 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Markov Decision Processes with Reachability Characterization from Mean First Passage Times
Jan 04, 2019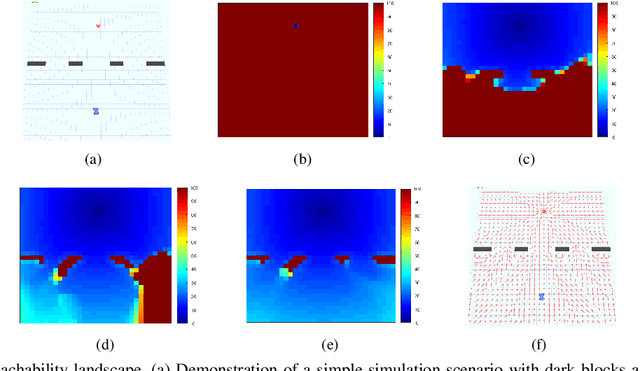
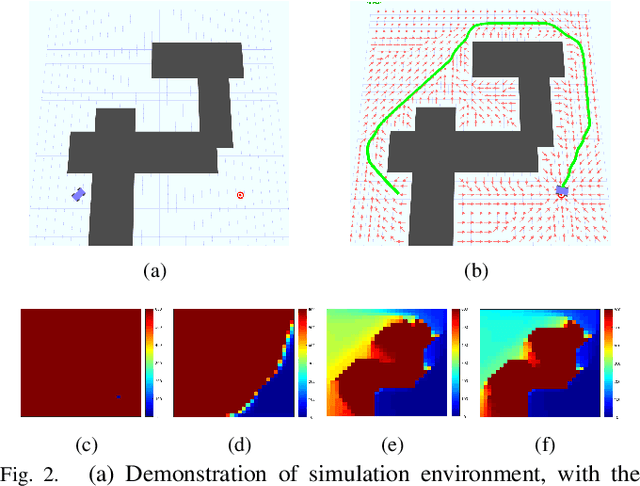
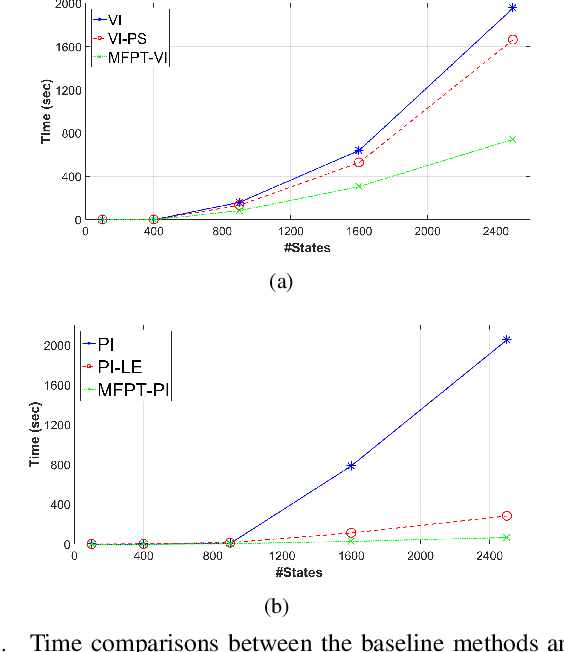
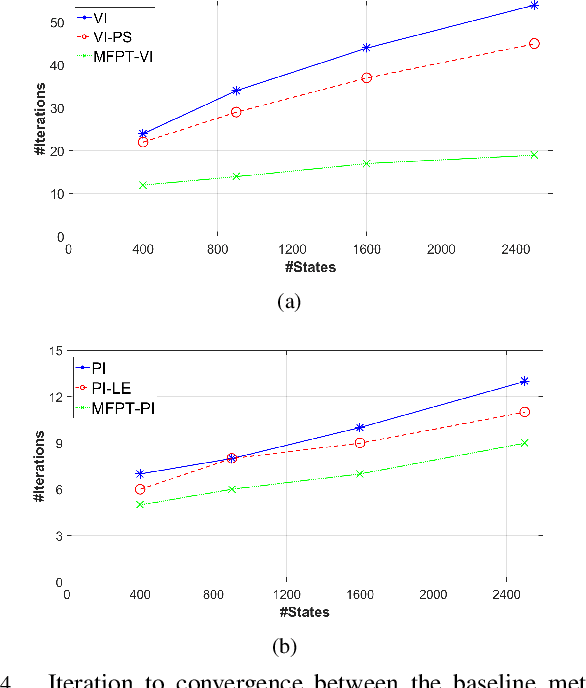
A new mechanism for efficiently solving the Markov decision processes (MDPs) is proposed in this paper. We introduce the notion of reachability landscape where we use the Mean First Passage Time (MFPT) as a means to characterize the reachability of every state in the state space. We show that such reachability characterization very well assesses the importance of states and thus provides a natural basis for effectively prioritizing states and approximating policies. Built on such a novel observation, we design two new algorithms -- Mean First Passage Time based Value Iteration (MFPT-VI) and Mean First Passage Time based Policy Iteration (MFPT-PI) -- that have been modified from the state-of-the-art solution methods. To validate our design, we have performed numerical evaluations in robotic decision-making scenarios, by comparing the proposed new methods with corresponding classic baseline mechanisms. The evaluation results showed that MFPT-VI and MFPT-PI have outperformed the state-of-the-art solutions in terms of both practical runtime and number of iterations. Aside from the advantage of fast convergence, this new solution method is intuitively easy to understand and practically simple to implement.
