 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporalFlowViz: Parameter-Aware Visual Analytics for Interpreting Scramjet Combustion Evolution
Sep 05, 2025



Understanding the complex combustion dynamics within scramjet engines is critical for advancing high-speed propulsion technologies. However, the large scale and high dimensionality of simulation-generated temporal flow field data present significant challenges for visual interpretation, feature differentiation, and cross-case comparison. In this paper, we present TemporalFlowViz, a parameter-aware visual analytics workflow and system designed to support expert-driven clustering, visualization, and interpretation of temporal flow fields from scramjet combustion simulations. Our approach leverages hundreds of simulated combustion cases with varying initial conditions, each producing time-sequenced flow field images. We use pretrained Vision Transformers to extract high-dimensional embeddings from these frames, apply dimensionality reduction and density-based clustering to uncover latent combustion modes, and construct temporal trajectories in the embedding space to track the evolution of each simulation over time. To bridge the gap between latent representations and expert reasoning, domain specialists annotate representative cluster centroids with descriptive labels. These annotations are used as contextual prompts for a vision-language model, which generates natural-language summaries for individual frames and full simulation cases. The system also supports parameter-based filtering, similarity-based case retrieval, and coordinated multi-view exploration to facilitate in-depth analysis. We demonstrate the effectiveness of TemporalFlowViz through two expert-informed case studies and expert feedback, showing TemporalFlowViz enhances hypothesis generation, supports interpretable pattern discovery, and enhances knowledge discovery in large-scale scramjet combustion analysis.
EntropyGS: An Efficient Entropy Coding on 3D Gaussian Splatting
Aug 13, 2025
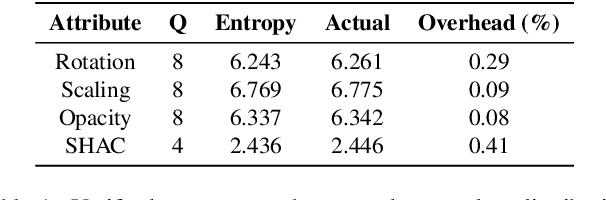
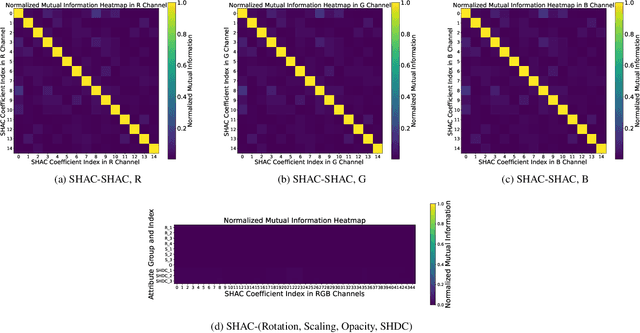
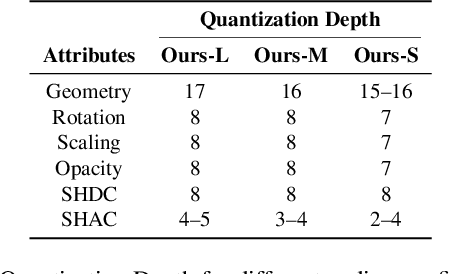
As an emerging novel view synthesis approach, 3D Gaussian Splatting (3DGS) demonstrates fast training/rendering with superior visual quality. The two tasks of 3DGS, Gaussian creation and view rendering, are typically separated over time or devices, and thus storage/transmission and finally compression of 3DGS Gaussians become necessary. We begin with a correlation and statistical analysis of 3DGS Gaussian attributes. An inspiring finding in this work reveals that spherical harmonic AC attributes precisely follow Laplace distributions, while mixtures of Gaussian distributions can approximate rotation, scaling, and opacity. Additionally, harmonic AC attributes manifest weak correlations with other attributes except for inherited correlations from a color space. A factorized and parameterized entropy coding method, EntropyGS, is hereinafter proposed. During encoding, distribution parameters of each Gaussian attribute are estimated to assist their entropy coding. The quantization for entropy coding is adaptively performed according to Gaussian attribute types. EntropyGS demonstrates about 30x rate reduction on benchmark datasets while maintaining similar rendering quality compared to input 3DGS data, with a fast encoding and decoding time.
Chunking the Critic: A Transformer-based Soft Actor-Critic with N-Step Returns
Mar 05, 2025Soft Actor-Critic (SAC) critically depends on its critic network, which typically evaluates a single state-action pair to guide policy updates. Using N-step returns is a common practice to reduce the bias in the target values of the critic. However, using N-step returns can again introduce high variance and necessitates importance sampling, often destabilizing training. Recent algorithms have also explored action chunking-such as direct action repetition and movement primitives-to enhance exploration. In this paper, we propose a Transformer-based Critic Network for SAC that integrates the N-returns framework in a stable and efficient manner. Unlike approaches that perform chunking in the actor network, we feed chunked actions into the critic network to explore potential performance gains. Our architecture leverages the Transformer's ability to process sequential information, facilitating more robust value estimation. Empirical results show that this method not only achieves efficient, stable training but also excels in sparse reward/multi-phase environments-traditionally a challenge for step-based methods. These findings underscore the promise of combining Transformer-based critics with N-returns to advance reinforcement learning performance
Towards Reproducible Learning-based Compression
Oct 13, 2024



