 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Latent Process Flows
Jun 29, 2021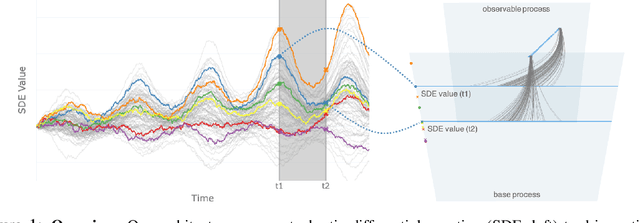
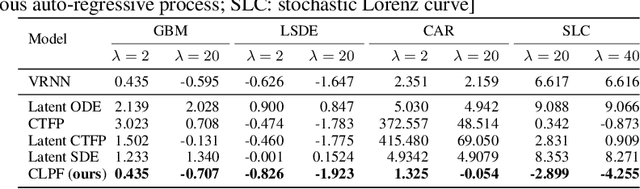
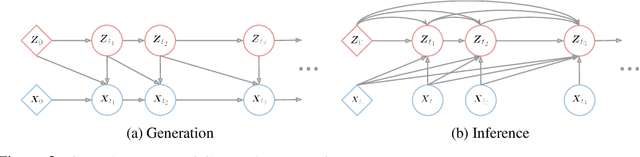
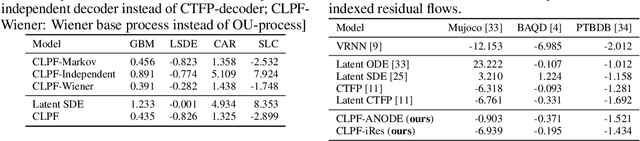
Partial observations of continuous time-series dynamics at arbitrary time stamps exist in many disciplines. Fitting this type of data using statistical models with continuous dynamics is not only promising at an intuitive level but also has practical benefits, including the ability to generate continuous trajectories and to perform inference on previously unseen time stamps. Despite exciting progress in this area, the existing models still face challenges in terms of their representational power and the quality of their variational approximations. We tackle these challenges with continuous latent process flows (CLPF), a principled architecture decoding continuous latent processes into continuous observable processes using a time-dependent normalizing flow driven by a stochastic differential equation. To optimize our model using maximum likelihood, we propose a novel piecewise construction of a variational posterior process and derive the corresponding variational lower bound using trajectory re-weighting. Our ablation studies demonstrate the effectiveness of our contributions in various inference tasks on irregular time grids. Comparisons to state-of-the-art baselines show our model's favourable performance on both synthetic and real-world time-series data.
Unsupervised Video Decomposition using Spatio-temporal Iterative Inference
Jun 25, 2020
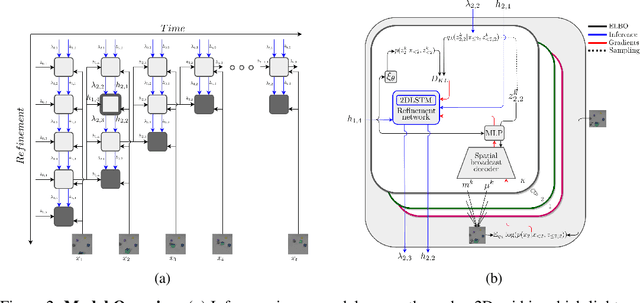
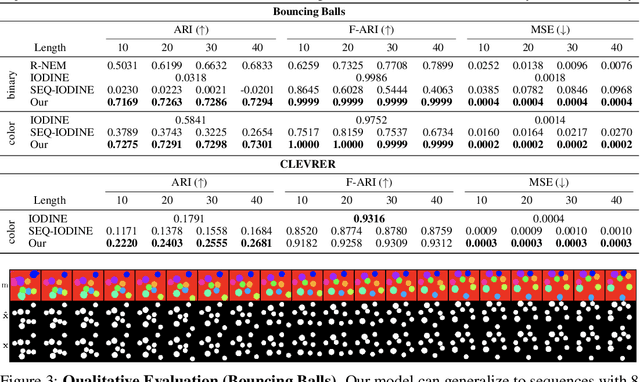
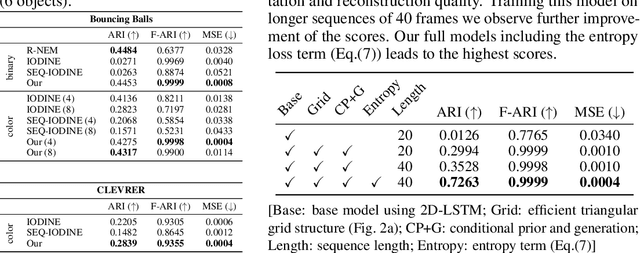