Reachability and Differential based Heuristics for Solving Markov Decision Processes
Jan 03, 2019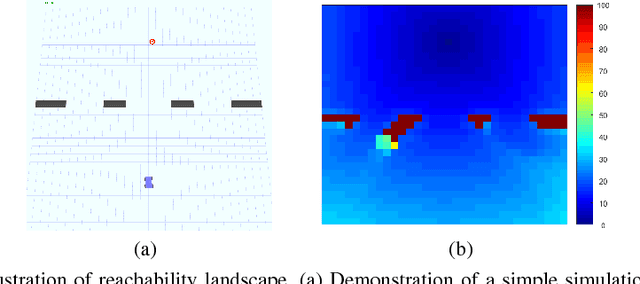
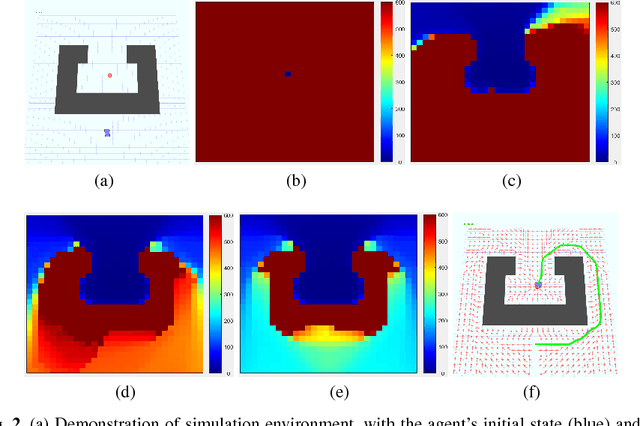
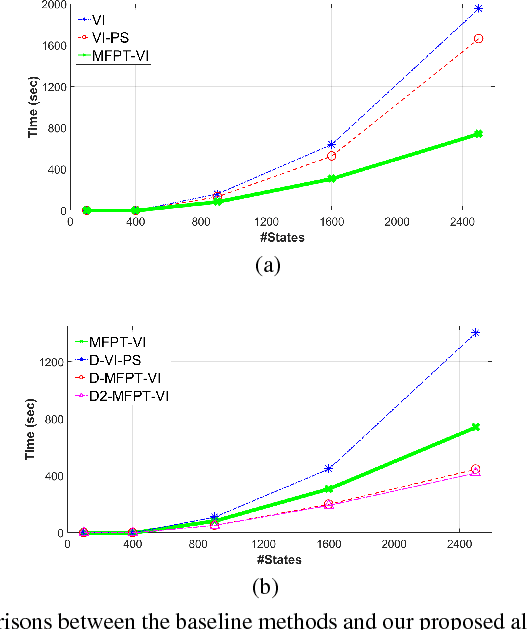
The solution convergence of Markov Decision Processes (MDPs) can be accelerated by prioritized sweeping of states ranked by their potential impacts to other states. In this paper, we present new heuristics to speed up the solution convergence of MDPs. First, we quantify the level of reachability of every state using the Mean First Passage Time (MFPT) and show that such reachability characterization very well assesses the importance of states which is used for effective state prioritization. Then, we introduce the notion of backup differentials as an extension to the prioritized sweeping mechanism, in order to evaluate the impacts of states at an even finer scale. Finally, we extend the state prioritization to the temporal process, where only partial sweeping can be performed during certain intermediate value iteration stages. To validate our design, we have performed numerical evaluations by comparing the proposed new heuristics with corresponding classic baseline mechanisms. The evaluation results showed that our reachability based framework and its differential variants have outperformed the state-of-the-art solutions in terms of both practical runtime and number of iterations.
