 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Computation with Elastic Input Sequence
Jan 30, 2023When solving a problem, human beings have the adaptive ability in terms of the type of information they use, the procedure they take, and the amount of time they spend approaching and solving the problem. However, most standard neural networks have the same function type and fixed computation budget on different samples regardless of their nature and difficulty. Adaptivity is a powerful paradigm as it not only imbues practitioners with flexibility pertaining to the downstream usage of these models but can also serve as a powerful inductive bias for solving certain challenging classes of problems. In this work, we propose a new strategy, AdaTape, that enables dynamic computation in neural networks via adaptive tape tokens. AdaTape employs an elastic input sequence by equipping an existing architecture with a dynamic read-and-write tape. Specifically, we adaptively generate input sequences using tape tokens obtained from a tape bank that can either be trainable or generated from input data. We analyze the challenges and requirements to obtain dynamic sequence content and length, and propose the Adaptive Tape Reader (ATR) algorithm to achieve both objectives. Via extensive experiments on image recognition tasks, we show that AdaTape can achieve better performance while maintaining the computational cost.
Deeper vs Wider: A Revisit of Transformer Configuration
May 24, 2022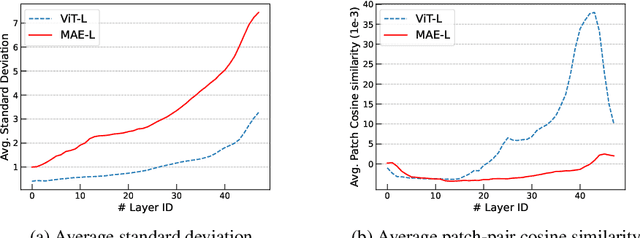
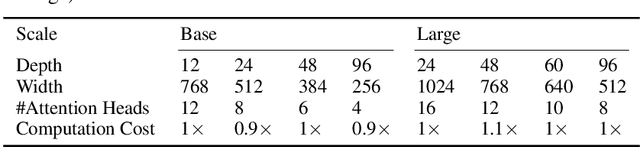
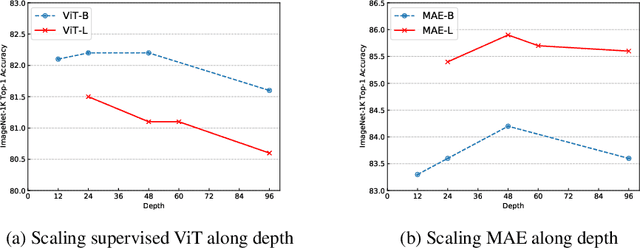

Transformer-based models have delivered impressive results on many tasks, particularly vision and language tasks. In many model training situations, conventional configurations are typically adopted. For example, we often set the base model with hidden dimensions (i.e. model width) to be 768 and the number of transformer layers (i.e. model depth) to be 12. In this paper, we revisit these conventional configurations. Through theoretical analysis and experimental evaluation, we show that the masked autoencoder is effective in alleviating the over-smoothing issue in deep transformer training. Based on this finding, we propose Bamboo, an idea of using deeper and narrower transformer configurations, for masked autoencoder training. On ImageNet, with such a simple change in configuration, re-designed model achieves 87.1% top-1 accuracy and outperforms SoTA models like MAE and BEiT. On language tasks, re-designed model outperforms BERT with default setting by 1.1 points on average, on GLUE datasets.
