 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan-Space State Embeddings for Improved Reinforcement Learning
Apr 30, 2020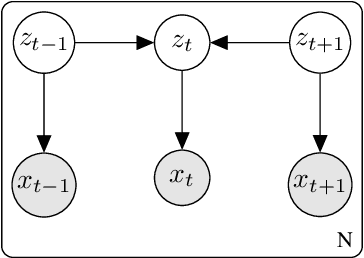
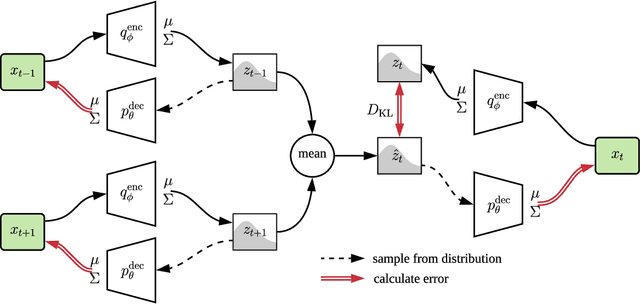
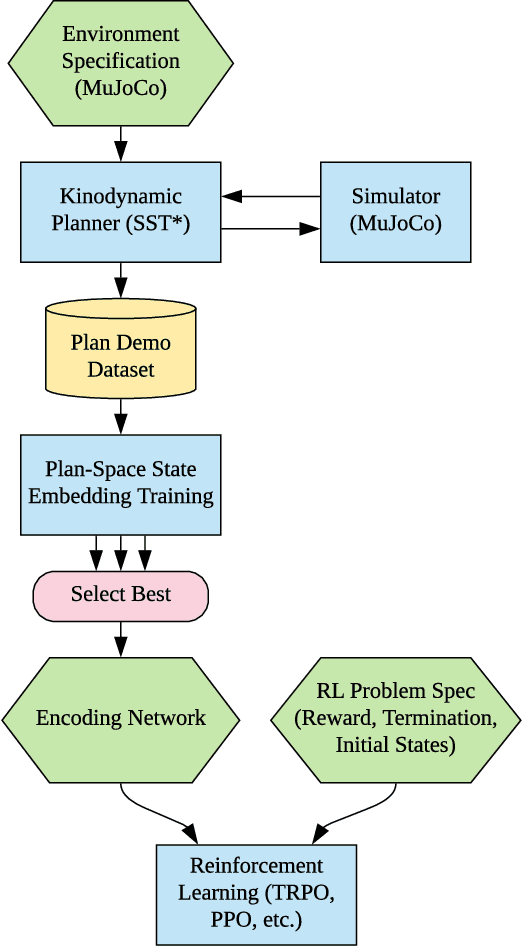
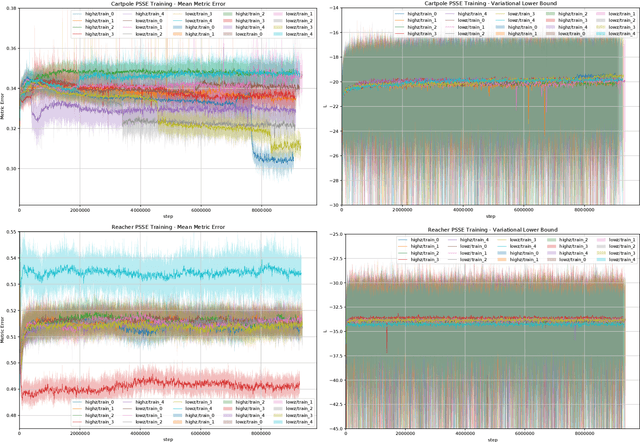
Robot control problems are often structured with a policy function that maps state values into control values, but in many dynamic problems the observed state can have a difficult to characterize relationship with useful policy actions. In this paper we present a new method for learning state embeddings from plans or other forms of demonstrations such that the embedding space has a specified geometric relationship with the demonstrations. We present a novel variational framework for learning these embeddings that attempts to optimize trajectory linearity in the learned embedding space. We show how these embedding spaces can then be used as an augmentation to the robot state in reinforcement learning problems. We use kinodynamic planning to generate training trajectories for some example environments, and then train embedding spaces for these environments. We show empirically that observing a system in the learned embedding space improves the performance of policy gradient reinforcement learning algorithms, particularly by reducing the variance between training runs. Our technique is limited to environments where demonstration data is available, but places no limits on how that data is collected. Our embedding technique provides a way to transfer domain knowledge from existing technologies such as planning and control algorithms, into more flexible policy learning algorithms, by creating an abstract representation of the robot state with meaningful geometry.