Scaling simulation-to-real transfer by learning composable robot skills
Nov 13, 2018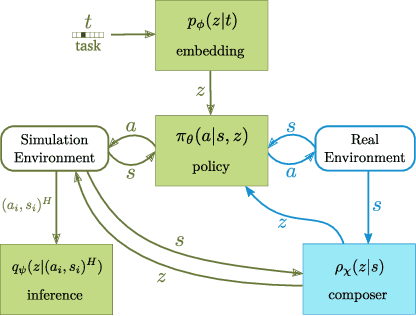
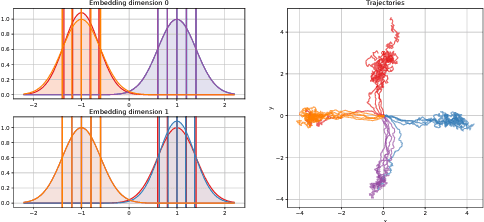

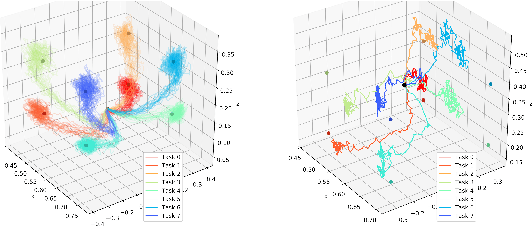
We present a novel solution to the problem of simulation-to-real transfer, which builds on recent advances in robot skill decomposition. Rather than focusing on minimizing the simulation-reality gap, we learn a set of diverse policies that are parameterized in a way that makes them easily reusable. This diversity and parameterization of low-level skills allows us to find a transferable policy that is able to use combinations and variations of different skills to solve more complex, high-level tasks. In particular, we first use simulation to jointly learn a policy for a set of low-level skills, and a "skill embedding" parameterization which can be used to compose them. Later, we learn high-level policies which actuate the low-level policies via this skill embedding parameterization. The high-level policies encode how and when to reuse the low-level skills together to achieve specific high-level tasks. Importantly, our method learns to control a real robot in joint-space to achieve these high-level tasks with little or no on-robot time, despite the fact that the low-level policies may not be perfectly transferable from simulation to real, and that the low-level skills were not trained on any examples of high-level tasks. We illustrate the principles of our method using informative simulation experiments. We then verify its usefulness for real robotics problems by learning, transferring, and composing free-space and contact motion skills on a Sawyer robot using only joint-space control. We experiment with several techniques for composing pre-learned skills, and find that our method allows us to use both learning-based approaches and efficient search-based planning to achieve high-level tasks using only pre-learned skills.