CowClip: Reducing CTR Prediction Model Training Time from 12 hours to 10 minutes on 1 GPU
Apr 22, 2022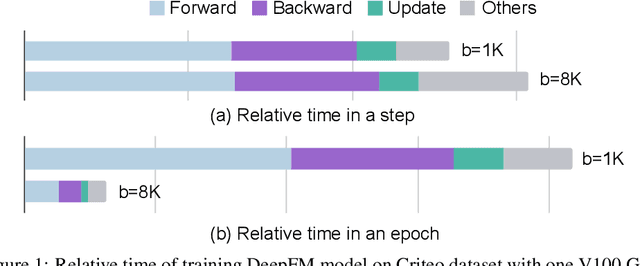
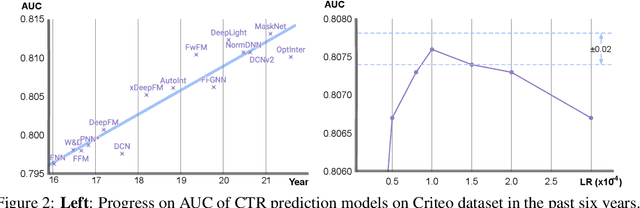
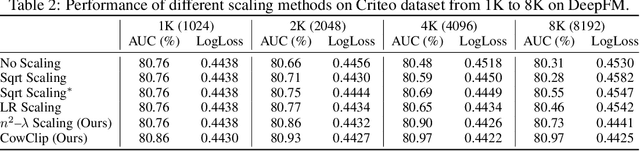
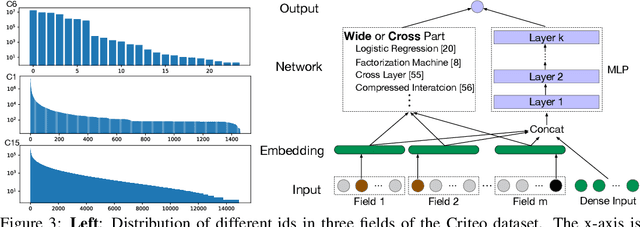
The click-through rate (CTR) prediction task is to predict whether a user will click on the recommended item. As mind-boggling amounts of data are produced online daily, accelerating CTR prediction model training is critical to ensuring an up-to-date model and reducing the training cost. One approach to increase the training speed is to apply large batch training. However, as shown in computer vision and natural language processing tasks, training with a large batch easily suffers from the loss of accuracy. Our experiments show that previous scaling rules fail in the training of CTR prediction neural networks. To tackle this problem, we first theoretically show that different frequencies of ids make it challenging to scale hyperparameters when scaling the batch size. To stabilize the training process in a large batch size setting, we develop the adaptive Column-wise Clipping (CowClip). It enables an easy and effective scaling rule for the embeddings, which keeps the learning rate unchanged and scales the L2 loss. We conduct extensive experiments with four CTR prediction networks on two real-world datasets and successfully scaled 128 times the original batch size without accuracy loss. In particular, for CTR prediction model DeepFM training on the Criteo dataset, our optimization framework enlarges the batch size from 1K to 128K with over 0.1% AUC improvement and reduces training time from 12 hours to 10 minutes on a single V100 GPU. Our code locates at https://github.com/bytedance/LargeBatchCTR.
Modeling Motion with Multi-Modal Features for Text-Based Video Segmentation
Apr 06, 2022
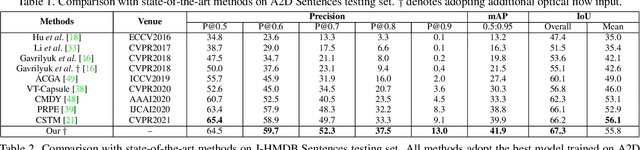
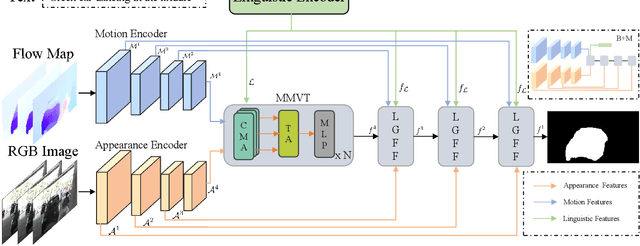
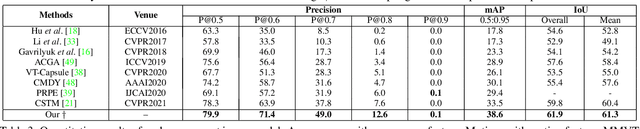
Text-based video segmentation aims to segment the target object in a video based on a describing sentence. Incorporating motion information from optical flow maps with appearance and linguistic modalities is crucial yet has been largely ignored by previous work. In this paper, we design a method to fuse and align appearance, motion, and linguistic features to achieve accurate segmentation. Specifically, we propose a multi-modal video transformer, which can fuse and aggregate multi-modal and temporal features between frames. Furthermore, we design a language-guided feature fusion module to progressively fuse appearance and motion features in each feature level with guidance from linguistic features. Finally, a multi-modal alignment loss is proposed to alleviate the semantic gap between features from different modalities. Extensive experiments on A2D Sentences and J-HMDB Sentences verify the performance and the generalization ability of our method compared to the state-of-the-art methods.
