 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Local and Global Contexts for Temporal Action Localization
Aug 07, 2021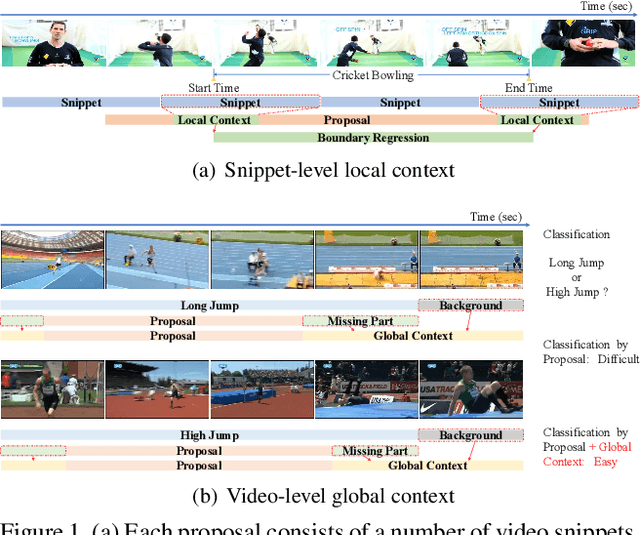
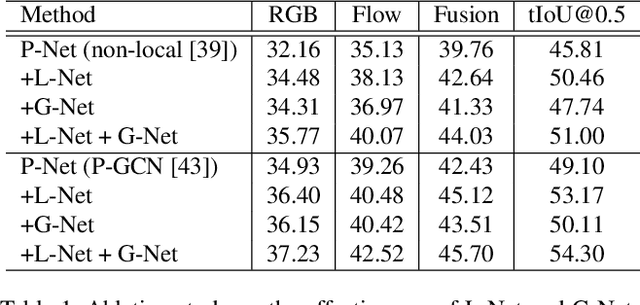
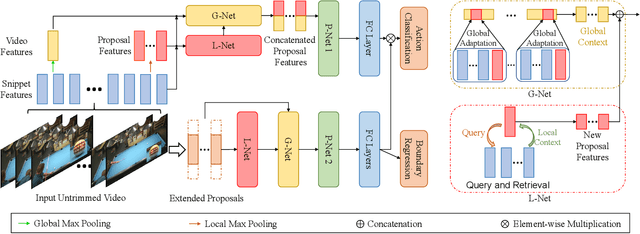
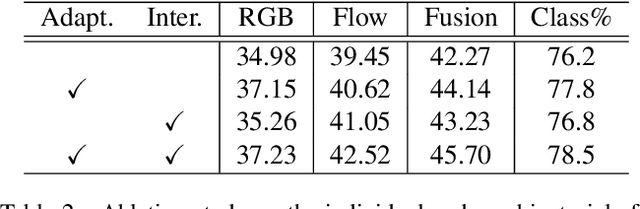
Effectively tackling the problem of temporal action localization (TAL) necessitates a visual representation that jointly pursues two confounding goals, i.e., fine-grained discrimination for temporal localization and sufficient visual invariance for action classification. We address this challenge by enriching both the local and global contexts in the popular two-stage temporal localization framework, where action proposals are first generated followed by action classification and temporal boundary regression. Our proposed model, dubbed ContextLoc, can be divided into three sub-networks: L-Net, G-Net and P-Net. L-Net enriches the local context via fine-grained modeling of snippet-level features, which is formulated as a query-and-retrieval process. G-Net enriches the global context via higher-level modeling of the video-level representation. In addition, we introduce a novel context adaptation module to adapt the global context to different proposals. P-Net further models the context-aware inter-proposal relations. We explore two existing models to be the P-Net in our experiments. The efficacy of our proposed method is validated by experimental results on the THUMOS14 (54.3\% at tIoU@0.5) and ActivityNet v1.3 (56.01\% at tIoU@0.5) datasets, which outperforms recent states of the art. Code is available at https://github.com/buxiangzhiren/ContextLoc.