Unsupervised multi-object scene decomposition is a fast-emerging problem in representation learning. Despite significant progress in static scenes, such models are unable to leverage important dynamic cues present in video. We propose a novel spatio-temporal iterative inference framework that is powerful enough to jointly model complex multi-object representations and explicit temporal dependencies between latent variables across frames. This is achieved by leveraging 2D-LSTM, temporally conditioned inference and generation within the iterative amortized inference for posterior refinement. Our method improves the overall quality of decompositions, encodes information about the objects' dynamics, and can be used to predict trajectories of each object separately. Additionally, we show that our model has a high accuracy even without color information. We demonstrate the decomposition, segmentation, and prediction capabilities of our model and show that it outperforms the state-of-the-art on several benchmark datasets, one of which was curated for this work and will be made publicly available.
Structural Decompositions for End-to-End Relighting
Jun 07, 2019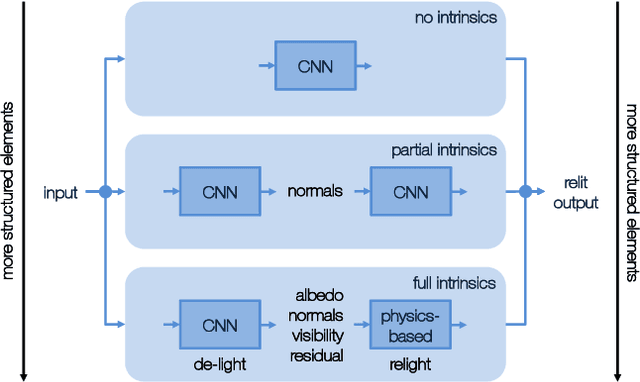
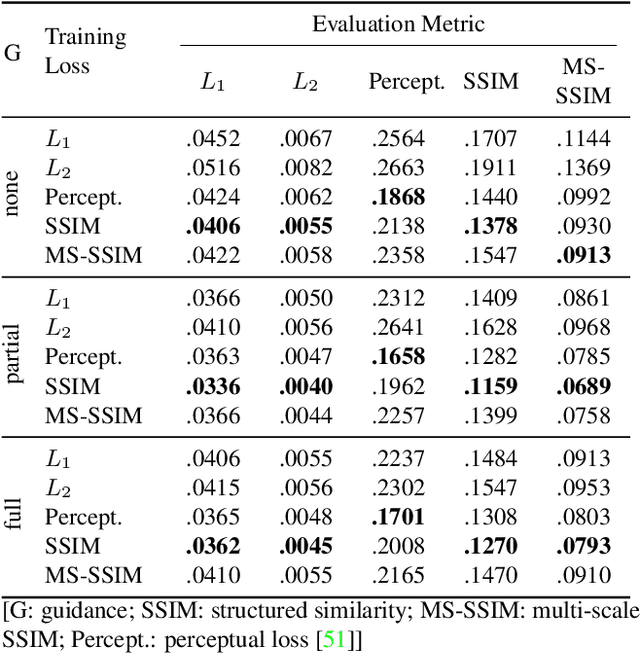

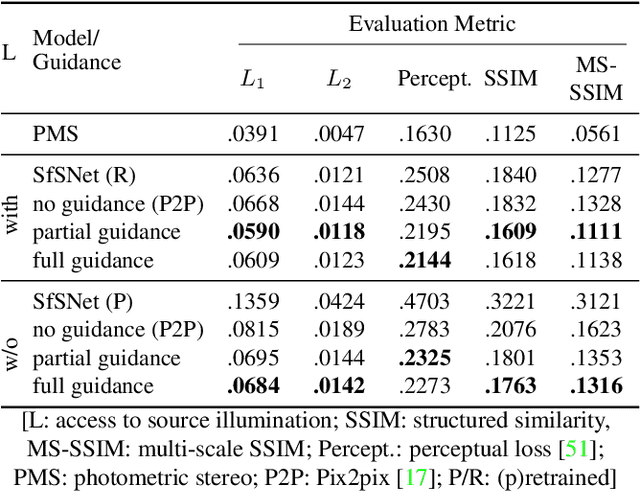
Relighting is an essential step in artificially transferring an object from one image into another environment. For example, a believable teleconference in Augmented Reality requires a portrait recorded in the source environment to be displayed and relit consistent with the light configuration of the destination scene. In this paper, we investigate architectures for learning to both de-light and relight an image of a human face end-to-end. The architectures vary in how much they enforce physically-based image formation and rendering constraints. The most structured model decomposes the input image into intrinsic components according to a diffuse physics-based image formation model and augments the render to relight including non-diffuse effects. An