 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Causal Scene Refinement for Video Question Answering
May 07, 2023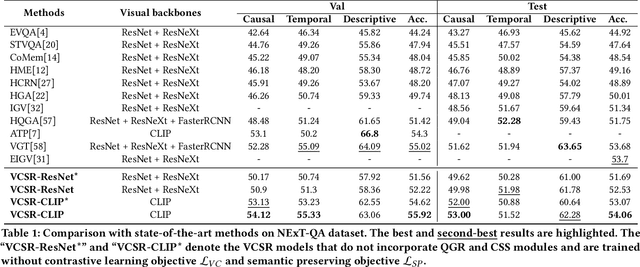
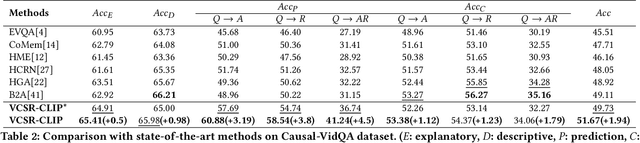
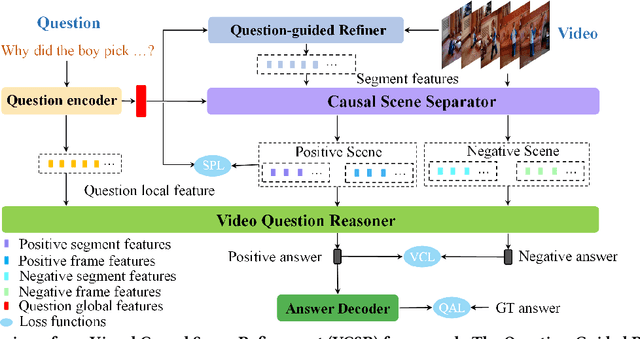
Existing methods for video question answering (VideoQA) often suffer from spurious correlations between different modalities, leading to a failure in identifying the dominant visual evidence and the intended question. Moreover, these methods function as black boxes, making it difficult to interpret the visual scene during the QA process. In this paper, to discover critical video segments and frames that serve as the visual causal scene for generating reliable answers, we present a causal analysis of VideoQA and propose a framework for cross-modal causal relational reasoning, named Visual Causal Scene Refinement (VCSR). Particularly, a set of causal front-door intervention operations is introduced to explicitly find the visual causal scenes at both segment and frame levels. Our VCSR involves two essential modules: i) the Question-Guided Refiner (QGR) module, which refines consecutive video frames guided by the question semantics to obtain more representative segment features for causal front-door intervention; ii) the Causal Scene Separator (CSS) module, which discovers a collection of visual causal and non-causal scenes based on the visual-linguistic causal relevance and estimates the causal effect of the scene-separating intervention in a contrastive learning manner. Extensive experiments on the NExT-QA, Causal-VidQA, and MSRVTT-QA datasets demonstrate the superiority of our VCSR in discovering visual causal scene and achieving robust video question answering.
SCoDA: Domain Adaptive Shape Completion for Real Scans
Apr 24, 20233D shape completion from point clouds is a challenging task, especially from scans of real-world objects. Considering the paucity of 3D shape ground truths for real scans, existing works mainly focus on benchmarking this task on synthetic data, e.g. 3D computer-aided design models. However, the domain gap between synthetic and real data limits the generalizability of these methods. Thus, we propose a new task, SCoDA, for the domain adaptation of real scan shape completion from synthetic data. A new dataset, ScanSalon, is contributed with a bunch of elaborate 3D models created by skillful artists according to scans. To address this new task, we propose a novel cross-domain feature fusion method for knowledge transfer and a novel volume-consistent self-training framework for robust learning from real data. Extensive experiments prove our method is effective to bring an improvement of 6%~7% mIoU.
Causality-aware Visual Scene Discovery for Cross-Modal Question Reasoning
Apr 17, 2023Existing visual question reasoning methods usually fail to explicitly discover the inherent causal mechanism and ignore the complex event-level understanding that requires jointly modeling cross-modal event temporality and causality. In this paper, we propose an event-level visual question reasoning framework named Cross-Modal Question Reasoning (CMQR), to explicitly discover temporal causal structure and mitigate visual spurious correlation by causal intervention. To explicitly discover visual causal structure, the Visual Causality Discovery (VCD) architecture is proposed to find question-critical scene temporally and disentangle the visual spurious correlations by attention-based front-door causal intervention module named Local-Global Causal Attention Module (LGCAM). To align the fine-grained interactions between linguistic semantics and spatial-temporal representations, we build an Interactive Visual-Linguistic Transformer (IVLT) that builds the multi-modal co-occurrence interactions between visual and linguistic content. Extensive experiments on four datasets demonstrate the superiority of CMQR for discovering visual causal structures and achieving robust question reasoning.