Efficient Adaptation for End-to-End Vision-Based Robotic Manipulation
Apr 21, 2020
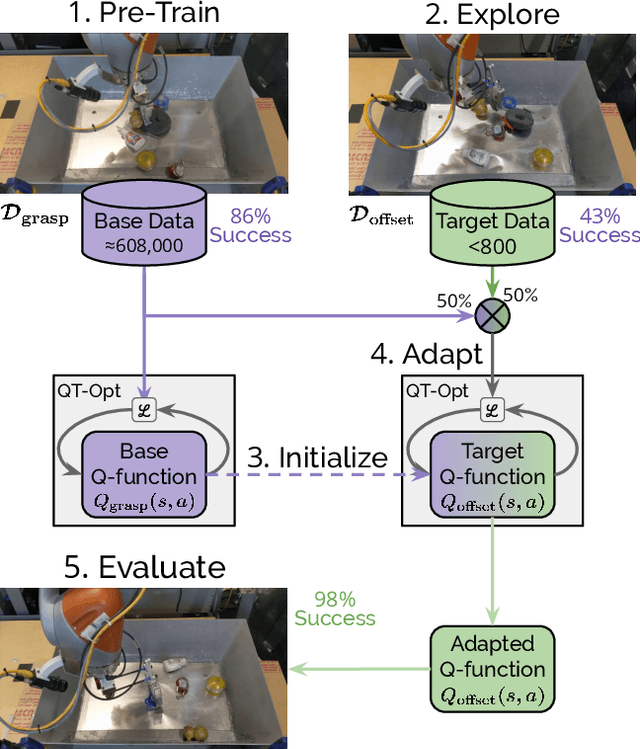
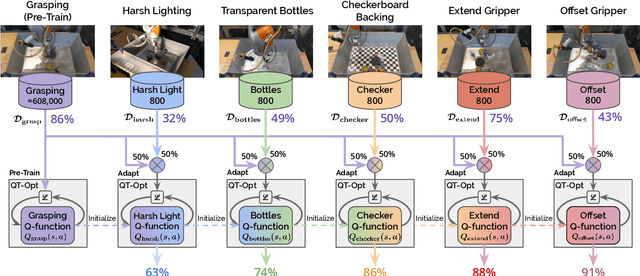
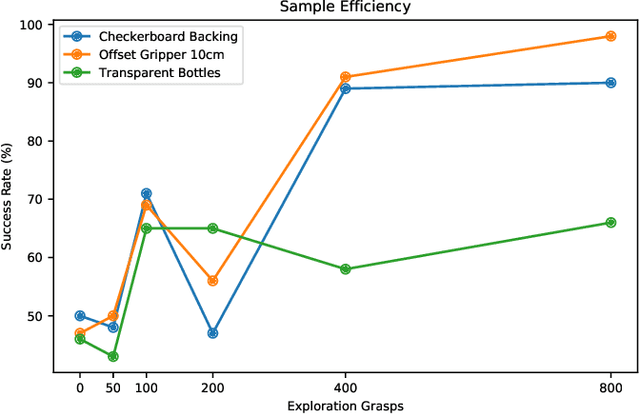
One of the great promises of robot learning systems is that they will be able to learn from their mistakes and continuously adapt to ever-changing environments. Despite this potential, most of the robot learning systems today are deployed as a fixed policy and they are not being adapted after their deployment. Can we efficiently adapt previously learned behaviors to new environments, objects and percepts in the real world? In this paper, we present a method and empirical evidence towards a robot learning framework that facilitates continuous adaption. In particular, we demonstrate how to adapt vision-based robotic manipulation policies to new variations by fine-tuning via off-policy reinforcement learning, including changes in background, object shape and appearance, lighting conditions, and robot morphology. Further, this adaptation uses less than 0.2% of the data necessary to learn the task from scratch. We find that our approach of adapting pre-trained policies leads to substantial performance gains over the course of fine-tuning, and that pre-training via RL is essential: training from scratch or adapting from supervised ImageNet features are both unsuccessful with such small amounts of data. We also find that these positive results hold in a limited continual learning setting, in which we repeatedly fine-tune a single lineage of policies using data from a succession of new tasks. Our empirical conclusions are consistently supported by experiments on simulated manipulation tasks, and by 52 unique fine-tuning experiments on a real robotic grasping system pre-trained on 580,000 grasps.
