 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Risk Estimators Can Mislead: A Case Study of Learning with Complementary Labels
Jul 07, 2020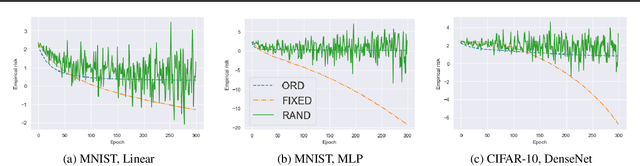
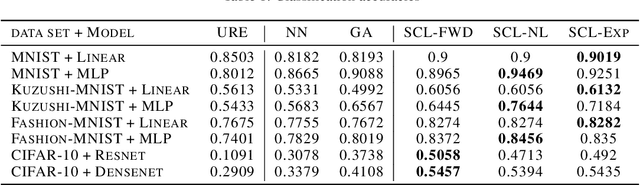
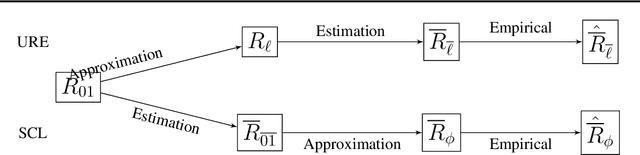
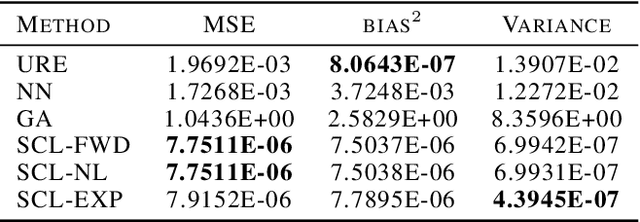
In weakly supervised learning, unbiased risk estimator(URE) is a powerful tool for training classifiers when training and test data are drawn from different distributions. Nevertheless, UREs lead to overfitting in many problem settings when the models are complex like deep networks. In this paper, we investigate reasons for such overfitting by studying a weakly supervised problem called learning with complementary labels. We argue the quality of gradient estimation matters more in risk minimization. Theoretically, we show that a URE gives an unbiased gradient estimator(UGE). Practically, however, UGEs may suffer from huge variance, which causes empirical gradients to be usually far away from true gradients during minimization. To this end, we propose a novel surrogate complementary loss(SCL) framework that trades zero bias with reduced variance and makes empirical gradients more aligned with true gradients in the direction. Thanks to this characteristic, SCL successfully mitigates the overfitting issue and improves URE-based methods.
Parts-dependent Label Noise: Towards Instance-dependent Label Noise
Jun 14, 2020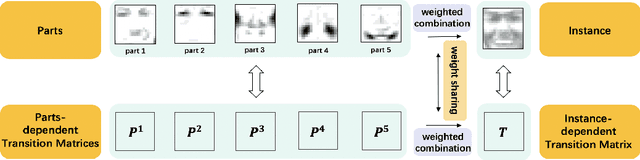
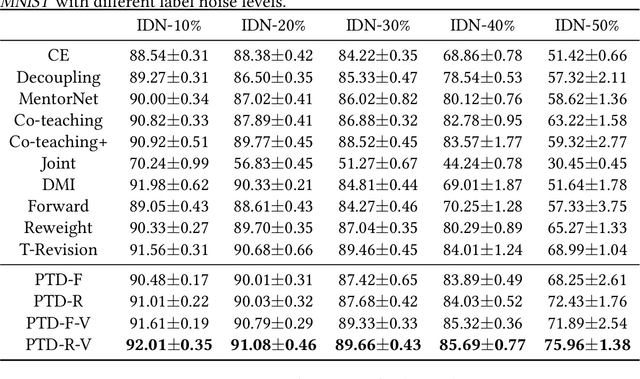
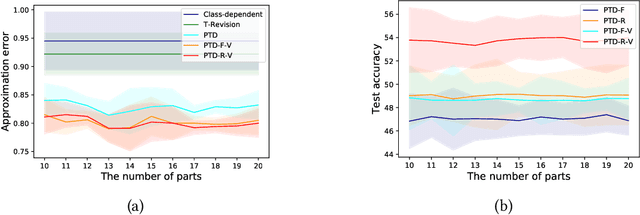
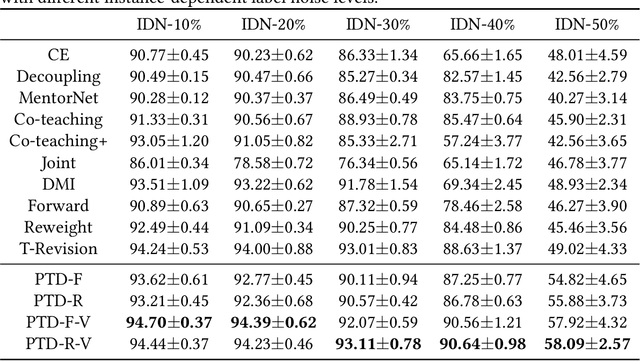
Learning with the \textit{instance-dependent} label noise is challenging, because it is hard to model such real-world noise. Note that there are psychological and physiological evidences showing that we humans perceive instances by decomposing them into parts. Annotators are therefore more likely to annotate instances based on the parts rather than the whole instances. Motivated by this human cognition, in this paper, we approximate the instance-dependent label noise by exploiting \textit{parts-dependent} label noise. Specifically, since instances can be approximately reconstructed by a combination of parts, we approximate the instance-dependent \textit{transition matrix} for an instance by a combination of the transition matrices for the parts of the instance. The transition matrices for parts can be learned by exploiting anchor points (i.e., data points that belong to a specific class almost surely). Empirical evaluations on synthetic and real-world datasets demonstrate our method is superior to the state-of-the-art approaches for learning from the instance-dependent label noise.
Class2Simi: A New Perspective on Learning with Label Noise
Jun 14, 2020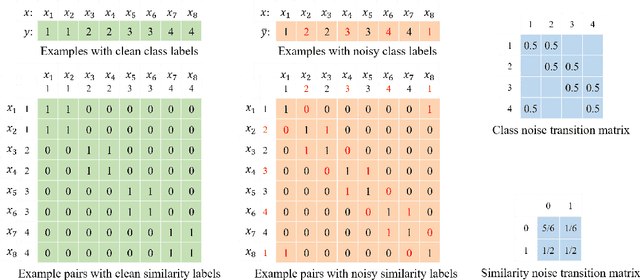


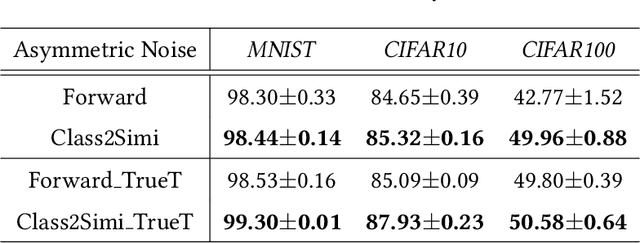
Label noise is ubiquitous in the era of big data. Deep learning algorithms can easily fit the noise and thus cannot generalize well without properly modeling the noise. In this paper, we propose a new perspective on dealing with label noise called Class2Simi. Specifically, we transform the training examples with noisy class labels into pairs of examples with noisy similarity labels and propose a deep learning framework to learn robust classifiers directly with the noisy similarity labels. Note that a class label shows the class that an instance belongs to; while a similarity label indicates whether or not two instances belong to the same class. It is worthwhile to perform the transformation: We prove that the noise rate for the noisy similarity labels is lower than that of the noisy class labels, because similarity labels themselves are robust to noise. For example, given two instances, even if both of their class labels are incorrect, their similarity label could be correct. Due to the lower noise rate, Class2Simi achieves remarkably better classification accuracy than its baselines that directly deals with the noisy class labels.
Dual T: Reducing Estimation Error for Transition Matrix in Label-noise Learning
Jun 14, 2020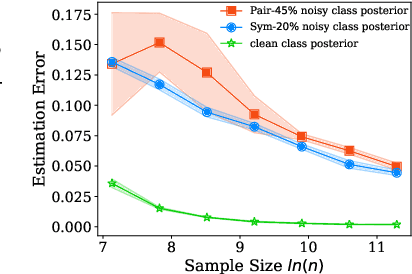
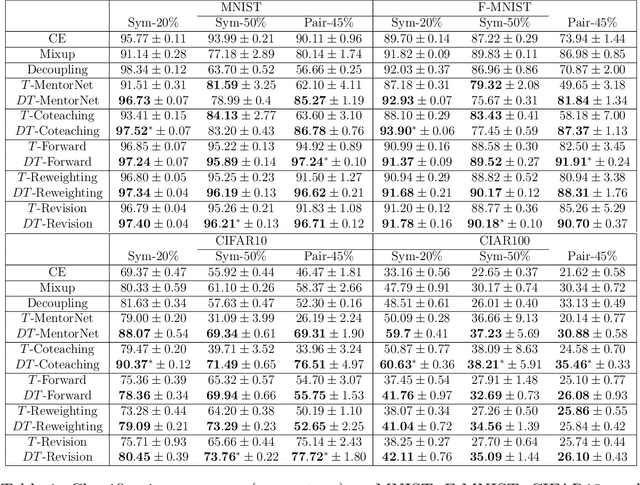
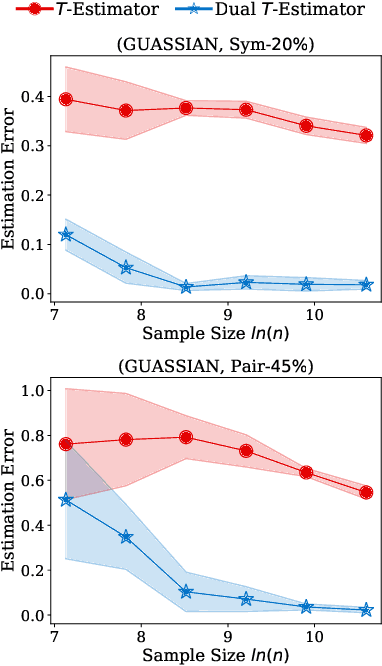

The \textit{transition matrix}, denoting the transition relationship from clean labels to noisy labels, is essential to build \textit{statistically consistent} classifiers in label-noise learning. Existing methods for estimating the transition matrix rely heavily on estimating the noisy class posterior. However, the estimation error for \textit{noisy class posterior} could be large due to the randomness of label noise. The estimation error would lead the transition matrix to be poorly estimated. Therefore, in this paper, we aim to solve this problem by exploiting the divide-and-conquer paradigm. Specifically, we introduce an \textit{intermediate class} to avoid directly estimating the noisy class posterior. By this intermediate class, the original transition matrix can then be factorized into the product of two easy-to-estimate transition matrices. We term the proposed method the \textit{dual $T$-estimator}. Both theoretical analyses and empirical results illustrate the effectiveness of the dual $T$-estimator for estimating transition matrices, leading to better classification performances.
Rethinking Importance Weighting for Deep Learning under Distribution Shift
Jun 08, 2020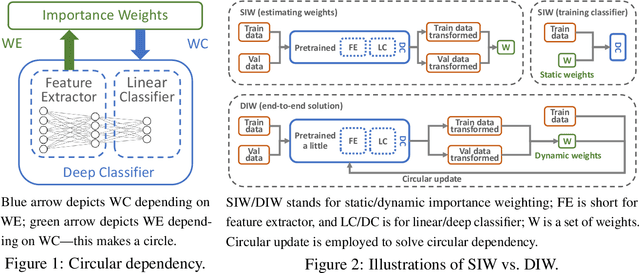
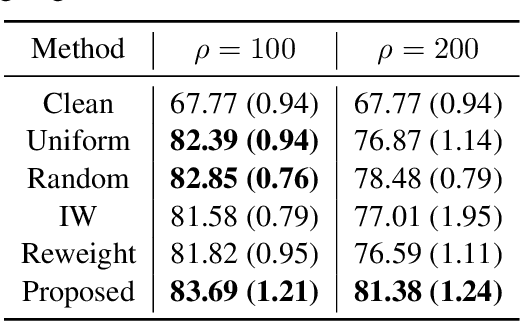
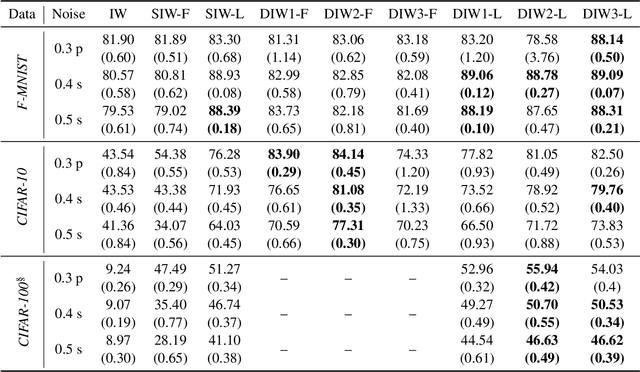
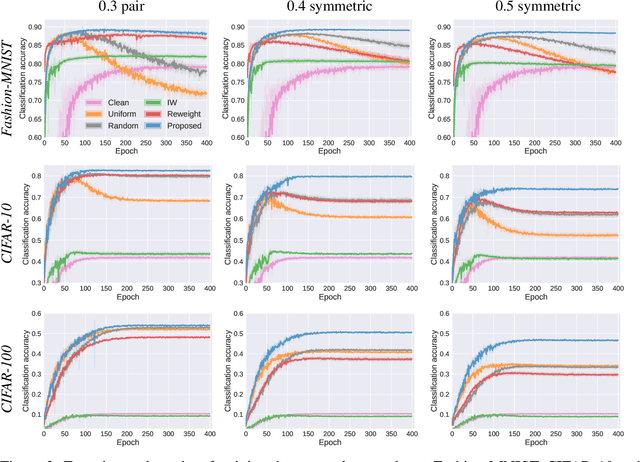
Under distribution shift (DS) where the training data distribution differs from the test one, a powerful technique is importance weighting (IW) which handles DS in two separate steps: weight estimation (WE) estimates the test-over-training density ratio and weighted classification (WC) trains the classifier from weighted training data. However, IW cannot work well on complex data, since WE is incompatible with deep learning. In this paper, we rethink IW and theoretically show it suffers from a circular dependency: we need not only WE for WC, but also WC for WE where a trained deep classifier is used as the feature extractor (FE). To cut off the dependency, we try to pretrain FE from unweighted training data, which leads to biased FE. To overcome the bias, we propose an end-to-end solution dynamic IW that iterates between WE and WC and combines them in a seamless manner, and hence our WE can also enjoy deep networks and stochastic optimizers indirectly. Experiments with two representative DSs on Fashion-MNIST and CIFAR-10/100 demonstrate that dynamic IW compares favorably with state-of-the-art methods.
Attacks Which Do Not Kill Training Make Adversarial Learning Stronger
Feb 26, 2020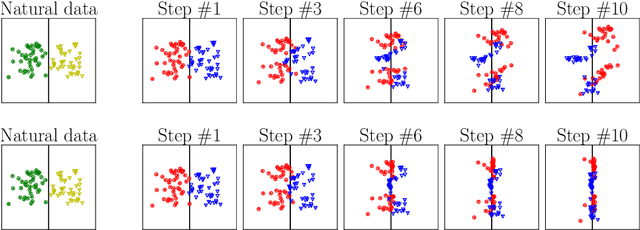
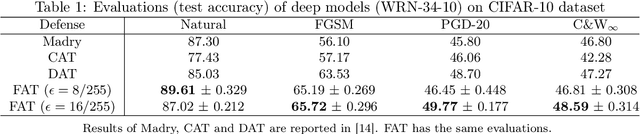
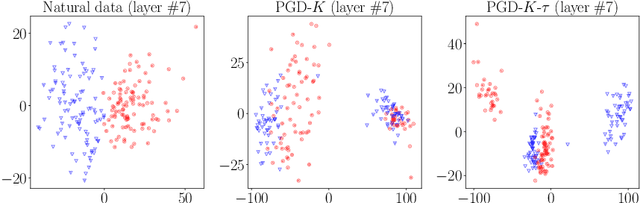
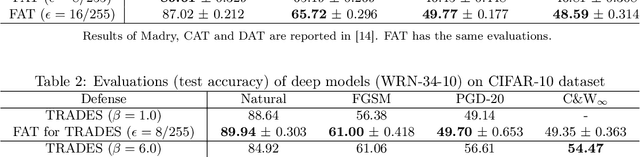
Adversarial training based on the minimax formulation is necessary for obtaining adversarial robustness of trained models. However, it is conservative or even pessimistic so that it sometimes hurts the natural generalization. In this paper, we raise a fundamental question---do we have to trade off natural generalization for adversarial robustness? We argue that adversarial training is to employ confident adversarial data for updating the current model. We propose a novel approach of friendly adversarial training (FAT): rather than employing most adversarial data maximizing the loss, we search for least adversarial (i.e., friendly adversarial) data minimizing the loss, among the adversarial data that are confidently misclassified. Our novel formulation is easy to implement by just stopping the most adversarial data searching algorithms such as PGD (projected gradient descent) early, which we call early-stopped PGD. Theoretically, FAT is justified by an upper bound of the adversarial risk. Empirically, early-stopped PGD allows us to answer the earlier question negatively---adversarial robustness can indeed be achieved without compromising the natural generalization.