Urban Regional Function Guided Traffic Flow Prediction
Mar 20, 2023



The prediction of traffic flow is a challenging yet crucial problem in spatial-temporal analysis, which has recently gained increasing interest. In addition to spatial-temporal correlations, the functionality of urban areas also plays a crucial role in traffic flow prediction. However, the exploration of regional functional attributes mainly focuses on adding additional topological structures, ignoring the influence of functional attributes on regional traffic patterns. Different from the existing works, we propose a novel module named POI-MetaBlock, which utilizes the functionality of each region (represented by Point of Interest distribution) as metadata to further mine different traffic characteristics in areas with different functions. Specifically, the proposed POI-MetaBlock employs a self-attention architecture and incorporates POI and time information to generate dynamic attention parameters for each region, which enables the model to fit different traffic patterns of various areas at different times. Furthermore, our lightweight POI-MetaBlock can be easily integrated into conventional traffic flow prediction models. Extensive experiments demonstrate that our module significantly improves the performance of traffic flow prediction and outperforms state-of-the-art methods that use metadata.
Visual-Linguistic Causal Intervention for Radiology Report Generation
Mar 16, 2023



Automatic radiology report generation is essential for computer-aided diagnosis and medication guidance. Importantly, automatic radiology report generation (RRG) can relieve the heavy burden of radiologists by generating medical reports automatically from visual-linguistic data relations. However, due to the spurious correlations within image-text data induced by visual and linguistic biases, it is challenging to generate accurate reports that reliably describe abnormalities. Besides, the cross-modal confounder is usually unobservable and difficult to be eliminated explicitly. In this paper, we mitigate the cross-modal data bias for RRG from a new perspective, i.e., visual-linguistic causal intervention, and propose a novel Visual-Linguistic Causal Intervention (VLCI) framework for RRG, which consists of a visual deconfounding module (VDM) and a linguistic deconfounding module (LDM), to implicitly deconfound the visual-linguistic confounder by causal front-door intervention. Specifically, the VDM explores and disentangles the visual confounder from the patch-based local and global features without object detection due to the absence of universal clinic semantic extraction. Simultaneously, the LDM eliminates the linguistic confounder caused by salient visual features and high-frequency context without constructing specific dictionaries. Extensive experiments on IU-Xray and MIMIC-CXR datasets show that our VLCI outperforms the state-of-the-art RRG methods significantly. Source code and models are available at https://github.com/WissingChen/VLCI.
Structure Embedded Nucleus Classification for Histopathology Images
Feb 22, 2023



Nuclei classification provides valuable information for histopathology image analysis. However, the large variations in the appearance of different nuclei types cause difficulties in identifying nuclei. Most neural network based methods are affected by the local receptive field of convolutions, and pay less attention to the spatial distribution of nuclei or the irregular contour shape of a nucleus. In this paper, we first propose a novel polygon-structure feature learning mechanism that transforms a nucleus contour into a sequence of points sampled in order, and employ a recurrent neural network that aggregates the sequential change in distance between key points to obtain learnable shape features. Next, we convert a histopathology image into a graph structure with nuclei as nodes, and build a graph neural network to embed the spatial distribution of nuclei into their representations. To capture the correlations between the categories of nuclei and their surrounding tissue patterns, we further introduce edge features that are defined as the background textures between adjacent nuclei. Lastly, we integrate both polygon and graph structure learning mechanisms into a whole framework that can extract intra and inter-nucleus structural characteristics for nuclei classification. Experimental results show that the proposed framework achieves significant improvements compared to the state-of-the-art methods.
Towards Unifying Medical Vision-and-Language Pre-training via Soft Prompts
Feb 17, 2023Medical vision-and-language pre-training (Med-VLP) has shown promising improvements on many downstream medical tasks owing to its applicability to extracting generic representations from medical images and texts. Practically, there exist two typical types, \textit{i.e.}, the fusion-encoder type and the dual-encoder type, depending on whether a heavy fusion module is used. The former is superior at multi-modal tasks owing to the sufficient interaction between modalities; the latter is good at uni-modal and cross-modal tasks due to the single-modality encoding ability. To take advantage of these two types, we propose an effective yet straightforward scheme named PTUnifier to unify the two types. We first unify the input format by introducing visual and textual prompts, which serve as a feature bank that stores the most representative images/texts. By doing so, a single model could serve as a \textit{foundation model} that processes various tasks adopting different input formats (\textit{i.e.}, image-only, text-only, and image-text-pair). Furthermore, we construct a prompt pool (instead of static ones) to improve diversity and scalability. Experimental results show that our approach achieves state-of-the-art results on a broad range of tasks, spanning uni-modal tasks (\textit{i.e.}, image/text classification and text summarization), cross-modal tasks (\textit{i.e.}, image-to-text generation and image-text/text-image retrieval), and multi-modal tasks (\textit{i.e.}, visual question answering), demonstrating the effectiveness of our approach. Note that the adoption of prompts is orthogonal to most existing Med-VLP approaches and could be a beneficial and complementary extension to these approaches.
