 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarCLR: Variable Semantic Representation Pre-training via Contrastive Learning
Dec 05, 2021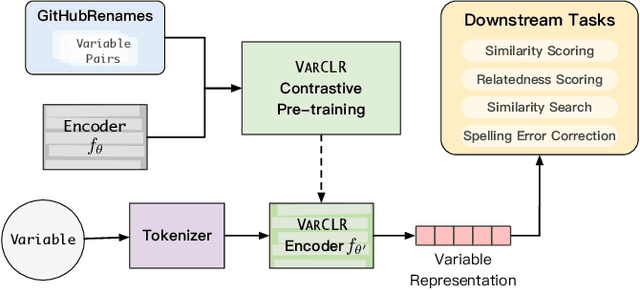
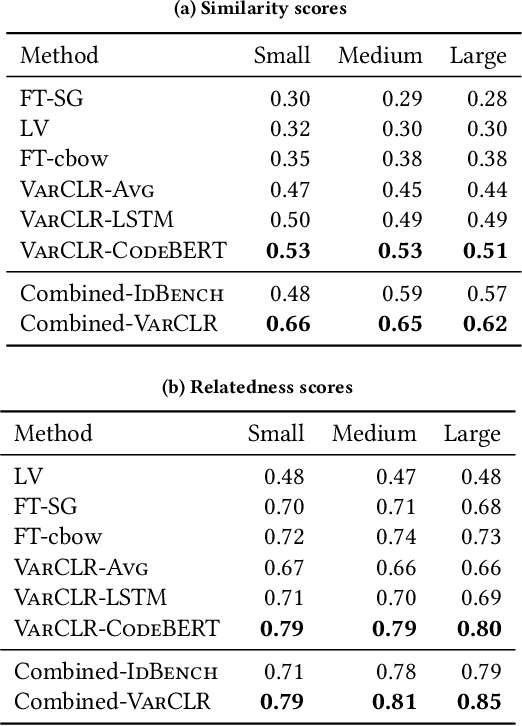
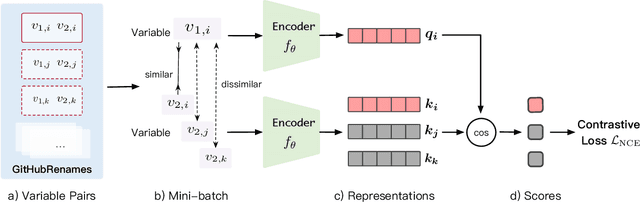
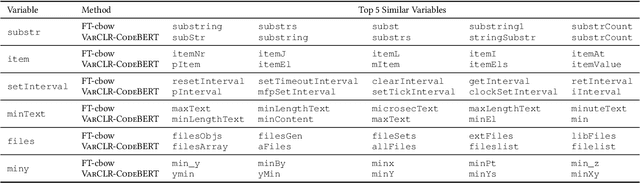
Variable names are critical for conveying intended program behavior. Machine learning-based program analysis methods use variable name representations for a wide range of tasks, such as suggesting new variable names and bug detection. Ideally, such methods could capture semantic relationships between names beyond syntactic similarity, e.g., the fact that the names average and mean are similar. Unfortunately, previous work has found that even the best of previous representation approaches primarily capture relatedness (whether two variables are linked at all), rather than similarity (whether they actually have the same meaning). We propose VarCLR, a new approach for learning semantic representations of variable names that effectively captures variable similarity in this stricter sense. We observe that this problem is an excellent fit for contrastive learning, which aims to minimize the distance between explicitly similar inputs, while maximizing the distance between dissimilar inputs. This requires labeled training data, and thus we construct a novel, weakly-supervised variable renaming dataset mined from GitHub edits. We show that VarCLR enables the effective application of sophisticated, general-purpose language models like BERT, to variable name representation and thus also to related downstream tasks like variable name similarity search or spelling correction. VarCLR produces models that significantly outperform the state-of-the-art on IdBench, an existing benchmark that explicitly captures variable similarity (as distinct from relatedness). Finally, we contribute a release of all data, code, and pre-trained models, aiming to provide a drop-in replacement for variable representations used in either existing or future program analyses that rely on variable names.
