 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Benefit from User and Item Embeddings in Recommendation Tasks?
Jan 08, 2026Large Language Models (LLMs) have emerged as promising recommendation systems, offering novel ways to model user preferences through generative approaches. However, many existing methods often rely solely on text semantics or incorporate collaborative signals in a limited manner, typically using only user or item embeddings. These methods struggle to handle multiple item embeddings representing user history, reverting to textual semantics and neglecting richer collaborative information. In this work, we propose a simple yet effective solution that projects user and item embeddings, learned from collaborative filtering, into the LLM token space via separate lightweight projector modules. A finetuned LLM then conditions on these projected embeddings alongside textual tokens to generate recommendations. Preliminary results show that this design effectively leverages structured user-item interaction data, improves recommendation performance over text-only LLM baselines, and offers a practical path for bridging traditional recommendation systems with modern LLMs.
Were RNNs All We Needed?
Oct 02, 2024



The scalability limitations of Transformers regarding sequence length have renewed interest in recurrent sequence models that are parallelizable during training. As a result, many novel recurrent architectures, such as S4, Mamba, and Aaren, have been proposed that achieve comparable performance. In this work, we revisit traditional recurrent neural networks (RNNs) from over a decade ago: LSTMs (1997) and GRUs (2014). While these models were slow due to requiring to backpropagate through time (BPTT), we show that by removing their hidden state dependencies from their input, forget, and update gates, LSTMs and GRUs no longer need to BPTT and can be efficiently trained in parallel. Building on this, we introduce minimal versions (minLSTMs and minGRUs) that (1) use significantly fewer parameters than their traditional counterparts and (2) are fully parallelizable during training (175x faster for a sequence of length 512). Lastly, we show that these stripped-down versions of decade-old RNNs match the empirical performance of recent sequence models.
Attention as an RNN
May 22, 2024



The advent of Transformers marked a significant breakthrough in sequence modelling, providing a highly performant architecture capable of leveraging GPU parallelism. However, Transformers are computationally expensive at inference time, limiting their applications, particularly in low-resource settings (e.g., mobile and embedded devices). Addressing this, we (1) begin by showing that attention can be viewed as a special Recurrent Neural Network (RNN) with the ability to compute its \textit{many-to-one} RNN output efficiently. We then (2) show that popular attention-based models such as Transformers can be viewed as RNN variants. However, unlike traditional RNNs (e.g., LSTMs), these models cannot be updated efficiently with new tokens, an important property in sequence modelling. Tackling this, we (3) introduce a new efficient method of computing attention's \textit{many-to-many} RNN output based on the parallel prefix scan algorithm. Building on the new attention formulation, we (4) introduce \textbf{Aaren}, an attention-based module that can not only (i) be trained in parallel (like Transformers) but also (ii) be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs). Empirically, we show Aarens achieve comparable performance to Transformers on $38$ datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks while being more time and memory-efficient.
Tree Cross Attention
Sep 29, 2023



Cross Attention is a popular method for retrieving information from a set of context tokens for making predictions. At inference time, for each prediction, Cross Attention scans the full set of $\mathcal{O}(N)$ tokens. In practice, however, often only a small subset of tokens are required for good performance. Methods such as Perceiver IO are cheap at inference as they distill the information to a smaller-sized set of latent tokens $L < N$ on which cross attention is then applied, resulting in only $\mathcal{O}(L)$ complexity. However, in practice, as the number of input tokens and the amount of information to distill increases, the number of latent tokens needed also increases significantly. In this work, we propose Tree Cross Attention (TCA) - a module based on Cross Attention that only retrieves information from a logarithmic $\mathcal{O}(\log(N))$ number of tokens for performing inference. TCA organizes the data in a tree structure and performs a tree search at inference time to retrieve the relevant tokens for prediction. Leveraging TCA, we introduce ReTreever, a flexible architecture for token-efficient inference. We show empirically that Tree Cross Attention (TCA) performs comparable to Cross Attention across various classification and uncertainty regression tasks while being significantly more token-efficient. Furthermore, we compare ReTreever against Perceiver IO, showing significant gains while using the same number of tokens for inference.
Constant Memory Attention Block
Jun 21, 2023



Modern foundation model architectures rely on attention mechanisms to effectively capture context. However, these methods require linear or quadratic memory in terms of the number of inputs/datapoints, limiting their applicability in low-compute domains. In this work, we propose Constant Memory Attention Block (CMAB), a novel general-purpose attention block that computes its output in constant memory and performs updates in constant computation. Highlighting CMABs efficacy, we introduce methods for Neural Processes and Temporal Point Processes. Empirically, we show our proposed methods achieve results competitive with state-of-the-art while being significantly more memory efficient.
Constant Memory Attentive Neural Processes
May 23, 2023



Neural Processes (NPs) are efficient methods for estimating predictive uncertainties. NPs comprise of a conditioning phase where a context dataset is encoded, a querying phase where the model makes predictions using the context dataset encoding, and an updating phase where the model updates its encoding with newly received datapoints. However, state-of-the-art methods require additional memory which scales linearly or quadratically with the size of the dataset, limiting their applications, particularly in low-resource settings. In this work, we propose Constant Memory Attentive Neural Processes (CMANPs), an NP variant which only requires constant memory for the conditioning, querying, and updating phases. In building CMANPs, we propose Constant Memory Attention Block (CMAB), a novel general-purpose attention block that can compute its output in constant memory and perform updates in constant computation. Empirically, we show CMANPs achieve state-of-the-art results on meta-regression and image completion tasks while being (1) significantly more memory efficient than prior methods and (2) more scalable to harder settings.
Meta Temporal Point Processes
Jan 27, 2023