Do We Need Zero Training Loss After Achieving Zero Training Error?
Feb 20, 2020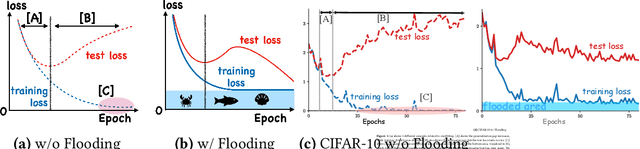
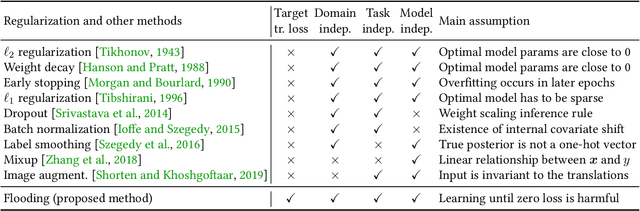
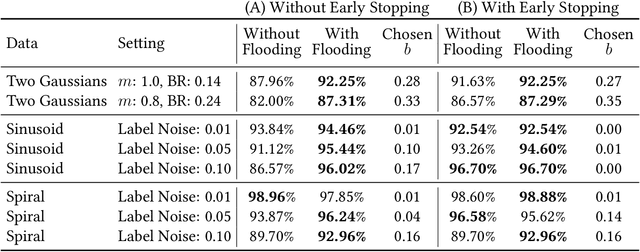
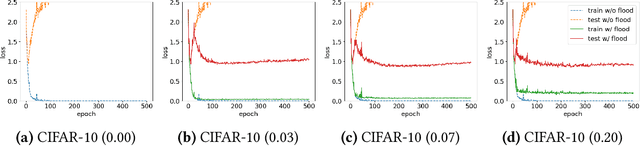
Overparameterized deep networks have the capacity to memorize training data with zero training error. Even after memorization, the training loss continues to approach zero, making the model overconfident and the test performance degraded. Since existing regularizers do not directly aim to avoid zero training loss, they often fail to maintain a moderate level of training loss, ending up with a too small or too large loss. We propose a direct solution called flooding that intentionally prevents further reduction of the training loss when it reaches a reasonably small value, which we call the flooding level. Our approach makes the loss float around the flooding level by doing mini-batched gradient descent as usual but gradient ascent if the training loss is below the flooding level. This can be implemented with one line of code, and is compatible with any stochastic optimizer and other regularizers. With flooding, the model will continue to "random walk" with the same non-zero training loss, and we expect it to drift into an area with a flat loss landscape that leads to better generalization. We experimentally show that flooding improves performance and as a byproduct, induces a double descent curve of the test loss.