Self-Supervised Correction Learning for Semi-Supervised Biomedical Image Segmentation
Jan 12, 2023Biomedical image segmentation plays a significant role in computer-aided diagnosis. However, existing CNN based methods rely heavily on massive manual annotations, which are very expensive and require huge human resources. In this work, we adopt a coarse-to-fine strategy and propose a self-supervised correction learning paradigm for semi-supervised biomedical image segmentation. Specifically, we design a dual-task network, including a shared encoder and two independent decoders for segmentation and lesion region inpainting, respectively. In the first phase, only the segmentation branch is used to obtain a relatively rough segmentation result. In the second step, we mask the detected lesion regions on the original image based on the initial segmentation map, and send it together with the original image into the network again to simultaneously perform inpainting and segmentation separately. For labeled data, this process is supervised by the segmentation annotations, and for unlabeled data, it is guided by the inpainting loss of masked lesion regions. Since the two tasks rely on similar feature information, the unlabeled data effectively enhances the representation of the network to the lesion regions and further improves the segmentation performance. Moreover, a gated feature fusion (GFF) module is designed to incorporate the complementary features from the two tasks. Experiments on three medical image segmentation datasets for different tasks including polyp, skin lesion and fundus optic disc segmentation well demonstrate the outstanding performance of our method compared with other semi-supervised approaches. The code is available at https://github.com/ReaFly/SemiMedSeg.
Adaptive Context Selection for Polyp Segmentation
Jan 12, 2023Accurate polyp segmentation is of great significance for the diagnosis and treatment of colorectal cancer. However, it has always been very challenging due to the diverse shape and size of polyp. In recent years, state-of-the-art methods have achieved significant breakthroughs in this task with the help of deep convolutional neural networks. However, few algorithms explicitly consider the impact of the size and shape of the polyp and the complex spatial context on the segmentation performance, which results in the algorithms still being powerless for complex samples. In fact, segmentation of polyps of different sizes relies on different local and global contextual information for regional contrast reasoning. To tackle these issues, we propose an adaptive context selection based encoder-decoder framework which is composed of Local Context Attention (LCA) module, Global Context Module (GCM) and Adaptive Selection Module (ASM). Specifically, LCA modules deliver local context features from encoder layers to decoder layers, enhancing the attention to the hard region which is determined by the prediction map of previous layer. GCM aims to further explore the global context features and send to the decoder layers. ASM is used for adaptive selection and aggregation of context features through channel-wise attention. Our proposed approach is evaluated on the EndoScene and Kvasir-SEG Datasets, and shows outstanding performance compared with other state-of-the-art methods. The code is available at https://github.com/ReaFly/ACSNet.
Lesion-aware Dynamic Kernel for Polyp Segmentation
Jan 12, 2023Automatic and accurate polyp segmentation plays an essential role in early colorectal cancer diagnosis. However, it has always been a challenging task due to 1) the diverse shape, size, brightness and other appearance characteristics of polyps, 2) the tiny contrast between concealed polyps and their surrounding regions. To address these problems, we propose a lesion-aware dynamic network (LDNet) for polyp segmentation, which is a traditional u-shape encoder-decoder structure incorporated with a dynamic kernel generation and updating scheme. Specifically, the designed segmentation head is conditioned on the global context features of the input image and iteratively updated by the extracted lesion features according to polyp segmentation predictions. This simple but effective scheme endows our model with powerful segmentation performance and generalization capability. Besides, we utilize the extracted lesion representation to enhance the feature contrast between the polyp and background regions by a tailored lesion-aware cross-attention module (LCA), and design an efficient self-attention module (ESA) to capture long-range context relations, further improving the segmentation accuracy. Extensive experiments on four public polyp benchmarks and our collected large-scale polyp dataset demonstrate the superior performance of our method compared with other state-of-the-art approaches. The source code is available at https://github.com/ReaFly/LDNet.