 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws of Motion Forecasting and Planning -- A Technical Report
Jun 09, 2025We study the empirical scaling laws of a family of encoder-decoder autoregressive transformer models on the task of joint motion forecasting and planning in the autonomous driving domain. Using a 500 thousand hours driving dataset, we demonstrate that, similar to language modeling, model performance improves as a power-law function of the total compute budget, and we observe a strong correlation between model training loss and model evaluation metrics. Most interestingly, closed-loop metrics also improve with scaling, which has important implications for the suitability of open-loop metrics for model development and hill climbing. We also study the optimal scaling of the number of transformer parameters and the training data size for a training compute-optimal model. We find that as the training compute budget grows, optimal scaling requires increasing the model size 1.5x as fast as the dataset size. We also study inference-time compute scaling, where we observe that sampling and clustering the output of smaller models makes them competitive with larger models, up to a crossover point beyond which a larger models becomes more inference-compute efficient. Overall, our experimental results demonstrate that optimizing the training and inference-time scaling properties of motion forecasting and planning models is a key lever for improving their performance to address a wide variety of driving scenarios. Finally, we briefly study the utility of training on general logged driving data of other agents to improve the performance of the ego-agent, an important research area to address the scarcity of robotics data for large capacity models training.
Bridging the Gap for Tokenizer-Free Language Models
Aug 27, 2019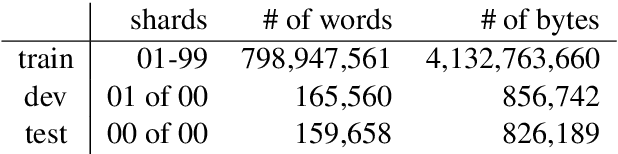
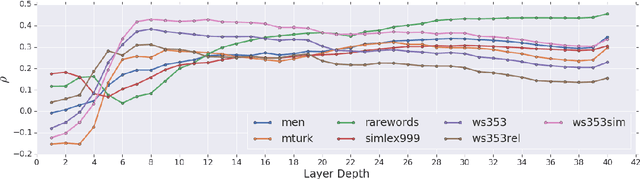
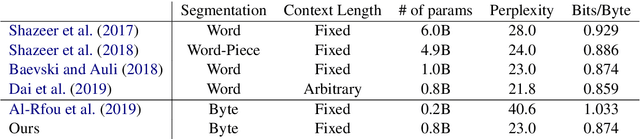
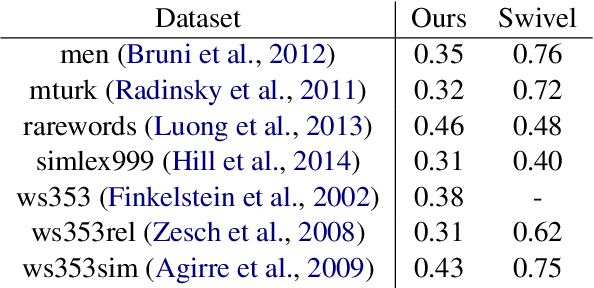
Purely character-based language models (LMs) have been lagging in quality on large scale datasets, and current state-of-the-art LMs rely on word tokenization. It has been assumed that injecting the prior knowledge of a tokenizer into the model is essential to achieving competitive results. In this paper, we show that contrary to this conventional wisdom, tokenizer-free LMs with sufficient capacity can achieve competitive performance on a large scale dataset. We train a vanilla transformer network with 40 self-attention layers on the One Billion Word (lm1b) benchmark and achieve a new state of the art for tokenizer-free LMs, pushing these models to be on par with their word-based counterparts.
Character-Level Language Modeling with Deeper Self-Attention
Aug 09, 2018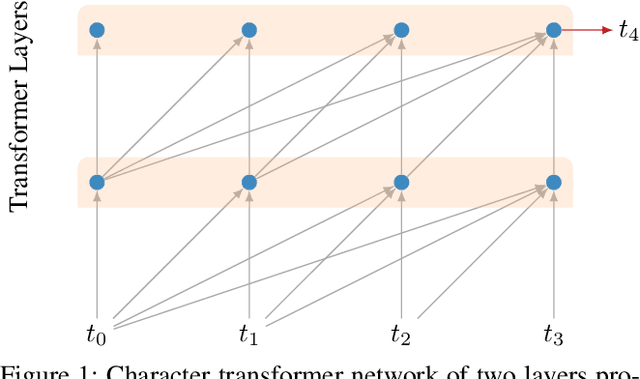
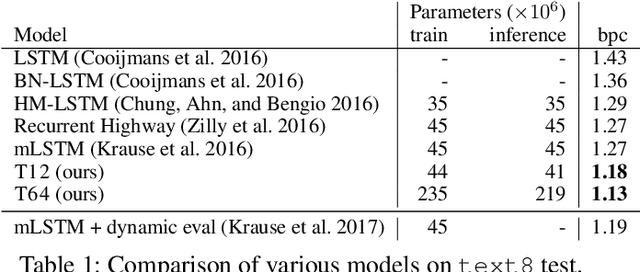
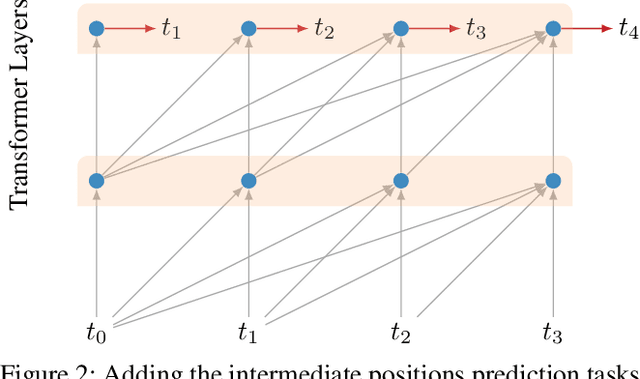
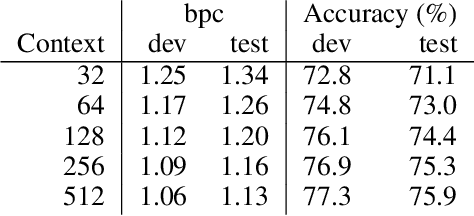
LSTMs and other RNN variants have shown strong performance on character-level language modeling. These models are typically trained using truncated backpropagation through time, and it is common to assume that their success stems from their ability to remember long-term contexts. In this paper, we show that a deep (64-layer) transformer model with fixed context outperforms RNN variants by a large margin, achieving state of the art on two popular benchmarks- 1.13 bits per character on text8 and 1.06 on enwik8. To get good results at this depth, we show that it is important to add auxiliary losses, both at intermediate network layers and intermediate sequence positions.