A deep learning system typically suffers from a lack of reproducibility that is partially rooted in hardware or software implementation details. The irreproducibility leads to skepticism in deep learning technologies and it can hinder them from being deployed in many applications. In this work, the irreproducibility issue is analyzed where deep learning is employed in compression systems while the encoding and decoding may be run on devices from different manufacturers. The decoding process can even crash due to a single bit difference, e.g., in a learning-based entropy coder. For a given deep learning-based module with limited resources for protection, we first suggest that reproducibility can only be assured when the mismatches are bounded. Then a safeguarding mechanism is proposed to tackle the challenges. The proposed method may be applied for different levels of protection either at the reconstruction level or at a selected decoding level. Furthermore, the overhead introduced for the protection can be scaled down accordingly when the error bound is being suppressed. Experiments demonstrate the effectiveness of the proposed approach for learning-based compression systems, e.g., in image compression and point cloud compression.
TOP-ERL: Transformer-based Off-Policy Episodic Reinforcement Learning
Oct 12, 2024



This work introduces Transformer-based Off-Policy Episodic Reinforcement Learning (TOP-ERL), a novel algorithm that enables off-policy updates in the ERL framework. In ERL, policies predict entire action trajectories over multiple time steps instead of single actions at every time step. These trajectories are typically parameterized by trajectory generators such as Movement Primitives (MP), allowing for smooth and efficient exploration over long horizons while capturing high-level temporal correlations. However, ERL methods are often constrained to on-policy frameworks due to the difficulty of evaluating state-action values for entire action sequences, limiting their sample efficiency and preventing the use of more efficient off-policy architectures. TOP-ERL addresses this shortcoming by segmenting long action sequences and estimating the state-action values for each segment using a transformer-based critic architecture alongside an n-step return estimation. These contributions result in efficient and stable training that is reflected in the empirical results conducted on sophisticated robot learning environments. TOP-ERL significantly outperforms state-of-the-art RL methods. Thorough ablation studies additionally show the impact of key design choices on the model performance.
PIVOT-Net: Heterogeneous Point-Voxel-Tree-based Framework for Point Cloud Compression
Feb 11, 2024



The universality of the point cloud format enables many 3D applications, making the compression of point clouds a critical phase in practice. Sampled as discrete 3D points, a point cloud approximates 2D surface(s) embedded in 3D with a finite bit-depth. However, the point distribution of a practical point cloud changes drastically as its bit-depth increases, requiring different methodologies for effective consumption/analysis. In this regard, a heterogeneous point cloud compression (PCC) framework is proposed. We unify typical point cloud representations -- point-based, voxel-based, and tree-based representations -- and their associated backbones under a learning-based framework to compress an input point cloud at different bit-depth levels. Having recognized the importance of voxel-domain processing, we augment the framework with a proposed context-aware upsampling for decoding and an enhanced voxel transformer for feature aggregation. Extensive experimentation demonstrates the state-of-the-art performance of our proposal on a wide range of point clouds.
WrappingNet: Mesh Autoencoder via Deep Sphere Deformation
Aug 29, 2023