Resilience in multi-robot multi-target tracking with unknown number of targets through reconfiguration
Apr 15, 2020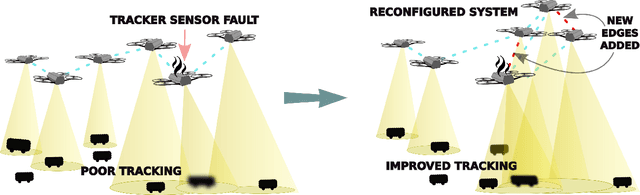
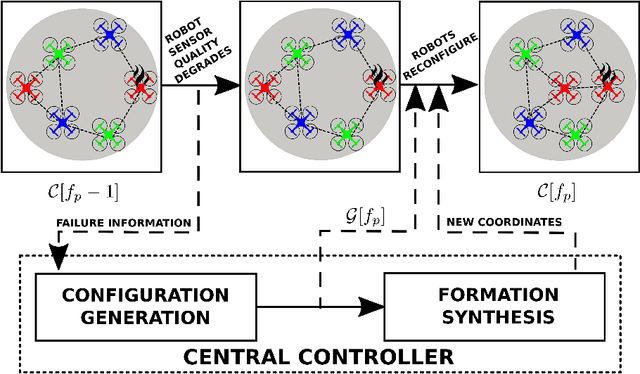
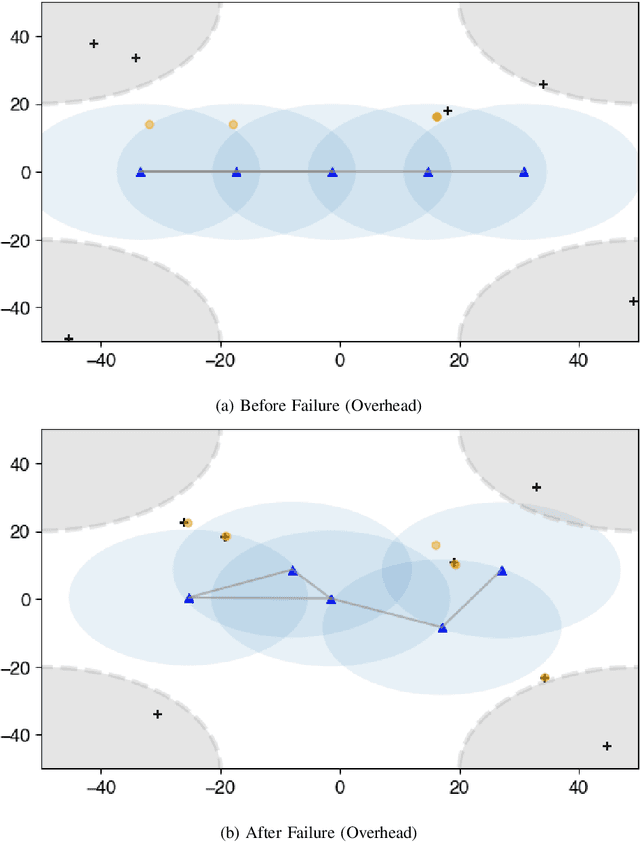
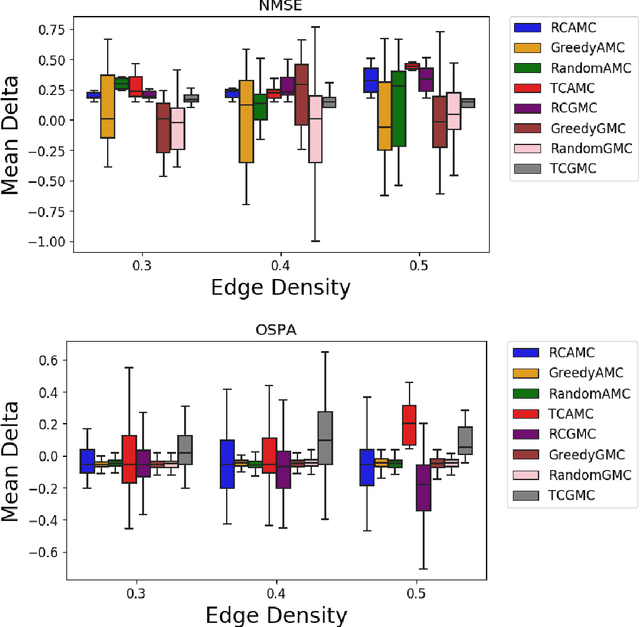
We address the problem of maintaining resource availability in a networked multi-robot team performing distributed tracking of unknown number of targets in an environment of interest. Based on our model, robots are equipped with sensing and computational resources enabling them to cooperatively track a set of targets in an environment using a distributed Probability Hypothesis Density (PHD) filter. We use the trace of a robot's sensor measurement noise covariance matrix to quantify its sensing quality. While executing the tracking task, if a robot experiences sensor quality degradation, then robot team's communication network is reconfigured such that the robot with the faulty sensor may share information with other robots to improve the team's target tracking ability without enforcing a large change in the number of active communication links. A central system which monitors the team executes all the network reconfiguration computations. We consider two different PHD fusion methods in this paper