 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Visuals: Investigating Force Feedback in Extended Reality for Robot Data Collection
Mar 26, 2025This work explores how force feedback affects various aspects of robot data collection within the Extended Reality (XR) setting. Force feedback has been proved to enhance the user experience in Extended Reality (XR) by providing contact-rich information. However, its impact on robot data collection has not received much attention in the robotics community. This paper addresses this shortcoming by conducting an extensive user study on the effects of force feedback during data collection in XR. We extended two XR-based robot control interfaces, Kinesthetic Teaching and Motion Controllers, with haptic feedback features. The user study is conducted using manipulation tasks ranging from simple pick-place to complex peg assemble, requiring precise operations. The evaluations show that force feedback enhances task performance and user experience, particularly in tasks requiring high-precision manipulation. These improvements vary depending on the robot control interface and task complexity. This paper provides new insights into how different factors influence the impact of force feedback.
Chunking the Critic: A Transformer-based Soft Actor-Critic with N-Step Returns
Mar 05, 2025Soft Actor-Critic (SAC) critically depends on its critic network, which typically evaluates a single state-action pair to guide policy updates. Using N-step returns is a common practice to reduce the bias in the target values of the critic. However, using N-step returns can again introduce high variance and necessitates importance sampling, often destabilizing training. Recent algorithms have also explored action chunking-such as direct action repetition and movement primitives-to enhance exploration. In this paper, we propose a Transformer-based Critic Network for SAC that integrates the N-returns framework in a stable and efficient manner. Unlike approaches that perform chunking in the actor network, we feed chunked actions into the critic network to explore potential performance gains. Our architecture leverages the Transformer's ability to process sequential information, facilitating more robust value estimation. Empirical results show that this method not only achieves efficient, stable training but also excels in sparse reward/multi-phase environments-traditionally a challenge for step-based methods. These findings underscore the promise of combining Transformer-based critics with N-returns to advance reinforcement learning performance
Underdamped Diffusion Bridges with Applications to Sampling
Mar 02, 2025We provide a general framework for learning diffusion bridges that transport prior to target distributions. It includes existing diffusion models for generative modeling, but also underdamped versions with degenerate diffusion matrices, where the noise only acts in certain dimensions. Extending previous findings, our framework allows to rigorously show that score matching in the underdamped case is indeed equivalent to maximizing a lower bound on the likelihood. Motivated by superior convergence properties and compatibility with sophisticated numerical integration schemes of underdamped stochastic processes, we propose \emph{underdamped diffusion bridges}, where a general density evolution is learned rather than prescribed by a fixed noising process. We apply our method to the challenging task of sampling from unnormalized densities without access to samples from the target distribution. Across a diverse range of sampling problems, our approach demonstrates state-of-the-art performance, notably outperforming alternative methods, while requiring significantly fewer discretization steps and no hyperparameter tuning.
X-IL: Exploring the Design Space of Imitation Learning Policies
Feb 19, 2025Designing modern imitation learning (IL) policies requires making numerous decisions, including the selection of feature encoding, architecture, policy representation, and more. As the field rapidly advances, the range of available options continues to grow, creating a vast and largely unexplored design space for IL policies. In this work, we present X-IL, an accessible open-source framework designed to systematically explore this design space. The framework's modular design enables seamless swapping of policy components, such as backbones (e.g., Transformer, Mamba, xLSTM) and policy optimization techniques (e.g., Score-matching, Flow-matching). This flexibility facilitates comprehensive experimentation and has led to the discovery of novel policy configurations that outperform existing methods on recent robot learning benchmarks. Our experiments demonstrate not only significant performance gains but also provide valuable insights into the strengths and weaknesses of various design choices. This study serves as both a practical reference for practitioners and a foundation for guiding future research in imitation learning.