There have been recent efforts to learn more meaningful representations via fixed length codewords from mesh data, since a mesh serves as a complete model of underlying 3D shape compared to a point cloud. However, the mesh connectivity presents new difficulties when constructing a deep learning pipeline for meshes. Previous mesh unsupervised learning approaches typically assume category-specific templates, e.g., human face/body templates. It restricts the learned latent codes to only be meaningful for objects in a specific category, so the learned latent spaces are unable to be used across different types of objects. In this work, we present WrappingNet, the first mesh autoencoder enabling general mesh unsupervised learning over heterogeneous objects. It introduces a novel base graph in the bottleneck dedicated to representing mesh connectivity, which is shown to facilitate learning a shared latent space representing object shape. The superiority of WrappingNet mesh learning is further demonstrated via improved reconstruction quality and competitive classification compared to point cloud learning, as well as latent interpolation between meshes of different categories.
Concavity-Induced Distance for Unoriented Point Cloud Decomposition
Jun 19, 2023



We propose Concavity-induced Distance (CID) as a novel way to measure the dissimilarity between a pair of points in an unoriented point cloud. CID indicates the likelihood of two points or two sets of points belonging to different convex parts of an underlying shape represented as a point cloud. After analyzing its properties, we demonstrate how CID can benefit point cloud analysis without the need for meshing or normal estimation, which is beneficial for robotics applications when dealing with raw point cloud observations. By randomly selecting very few points for manual labeling, a CID-based point cloud instance segmentation via label propagation achieves comparable average precision as recent supervised deep learning approaches, on S3DIS and ScanNet datasets. Moreover, CID can be used to group points into approximately convex parts whose convex hulls can be used as compact scene representations in robotics, and it outperforms the baseline method in terms of grouping quality. Our project website is available at: https://ai4ce.github.io/CID/
GRASP-Net: Geometric Residual Analysis and Synthesis for Point Cloud Compression
Sep 09, 2022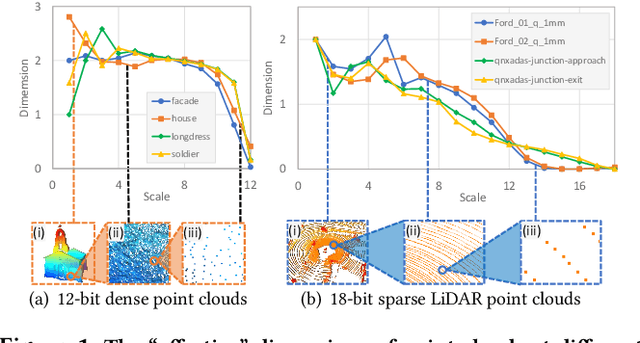