and propose four different Mixed Integer Semi-Definite Programming (MISDP) formulations (two formulations for each PHD fusion method) to accomplish our objective. All four MISDP formulations are validated in simulation.
On Localizing a Camera from a Single Image
Mar 24, 2020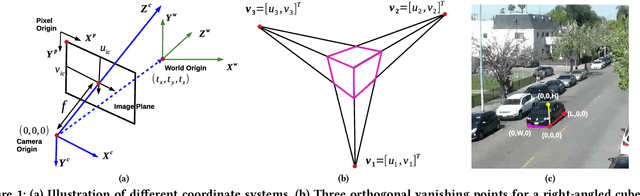



Public cameras often have limited metadata describing their attributes. A key missing attribute is the precise location of the camera, using which it is possible to precisely pinpoint the location of events seen in the camera. In this paper, we explore the following question: under what conditions is it possible to estimate the location of a camera from a single image taken by the camera? We show that, using a judicious combination of projective geometry, neural networks, and crowd-sourced annotations from human workers, it is possible to position 95% of the images in our test data set to within 12 m. This performance is two orders of magnitude better than PoseNet, a state-of-the-art neural network that, when trained on a large corpus of images in an area, can estimate the pose of a single image. Finally, we show that the camera's inferred position and intrinsic parameters can help design a number of virtual sensors, all of which are reasonably accurate.