DEEP: DEnoising Entity Pre-training for Neural Machine Translation
Nov 14, 2021
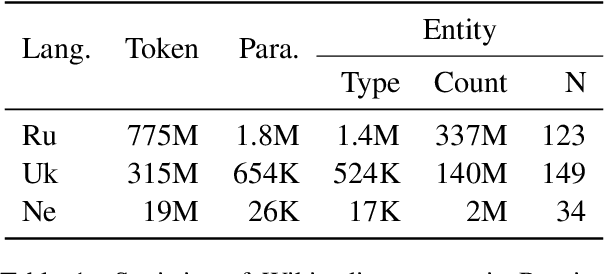
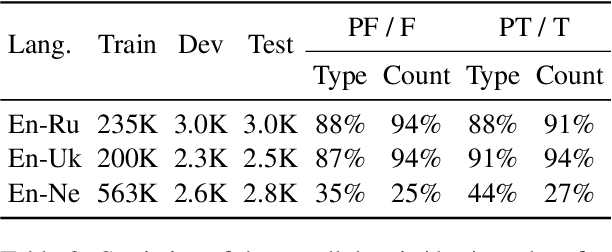
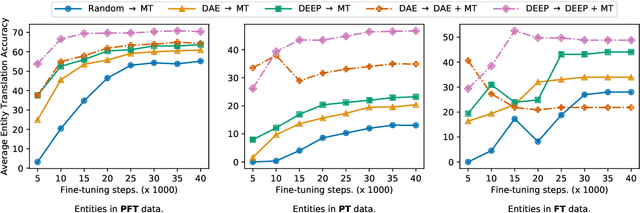
It has been shown that machine translation models usually generate poor translations for named entities that are infrequent in the training corpus. Earlier named entity translation methods mainly focus on phonetic transliteration, which ignores the sentence context for translation and is limited in domain and language coverage. To address this limitation, we propose DEEP, a DEnoising Entity Pre-training method that leverages large amounts of monolingual data and a knowledge base to improve named entity translation accuracy within sentences. Besides, we investigate a multi-task learning strategy that finetunes a pre-trained neural machine translation model on both entity-augmented monolingual data and parallel data to further improve entity translation. Experimental results on three language pairs demonstrate that \method results in significant improvements over strong denoising auto-encoding baselines, with a gain of up to 1.3 BLEU and up to 9.2 entity accuracy points for English-Russian translation.
Lexically Aware Semi-Supervised Learning for OCR Post-Correction
Nov 04, 2021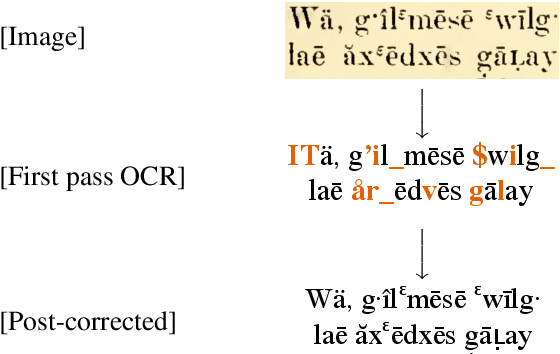
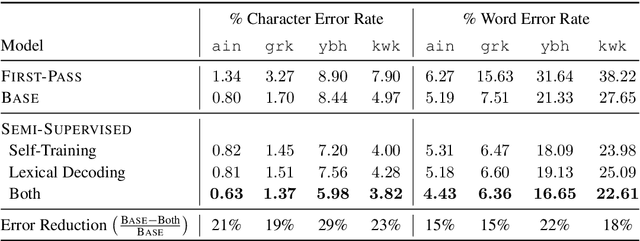
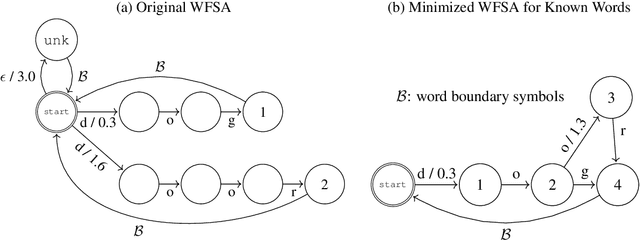
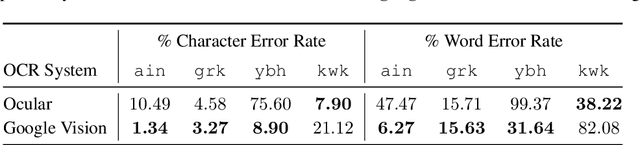
Much of the existing linguistic data in many languages of the world is locked away in non-digitized books and documents. Optical character recognition (OCR) can be used to produce digitized text, and previous work has demonstrated the utility of neural post-correction methods that improve the results of general-purpose OCR systems on recognition of less-well-resourced languages. However, these methods rely on manually curated post-correction data, which are relatively scarce compared to the non-annotated raw images that need to be digitized. In this paper, we present a semi-supervised learning method that makes it possible to utilize these raw images to improve performance, specifically through the use of self-training, a technique where a model is iteratively trained on its own outputs. In addition, to enforce consistency in the recognized vocabulary, we introduce a lexically-aware decoding method that augments the neural post-correction model with a count-based language model constructed from the recognized texts, implemented using weighted finite-state automata (WFSA) for efficient and effective decoding. Results on four endangered languages demonstrate the utility of the proposed method, with relative error reductions of 15-29%, where we find the combination of self-training and lexically-aware decoding essential for achieving consistent improvements. Data and code are available at https://shrutirij.github.io/ocr-el/.
