 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill-Conditioned Visual Geolocation for Vision-Language
Apr 10, 2026Vision-language models (VLMs) have shown a promising ability in image geolocation, but they still lack structured geographic reasoning and the capacity for autonomous self-evolution. Existing methods predominantly rely on implicit parametric memory, which often exploits outdated knowledge and generates hallucinated reasoning. Furthermore, current inference is a "one-off" process, lacking the feedback loops necessary for self-evolution based on reasoning outcomes. To address these issues, we propose GeoSkill, a training-free framework based on an evolving Skill-Graph. We first initialize the graph by refining human expert trajectories into atomic, natural-language skills. For execution, GeoSkill employs an inference model to perform direct reasoning guided by the current Skill-Graph. For continuous growth, an Autonomous Evolution mechanism leverages a larger model to conduct multiple reasoning rollouts on image-coordinate pairs sourced from web-scale data and verified real-world reasoning. By analyzing both successful and failed trajectories from these rollouts, the mechanism iteratively synthesizes and prunes skills, effectively expanding the Skill-Graph and correcting geographic biases without any parameter updates. Experiments demonstrate that GeoSkill achieves promising performance in both geolocation accuracy and reasoning faithfulness on GeoRC, while maintaining superior generalization across diverse external datasets. Furthermore, our autonomous evolution fosters the emergence of novel, verifiable skills, significantly enhancing the system's cognition of real-world geographic knowledge beyond isolated case studies.
ActivityEditor: Learning to Synthesize Physically Valid Human Mobility
Apr 07, 2026Human mobility modeling is indispensable for diverse urban applications. However, existing data-driven methods often suffer from data scarcity, limiting their applicability in regions where historical trajectories are unavailable or restricted. To bridge this gap, we propose \textbf{ActivityEditor}, a novel dual-LLM-agent framework designed for zero-shot cross-regional trajectory generation. Our framework decomposes the complex synthesis task into two collaborative stages. Specifically, an intention-based agent, which leverages demographic-driven priors to generate structured human intentions and coarse activity chains to ensure high-level socio-semantic coherence. These outputs are then refined by editor agent to obtain mobility trajectories through iteratively revisions that enforces human mobility law. This capability is acquired through reinforcement learning with multiple rewards grounded in real-world physical constraints, allowing the agent to internalize mobility regularities and ensure high-fidelity trajectory generation. Extensive experiments demonstrate that \textbf{ActivityEditor} achieves superior zero-shot performance when transferred across diverse urban contexts. It maintains high statistical fidelity and physical validity, providing a robust and highly generalizable solution for mobility simulation in data-scarce scenarios. Our code is available at: https://anonymous.4open.science/r/ActivityEditor-066B.
RoboRouter: Training-Free Policy Routing for Robotic Manipulation
Mar 12, 2026Research on robotic manipulation has developed a diverse set of policy paradigms, including vision-language-action (VLA) models, vision-action (VA) policies, and code-based compositional approaches. Concrete policies typically attain high success rates on specific task distributions but lim-ited generalization beyond it. Rather than proposing an other monolithic policy, we propose to leverage the complementary strengths of existing approaches through intelligent policy routing. We introduce RoboRouter, a training-free framework that maintains a pool of heterogeneous policies and learns to select the best-performing policy for each task through accumulated execution experience. Given a new task, RoboRouter constructs a semantic task representation, retrieves historical records of similar tasks, predicts the optimal policy choice without requiring trial-and-error, and incorporates structured feedback to refine subsequent routing decisions. Integrating a new policy into the system requires only lightweight evaluation and incurs no training overhead. Across simulation benchmark and real-world evaluations, RoboRouter consistently outperforms than in-dividual policies, improving average success rate by more than 3% in simulation and over 13% in real-world settings, while preserving execution efficiency. Our results demonstrate that intelligent routing across heterogeneous, off-the-shelf policies provides a practical and scalable pathway toward building more capable robotic systems.
Scaling Laws of Motion Forecasting and Planning -- A Technical Report
Jun 09, 2025We study the empirical scaling laws of a family of encoder-decoder autoregressive transformer models on the task of joint motion forecasting and planning in the autonomous driving domain. Using a 500 thousand hours driving dataset, we demonstrate that, similar to language modeling, model performance improves as a power-law function of the total compute budget, and we observe a strong correlation between model training loss and model evaluation metrics. Most interestingly, closed-loop metrics also improve with scaling, which has important implications for the suitability of open-loop metrics for model development and hill climbing. We also study the optimal scaling of the number of transformer parameters and the training data size for a training compute-optimal model. We find that as the training compute budget grows, optimal scaling requires increasing the model size 1.5x as fast as the dataset size. We also study inference-time compute scaling, where we observe that sampling and clustering the output of smaller models makes them competitive with larger models, up to a crossover point beyond which a larger models becomes more inference-compute efficient. Overall, our experimental results demonstrate that optimizing the training and inference-time scaling properties of motion forecasting and planning models is a key lever for improving their performance to address a wide variety of driving scenarios. Finally, we briefly study the utility of training on general logged driving data of other agents to improve the performance of the ego-agent, an important research area to address the scarcity of robotics data for large capacity models training.
A Multi-task Convolutional Neural Network for Autonomous Robotic Grasping in Object Stacking Scenes
Mar 02, 2019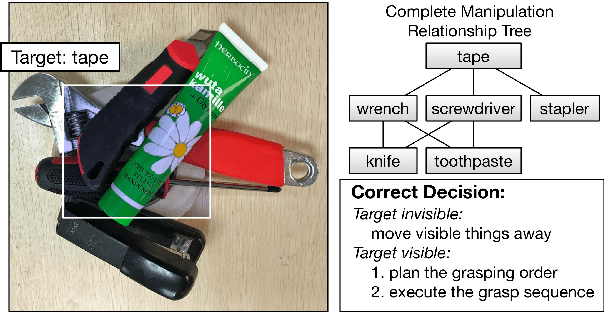


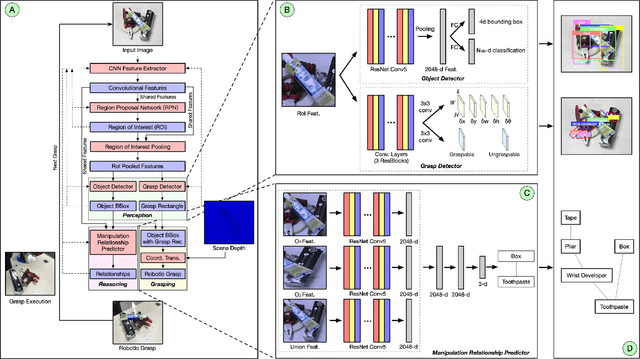
Autonomous robotic grasping plays an important role in intelligent robotics. However, how to help the robot grasp specific objects in object stacking scenes is still an open problem, because there are two main challenges for autonomous robots: (1)it is a comprehensive task to know what and how to grasp; (2)it is hard to deal with the situations in which the target is hidden or covered by other objects. In this paper, we propose a multi-task convolutional neural network for autonomous robotic grasping, which can help the robot find the target, make the plan for grasping and finally grasp the target step by step in object stacking scenes. We integrate vision-based robotic grasping detection and visual manipulation relationship reasoning in one single deep network and build the autonomous robotic grasping system. Experimental results demonstrate that with our model, Baxter robot can autonomously grasp the target with a success rate of 90.6%, 71.9% and 59.4% in object cluttered scenes, familiar stacking scenes and complex stacking scenes respectively.