Exploring Structure Consistency for Deep Model Watermarking
Aug 05, 2021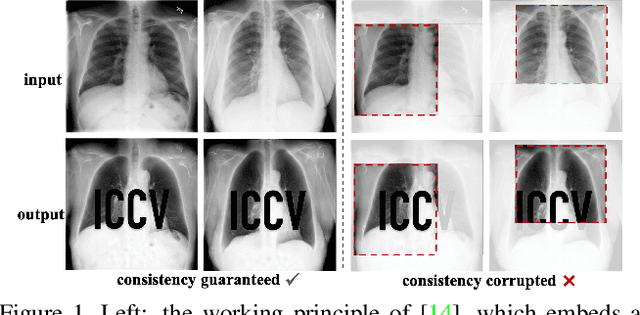
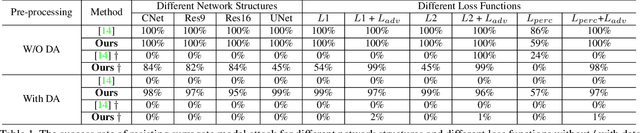

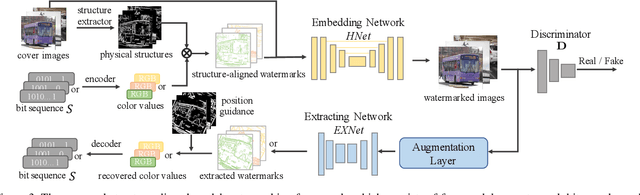
The intellectual property (IP) of Deep neural networks (DNNs) can be easily ``stolen'' by surrogate model attack. There has been significant progress in solutions to protect the IP of DNN models in classification tasks. However, little attention has been devoted to the protection of DNNs in image processing tasks. By utilizing consistent invisible spatial watermarks, one recent work first considered model watermarking for deep image processing networks and demonstrated its efficacy in many downstream tasks. Nevertheless, it highly depends on the hypothesis that the embedded watermarks in the network outputs are consistent. When the attacker uses some common data augmentation attacks (e.g., rotate, crop, and resize) during surrogate model training, it will totally fail because the underlying watermark consistency is destroyed. To mitigate this issue, we propose a new watermarking methodology, namely ``structure consistency'', based on which a new deep structure-aligned model watermarking algorithm is designed. Specifically, the embedded watermarks are designed to be aligned with physically consistent image structures, such as edges or semantic regions. Experiments demonstrate that our method is much more robust than the baseline method in resisting data augmentation attacks for model IP protection. Besides that, we further test the generalization ability and robustness of our method to a broader range of circumvention attacks.
Learning Dynamics via Graph Neural Networks for Human Pose Estimation and Tracking
Jun 07, 2021
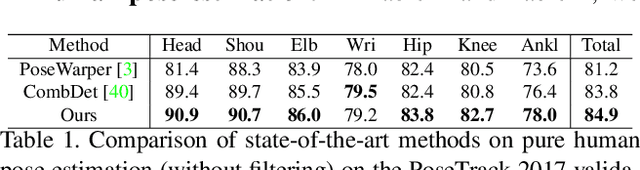
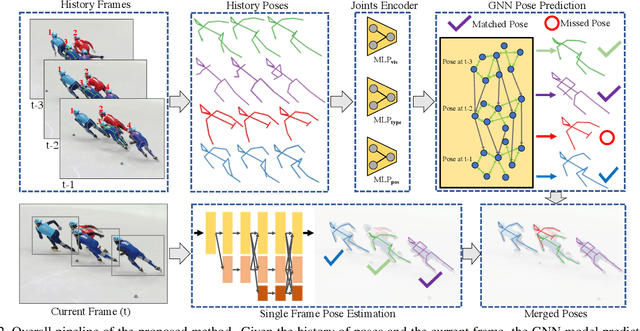
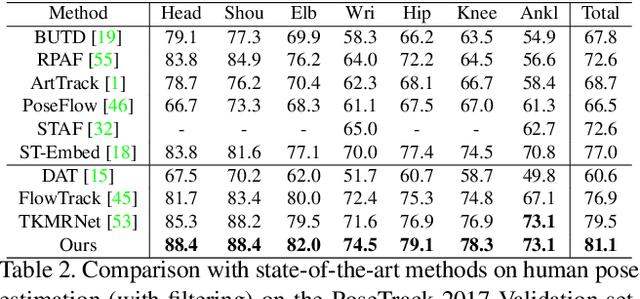
Multi-person pose estimation and tracking serve as crucial steps for video understanding. Most state-of-the-art approaches rely on first estimating poses in each frame and only then implementing data association and refinement. Despite the promising results achieved, such a strategy is inevitably prone to missed detections especially in heavily-cluttered scenes, since this tracking-by-detection paradigm is, by nature, largely dependent on visual evidences that are absent in the case of occlusion. In this paper, we propose a novel online approach to learning the pose dynamics, which are independent of pose detections in current fame, and hence may serve as a robust estimation even in challenging scenarios including occlusion. Specifically, we derive this prediction of dynamics through a graph neural network~(GNN) that explicitly accounts for both spatial-temporal and visual information. It takes as input the historical pose tracklets and directly predicts the corresponding poses in the following frame for each tracklet. The predicted poses will then be aggregated with the detected poses, if any, at the same frame so as to produce the final pose, potentially recovering the occluded joints missed by the estimator. Experiments on PoseTrack 2017 and PoseTrack 2018 datasets demonstrate that the proposed method achieves results superior to the state of the art on both human pose estimation and tracking tasks.