On The Ingredients of an Effective Zero-shot Semantic Parser
Oct 15, 2021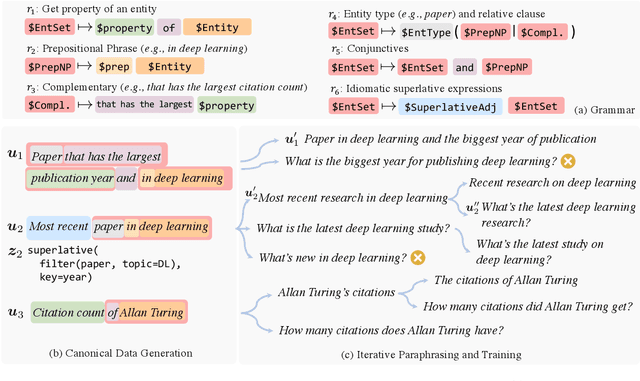
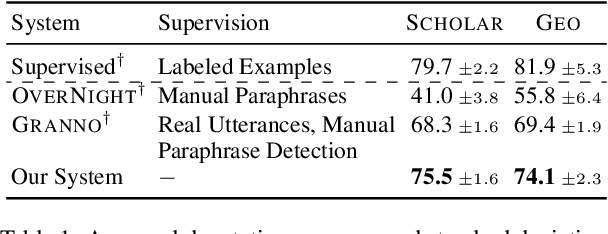
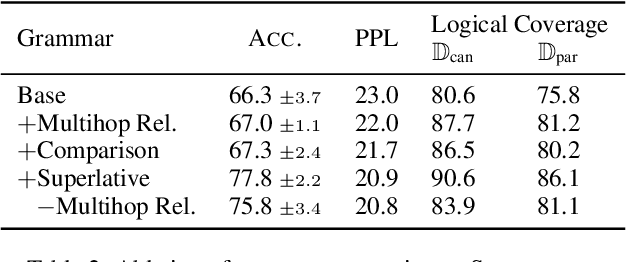

Semantic parsers map natural language utterances into meaning representations (e.g., programs). Such models are typically bottlenecked by the paucity of training data due to the required laborious annotation efforts. Recent studies have performed zero-shot learning by synthesizing training examples of canonical utterances and programs from a grammar, and further paraphrasing these utterances to improve linguistic diversity. However, such synthetic examples cannot fully capture patterns in real data. In this paper we analyze zero-shot parsers through the lenses of the language and logical gaps (Herzig and Berant, 2019), which quantify the discrepancy of language and programmatic patterns between the canonical examples and real-world user-issued ones. We propose bridging these gaps using improved grammars, stronger paraphrasers, and efficient learning methods using canonical examples that most likely reflect real user intents. Our model achieves strong performance on two semantic parsing benchmarks (Scholar, Geo) with zero labeled data.