Experimental Comparison of Global Motion Planning Algorithms for Wheeled Mobile Robots
Mar 07, 2020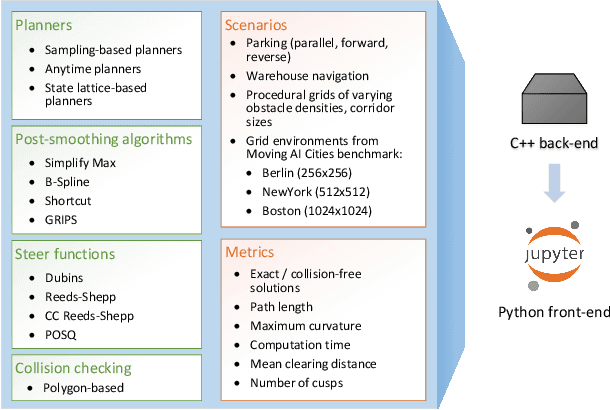
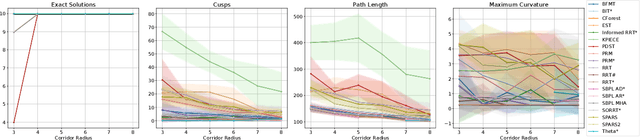
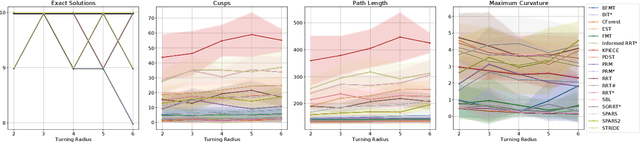
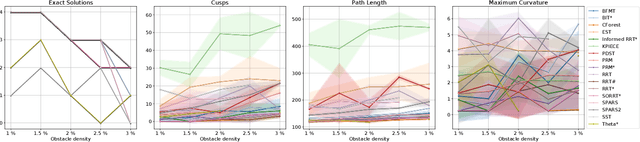
Planning smooth and energy-efficient motions for wheeled mobile robots is a central task for applications ranging from autonomous driving to service and intralogistic robotics. Over the past decades, a wide variety of motion planners, steer functions and path-improvement techniques have been proposed for such non-holonomic systems. With the objective of comparing this large assortment of state-of-the-art motion-planning techniques, we introduce a novel open-source motion-planning benchmark for wheeled mobile robots, whose scenarios resemble real-world applications (such as navigating warehouses, moving in cluttered cities or parking), and propose metrics for planning efficiency and path quality. Our benchmark is easy to use and extend, and thus allows practitioners and researchers to evaluate new motion-planning algorithms, scenarios and metrics easily. We use our benchmark to highlight the strengths and weaknesses of several common state-of-the-art motion planners and provide recommendations on when they should be used.
Automatic Differentiation and Continuous Sensitivity Analysis of Rigid Body Dynamics
Jan 22, 2020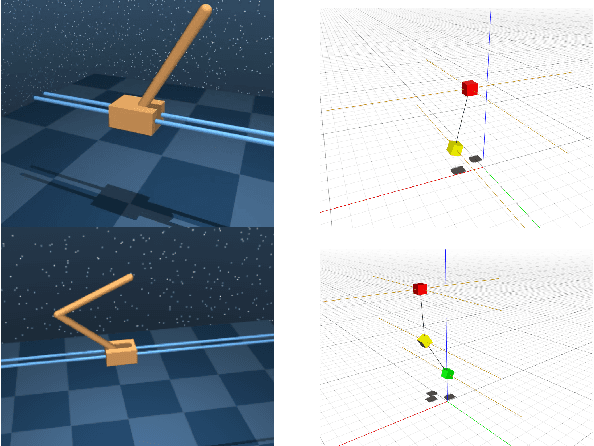

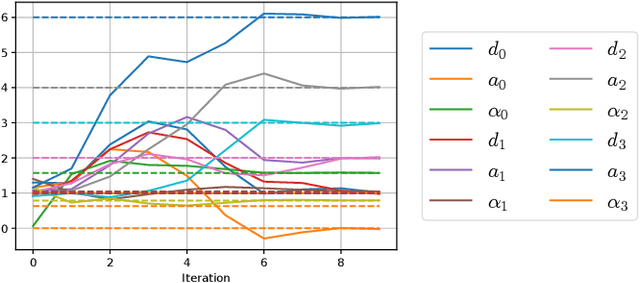
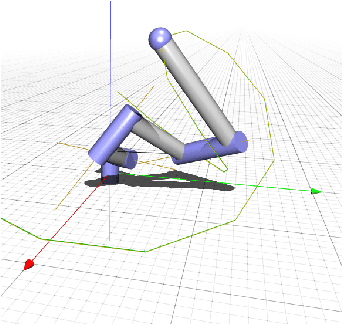
A key ingredient to achieving intelligent behavior is physical understanding that equips robots with the ability to reason about the effects of their actions in a dynamic environment. Several methods have been proposed to learn dynamics models from data that inform model-based control algorithms. While such learning-based approaches can model locally observed behaviors, they fail to generalize to more complex dynamics and under long time horizons. In this work, we introduce a differentiable physics simulator for rigid body dynamics. Leveraging various techniques for differential equation integration and gradient calculation, we compare different methods for parameter estimation that allow us to infer the simulation parameters that are relevant to estimation and control of physical systems. In the context of trajectory optimization, we introduce a closed-loop model-predictive control algorithm that infers the simulation parameters through experience while achieving cost-minimizing performance.