Zero-Shot Skill Composition and Simulation-to-Real Transfer by Learning Task Representations
Nov 13, 2018

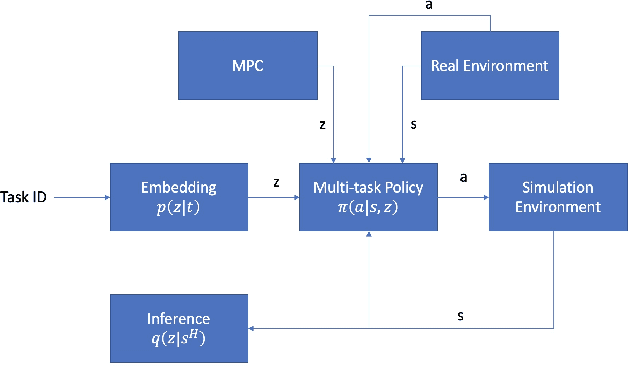
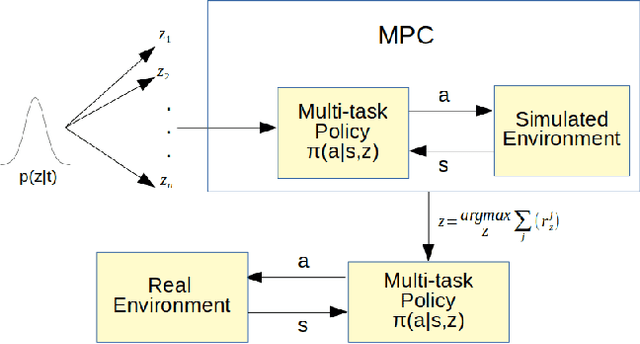
Simulation-to-real transfer is an important strategy for making reinforcement learning practical with real robots. Successful sim-to-real transfer systems have difficulty producing policies which generalize across tasks, despite training for thousands of hours equivalent real robot time. To address this shortcoming, we present a novel approach to efficiently learning new robotic skills directly on a real robot, based on model-predictive control (MPC) and an algorithm for learning task representations. In short, we show how to reuse the simulation from the pre-training step of sim-to-real methods as a tool for foresight, allowing the sim-to-real policy adapt to unseen tasks. Rather than end-to-end learning policies for single tasks and attempting to transfer them, we first use simulation to simultaneously learn (1) a continuous parameterization (i.e. a skill embedding or latent) of task-appropriate primitive skills, and (2) a single policy for these skills which is conditioned on this representation. We then directly transfer our multi-skill policy to a real robot, and actuate the robot by choosing sequences of skill latents which actuate the policy, with each latent corresponding to a pre-learned primitive skill controller. We complete unseen tasks by choosing new sequences of skill latents to control the robot using MPC, where our MPC model is composed of the pre-trained skill policy executed in the simulation environment, run in parallel with the real robot. We discuss the background and principles of our method, detail its practical implementation, and evaluate its performance by using our method to train a real Sawyer Robot to achieve motion tasks such as drawing and block pushing.
Region Growing Curriculum Generation for Reinforcement Learning
Jul 04, 2018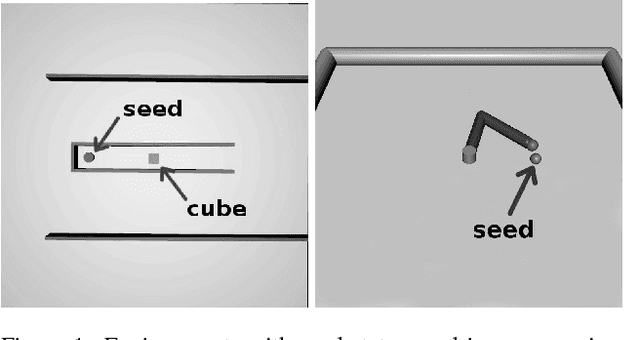
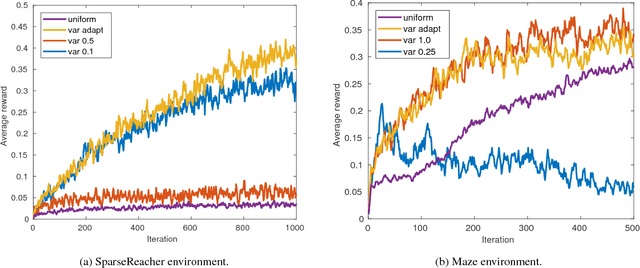
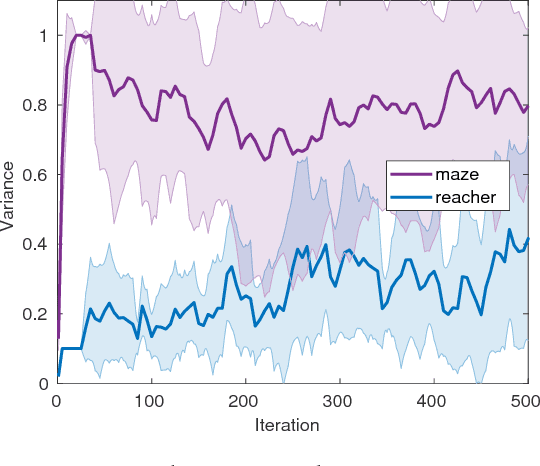
Learning a policy capable of moving an agent between any two states in the environment is important for many robotics problems involving navigation and manipulation. Due to the sparsity of rewards in such tasks, applying reinforcement learning in these scenarios can be challenging. Common approaches for tackling this problem include reward engineering with auxiliary rewards, requiring domain-specific knowledge or changing the objective. In this work, we introduce a method based on region-growing that allows learning in an environment with any pair of initial and goal states. Our algorithm first learns how to move between nearby states and then increases the difficulty of the start-goal transitions as the agent's performance improves. This approach creates an efficient curriculum for learning the objective behavior of reaching any goal from any initial state. In addition, we describe a method to adaptively adjust expansion of the growing region that allows automatic adjustment of the key exploration hyperparameter to environments with different requirements. We evaluate our approach on a set of simulated navigation and manipulation tasks, where we demonstrate that our algorithm can efficiently learn a policy in the presence of sparse rewards.