Adversarial Attack and Defense in Deep Ranking
Jun 07, 2021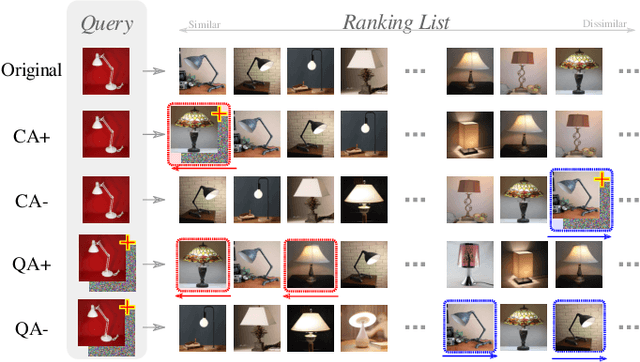
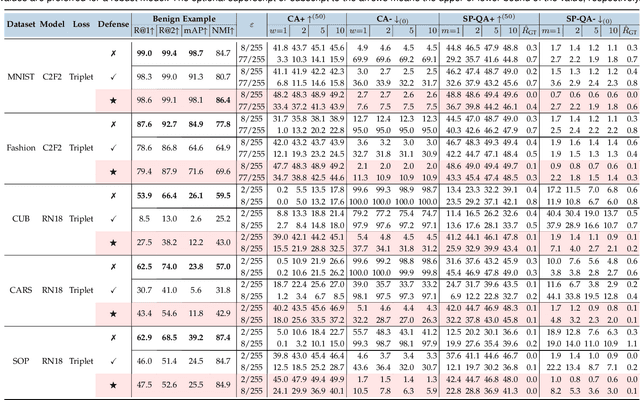
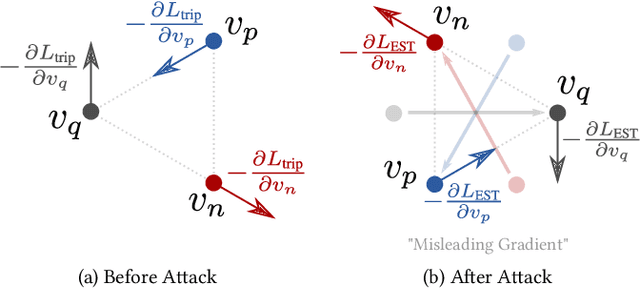
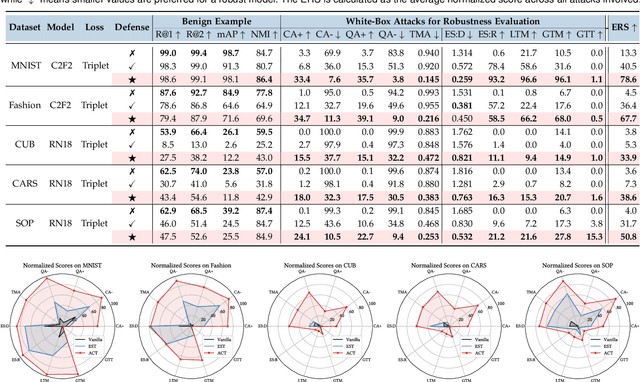
Deep Neural Network classifiers are vulnerable to adversarial attack, where an imperceptible perturbation could result in misclassification. However, the vulnerability of DNN-based image ranking systems remains under-explored. In this paper, we propose two attacks against deep ranking systems, i.e., Candidate Attack and Query Attack, that can raise or lower the rank of chosen candidates by adversarial perturbations. Specifically, the expected ranking order is first represented as a set of inequalities, and then a triplet-like objective function is designed to obtain the optimal perturbation. Conversely, an anti-collapse triplet defense is proposed to improve the ranking model robustness against all proposed attacks, where the model learns to prevent the positive and negative samples being pulled close to each other by adversarial attack. To comprehensively measure the empirical adversarial robustness of a ranking model with our defense, we propose an empirical robustness score, which involves a set of representative attacks against ranking models. Our adversarial ranking attacks and defenses are evaluated on MNIST, Fashion-MNIST, CUB200-2011, CARS196 and Stanford Online Products datasets. Experimental results demonstrate that a typical deep ranking system can be effectively compromised by our attacks. Nevertheless, our defense can significantly improve the ranking system robustness, and simultaneously mitigate a wide range of attacks.