Physics-based Simulation of Continuous-Wave LIDAR for Localization, Calibration and Tracking
Dec 03, 2019
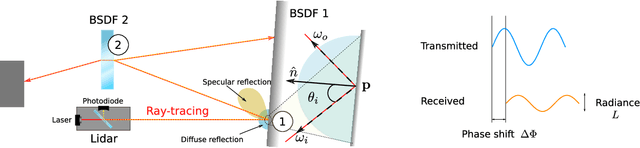


Light Detection and Ranging (LIDAR) sensors play an important role in the perception stack of autonomous robots, supplying mapping and localization pipelines with depth measurements of the environment. While their accuracy outperforms other types of depth sensors, such as stereo or time-of-flight cameras, the accurate modeling of LIDAR sensors requires laborious manual calibration that typically does not take into account the interaction of laser light with different surface types, incidence angles and other phenomena that significantly influence measurements. In this work, we introduce a physically plausible model of a 2D continuous-wave LIDAR that accounts for the surface-light interactions and simulates the measurement process in the Hokuyo URG-04LX LIDAR. Through automatic differentiation, we employ gradient-based optimization to estimate model parameters from real sensor measurements.
Resilient Coverage: Exploring the Local-to-Global Trade-off
Oct 03, 2019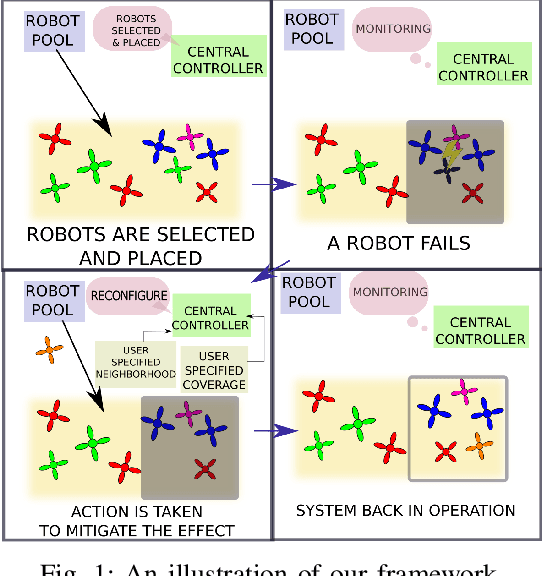
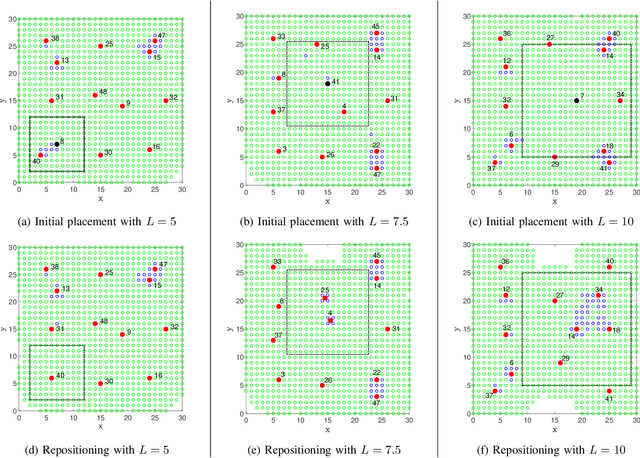
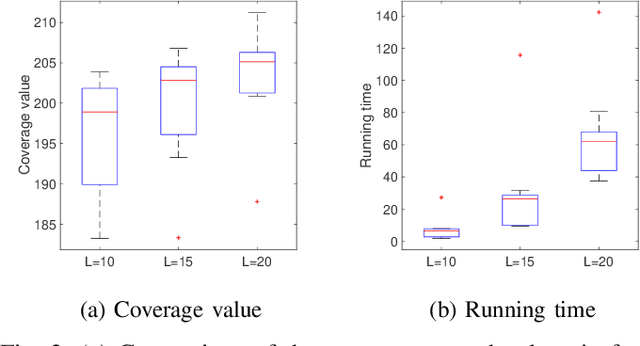
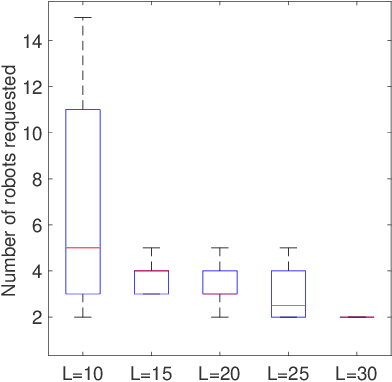
We propose a centralized control framework to select suitable robots from a heterogeneous pool and place them at appropriate locations to monitor a region for events of interest. In the event of a robot failure, the framework repositions robots in a user-defined local neighborhood of the failed robot to compensate for the coverage loss. The central controller augments the team with additional robots from the robot pool when simply repositioning robots fails to attain a user-specified level of desired coverage. The size of the local neighborhood around the failed robot and the desired