intermediate model uses fewer intrinsic constraints and the least structured model makes no assumptions on the image formation. To train our models and evaluate the approach, we collected portraits of 21 subjects with various expressions and poses, each in a sequence of 32 individual light sources in a controlled light stage setup. Our method leads to precise and believable relighting results in challenging illumination conditions and poses, including when the subject is facing away from the camera. We compare our method to state-of-the-art relighting approaches and illustrate its superiority in a series of quantitative and qualitative experiments.
Towards Traversing the Continuous Spectrum of Image Retrieval
Dec 01, 2018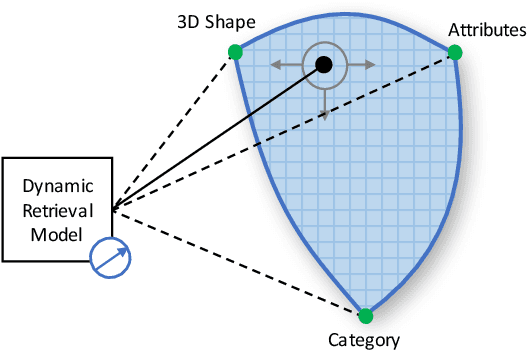
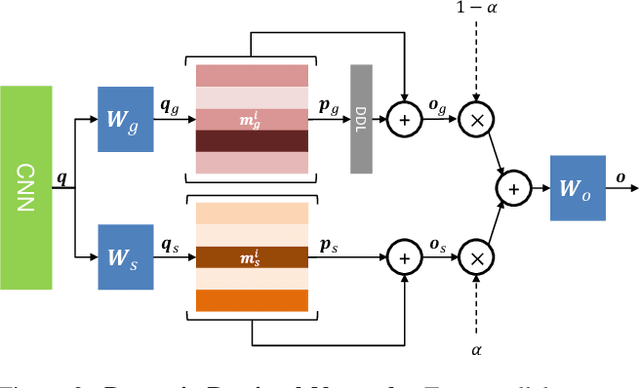
Image retrieval is one of the most popular tasks in computer vision. However, the proposed approaches in the literature can be roughly categorized into two groups: category- and instance-based retrieval. In this work, we show that the retrieval task is much richer and more complex, and can be viewed as a continuous spectrum spanning the space among these operational points. Hence, we propose to tackle a novel retrieval task where we want to smoothly traverse the simplex from category- to instance- and attribute-based retrieval. We propose a novel deep network architecture that learns to decompose an input query image into its basic components of categorical and attribute information. Moreover, using a continuous control parameter, our model learns to reconstruct a new embedding of the query by mixing these two signals, with different proportions, to target a specific point along the retrieval simplex. We demonstrate our idea in a detailed evaluation of the proposed model and highlight the advantages of our approach against a set of well-established retrieval model baselines.