Video Imprint
Jun 07, 2021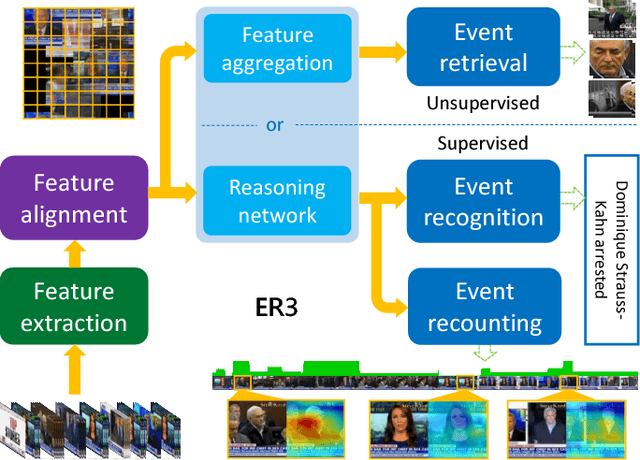


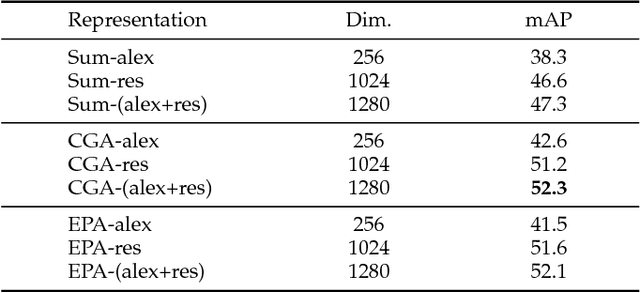
A new unified video analytics framework (ER3) is proposed for complex event retrieval, recognition and recounting, based on the proposed video imprint representation, which exploits temporal correlations among image features across video frames. With the video imprint representation, it is convenient to reverse map back to both temporal and spatial locations in video frames, allowing for both key frame identification and key areas localization within each frame. In the proposed framework, a dedicated feature alignment module is incorporated for redundancy removal across frames to produce the tensor representation, i.e., the video imprint. Subsequently, the video imprint is individually fed into both a reasoning network and a feature aggregation module, for event recognition/recounting and event retrieval tasks, respectively. Thanks to its attention mechanism inspired by the memory networks used in language modeling, the proposed reasoning network is capable of simultaneous event category recognition and localization of the key pieces of evidence for event recounting. In addition, the latent structure in our reasoning network highlights the areas of the video imprint, which can be directly used for event recounting. With the event retrieval task, the compact video representation aggregated from the video imprint contributes to better retrieval results than existing state-of-the-art methods.