coverage over the region are two settings that can be manipulated to achieve a user-specified balance. We investigate the trade-off between the coverage compensation achieved through local repositioning and the computation required to plan the new robot locations. We also study the relationship between the size of the local neighborhood and the number of additional robots added to the team for a given user-specified level of desired coverage. The computational complexity of our resilient strategy (tunable resilient coordination), is quadratic in both neighborhood size and number of robots in the team. At first glance, it seems that any desired level of coverage can be efficiently achieved by augmenting the robot team with more robots while keeping the neighborhood size fixed. However, we show that to reach a high level of coverage in a neighborhood with a large robot population, it is more efficient to enlarge the neighborhood size, instead of adding additional robots and repositioning them.
Resilience in multi-robot target tracking through reconfiguration
Oct 03, 2019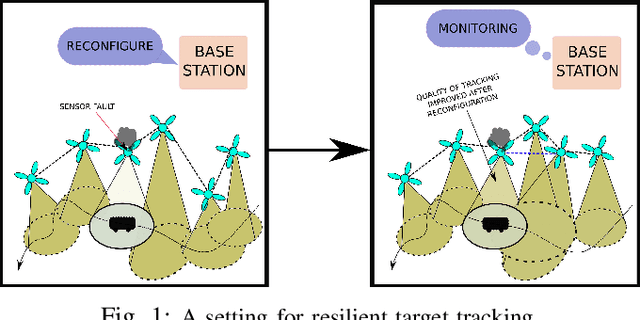
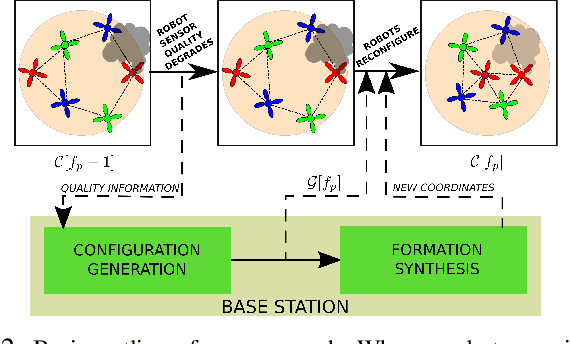
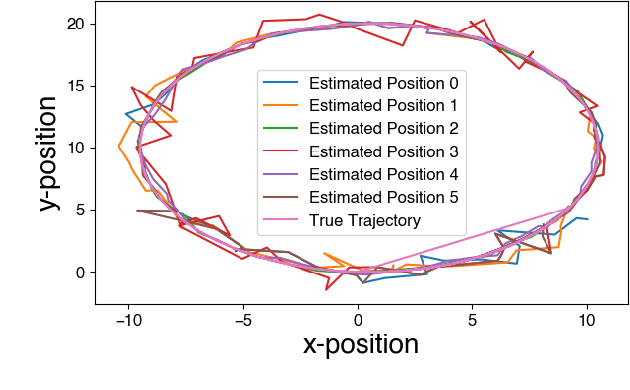
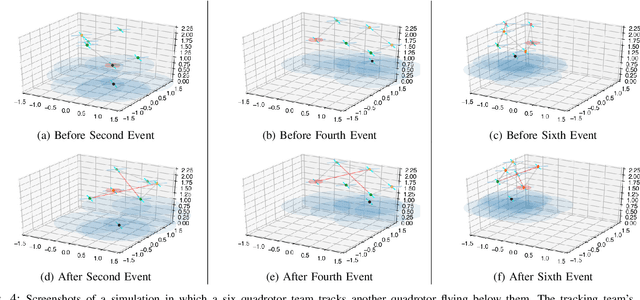
We address the problem of maintaining resource availability in a networked multi-robot system performing distributed target tracking. In our model, robots are equipped with sensing and computational resources enabling them to track a target's position using a Distributed Kalman Filter (DKF). We use the trace of each robot's sensor measurement noise covariance matrix as a measure of sensing quality. When a robot's sensing quality deteriorates, the system's communication graph is modified by adding edges such that the robot with deteriorating sensor quality may share information with other robots to improve the team's target