Towards Fusing Point Cloud and Visual Representations for Imitation Learning
Feb 19, 2025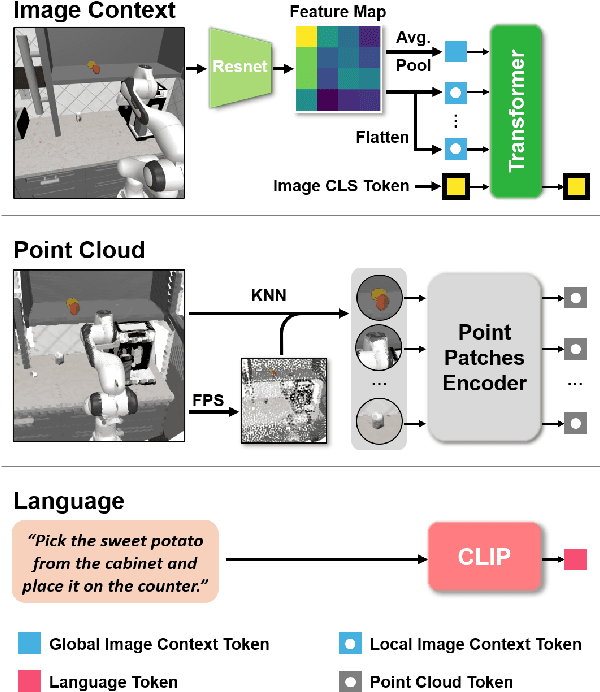
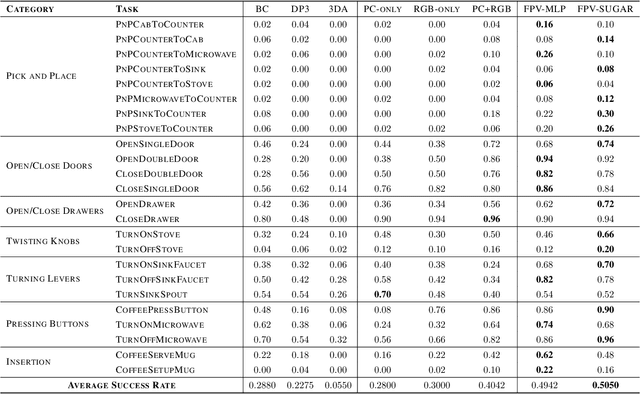
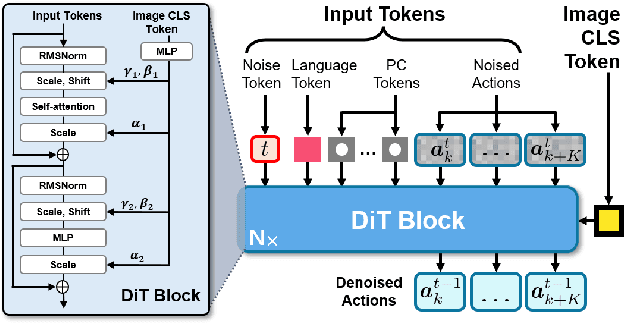
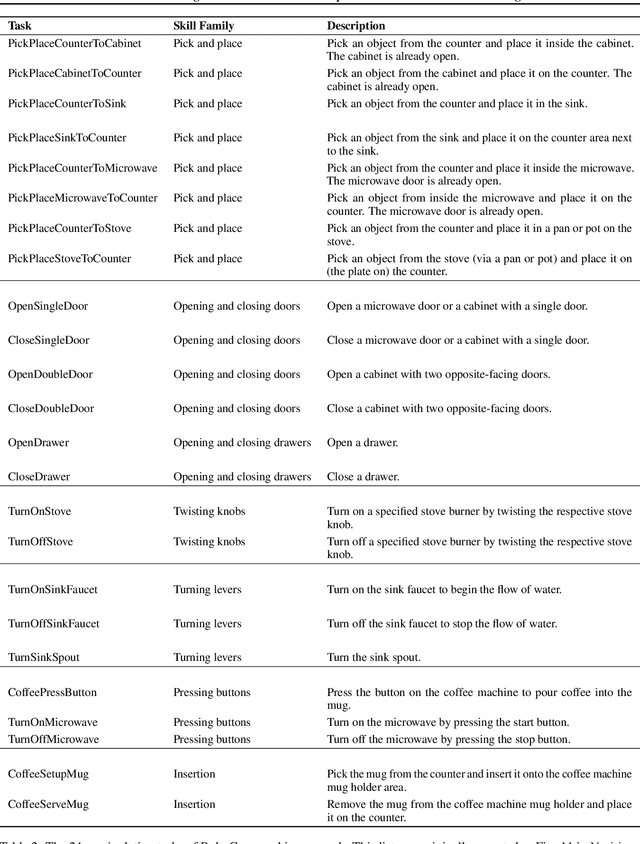
Learning for manipulation requires using policies that have access to rich sensory information such as point clouds or RGB images. Point clouds efficiently capture geometric structures, making them essential for manipulation tasks in imitation learning. In contrast, RGB images provide rich texture and semantic information that can be crucial for certain tasks. Existing approaches for fusing both modalities assign 2D image features to point clouds. However, such approaches often lose global contextual information from the original images. In this work, we propose FPV-Net, a novel imitation learning method that effectively combines the strengths of both point cloud and RGB modalities. Our method conditions the point-cloud encoder on global and local image tokens using adaptive layer norm conditioning, leveraging the beneficial properties of both modalities. Through extensive experiments on the challenging RoboCasa benchmark, we demonstrate the limitations of relying on either modality alone and show that our method achieves state-of-the-art performance across all tasks.
Geometry-aware RL for Manipulation of Varying Shapes and Deformable Objects
Feb 12, 2025



Manipulating objects with varying geometries and deformable objects is a major challenge in robotics. Tasks such as insertion with different objects or cloth hanging require precise control and effective modelling of complex dynamics. In this work, we frame this problem through the lens of a heterogeneous graph that comprises smaller sub-graphs, such as actuators and objects, accompanied by different edge types describing their interactions. This graph representation serves as a unified structure for both rigid and deformable objects tasks, and can be extended further to tasks comprising multiple actuators. To evaluate this setup, we present a novel and challenging reinforcement learning benchmark, including rigid insertion of diverse objects, as well as rope and cloth manipulation with multiple end-effectors. These tasks present a large search space, as both the initial and target configurations are uniformly sampled in 3D space. To address this