Semi-supervised Long-tailed Recognition using Alternate Sampling
May 01, 2021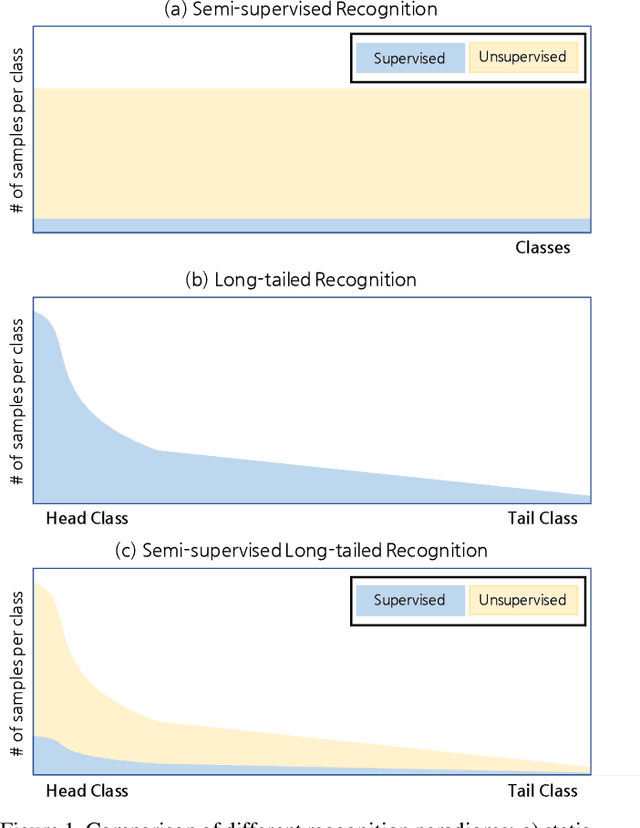
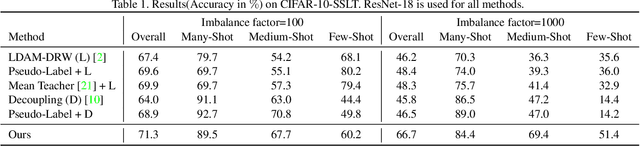
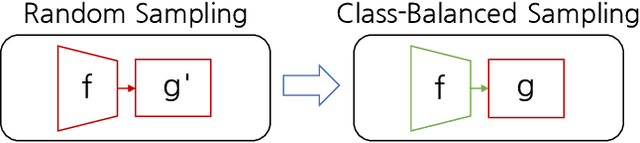
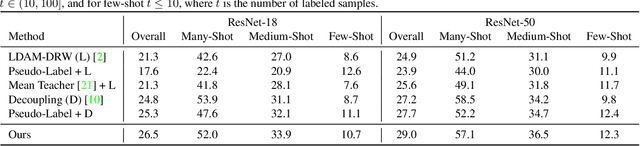
Main challenges in long-tailed recognition come from the imbalanced data distribution and sample scarcity in its tail classes. While techniques have been proposed to achieve a more balanced training loss and to improve tail classes data variations with synthesized samples, we resort to leverage readily available unlabeled data to boost recognition accuracy. The idea leads to a new recognition setting, namely semi-supervised long-tailed recognition. We argue this setting better resembles the real-world data collection and annotation process and hence can help close the gap to real-world scenarios. To address the semi-supervised long-tailed recognition problem, we present an alternate sampling framework combining the intuitions from successful methods in these two research areas. The classifier and feature embedding are learned separately and updated iteratively. The class-balanced sampling strategy has been implemented to train the classifier in a way not affected by the pseudo labels' quality on the unlabeled data. A consistency loss has been introduced to limit the impact from unlabeled data while leveraging them to update the feature embedding. We demonstrate significant accuracy improvements over other competitive methods on two datasets.