Interactive Perception: Leveraging Action in Perception and Perception in Action
Dec 06, 2017
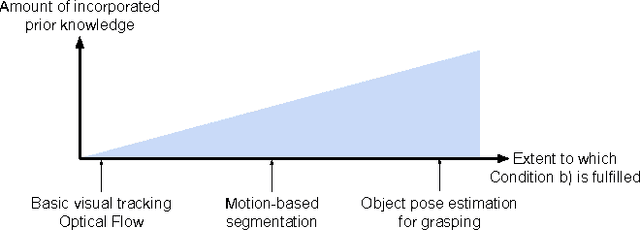
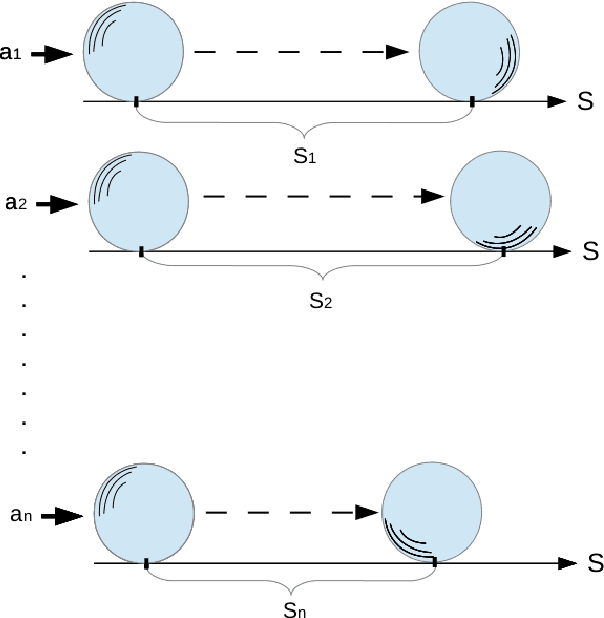
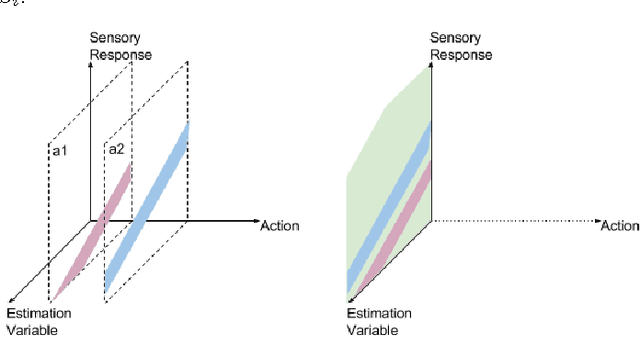
Recent approaches in robotics follow the insight that perception is facilitated by interaction with the environment. These approaches are subsumed under the term of Interactive Perception (IP). It provides the following benefits: (i) interaction with the environment creates a rich sensory signal that would otherwise not be present and (ii) knowledge of the regularity in the combined space of sensory data and action parameters facilitate the prediction and interpretation of the signal. In this survey we postulate this as a principle and collect evidence in support by analyzing and categorizing existing work in this area. We also provide an overview of the most important applications of Interactive Perception. We close this survey by discussing remaining open questions. Thereby, we hope to define a field and inspire future work.
* Equal contribution by first three authors
Multi-Modal Imitation Learning from Unstructured Demonstrations using Generative Adversarial Nets
Nov 23, 2017


Imitation learning has traditionally been applied to learn a single task from demonstrations thereof. The requirement of structured and isolated demonstrations limits the scalability of imitation learning approaches as they are difficult to apply to real-world scenarios, where robots have to be able to execute a multitude of tasks. In this paper, we propose a multi-modal imitation learning framework that is able to segment and imitate skills from unlabelled and unstructured demonstrations by learning skill segmentation and imitation learning jointly. The extensive simulation results indicate that our method can efficiently separate the demonstrations into individual skills and learn to imitate them using a single multi-modal policy. The video of our experiments is available at http://sites.google.com/view/nips17intentiongan
Combining Model-Based and Model-Free Updates for Trajectory-Centric Reinforcement Learning
Jun 18, 2017
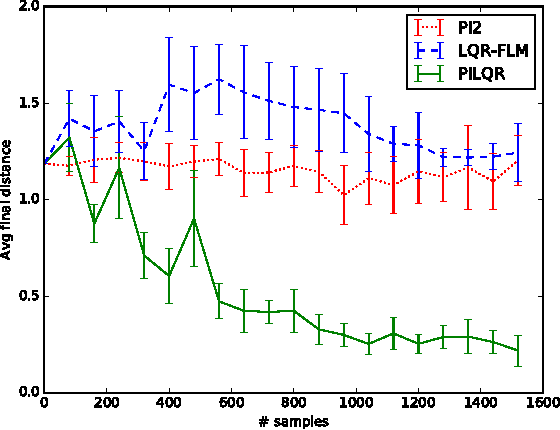
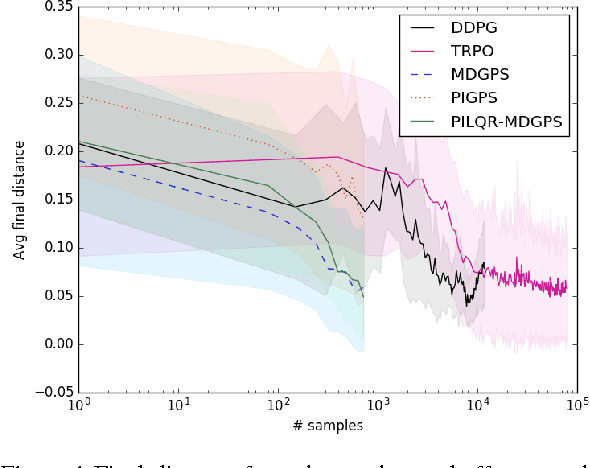
Reinforcement learning (RL) algorithms for real-world robotic applications need a data-efficient learning process and the ability to handle complex, unknown dynamical systems. These requirements are handled well by model-based and model-free RL approaches, respectively. In this work, we aim to combine the advantages of these two types of methods in a principled manner. By focusing on time-varying linear-Gaussian policies, we enable a model-based algorithm based on the linear quadratic regulator (LQR) that can be integrated into the model-free framework of path integral policy improvement (PI2). We can further combine our method with guided policy search (GPS) to train arbitrary parameterized policies such as deep neural networks. Our simulation and real-world experiments demonstrate that this method can solve challenging manipulation tasks with comparable or better performance than model-free methods while maintaining the sample efficiency of model-based methods. A video presenting our results is available at https://sites.google.com/site/icml17pilqr