Breaking Down Multilingual Machine Translation
Oct 15, 2021
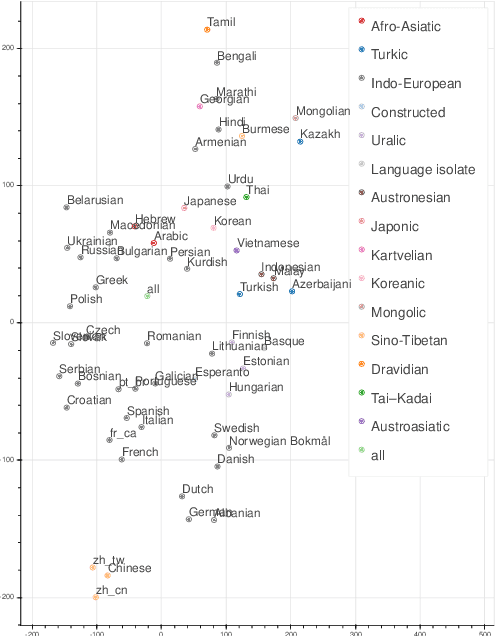
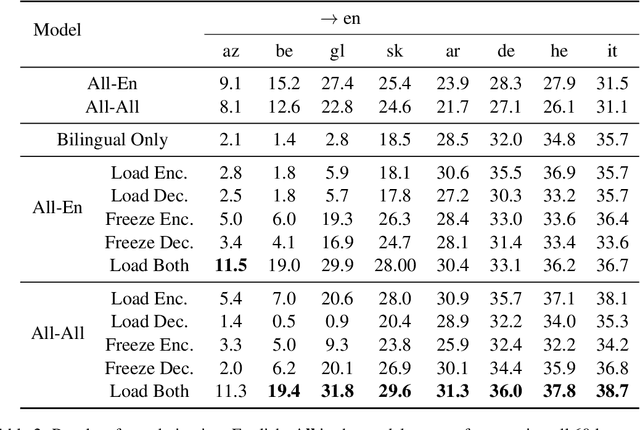
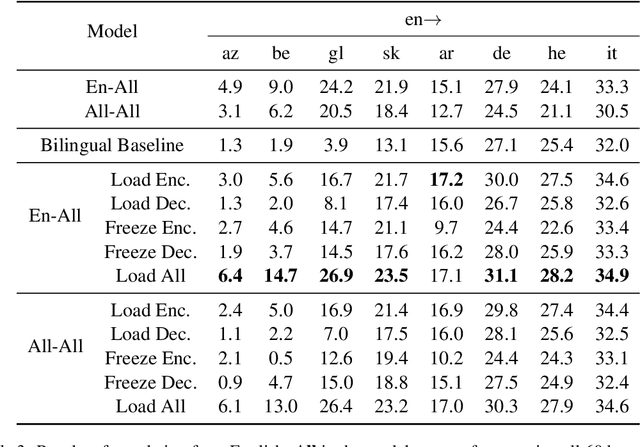
While multilingual training is now an essential ingredient in machine translation (MT) systems, recent work has demonstrated that it has different effects in different multilingual settings, such as many-to-one, one-to-many, and many-to-many learning. These training settings expose the encoder and the decoder in a machine translation model with different data distributions. In this paper, we examine how different varieties of multilingual training contribute to learning these two components of the MT model. Specifically, we compare bilingual models with encoders and/or decoders initialized by multilingual training. We show that multilingual training is beneficial to encoders in general, while it only benefits decoders for low-resource languages (LRLs). We further find the important attention heads for each language pair and compare their correlations during inference. Our analysis sheds light on how multilingual translation models work and also enables us to propose methods to improve performance by training with highly related languages. Our many-to-one models for high-resource languages and one-to-many models for LRL outperform the best results reported by Aharoni et al. (2019).
