derived from reconstruction error minimization. Furthermore, it incorporates Decoupled Scale Search (DSS). DSS decouples the high-precision quantization scale from its constrained dequantization counterpart, and performs discrete search to mitigate precision loss from scale quantization. Extensive experiments across multiple LLMs show that our method consistently outperforms existing NVFP4 quantization baselines, achieving superior accuracy under the same memory footprint with no additional hardware overhead. The code and models will be available at https://github.com/steven-bao1/SOAR.
IDPruner: Harmonizing Importance and Diversity in Visual Token Pruning for MLLMs
Feb 10, 2026Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities, yet they encounter significant computational bottlenecks due to the massive volume of visual tokens. Consequently, visual token pruning, which substantially reduces the token count, has emerged as a critical technique for accelerating MLLM inference. Existing approaches focus on token importance, diversity, or an intuitive combination of both, without a principled framework for their optimal integration. To address this issue, we first conduct a systematic analysis to characterize the trade-off between token importance and semantic diversity. Guided by this analysis, we propose the \textbf{I}mportance and \textbf{D}iversity Pruner (\textbf{IDPruner}), which leverages the Maximal Marginal Relevance (MMR) algorithm to achieve a Pareto-optimal balance between these two objectives. Crucially, our method operates without requiring attention maps, ensuring full compatibility with FlashAttention and efficient deployment via one-shot pruning. We conduct extensive experiments across various model architectures and multimodal benchmarks, demonstrating that IDPruner achieves state-of-the-art performance and superior generalization across diverse architectures and tasks. Notably, on Qwen2.5-VL-7B-Instruct, IDPruner retains 95.18\% of baseline performance when pruning 75\% of the tokens, and still maintains 86.40\% even under an extreme 90\% pruning ratio. Our code is available at https://github.com/Tencent/AngelSlim.
Sherry: Hardware-Efficient 1.25-Bit Ternary Quantization via Fine-grained Sparsification
Jan 12, 2026The deployment of Large Language Models (LLMs) on resource-constrained edge devices is increasingly hindered by prohibitive memory and computational requirements. While ternary quantization offers a compelling solution by reducing weights to {-1, 0, +1}, current implementations suffer from a fundamental misalignment with commodity hardware. Most existing methods must choose between 2-bit aligned packing, which incurs significant bit wastage, or 1.67-bit irregular packing, which degrades inference speed. To resolve this tension, we propose Sherry, a hardware-efficient ternary quantization framework. Sherry introduces a 3:4 fine-grained sparsity that achieves a regularized 1.25-bit width by packing blocks of four weights into five bits, restoring power-of-two alignment. Furthermore, we identify weight trapping issue in sparse ternary training, which leads to representational collapse. To address this, Sherry introduces Arenas, an annealing residual synapse mechanism that maintains representational diversity during training. Empirical evaluations on LLaMA-3.2 across five benchmarks demonstrate that Sherry matches state-of-the-art ternary performance while significantly reducing model size. Notably, on an Intel i7-14700HX CPU, our 1B model achieves zero accuracy loss compared to SOTA baselines while providing 25% bit savings and 10% speed up. The code is available at https://github.com/Tencent/AngelSlim .
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices
Nov 01, 2021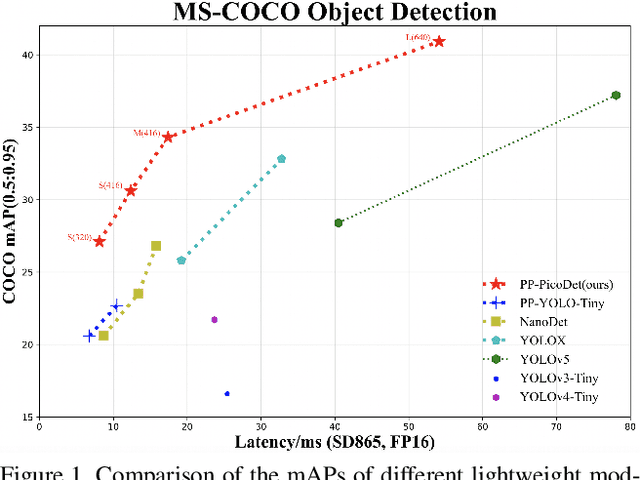
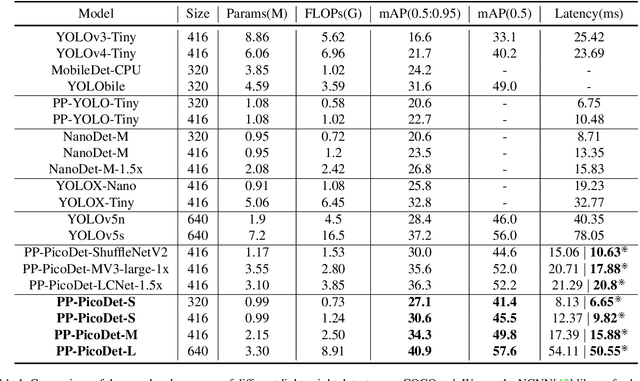
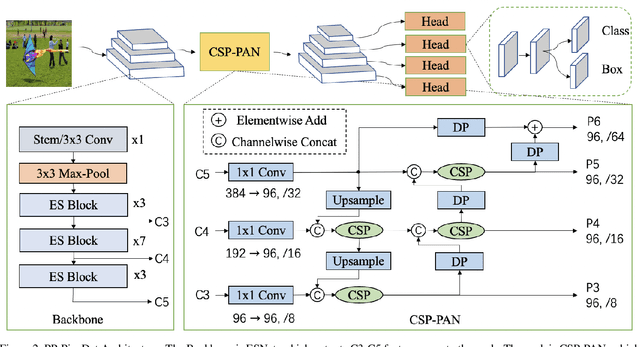
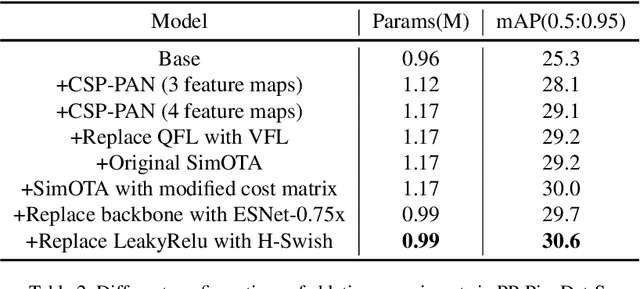
The better accuracy and efficiency trade-off has been a challenging problem in object detection. In this work, we are dedicated to studying key optimizations and neural network architecture choices for object detection to improve accuracy and efficiency. We investigate the applicability of the anchor-free strategy on lightweight object detection models. We enhance the backbone structure and design the lightweight structure of the neck, which improves the feature extraction ability of the network. We improve label assignment strategy and loss function to make training more stable and efficient. Through these optimizations, we create a new family of real-time object detectors, named PP-PicoDet, which achieves superior performance on object detection for mobile devices. Our models achieve better trade-offs between accuracy and latency compared to other popular models. PicoDet-S with only 0.99M parameters achieves 30.6% mAP, which is an absolute 4.8% improvement in mAP while reducing mobile CPU inference latency by 55% compared to YOLOX-Nano, and is an absolute 7.1% improvement in mAP compared to NanoDet. It reaches 123 FPS (150 FPS using Paddle Lite) on mobile ARM CPU when the input size is 320. PicoDet-L with only 3.3M parameters achieves 40.9% mAP, which is an absolute 3.7% improvement in mAP and 44% faster than YOLOv5s. As shown in Figure 1, our models far outperform the state-of-the-art results for lightweight object detection. Code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection.