 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Sample Selection Approach to Positive-Unlabeled Learning: Turning Unlabeled Data into Positive rather than Negative
Paper and Code
Jan 29, 2019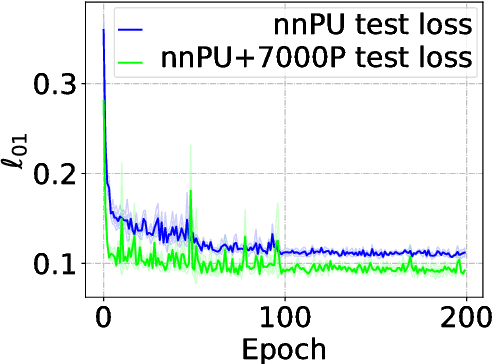

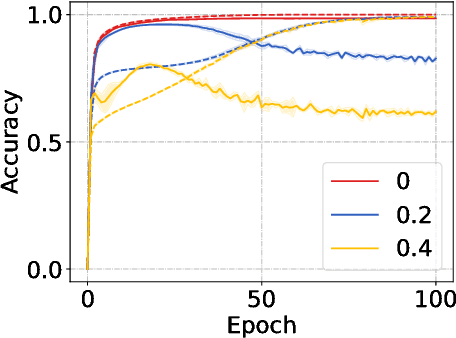
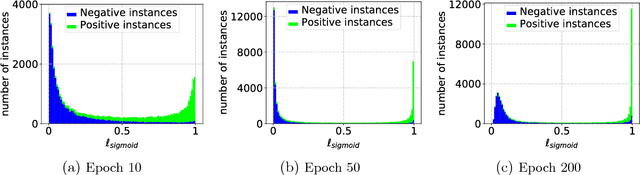
In the early history of positive-unlabeled (PU) learning, the sample selection approach, which heuristically selects negative (N) data from U data, was explored extensively. However, this approach was later dominated by the importance reweighting approach, which carefully treats all U data as N data. May there be a new sample selection method that can outperform the latest importance reweighting method in the deep learning age? This paper is devoted to answering this question affirmatively---we propose to label large-loss U data as P, based on the memorization properties of deep networks. Since P data selected in such a way are biased, we develop a novel learning objective that can handle such biased P data properly. Experiments confirm the superiority of the proposed method.