Observability-Aware Trajectory Optimization for Self-Calibration with Application to UAVs
Apr 27, 2016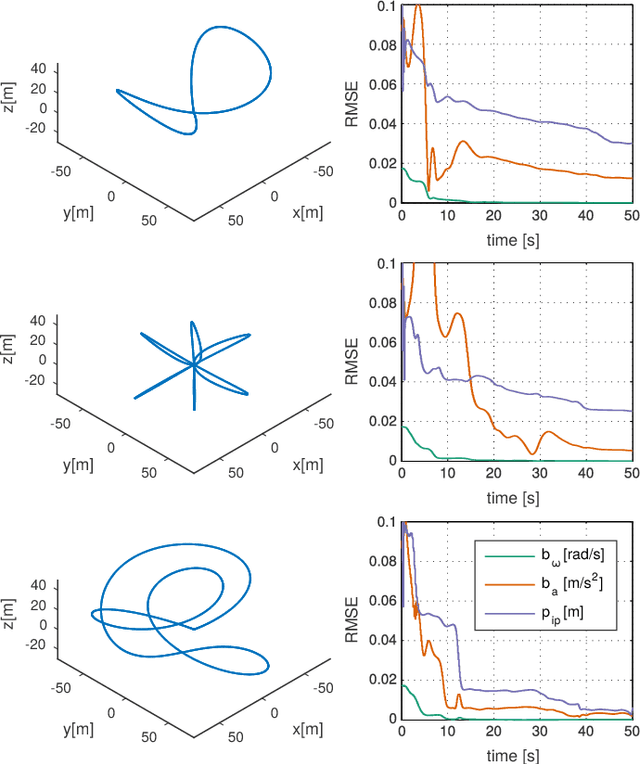
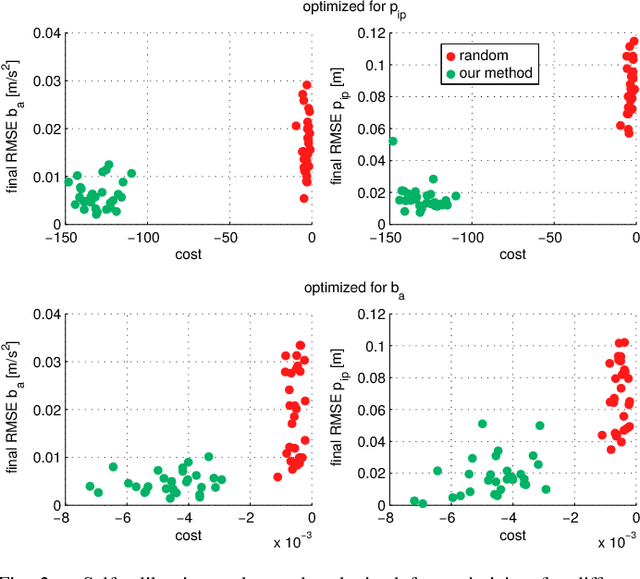
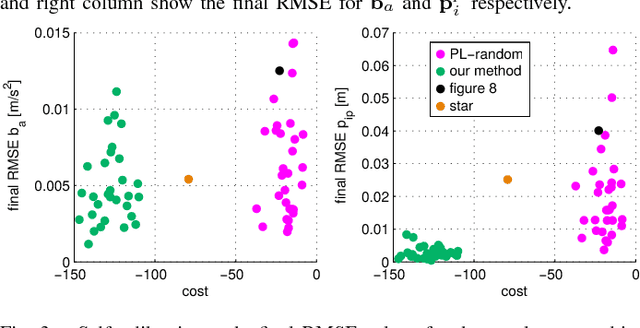
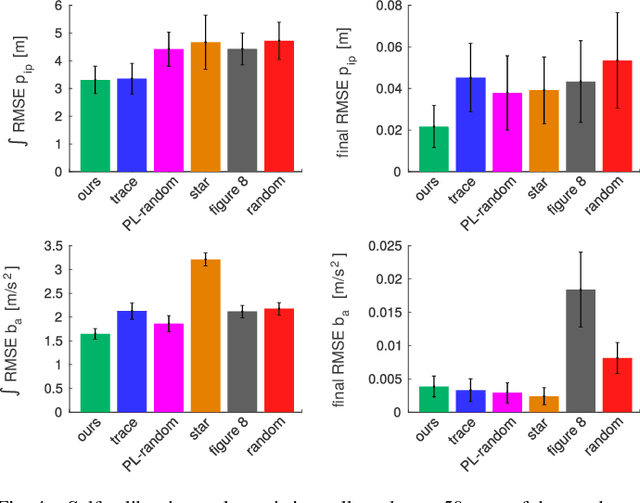
We study the nonlinear observability of a systems states in view of how well they are observable and what control inputs would improve the convergence of their estimates. We use these insights to develop an observability-aware trajectory-optimization framework for nonlinear systems that produces trajectories well suited for self-calibration. Common trajectory-planning algorithms tend to generate motions that lead to an unobservable subspace of the system state, causing suboptimal state estimation. We address this problem with a method that reasons about the quality of observability while respecting system dynamics and motion constraints to yield the optimal trajectory for rapid convergence of the self-calibration states (or other user-chosen states). Experiments performed on a simulated quadrotor system with a GPS-IMU sensor suite demonstrate the benefits of the optimized observability-aware trajectories when compared to a covariance-based approach and multiple heuristic approaches. Our method is approx. 80x faster than the covariance-based approach and achieves better results than any other approach in the self-calibration task. We applied our method to a waypoint navigation task and achieved a approx. 2x improvement in the integrated RMSE of the global position estimates and approx. 4x improvement in the integrated RMSE of the GPS-IMU transformation estimates compared to a minimal-energy trajectory planner.