One Student Knows All Experts Know: From Sparse to Dense
Jan 26, 2022
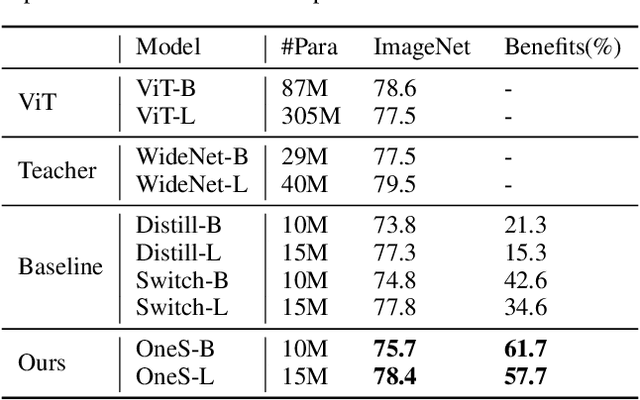
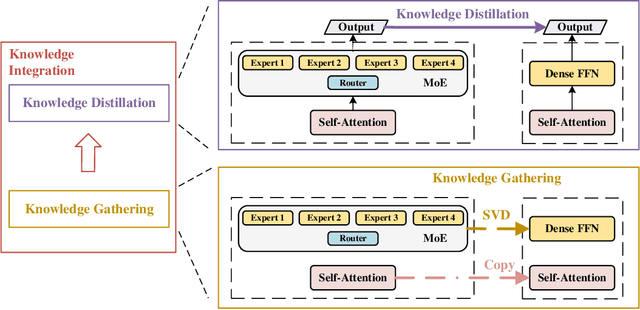
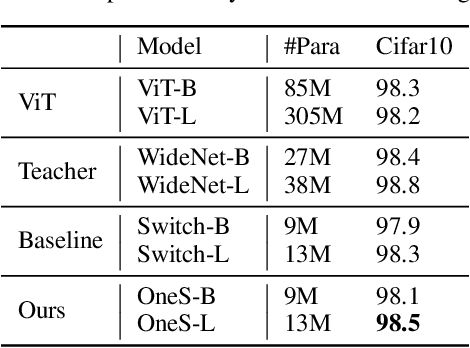
Human education system trains one student by multiple experts. Mixture-of-experts (MoE) is a powerful sparse architecture including multiple experts. However, sparse MoE model is hard to implement, easy to overfit, and not hardware-friendly. In this work, inspired by human education model, we propose a novel task, knowledge integration, to obtain a dense student model (OneS) as knowledgeable as one sparse MoE. We investigate this task by proposing a general training framework including knowledge gathering and knowledge distillation. Specifically, we first propose Singular Value Decomposition Knowledge Gathering (SVD-KG) to gather key knowledge from different pretrained experts. We then refine the dense student model by knowledge distillation to offset the noise from gathering. On ImageNet, our OneS preserves $61.7\%$ benefits from MoE. OneS can achieve $78.4\%$ top-1 accuracy with only $15$M parameters. On four natural language processing datasets, OneS obtains $88.2\%$ MoE benefits and outperforms SoTA by $51.7\%$ using the same architecture and training data. In addition, compared with the MoE counterpart, OneS can achieve $3.7 \times$ inference speedup due to the hardware-friendly architecture.