Progressive Identification of True Labels for Partial-Label Learning
Feb 19, 2020
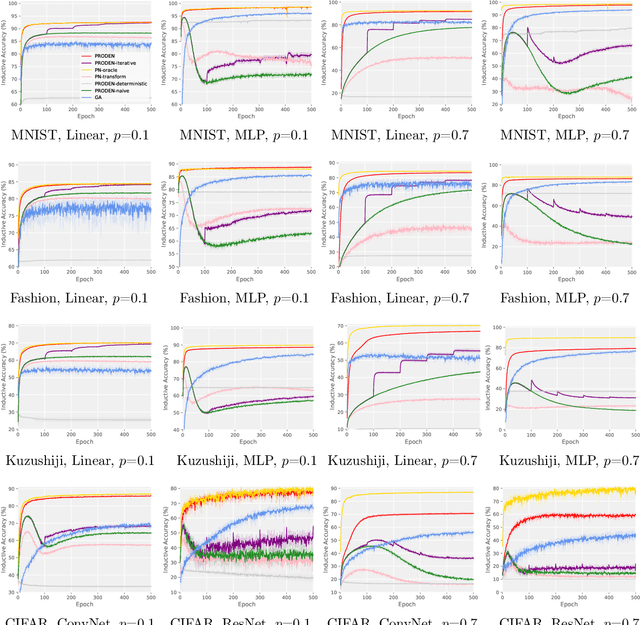
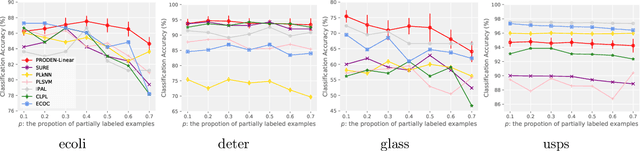
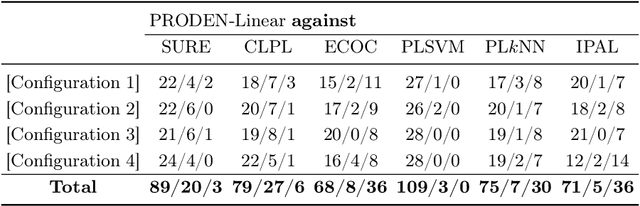
Partial-label learning is one of the important weakly supervised learning problems, where each training example is equipped with a set of candidate labels that contains the true label. Most existing methods elaborately designed learning objectives as constrained optimizations that must be solved in specific manners, making their computational complexity a bottleneck for scaling up to big data. The goal of this paper is to propose a novel framework of partial-label learning without implicit assumptions on the model or optimization algorithm. More specifically, we propose a general estimator of the classification risk, theoretically analyze the classifier-consistency, and establish an estimation error bound. We then explore a progressive identification method for approximately minimizing the proposed risk estimator, where the update of the model and identification of true labels are conducted in a seamless manner. The resulting algorithm is model-independent and loss-independent, and compatible with stochastic optimization. Thorough experiments demonstrate it sets the new state of the art.
Multi-Class Classification from Noisy-Similarity-Labeled Data
Feb 16, 2020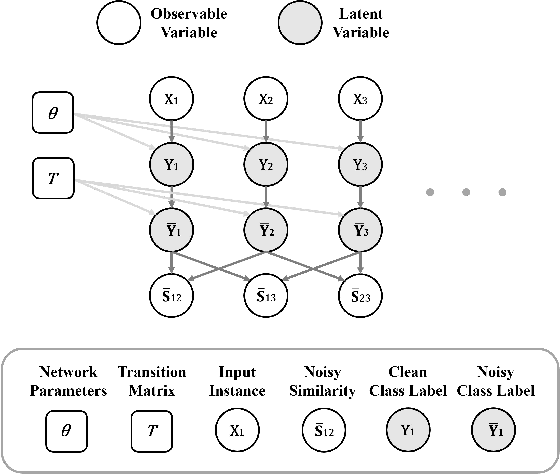
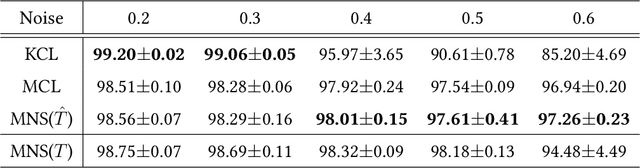

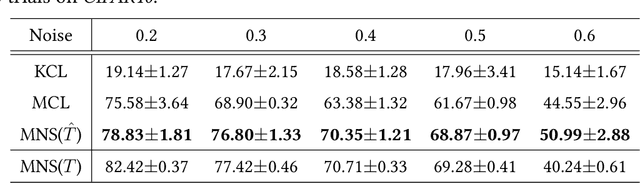
A similarity label indicates whether two instances belong to the same class while a class label shows the class of the instance. Without class labels, a multi-class classifier could be learned from similarity-labeled pairwise data by meta classification learning. However, since the similarity label is less informative than the class label, it is more likely to be noisy. Deep neural networks can easily remember noisy data, leading to overfitting in classification. In this paper, we propose a method for learning from only noisy-similarity-labeled data. Specifically, to model the noise, we employ a noise transition matrix to bridge the class-posterior probability between clean and noisy data. We further estimate the transition matrix from only noisy data and build a novel learning system to learn a classifier which can assign noise-free class labels for instances. Moreover, we theoretically justify how our proposed method generalizes for learning classifiers. Experimental results demonstrate the superiority of the proposed method over the state-of-the-art method on benchmark-simulated and real-world noisy-label datasets.
Towards Mixture Proportion Estimation without Irreducibility
Feb 10, 2020
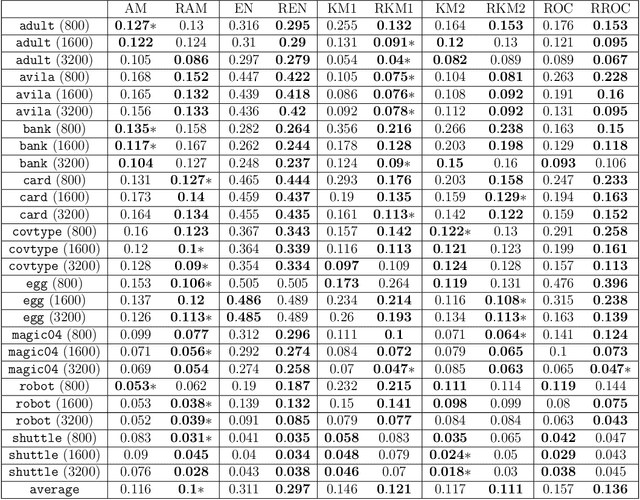
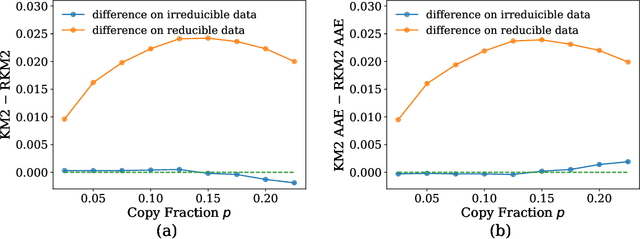
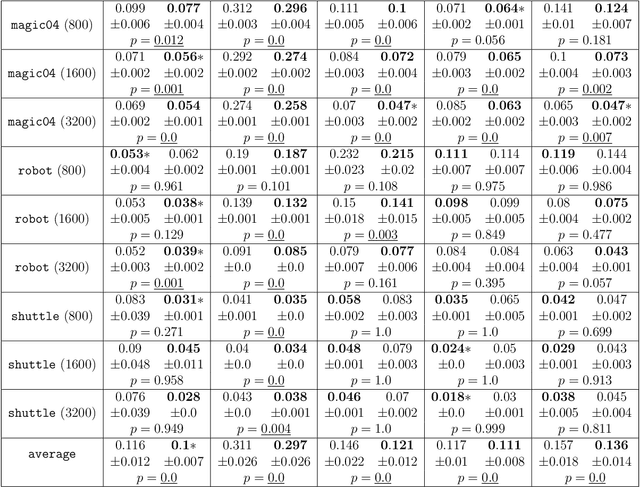
\textit{Mixture proportion estimation} (MPE) is a fundamental problem of practical significance, where we are given data from only a \textit{mixture} and one of its two \textit{components} to identify the proportion of each component. All existing MPE methods that are distribution-independent explicitly or implicitly rely on the \textit{irreducible} assumption---the unobserved component is not a mixture containing the observable component. If this is not satisfied, those methods will lead to a critical estimation bias. In this paper, we propose \textit{Regrouping-MPE} that works without irreducible assumption: it builds a new irreducible MPE problem and solves the new problem. It is worthwhile to change the problem: we prove that if the assumption holds, our method will not affect anything; if the assumption does not hold, the bias from problem changing is less than the bias from violation of the irreducible assumption in the original problem. Experiments show that our method outperforms all state-of-the-art MPE methods on various real-world datasets.