GistNet: a Geometric Structure Transfer Network for Long-Tailed Recognition
May 01, 2021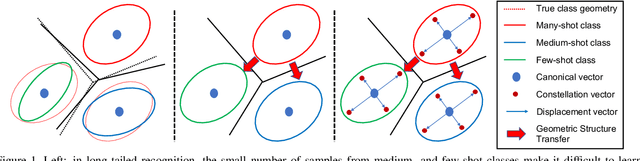
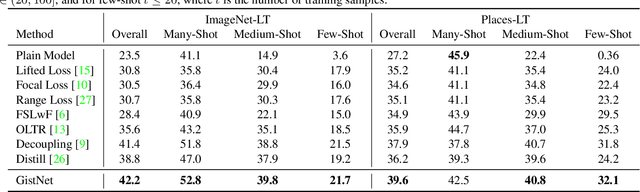
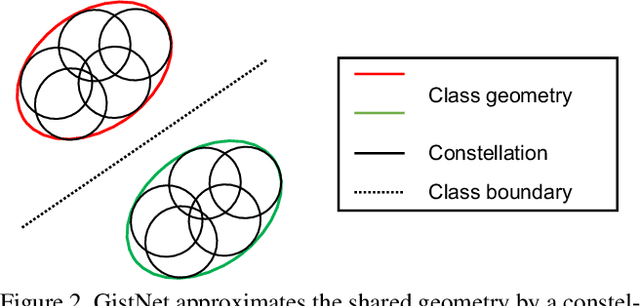

The problem of long-tailed recognition, where the number of examples per class is highly unbalanced, is considered. It is hypothesized that the well known tendency of standard classifier training to overfit to popular classes can be exploited for effective transfer learning. Rather than eliminating this overfitting, e.g. by adopting popular class-balanced sampling methods, the learning algorithm should instead leverage this overfitting to transfer geometric information from popular to low-shot classes. A new classifier architecture, GistNet, is proposed to support this goal, using constellations of classifier parameters to encode the class geometry. A new learning algorithm is then proposed for GeometrIc Structure Transfer (GIST), with resort to a combination of loss functions that combine class-balanced and random sampling to guarantee that, while overfitting to the popular classes is restricted to geometric parameters, it is leveraged to transfer class geometry from popular to few-shot classes. This enables better generalization for few-shot classes without the need for the manual specification of class weights, or even the explicit grouping of classes into different types. Experiments on two popular long-tailed recognition datasets show that GistNet outperforms existing solutions to this problem.
Breadcrumbs: Adversarial Class-Balanced Sampling for Long-tailed Recognition
May 01, 2021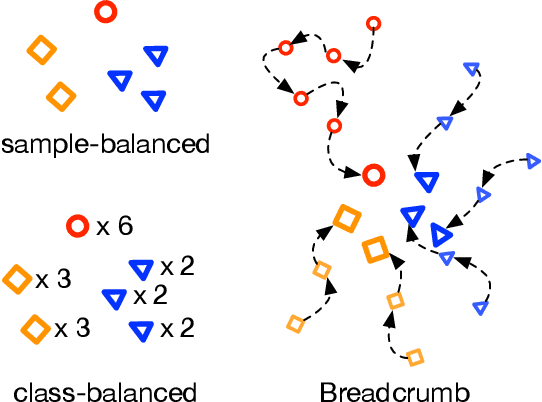
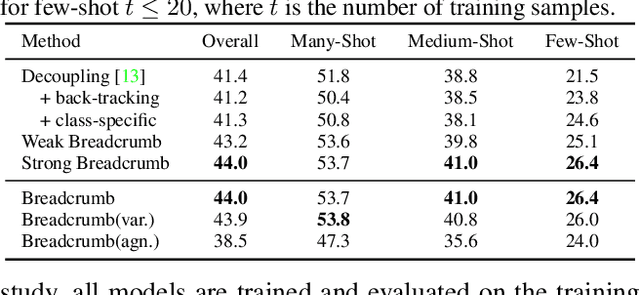
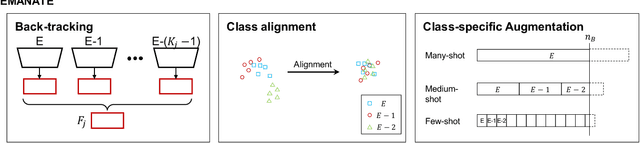
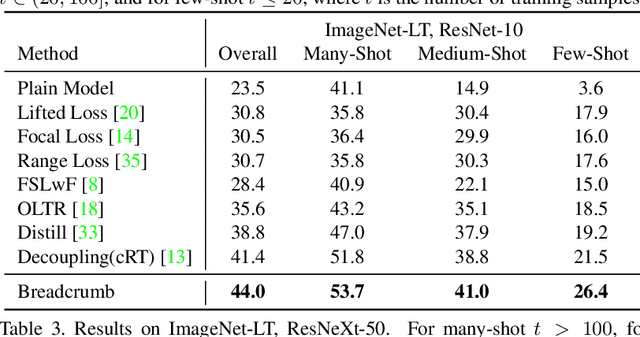
The problem of long-tailed recognition, where the number of examples per class is highly unbalanced, is considered. While training with class-balanced sampling has been shown effective for this problem, it is known to over-fit to few-shot classes. It is hypothesized that this is due to the repeated sampling of examples and can be addressed by feature space augmentation. A new feature augmentation strategy, EMANATE, based on back-tracking of features across epochs during training, is proposed. It is shown that, unlike class-balanced sampling, this is an adversarial augmentation strategy. A new sampling procedure, Breadcrumb, is then introduced to implement adversarial class-balanced sampling without extra computation. Experiments on three popular long-tailed recognition datasets show that Breadcrumb training produces classifiers that outperform existing solutions to the problem.