Large-Scale Deep Learning Optimizations: A Comprehensive Survey
Nov 02, 2021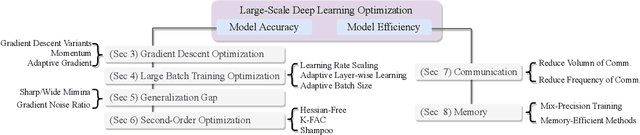
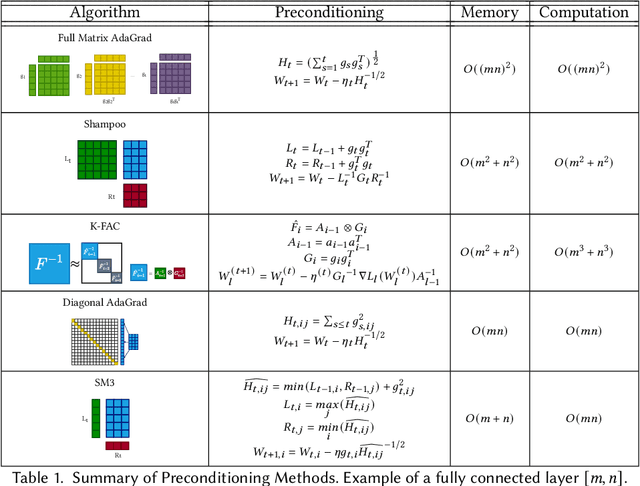
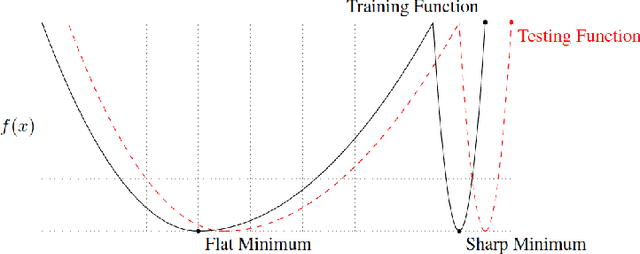

Deep learning have achieved promising results on a wide spectrum of AI applications. Larger datasets and models consistently yield better performance. However, we generally spend longer training time on more computation and communication. In this survey, we aim to provide a clear sketch about the optimizations for large-scale deep learning with regard to the model accuracy and model efficiency. We investigate algorithms that are most commonly used for optimizing, elaborate the debatable topic of generalization gap arises in large-batch training, and review the SOTA strategies in addressing the communication overhead and reducing the memory footprints.
Sparse-MLP: A Fully-MLP Architecture with Conditional Computation
Sep 08, 2021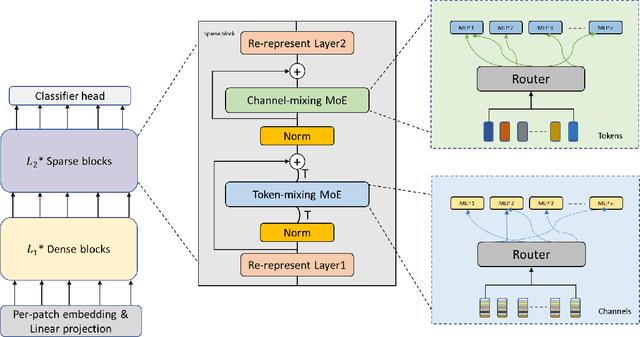

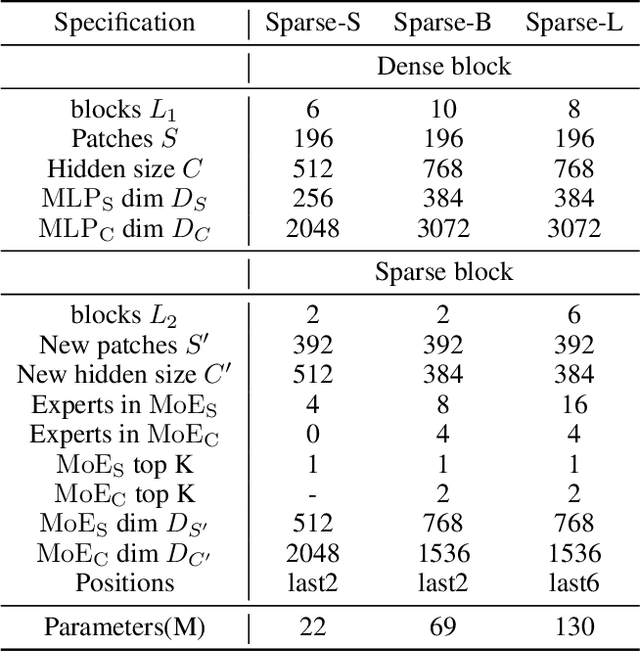
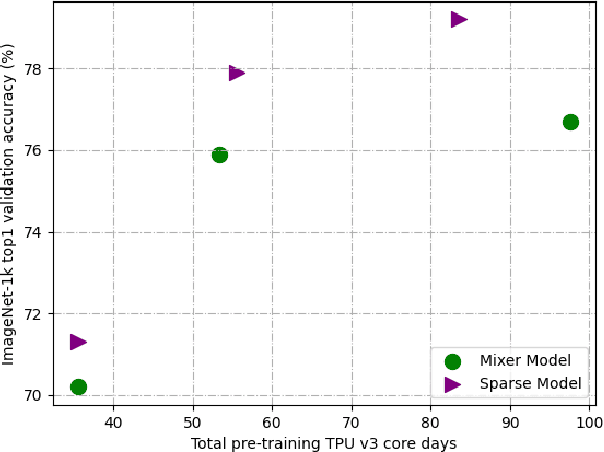
Mixture-of-Experts (MoE) with sparse conditional computation has been proved an effective architecture for scaling attention-based models to more parameters with comparable computation cost. In this paper, we propose Sparse-MLP, scaling the recent MLP-Mixer model with sparse MoE layers, to achieve a more computation-efficient architecture. We replace a subset of dense MLP blocks in the MLP-Mixer model with Sparse blocks. In each Sparse block, we apply two stages of MoE layers: one with MLP experts