Systematic Inequalities in Language Technology Performance across the World's Languages
Oct 13, 2021
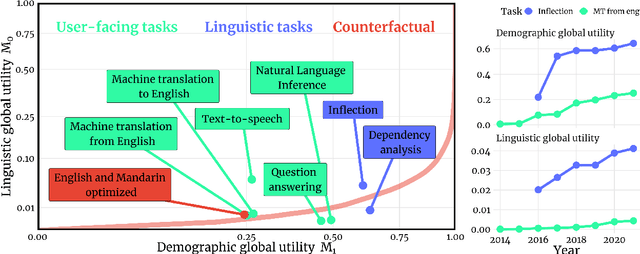
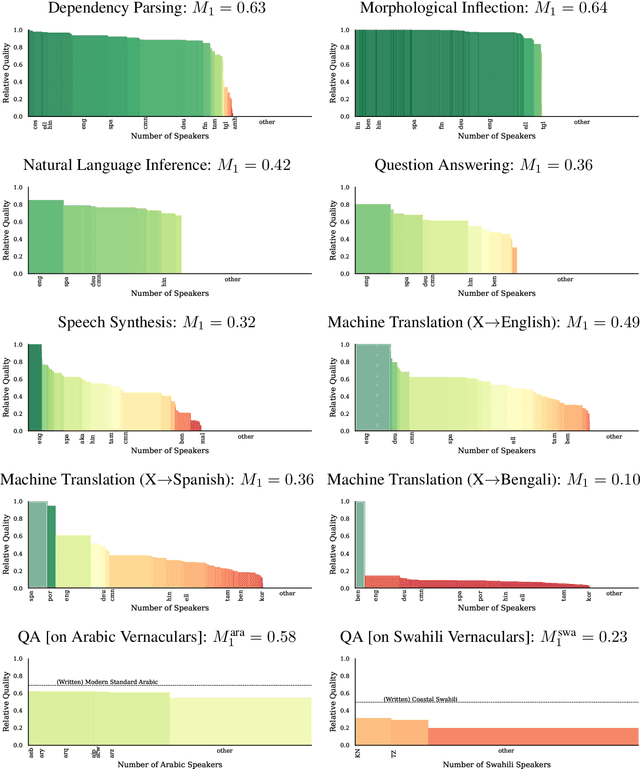
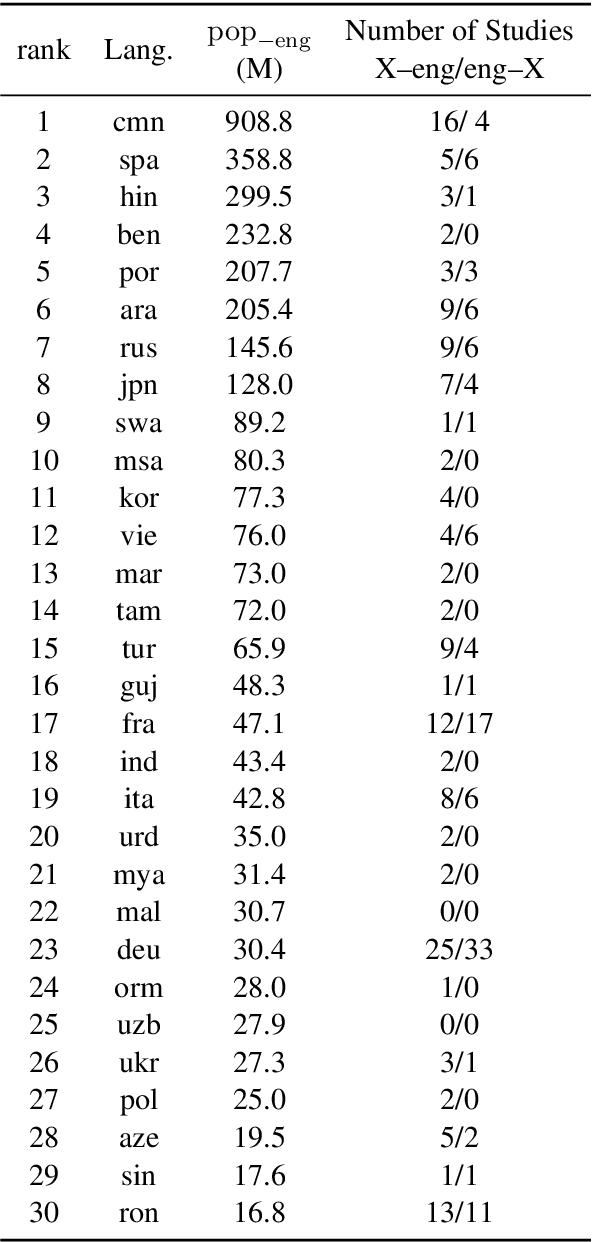
Natural language processing (NLP) systems have become a central technology in communication, education, medicine, artificial intelligence, and many other domains of research and development. While the performance of NLP methods has grown enormously over the last decade, this progress has been restricted to a minuscule subset of the world's 6,500 languages. We introduce a framework for estimating the global utility of language technologies as revealed in a comprehensive snapshot of recent publications in NLP. Our analyses involve the field at large, but also more in-depth studies on both user-facing technologies (machine translation, language understanding, question answering, text-to-speech synthesis) as well as more linguistic NLP tasks (dependency parsing, morphological inflection). In the process, we (1) quantify disparities in the current state of NLP research, (2) explore some of its associated societal and academic factors, and (3) produce tailored recommendations for evidence-based policy making aimed at promoting more global and equitable language technologies.