Decentralized Data Fusion and Active Sensing with Mobile Sensors for Modeling and Predicting Spatiotemporal Traffic Phenomena
Aug 09, 2014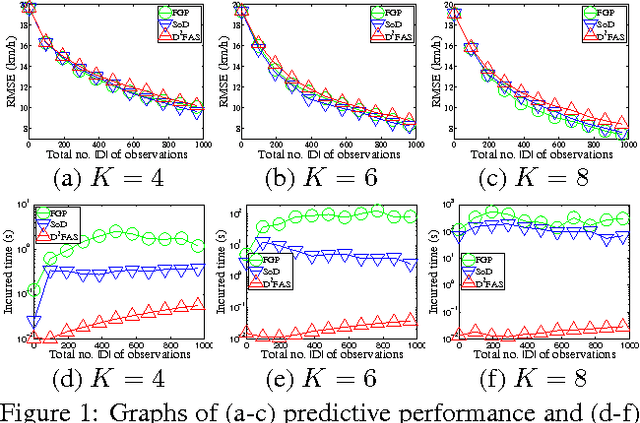
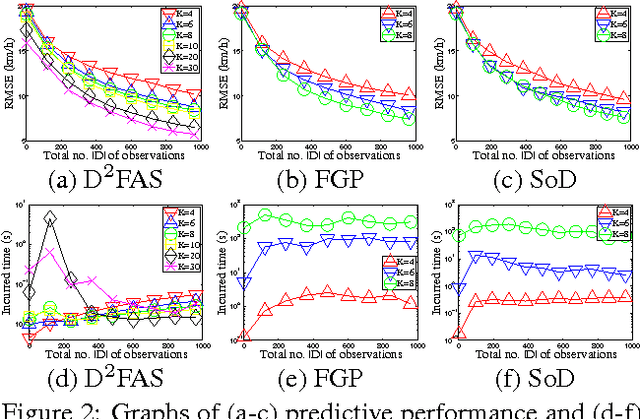
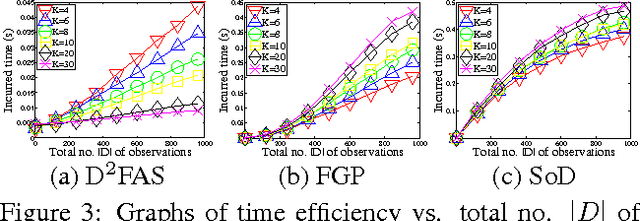
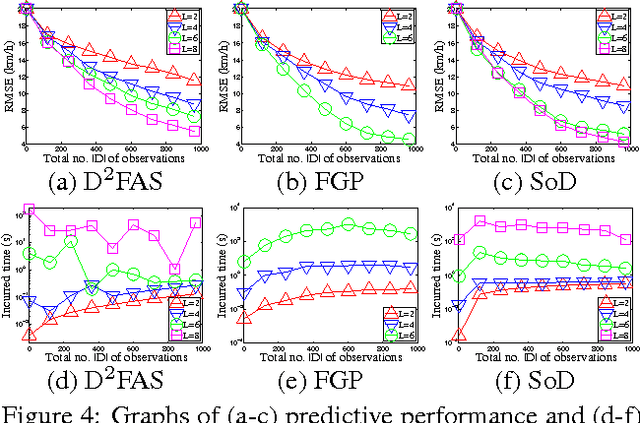
The problem of modeling and predicting spatiotemporal traffic phenomena over an urban road network is important to many traffic applications such as detecting and forecasting congestion hotspots. This paper presents a decentralized data fusion and active sensing (D2FAS) algorithm for mobile sensors to actively explore the road network to gather and assimilate the most informative data for predicting the traffic phenomenon. We analyze the time and communication complexity of D2FAS and demonstrate that it can scale well with a large number of observations and sensors. We provide a theoretical guarantee on its predictive performance to be equivalent to that of a sophisticated centralized sparse approximation for the Gaussian process (GP) model: The computation of such a sparse approximate GP model can thus be parallelized and distributed among the mobile sensors (in a Google-like MapReduce paradigm), thereby achieving efficient and scalable prediction. We also theoretically guarantee its active sensing performance that improves under various practical environmental conditions. Empirical evaluation on real-world urban road network data shows that our D2FAS algorithm is significantly more time-efficient and scalable than state-oftheart centralized algorithms while achieving comparable predictive performance.