mixing information within channels along image patch dimension, one with MLP experts mixing information within patches along the channel dimension. Besides, to reduce computational cost in routing and improve expert capacity, we design Re-represent layers in each Sparse block. These layers are to re-scale image representations by two simple but effective linear transformations. When pre-training on ImageNet-1k with MoCo v3 algorithm, our models can outperform dense MLP models by 2.5\% on ImageNet Top-1 accuracy with fewer parameters and computational cost. On small-scale downstream image classification tasks, i.e. Cifar10 and Cifar100, our Sparse-MLP can still achieve better performance than baselines.
Automated Audio Captioning using Transfer Learning and Reconstruction Latent Space Similarity Regularization
Aug 10, 2021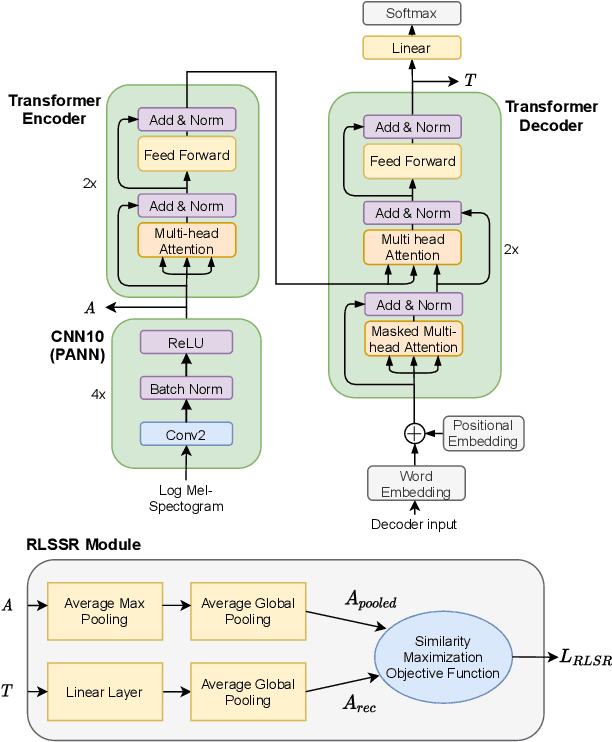

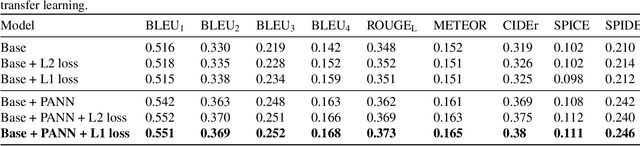

In this paper, we examine the use of Transfer Learning using Pretrained Audio Neural Networks (PANNs), and propose an architecture that is able to better leverage the acoustic features provided by PANNs for the Automated Audio Captioning Task. We also introduce a novel self-supervised objective, Reconstruction Latent Space Similarity Regularization (RLSSR). The RLSSR module supplements the training of the model by minimizing the similarity between the encoder and decoder embedding. The combination of both methods allows us to surpass state of the art results by a significant margin on the Clotho dataset across several metrics and benchmarks.