Towards a Unified View of Parameter-Efficient Transfer Learning
Oct 08, 2021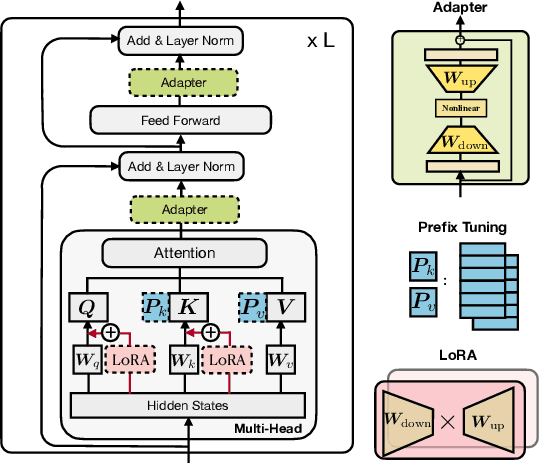
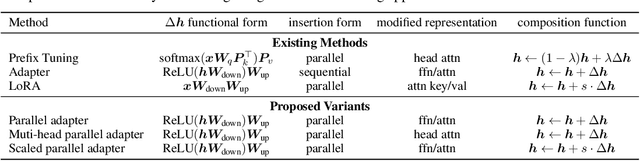
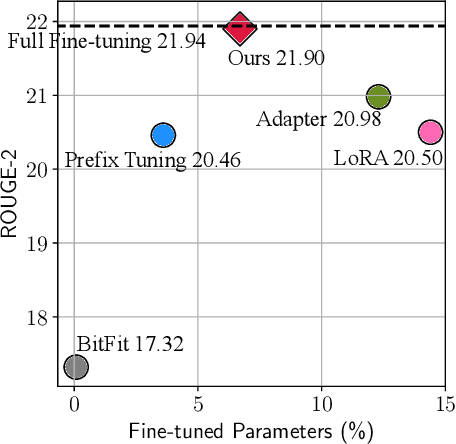
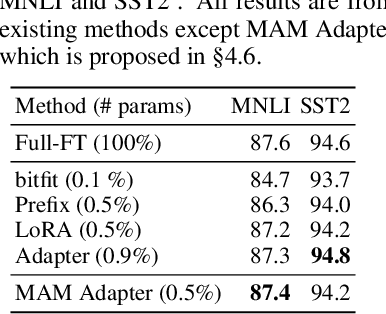
Fine-tuning large pre-trained language models on downstream tasks has become the de-facto learning paradigm in NLP. However, conventional approaches fine-tune all the parameters of the pre-trained model, which becomes prohibitive as the model size and the number of tasks grow. Recent work has proposed a variety of parameter-efficient transfer learning methods that only fine-tune a small number of (extra) parameters to attain strong performance. While effective, the critical ingredients for success and the connections among the various methods are poorly understood. In this paper, we break down the design of state-of-the-art parameter-efficient transfer learning methods and present a unified framework that establishes connections between them. Specifically, we re-frame them as modifications to specific hidden states in pre-trained models, and define a set of design dimensions along which different methods vary, such as the function to compute the modification and the position to apply the modification. Through comprehensive empirical studies across machine translation, text summarization, language understanding, and text classification benchmarks, we utilize the unified view to identify important design choices in previous methods. Furthermore, our unified framework enables the transfer of design elements across different approaches, and as a result we are able to instantiate new parameter-efficient fine-tuning methods that tune less parameters than previous methods while being more effective, achieving comparable results to fine-tuning all parameters on all four tasks.
