 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJVLDLoc: a Joint Optimization of Visual-LiDAR Constraints and Direction Priors for Localization in Driving Scenario
Aug 26, 2022
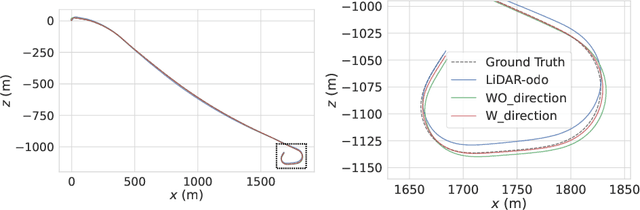
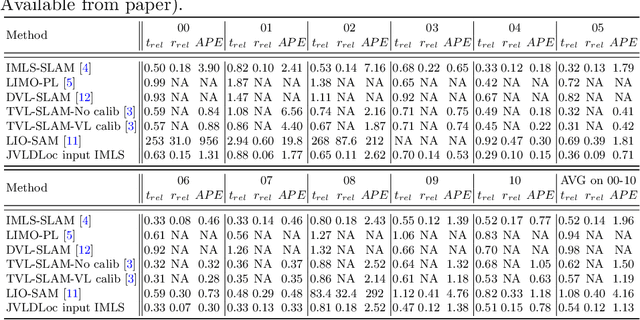
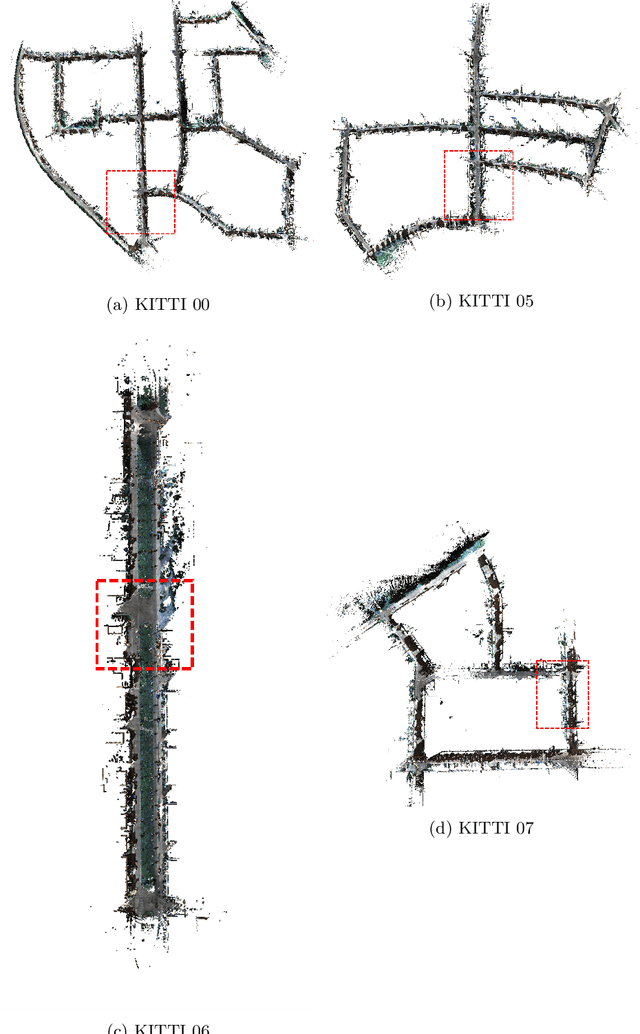
The ability for a moving agent to localize itself in environment is the basic demand for emerging applications, such as autonomous driving, etc. Many existing methods based on multiple sensors still suffer from drift. We propose a scheme that fuses map prior and vanishing points from images, which can establish an energy term that is only constrained on rotation, called the direction projection error. Then we embed these direction priors into a visual-LiDAR SLAM system that integrates camera and LiDAR measurements in a tightly-coupled way at backend. Specifically, our method generates visual reprojection error and point to Implicit Moving Least Square(IMLS) surface of scan constraints, and solves them jointly along with direction projection error at global optimization. Experiments on KITTI, KITTI-360 and Oxford Radar Robotcar show that we achieve lower localization error or Absolute Pose Error (APE) than prior map, which validates our method is effective.
Group DETR: Fast DETR Training with Group-Wise One-to-Many Assignment
Aug 02, 2022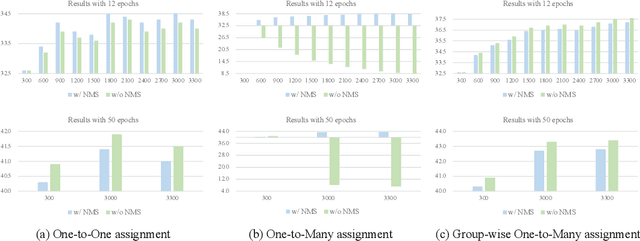
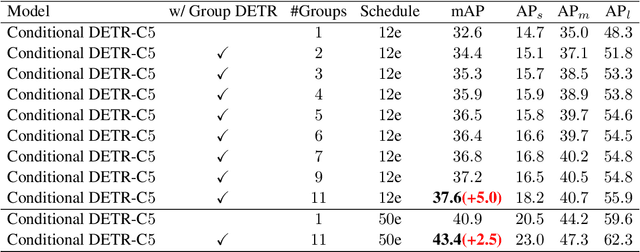
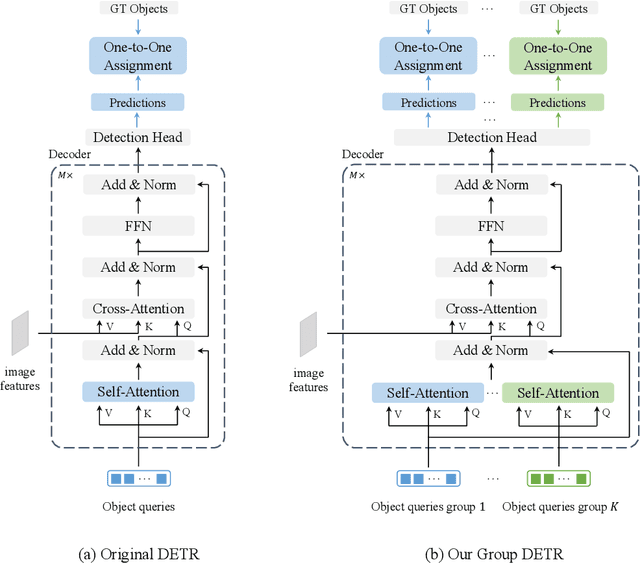
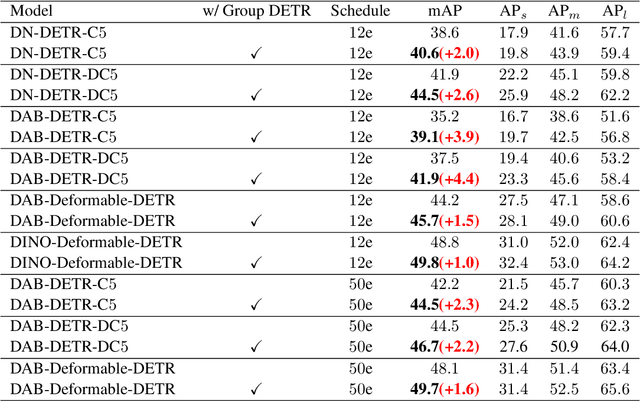
Detection Transformer (DETR) relies on One-to-One assignment, i.e., assigning one ground-truth object to only one positive object query, for end-to-end object detection and lacks the capability of exploiting multiple positive object queries. We present a novel DETR training approach, named {\em Group DETR}, to support Group-wise One-to-Many assignment. We make simple modifications during training: (i) adopt $K$ groups of object queries; (ii) conduct decoder self-attention on each group of object queries with the same parameters; (iii) perform One-to-One label assignment for each group, leading to $K$ positive object queries for each ground-truth object. In inference, we only use one group of object queries, making no modifications to DETR architecture and processes. We validate the effectiveness of the proposed approach on DETR variants, including Conditional DETR, DAB-DETR, DN-DETR, and DINO. Code will be available.
Conditional DETR V2: Efficient Detection Transformer with Box Queries
Jul 18, 2022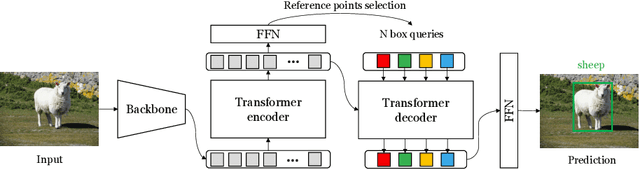
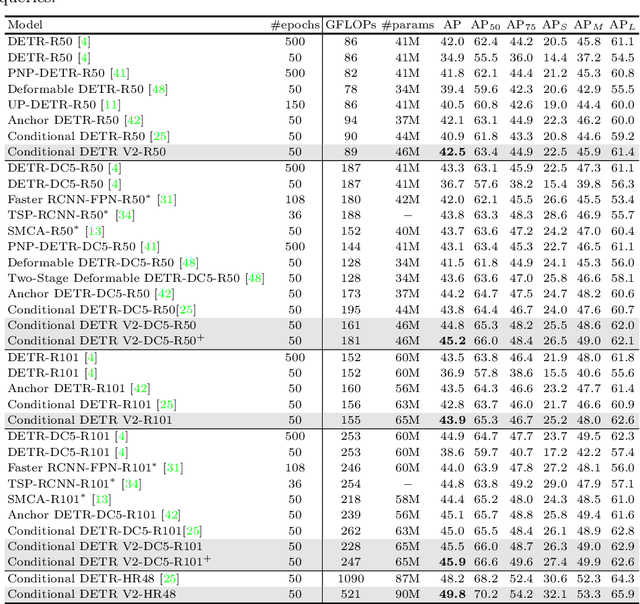
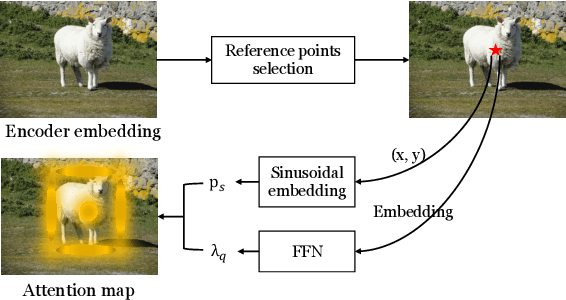
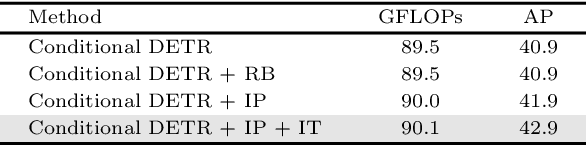
In this paper, we are interested in Detection Transformer (DETR), an end-to-end object detection approach based on a transformer encoder-decoder architecture without hand-crafted postprocessing, such as NMS. Inspired by Conditional DETR, an improved DETR with fast training convergence, that presented box queries (originally called spatial queries) for internal decoder layers, we reformulate the object query into the format of the box query that is a composition of the embeddings of the reference point and the transformation of the box with respect to the reference point. This reformulation indicates the connection between the object query in DETR and the anchor box that is widely studied in Faster R-CNN. Furthermore, we learn the box queries from the image content, further improving the detection quality of Conditional DETR still with fast training convergence. In addition, we adopt the idea of axial self-attention to save the memory cost and accelerate the encoder. The resulting detector, called Conditional DETR V2, achieves better results than Conditional DETR, saves the memory cost and runs more efficiently. For example, for the DC$5$-ResNet-$50$ backbone, our approach achieves $44.8$ AP with $16.4$ FPS on the COCO $val$ set and compared to Conditional DETR, it runs $1.6\times$ faster, saves $74$\% of the overall memory cost, and improves $1.0$ AP score.
Compressible-composable NeRF via Rank-residual Decomposition
May 30, 2022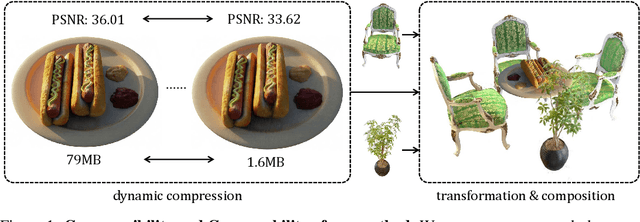
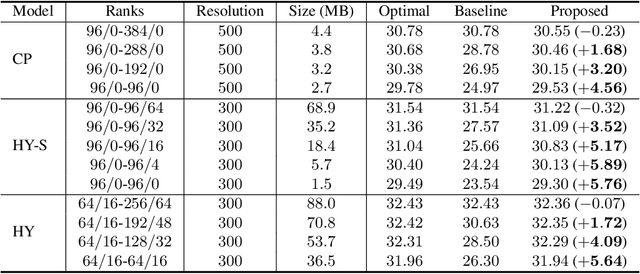
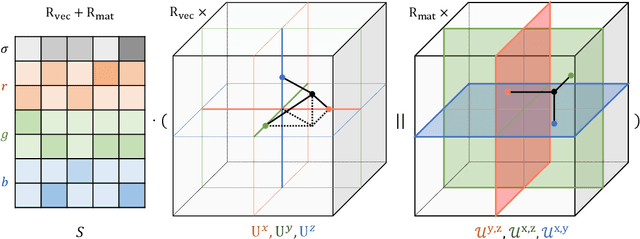
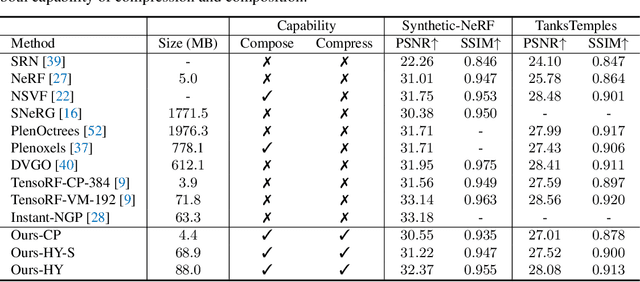
Neural Radiance Field (NeRF) has emerged as a compelling method to represent 3D objects and scenes for photo-realistic rendering. However, its implicit representation causes difficulty in manipulating the models like the explicit mesh representation. Several recent advances in NeRF manipulation are usually restricted by a shared renderer network, or suffer from large model size. To circumvent the hurdle, in this paper, we present an explicit neural field representation that enables efficient and convenient manipulation of models. To achieve this goal, we learn a hybrid tensor rank decomposition of the scene without neural networks. Motivated by the low-rank approximation property of the SVD algorithm, we propose a rank-residual learning strategy to encourage the preservation of primary information in lower ranks. The model size can then be dynamically adjusted by rank truncation to control the levels of detail, achieving near-optimal compression without extra optimization. Furthermore, different models can be arbitrarily transformed and composed into one scene by concatenating along the rank dimension. The growth of storage cost can also be mitigated by compressing the unimportant objects in the composed scene. We demonstrate that our method is able to achieve comparable rendering quality to state-of-the-art methods, while enabling extra capability of compression and composition. Code will be made available at \url{https://github.com/ashawkey/CCNeRF}.
Point Scene Understanding via Disentangled Instance Mesh Reconstruction
Mar 31, 2022

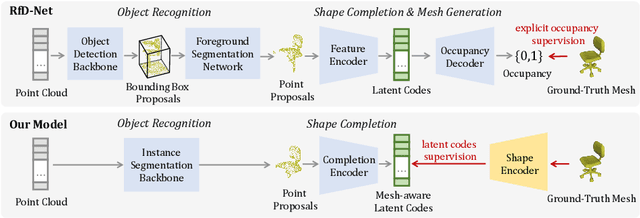
Semantic scene reconstruction from point cloud is an essential and challenging task for 3D scene understanding. This task requires not only to recognize each instance in the scene, but also to recover their geometries based on the partial observed point cloud. Existing methods usually attempt to directly predict occupancy values of the complete object based on incomplete point cloud proposals from a detection-based backbone. However, this framework always fails to reconstruct high fidelity mesh due to the obstruction of various detected false positive object proposals and the ambiguity of incomplete point observations for learning occupancy values of complete objects. To circumvent the hurdle, we propose a Disentangled Instance Mesh Reconstruction (DIMR) framework for effective point scene understanding. A segmentation-based backbone is applied to reduce false positive object proposals, which further benefits our exploration on the relationship between recognition and reconstruction. Based on the accurate proposals, we leverage a mesh-aware latent code space to disentangle the processes of shape completion and mesh generation, relieving the ambiguity caused by the incomplete point observations. Furthermore, with access to the CAD model pool at test time, our model can also be used to improve the reconstruction quality by performing mesh retrieval without extra training. We thoroughly evaluate the reconstructed mesh quality with multiple metrics, and demonstrate the superiority of our method on the challenging ScanNet dataset.
MaskGroup: Hierarchical Point Grouping and Masking for 3D Instance Segmentation
Mar 28, 2022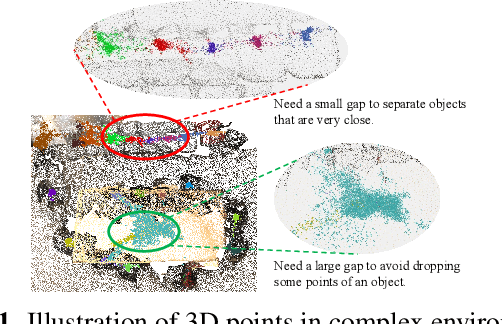
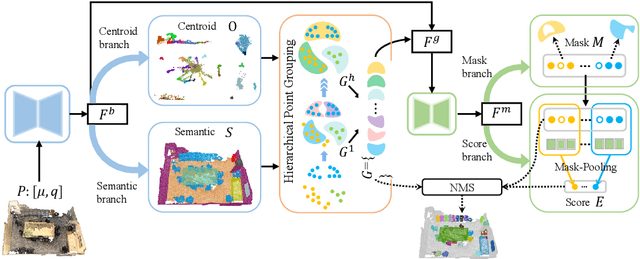
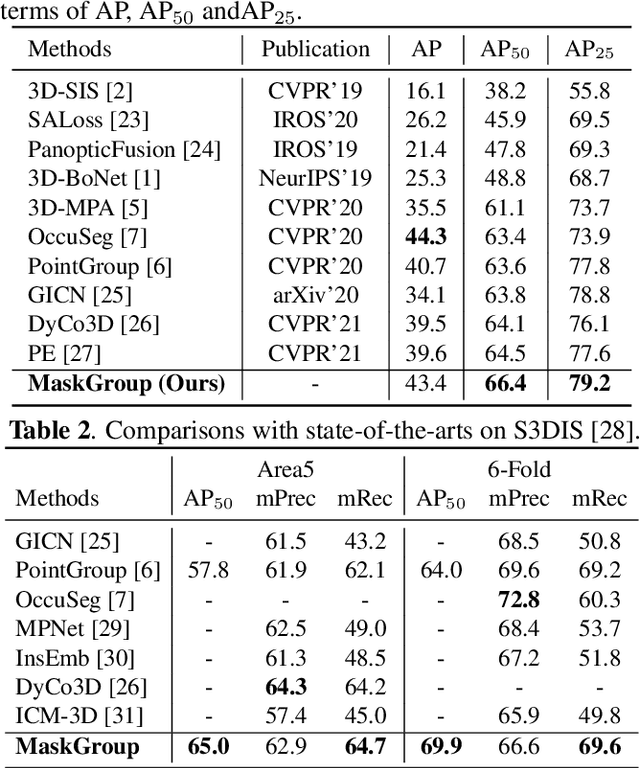
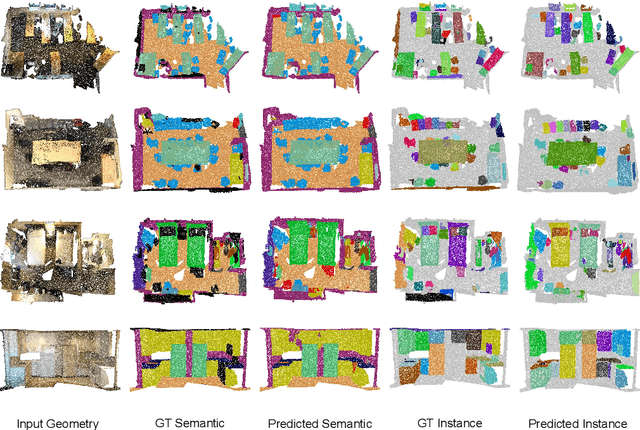
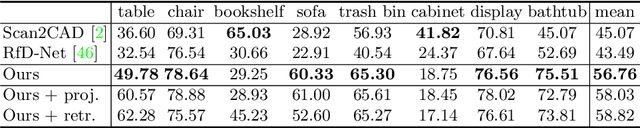
This paper studies the 3D instance segmentation problem, which has a variety of real-world applications such as robotics and augmented reality. Since the surroundings of 3D objects are of high complexity, the separating of different objects is very difficult. To address this challenging problem, we propose a novel framework to group and refine the 3D instances. In practice, we first learn an offset vector for each point and shift it to its predicted instance center. To better group these points, we propose a Hierarchical Point Grouping algorithm to merge the centrally aggregated points progressively. All points are grouped into small clusters, which further gradually undergo another clustering procedure to merge into larger groups. These multi-scale groups are exploited for instance prediction, which is beneficial for predicting instances with different scales. In addition, a novel MaskScoreNet is developed to produce binary point masks of these groups for further refining the segmentation results. Extensive experiments conducted on the ScanNetV2 and S3DIS benchmarks demonstrate the effectiveness of the proposed method. For instance, our approach achieves a 66.4\% mAP with the 0.5 IoU threshold on the ScanNetV2 test set, which is 1.9\% higher than the state-of-the-art method.