A temporal point process (TPP) is a stochastic process where its realization is a sequence of discrete events in time. Recent work in TPPs model the process using a neural network in a supervised learning framework, where a training set is a collection of all the sequences. In this work, we propose to train TPPs in a meta learning framework, where each sequence is treated as a different task, via a novel framing of TPPs as neural processes (NPs). We introduce context sets to model TPPs as an instantiation of NPs. Motivated by attentive NP, we also introduce local history matching to help learn more informative features. We demonstrate the potential of the proposed method on popular public benchmark datasets and tasks, and compare with state-of-the-art TPP methods.
Gumbel-Softmax Selective Networks
Nov 19, 2022


ML models often operate within the context of a larger system that can adapt its response when the ML model is uncertain, such as falling back on safe defaults or a human in the loop. This commonly encountered operational context calls for principled techniques for training ML models with the option to abstain from predicting when uncertain. Selective neural networks are trained with an integrated option to abstain, allowing them to learn to recognize and optimize for the subset of the data distribution for which confident predictions can be made. However, optimizing selective networks is challenging due to the non-differentiability of the binary selection function (the discrete decision of whether to predict or abstain). This paper presents a general method for training selective networks that leverages the Gumbel-softmax reparameterization trick to enable selection within an end-to-end differentiable training framework. Experiments on public datasets demonstrate the potential of Gumbel-softmax selective networks for selective regression and classification.
Latent Bottlenecked Attentive Neural Processes
Nov 15, 2022



Neural Processes (NPs) are popular methods in meta-learning that can estimate predictive uncertainty on target datapoints by conditioning on a context dataset. Previous state-of-the-art method Transformer Neural Processes (TNPs) achieve strong performance but require quadratic computation with respect to the number of context datapoints, significantly limiting its scalability. Conversely, existing sub-quadratic NP variants perform significantly worse than that of TNPs. Tackling this issue, we propose Latent Bottlenecked Attentive Neural Processes (LBANPs), a new computationally efficient sub-quadratic NP variant, that has a querying computational complexity independent of the number of context datapoints. The model encodes the context dataset into a constant number of latent vectors on which self-attention is performed. When making predictions, the model retrieves higher-order information from the context dataset via multiple cross-attention mechanisms on the latent vectors. We empirically show that LBANPs achieve results competitive with the state-of-the-art on meta-regression, image completion, and contextual multi-armed bandits. We demonstrate that LBANPs can trade-off the computational cost and performance according to the number of latent vectors. Finally, we show LBANPs can scale beyond existing attention-based NP variants to larger dataset settings.
Stop Overcomplicating Selective Classification: Use Max-Logit
Jun 17, 2022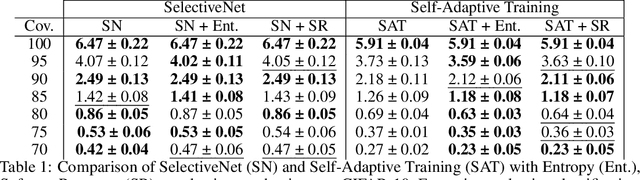
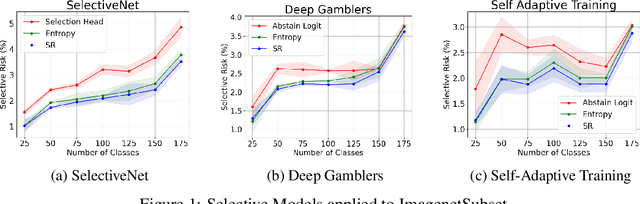
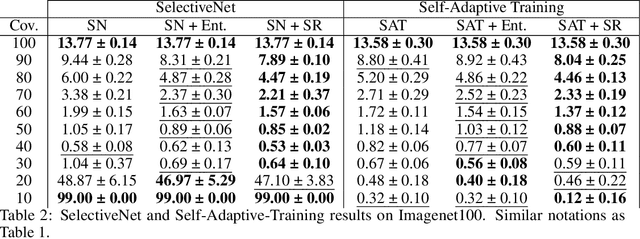
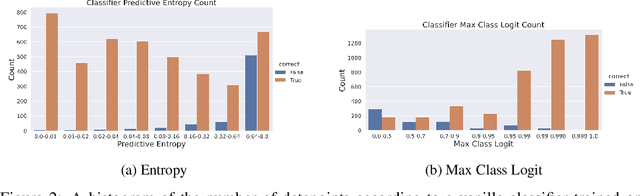
We tackle the problem of Selective Classification where the goal is to achieve the best performance on the desired coverages of the dataset. Recent state-of-the-art selective methods come with architectural changes either via introducing a separate selection head or an extra abstention logit. In this paper, we present surprising results for Selective Classification by confirming that the superior performance of state-of-the-art methods is owed to training a more generalizable classifier; however, their selection mechanism is suboptimal. We argue that the selection mechanism should be rooted in the objective function instead of a separately calculated score. Accordingly, in this paper, we motivate an alternative selection strategy that is based on the cross entropy loss for the classification settings, namely, max of the logits. Our proposed selection strategy achieves better results by a significant margin, consistently, across all coverages and all datasets, without any additional computation. Finally, inspired by our superior selection mechanism, we propose to further regularize the objective function with entropy-minimization. Our proposed max-logit selection with the modified loss function achieves new state-of-the-art results for Selective Classification.