issue, we propose a novel graph-based policy model, dubbed Heterogeneous Equivariant Policy (HEPi), utilizing $SE(3)$ equivariant message passing networks as the main backbone to exploit the geometric symmetry. In addition, by modeling explicit heterogeneity, HEPi can outperform Transformer-based and non-heterogeneous equivariant policies in terms of average returns, sample efficiency, and generalization to unseen objects.
IRIS: An Immersive Robot Interaction System
Feb 05, 2025



This paper introduces IRIS, an immersive Robot Interaction System leveraging Extended Reality (XR), designed for robot data collection and interaction across multiple simulators, benchmarks, and real-world scenarios. While existing XR-based data collection systems provide efficient and intuitive solutions for large-scale data collection, they are often challenging to reproduce and reuse. This limitation arises because current systems are highly tailored to simulator-specific use cases and environments. IRIS is a novel, easily extendable framework that already supports multiple simulators, benchmarks, and even headsets. Furthermore, IRIS is able to include additional information from real-world sensors, such as point clouds captured through depth cameras. A unified scene specification is generated directly from simulators or real-world sensors and transmitted to XR headsets, creating identical scenes in XR. This specification allows IRIS to support any of the objects, assets, and robots provided by the simulators. In addition, IRIS introduces shared spatial anchors and a robust communication protocol that links simulations between multiple XR headsets. This feature enables multiple XR headsets to share a synchronized scene, facilitating collaborative and multi-user data collection. IRIS can be deployed on any device that supports the Unity Framework, encompassing the vast majority of commercially available headsets. In this work, IRIS was deployed and tested on the Meta Quest 3 and the HoloLens 2. IRIS showcased its versatility across a wide range of real-world and simulated scenarios, using current popular robot simulators such as MuJoCo, IsaacSim, CoppeliaSim, and Genesis. In addition, a user study evaluates IRIS on a data collection task for the LIBERO benchmark. The study shows that IRIS significantly outperforms the baseline in both objective and subjective metrics.