Context Autoencoder for Self-Supervised Representation Learning
Feb 07, 2022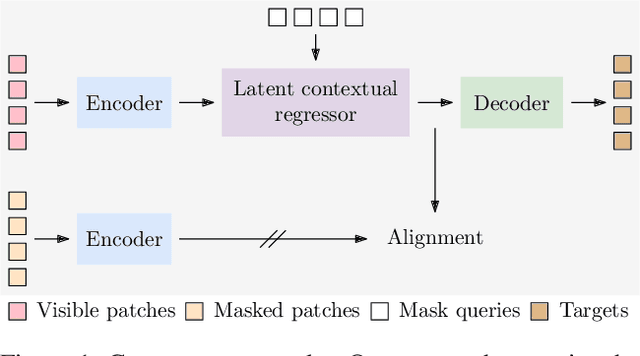
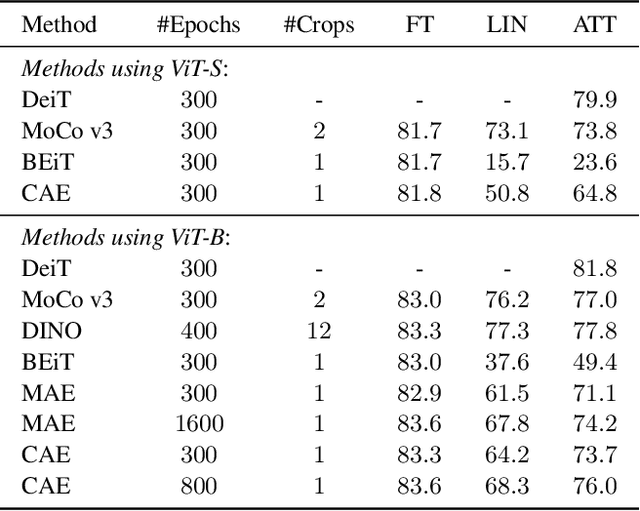


We present a novel masked image modeling (MIM) approach, context autoencoder (CAE), for self-supervised learning. We randomly partition the image into two sets: visible patches and masked patches. The CAE architecture consists of: (i) an encoder that takes visible patches as input and outputs their latent representations, (ii) a latent context regressor that predicts the masked patch representations from the visible patch representations that are not updated in this regressor, (iii) a decoder that takes the estimated masked patch representations as input and makes predictions for the masked patches, and (iv) an alignment module that aligns the masked patch representation estimation with the masked patch representations computed from the encoder. In comparison to previous MIM methods that couple the encoding and decoding roles, e.g., using a single module in BEiT, our approach attempts to~\emph{separate the encoding role (content understanding) from the decoding role (making predictions for masked patches)} using different modules, improving the content understanding capability. In addition, our approach makes predictions from the visible patches to the masked patches in \emph{the latent representation space} that is expected to take on semantics. In addition, we present the explanations about why contrastive pretraining and supervised pretraining perform similarly and why MIM potentially performs better. We demonstrate the effectiveness of our CAE through superior transfer performance in downstream tasks: semantic segmentation, and object detection and instance segmentation.
Not All Voxels Are Equal: Semantic Scene Completion from the Point-Voxel Perspective
Dec 24, 2021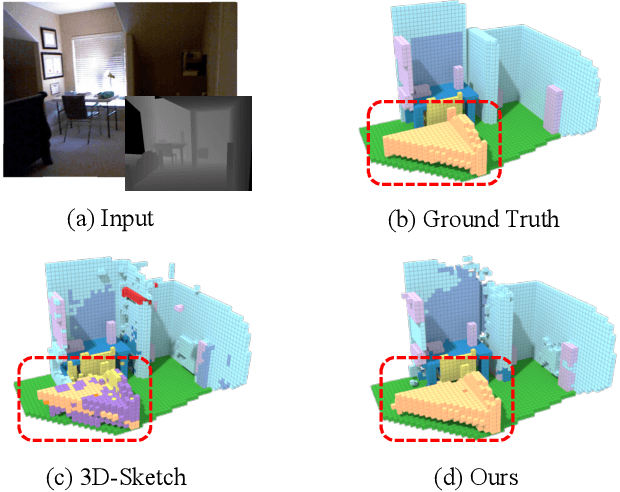
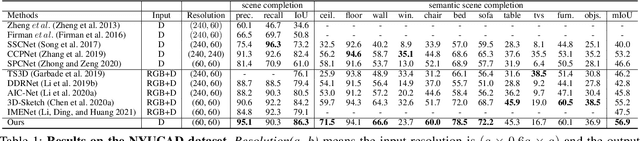
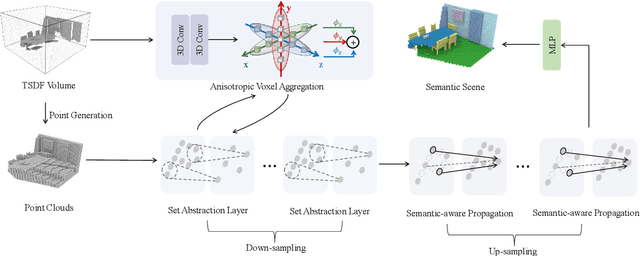
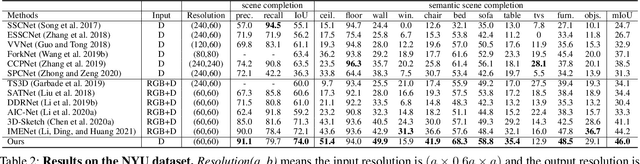