Go Wider Instead of Deeper
Jul 29, 2021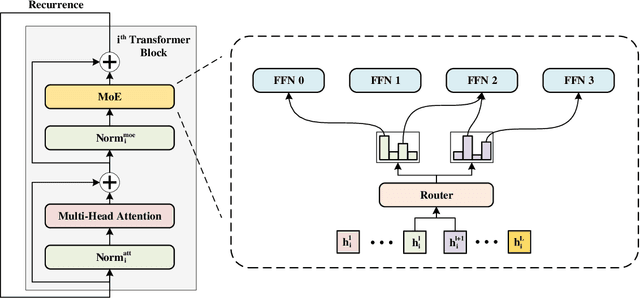
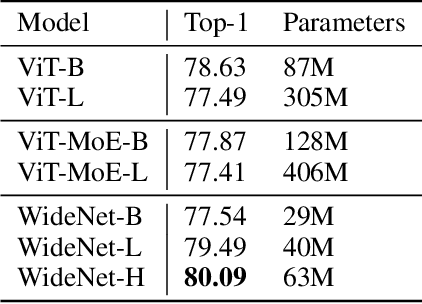
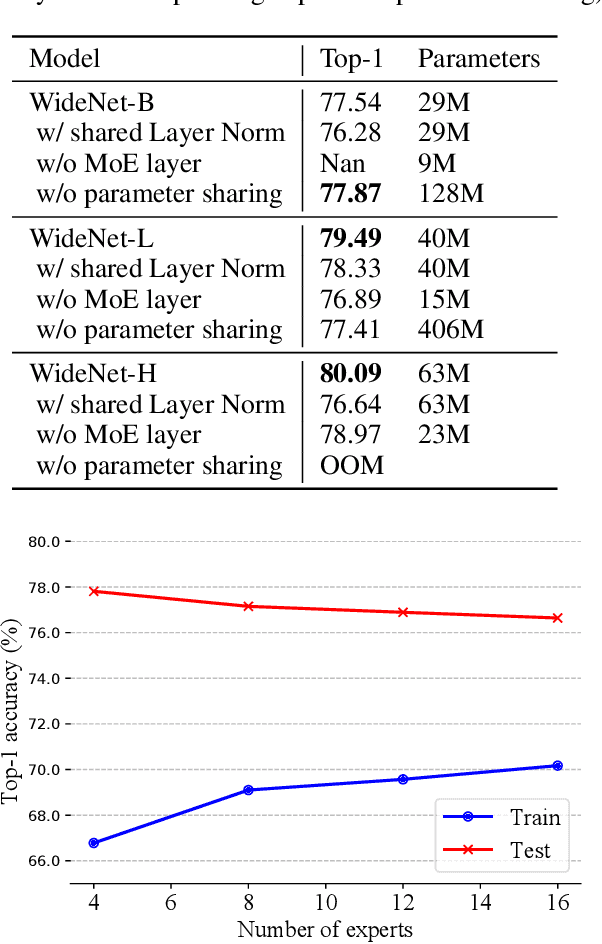
The transformer has recently achieved impressive results on various tasks. To further improve the effectiveness and efficiency of the transformer, there are two trains of thought among existing works: (1) going wider by scaling to more trainable parameters; (2) going shallower by parameter sharing or model compressing along with the depth. However, larger models usually do not scale well when fewer tokens are available to train, and advanced parallelisms are required when the model is extremely large. Smaller models usually achieve inferior performance compared to the original transformer model due to the loss of representation power. In this paper, to achieve better performance with fewer trainable parameters, we propose a framework to deploy trainable parameters efficiently, by going wider instead of deeper. Specially, we scale along model width by replacing feed-forward network (FFN) with mixture-of-experts (MoE). We then share the MoE layers across transformer blocks using individual layer normalization. Such deployment plays the role to transform various semantic representations, which makes the model more parameter-efficient and effective. To evaluate our framework, we design WideNet and evaluate it on ImageNet-1K. Our best model outperforms Vision Transformer (ViT) by $1.46\%$ with $0.72 \times$ trainable parameters. Using $0.46 \times$ and $0.13 \times$ parameters, our WideNet can still surpass ViT and ViT-MoE by $0.83\%$ and $2.08\%$, respectively.
Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey
Jun 01, 2021
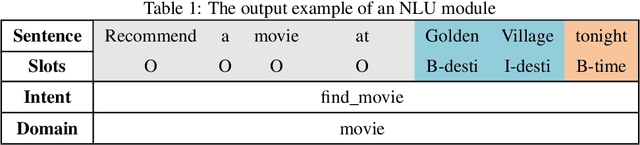
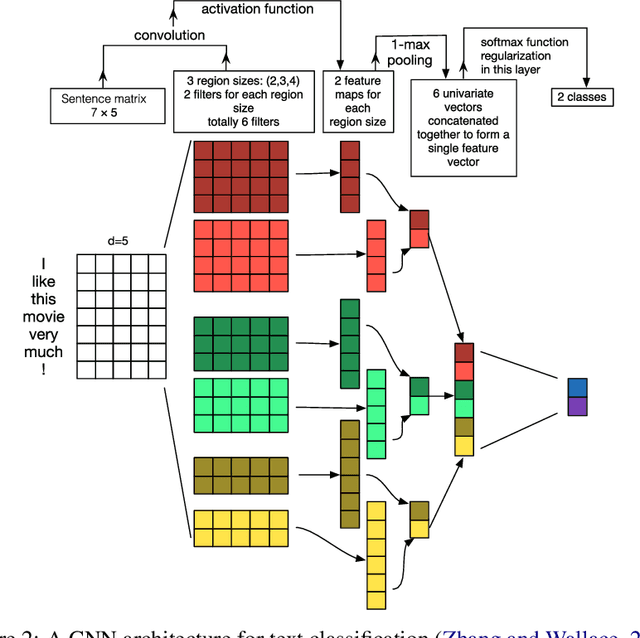
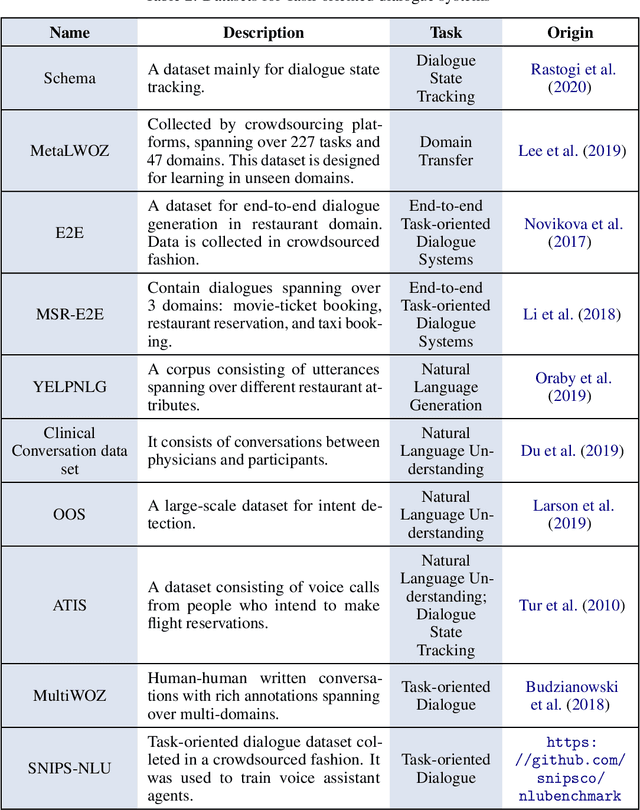
Dialogue systems are a popular Natural Language Processing (NLP) task as it is promising in real-life applications. It is also a complicated task since many NLP tasks deserving study are involved. As a result, a multitude of novel works on this task are carried out, and most of them are deep learning-based due to the outstanding performance. In this survey, we mainly focus on the deep learning-based dialogue systems. We comprehensively review state-of-the-art research outcomes in dialogue systems and analyze them from two angles: model type and system type. Specifically, from the angle of model type, we discuss the principles, characteristics, and applications of different models that are widely used in dialogue systems. This will help researchers acquaint these models and see how they are applied in state-of-the-art frameworks, which is rather helpful when designing a new dialogue system. From the angle of system type, we discuss task-oriented and open-domain dialogue systems as two streams of research, providing insight into the hot topics related. Furthermore, we comprehensively review the evaluation methods and datasets for dialogue systems to pave the way for future research. Finally, some possible research trends are identified based on the recent research outcomes. To the best of our knowledge, this survey is the most comprehensive and up-to-date one at present in the area of dialogue systems and dialogue-related tasks, extensively covering the popular frameworks, topics, and datasets. Keywords: Dialogue Systems, Chatbots, Conversational AI, Task-oriented, Open Domain, Chit-chat, Question Answering, Artificial Intelligence, Natural Language Processing, Information Retrieval, Deep Learning, Neural Networks, CNN, RNN, Hierarchical Recurrent Encoder-Decoder, Memory Networks, Attention, Transformer, Pointer Net, CopyNet, Reinforcement Learning, GANs, Knowledge Graph, Survey, Review