DIME:Diffusion-Based Maximum Entropy Reinforcement Learning
Feb 04, 2025Maximum entropy reinforcement learning (MaxEnt-RL) has become the standard approach to RL due to its beneficial exploration properties. Traditionally, policies are parameterized using Gaussian distributions, which significantly limits their representational capacity. Diffusion-based policies offer a more expressive alternative, yet integrating them into MaxEnt-RL poses challenges--primarily due to the intractability of computing their marginal entropy. To overcome this, we propose Diffusion-Based Maximum Entropy RL (DIME). DIME leverages recent advances in approximate inference with diffusion models to derive a lower bound on the maximum entropy objective. Additionally, we propose a policy iteration scheme that provably converges to the optimal diffusion policy. Our method enables the use of expressive diffusion-based policies while retaining the principled exploration benefits of MaxEnt-RL, significantly outperforming other diffusion-based methods on challenging high-dimensional control benchmarks. It is also competitive with state-of-the-art non-diffusion based RL methods while requiring fewer algorithmic design choices and smaller update-to-data ratios, reducing computational complexity.
Sequential Controlled Langevin Diffusions
Dec 10, 2024



An effective approach for sampling from unnormalized densities is based on the idea of gradually transporting samples from an easy prior to the complicated target distribution. Two popular methods are (1) Sequential Monte Carlo (SMC), where the transport is performed through successive annealed densities via prescribed Markov chains and resampling steps, and (2) recently developed diffusion-based sampling methods, where a learned dynamical transport is used. Despite the common goal, both approaches have different, often complementary, advantages and drawbacks. The resampling steps in SMC allow focusing on promising regions of the space, often leading to robust performance. While the algorithm enjoys asymptotic guarantees, the lack of flexible, learnable transitions can lead to slow convergence. On the other hand, diffusion-based samplers are learned and can potentially better adapt themselves to the target at hand, yet often suffer from training instabilities. In this work, we present a principled framework for combining SMC with diffusion-based samplers by viewing both methods in continuous time and considering measures on path space. This culminates in the new Sequential Controlled Langevin Diffusion (SCLD) sampling method, which is able to utilize the benefits of both methods and reaches improved performance on multiple benchmark problems, in many cases using only 10% of the training budget of previous diffusion-based samplers.
Enhancing Exploration with Diffusion Policies in Hybrid Off-Policy RL: Application to Non-Prehensile Manipulation
Nov 22, 2024



Learning diverse policies for non-prehensile manipulation is essential for improving skill transfer and generalization to out-of-distribution scenarios. In this work, we enhance exploration through a two-fold approach within a hybrid framework that tackles both discrete and continuous action spaces. First, we model the continuous motion parameter policy as a diffusion model, and second, we incorporate this into a maximum entropy reinforcement learning framework that unifies both the discrete and continuous components. The discrete action space, such as contact point selection, is optimized through Q-value function maximization, while the continuous part is guided by a diffusion-based policy. This hybrid approach leads to a principled objective, where the maximum entropy term is derived as a lower bound using structured variational inference. We propose the Hybrid Diffusion Policy algorithm (HyDo) and evaluate its performance on both simulation and zero-shot sim2real tasks. Our results show that HyDo encourages more diverse behavior policies, leading to significantly improved success rates across tasks - for example, increasing from 53% to 72% on a real-world 6D pose alignment task. Project page: https://leh2rng.github.io/hydo