Sparse Pose Trajectory Completion
May 01, 2021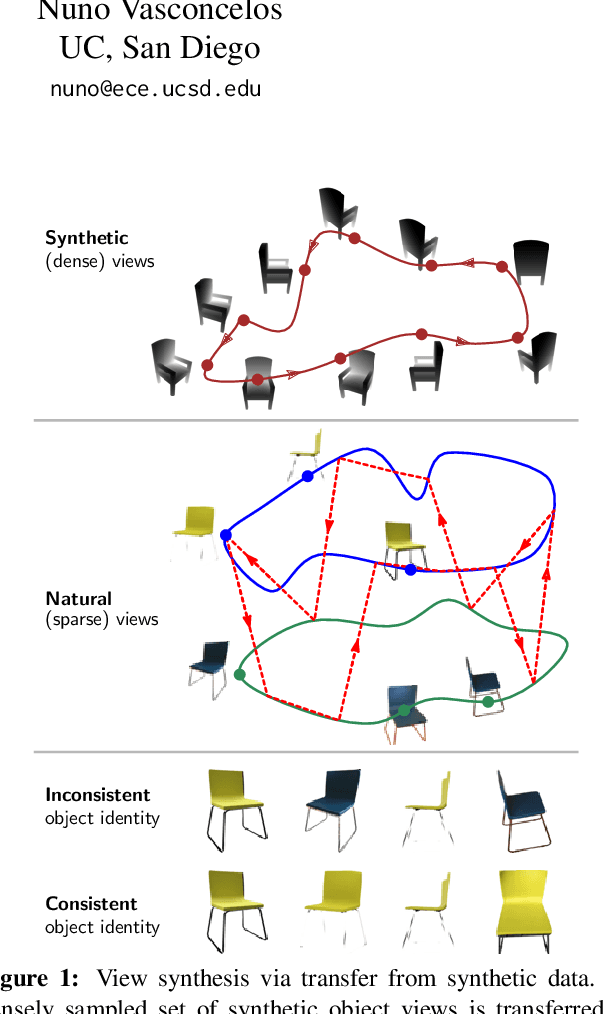
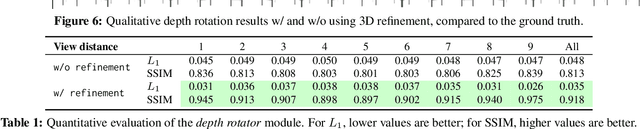
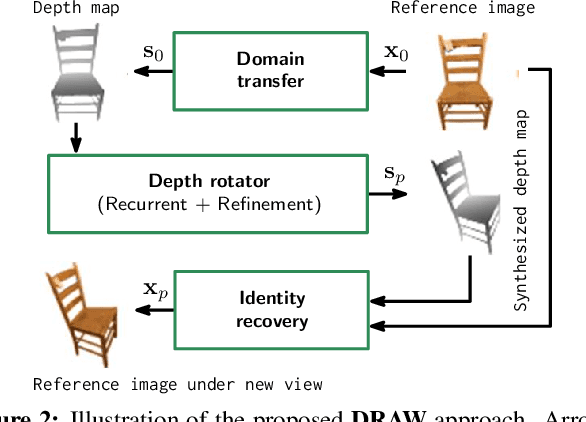
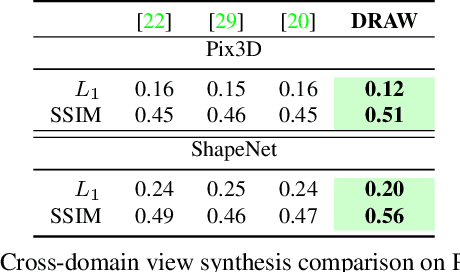
We propose a method to learn, even using a dataset where objects appear only in sparsely sampled views (e.g. Pix3D), the ability to synthesize a pose trajectory for an arbitrary reference image. This is achieved with a cross-modal pose trajectory transfer mechanism. First, a domain transfer function is trained to predict, from an RGB image of the object, its 2D depth map. Then, a set of image views is generated by learning to simulate object rotation in the depth space. Finally, the generated poses are mapped from this latent space into a set of corresponding RGB images using a learned identity preserving transform. This results in a dense pose trajectory of the object in image space. For each object type (e.g., a specific Ikea chair model), a 3D CAD model is used to render a full pose trajectory of 2D depth maps. In the absence of dense pose sampling in image space, these latent space trajectories provide cross-modal guidance for learning. The learned pose trajectories can be transferred to unseen examples, effectively synthesizing all object views in image space. Our method is evaluated on the Pix3D and ShapeNet datasets, in the setting of novel view synthesis under sparse pose supervision, demonstrating substantial improvements over recent art.
A Simple Baseline for StyleGAN Inversion
