 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Alignment Objectives for Multilingual Bidirectional Encoders
Paper and Code
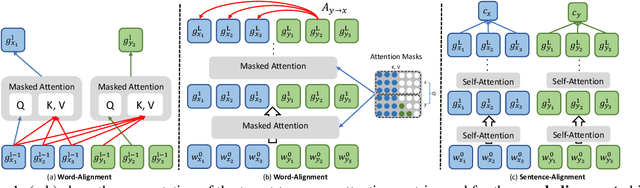
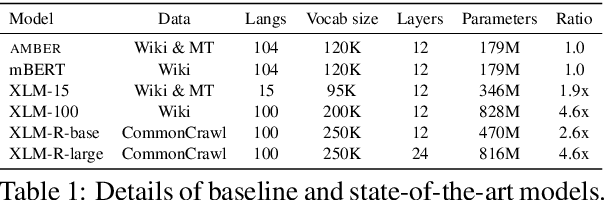
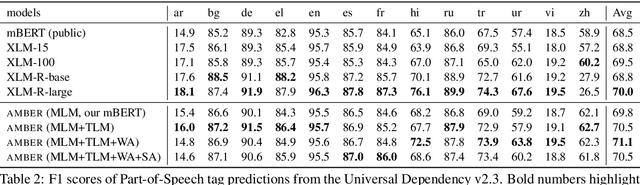
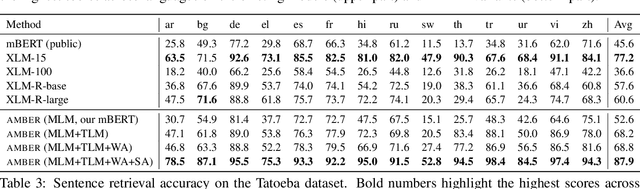
Pre-trained cross-lingual encoders such as mBERT (Devlin et al., 2019) and XLMR (Conneau et al., 2020) have proven to be impressively effective at enabling transfer-learning of NLP systems from high-resource languages to low-resource languages. This success comes despite the fact that there is no explicit objective to align the contextual embeddings of words/sentences with similar meanings across languages together in the same space. In this paper, we present a new method for learning multilingual encoders, AMBER (Aligned Multilingual Bidirectional EncodeR). AMBER is trained on additional parallel data using two explicit alignment objectives that align the multilingual representations at different granularities. We conduct experiments on zero-shot cross-lingual transfer learning for different tasks including sequence tagging, sentence retrieval and sentence classification. Experimental results show that AMBER obtains gains of up to 1.1 average F1 score on sequence tagging and up to 27.3 average accuracy on retrieval over the XLMR-large model which has 4.6x the parameters of AMBER.