Capturing Structural Locality in Non-parametric Language Models
Oct 06, 2021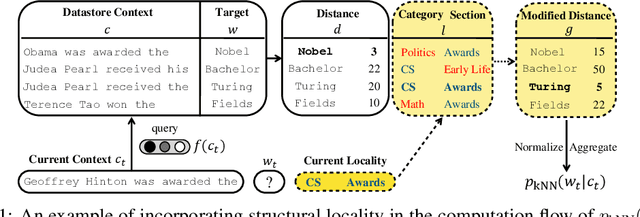

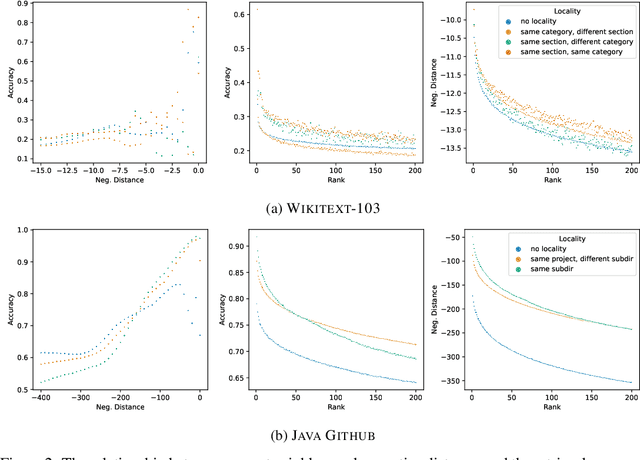
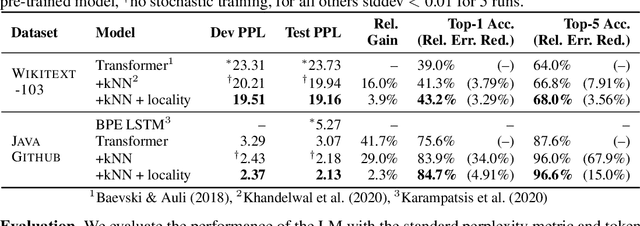
Structural locality is a ubiquitous feature of real-world datasets, wherein data points are organized into local hierarchies. Some examples include topical clusters in text or project hierarchies in source code repositories. In this paper, we explore utilizing this structural locality within non-parametric language models, which generate sequences that reference retrieved examples from an external source. We propose a simple yet effective approach for adding locality information into such models by adding learned parameters that improve the likelihood of retrieving examples from local neighborhoods. Experiments on two different domains, Java source code and Wikipedia text, demonstrate that locality features improve model efficacy over models without access to these features, with interesting differences. We also perform an analysis of how and where locality features contribute to improved performance and why the traditionally used contextual similarity metrics alone are not enough to grasp the locality structure.
Learning to Superoptimize Real-world Programs
Sep 28, 2021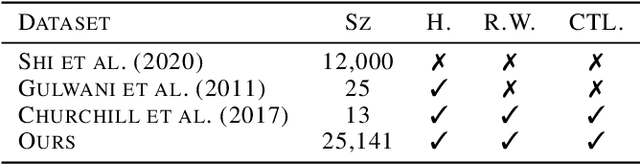
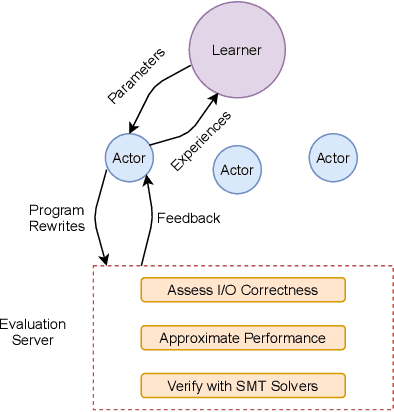

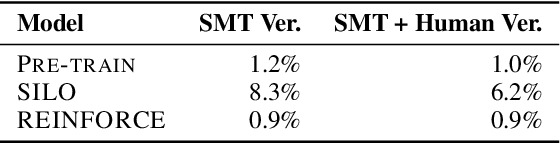
Program optimization is the process of modifying software to execute more efficiently. Because finding the optimal program is generally undecidable, modern compilers usually resort to expert-written heuristic optimizations. In contrast, superoptimizers attempt to find the optimal program by employing significantly more expensive search and constraint solving techniques. Generally, these methods do not scale well to programs in real development scenarios, and as a result superoptimization has largely been confined to small-scale, domain-specific, and/or synthetic program benchmarks. In this paper, we propose a framework to learn to superoptimize real-world programs by using neural sequence-to-sequence models. We introduce the Big Assembly benchmark, a dataset consisting of over 25K real-world functions mined from open-source projects in x86-64 assembly, which enables experimentation on large-scale optimization of real-world programs. We propose an approach, Self Imitation Learning for Optimization (SILO) that is easy to implement and outperforms a standard policy gradient learning approach on our Big Assembly benchmark. Our method, SILO, superoptimizes programs an expected 6.2% of our test set when compared with the gcc version 10.3 compiler's aggressive optimization level -O3. We also report that SILO's rate of superoptimization on our test set is over five times that of a standard policy gradient approach and a model pre-trained on compiler optimization demonstration.