We revisit Semantic Scene Completion (SSC), a useful task to predict the semantic and occupancy representation of 3D scenes, in this paper. A number of methods for this task are always based on voxelized scene representations for keeping local scene structure. However, due to the existence of visible empty voxels, these methods always suffer from heavy computation redundancy when the network goes deeper, and thus limit the completion quality. To address this dilemma, we propose our novel point-voxel aggregation network for this task. Firstly, we transfer the voxelized scenes to point clouds by removing these visible empty voxels and adopt a deep point stream to capture semantic information from the scene efficiently. Meanwhile, a light-weight voxel stream containing only two 3D convolution layers preserves local structures of the voxelized scenes. Furthermore, we design an anisotropic voxel aggregation operator to fuse the structure details from the voxel stream into the point stream, and a semantic-aware propagation module to enhance the up-sampling process in the point stream by semantic labels. We demonstrate that our model surpasses state-of-the-arts on two benchmarks by a large margin, with only depth images as the input.
Conditional DETR for Fast Training Convergence
Aug 19, 2021
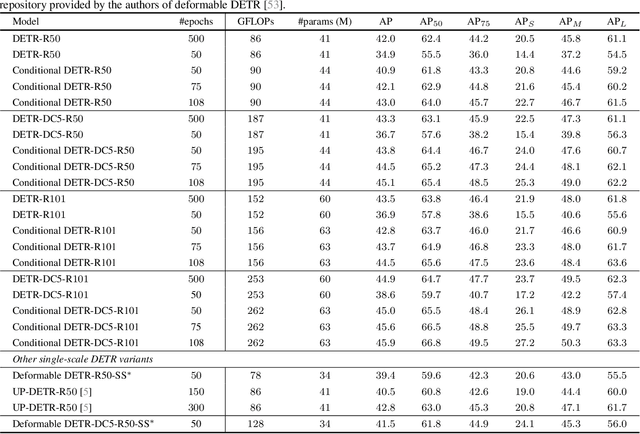
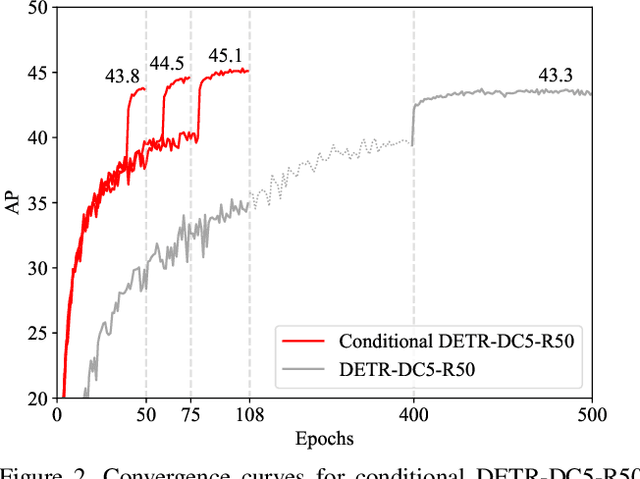
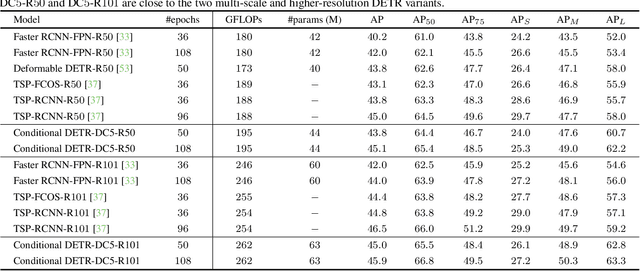
The recently-developed DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings for localizing the four extremities and predicting the box, which increases the need for high-quality content embeddings and thus the training difficulty. Our approach, named conditional DETR, learns a conditional spatial query from the decoder embedding for decoder multi-head cross-attention. The benefit is that through the conditional spatial query, each cross-attention head is able to attend to a band containing a distinct region, e.g., one object extremity or a region inside the object box. This narrows down the spatial range for localizing the distinct regions for object classification and box regression, thus relaxing the dependence on the content embeddings and easing the training. Empirical results show that conditional DETR converges 6.7x faster for the backbones R50 and R101 and 10x faster for stronger backbones DC5-R50 and DC5-R101. Code is available at https://github.com/Atten4Vis/ConditionalDETR.