tracking ability. This computation is performed centrally and is designed to work without a large change in the number of active communication links. We propose two mixed integer semi-definite programming formulations (an 'agent-centric' strategy and a 'team-centric' strategy) to achieve this goal. We implement both formulations and a greedy strategy in simulation and show that the team-centric strategy outperforms the agent-centric and greedy strategies.
Interactive Differentiable Simulation
May 26, 2019
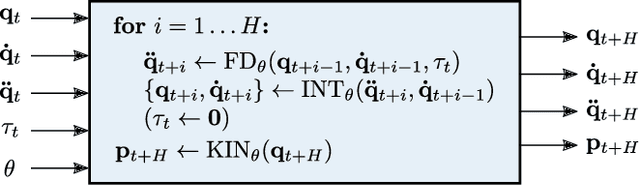
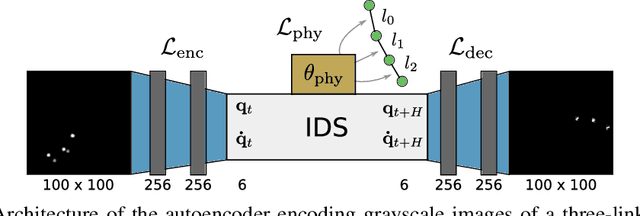
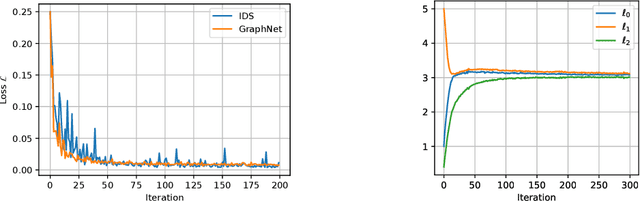
Intelligent agents need a physical understanding of the world to predict the impact of their actions in the future. While learning-based models of the environment dynamics have contributed to significant improvements in sample efficiency compared to model-free reinforcement learning algorithms, they typically fail to generalize to system states beyond the training data, while often grounding their predictions on non-interpretable latent variables. We introduce Interactive Differentiable Simulation (IDS), a differentiable physics engine, that allows for efficient, accurate inference of physical properties of rigid-body systems. Integrated into deep learning architectures, our model is able to accomplish system identification using visual input, leading to an interpretable model of the world whose parameters have physical meaning. We present experiments showing automatic task-based robot design and parameter estimation for nonlinear dynamical systems by automatically calculating gradients in IDS. When integrated into an adaptive model-predictive control algorithm, our approach exhibits orders of magnitude improvements in sample efficiency over model-free reinforcement learning algorithms on challenging nonlinear control domains.