Dependency Induction Through the Lens of Visual Perception
Sep 20, 2021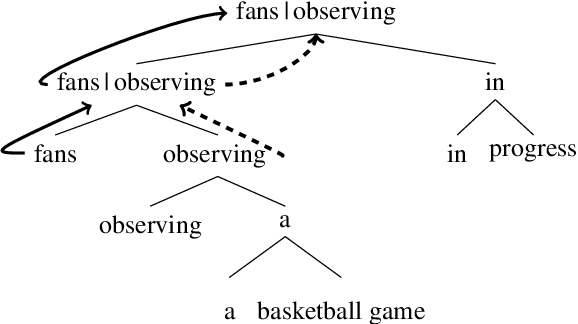
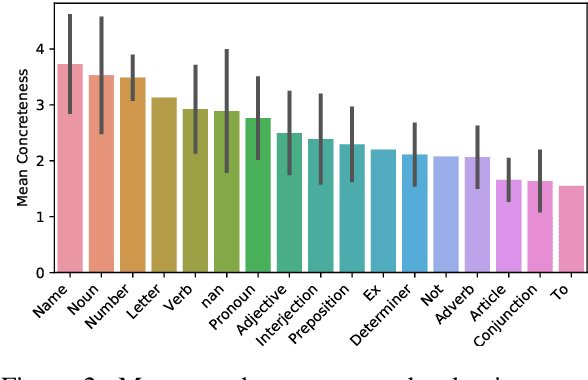
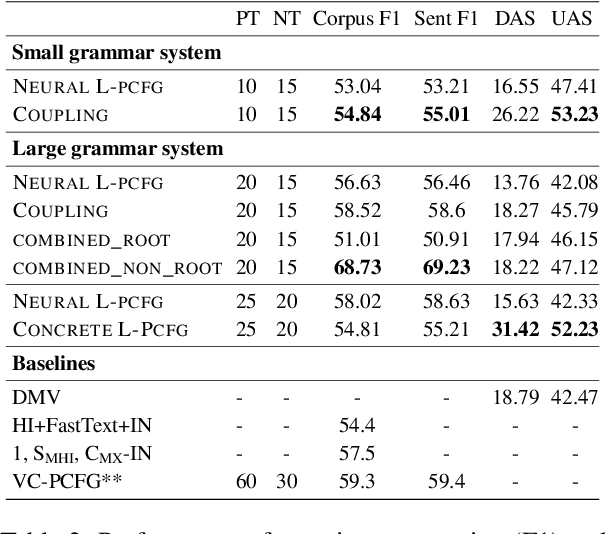
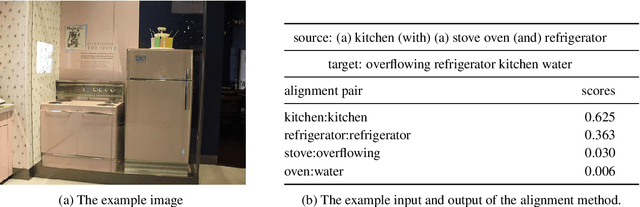
Most previous work on grammar induction focuses on learning phrasal or dependency structure purely from text. However, because the signal provided by text alone is limited, recently introduced visually grounded syntax models make use of multimodal information leading to improved performance in constituency grammar induction. However, as compared to dependency grammars, constituency grammars do not provide a straightforward way to incorporate visual information without enforcing language-specific heuristics. In this paper, we propose an unsupervised grammar induction model that leverages word concreteness and a structural vision-based heuristic to jointly learn constituency-structure and dependency-structure grammars. Our experiments find that concreteness is a strong indicator for learning dependency grammars, improving the direct attachment score (DAS) by over 50\% as compared to state-of-the-art models trained on pure text. Next, we propose an extension of our model that leverages both word concreteness and visual semantic role labels in constituency and dependency parsing. Our experiments show that the proposed extension outperforms the current state-of-the-art visually grounded models in constituency parsing even with a smaller grammar size.