Apr 15, 2021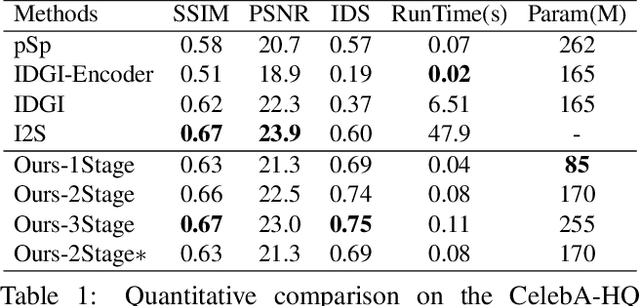
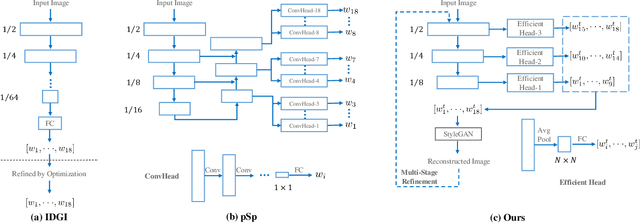
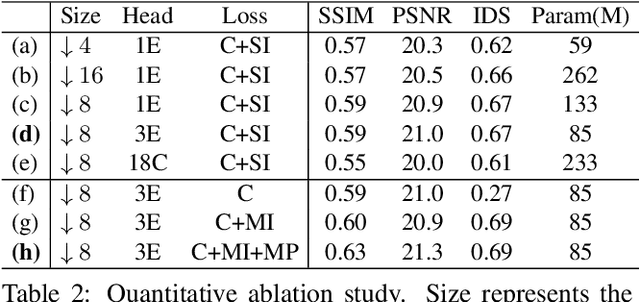

This paper studies the problem of StyleGAN inversion, which plays an essential role in enabling the pretrained StyleGAN to be used for real facial image editing tasks. This problem has the high demand for quality and efficiency. Existing optimization-based methods can produce high quality results, but the optimization often takes a long time. On the contrary, forward-based methods are usually faster but the quality of their results is inferior. In this paper, we present a new feed-forward network for StyleGAN inversion, with significant improvement in terms of efficiency and quality. In our inversion network, we introduce: 1) a shallower backbone with multiple efficient heads across scales; 2) multi-layer identity loss and multi-layer face parsing loss to the loss function; and 3) multi-stage refinement. Combining these designs together forms a simple and efficient baseline method which exploits all benefits of optimization-based and forward-based methods. Quantitative and qualitative results show that our method performs better than existing forward-based methods and comparably to state-of-the-art optimization-based methods, while maintaining the high efficiency as well as forward-based methods. Moreover, a number of real image editing applications demonstrate the efficacy of our method. Our project page is ~\url{https://wty-ustc.github.io/inversion}.