Joint Implicit Image Function for Guided Depth Super-Resolution
Jul 23, 2021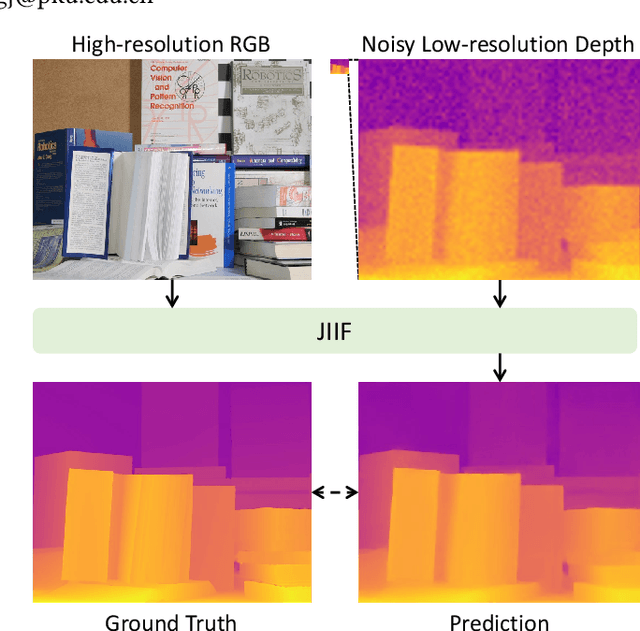
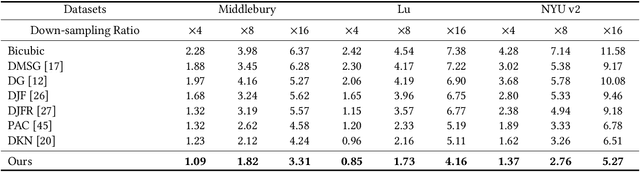
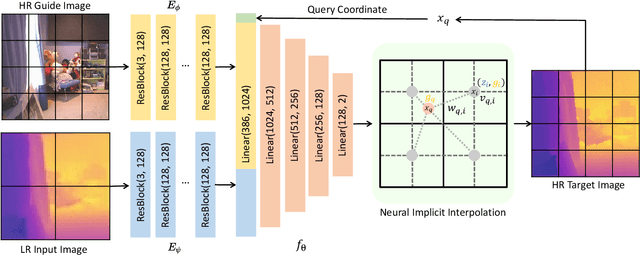
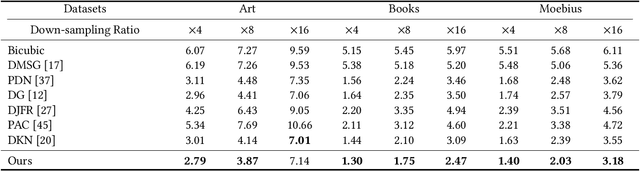
Guided depth super-resolution is a practical task where a low-resolution and noisy input depth map is restored to a high-resolution version, with the help of a high-resolution RGB guide image. Existing methods usually view this task as a generalized guided filtering problem that relies on designing explicit filters and objective functions, or a dense regression problem that directly predicts the target image via deep neural networks. These methods suffer from either model capability or interpretability. Inspired by the recent progress in implicit neural representation, we propose to formulate the guided super-resolution as a neural implicit image interpolation problem, where we take the form of a general image interpolation but use a novel Joint Implicit Image Function (JIIF) representation to learn both the interpolation weights and values. JIIF represents the target image domain with spatially distributed local latent codes extracted from the input image and the guide image, and uses a graph attention mechanism to learn the interpolation weights at the same time in one unified deep implicit function. We demonstrate the effectiveness of our JIIF representation on guided depth super-resolution task, significantly outperforming state-of-the-art methods on three public benchmarks. Code can be found at \url{https://git.io/JC2sU}.