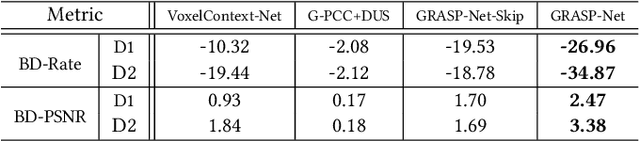
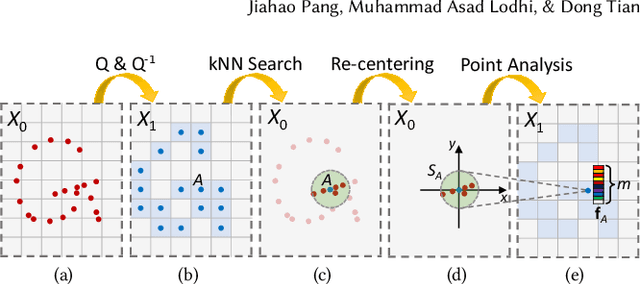
Point cloud compression (PCC) is a key enabler for various 3-D applications, owing to the universality of the point cloud format. Ideally, 3D point clouds endeavor to depict object/scene surfaces that are continuous. Practically, as a set of discrete samples, point clouds are locally disconnected and sparsely distributed. This sparse nature is hindering the discovery of local correlation among points for compression. Motivated by an analysis with fractal dimension, we propose a heterogeneous approach with deep learning for lossy point cloud geometry compression. On top of a base layer compressing a coarse representation of the input, an enhancement layer is designed to cope with the challenging geometric residual/details. Specifically, a point-based network is applied to convert the erratic local details to latent features residing on the coarse point cloud. Then a sparse convolutional neural network operating on the coarse point cloud is launched. It utilizes the continuity/smoothness of the coarse geometry to compress the latent features as an enhancement bit-stream that greatly benefits the reconstruction quality. When this bit-stream is unavailable, e.g., due to packet loss, we support a skip mode with the same architecture which generates geometric details from the coarse point cloud directly. Experimentation on both dense and sparse point clouds demonstrate the state-of-the-art compression performance achieved by our proposal. Our code is available at https://github.com/InterDigitalInc/GRASP-Net.
FESTA: Flow Estimation via Spatial-Temporal Attention for Scene Point Clouds
Apr 01, 2021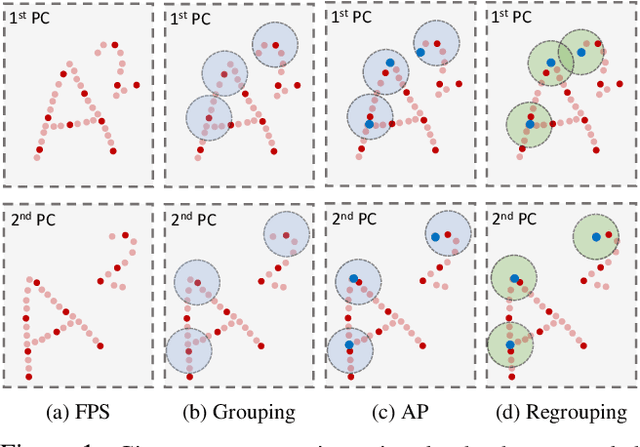
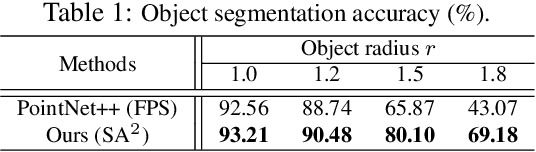
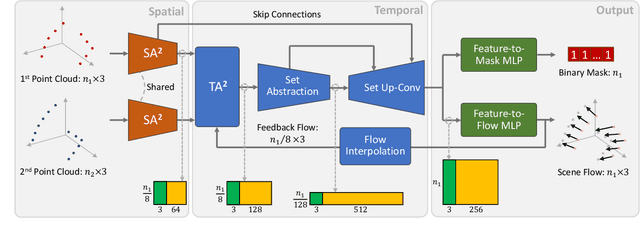
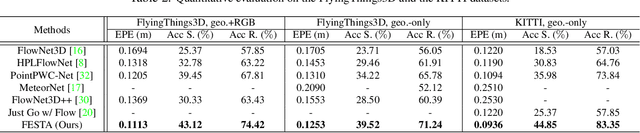
Scene flow depicts the dynamics of a 3D scene, which is critical for various applications such as autonomous driving, robot navigation, AR/VR, etc. Conventionally, scene flow is estimated from dense/regular RGB video frames. With the development of depth-sensing technologies, precise 3D measurements are available via point clouds which have sparked new research in 3D scene flow. Nevertheless, it remains challenging to extract scene flow from point clouds due to the sparsity and irregularity in typical point cloud sampling patterns. One major issue related to irregular sampling is identified as the randomness during point set abstraction/feature extraction -- an elementary process in many flow estimation scenarios. A novel Spatial Abstraction with Attention (SA^2) layer is accordingly proposed to alleviate the unstable abstraction problem. Moreover, a Temporal Abstraction with Attention (TA^2) layer is proposed to rectify attention in temporal domain, leading to benefits with motions scaled in a larger range. Extensive analysis and experiments verified the motivation and significant performance gains of our method, dubbed as Flow Estimation via Spatial-Temporal Attention (FESTA), when compared to several state-of-the-art benchmarks of scene flow estimation.