 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny but Accurate: A Pruned, Quantized and Optimized Memristor Crossbar Framework for Ultra Efficient DNN Implementation
Aug 27, 2019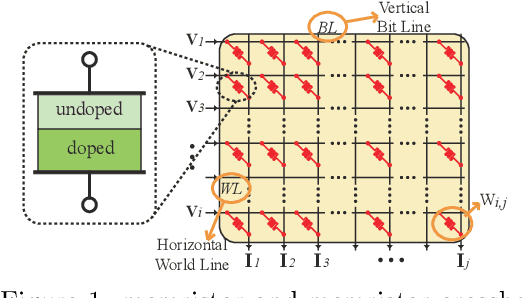
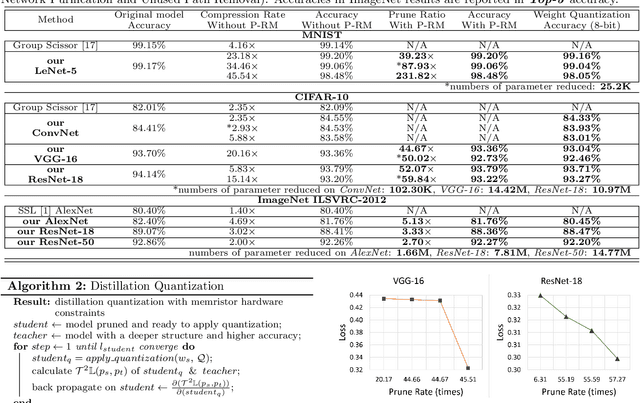
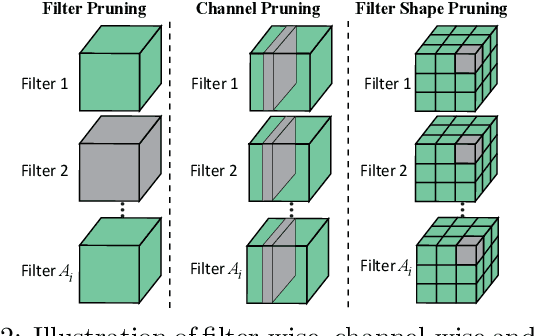
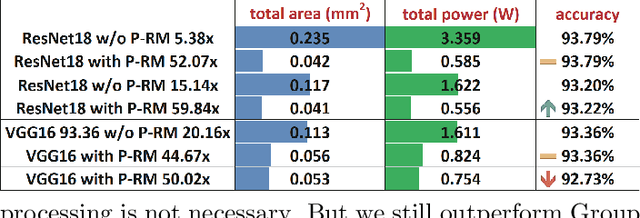
The state-of-art DNN structures involve intensive computation and high memory storage. To mitigate the challenges, the memristor crossbar array has emerged as an intrinsically suitable matrix computation and low-power acceleration framework for DNN applications. However, the high accuracy solution for extreme model compression on memristor crossbar array architecture is still waiting for unraveling. In this paper, we propose a memristor-based DNN framework which combines both structured weight pruning and quantization by incorporating alternating direction method of multipliers (ADMM) algorithm for better pruning and quantization performance. We also discover the non-optimality of the ADMM solution in weight pruning and the unused data path in a structured pruned model. Motivated by these discoveries, we design a software-hardware co-optimization framework which contains the first proposed Network Purification and Unused Path Removal algorithms targeting on post-processing a structured pruned model after ADMM steps. By taking memristor hardware constraints into our whole framework, we achieve extreme high compression ratio on the state-of-art neural network structures with minimum accuracy loss. For quantizing structured pruned model, our framework achieves nearly no accuracy loss after quantizing weights to 8-bit memristor weight representation. We share our models at anonymous link https://bit.ly/2VnMUy0.
ADMM for Efficient Deep Learning with Global Convergence
Jun 07, 2019
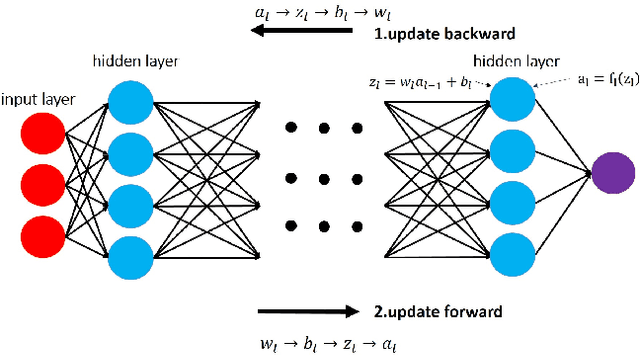
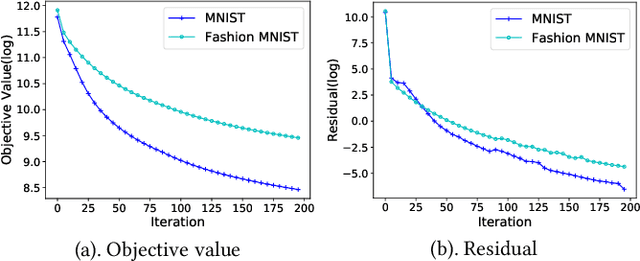
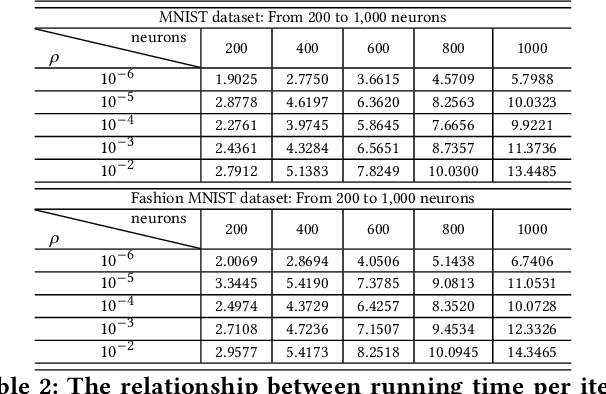
Alternating Direction Method of Multipliers (ADMM) has been used successfully in many conventional machine learning applications and is considered to be a useful alternative to Stochastic Gradient Descent (SGD) as a deep learning optimizer. However, as an emerging domain, several challenges remain, including 1) The lack of global convergence guarantees, 2) Slow convergence towards solutions, and 3) Cubic time complexity with regard to feature dimensions. In this paper, we propose a novel optimization framework for deep learning via ADMM (dlADMM) to address these challenges simultaneously. The parameters in each layer are updated backward and then forward so that the parameter information in each layer is exchanged efficiently. The time complexity is reduced from cubic to quadratic in (latent) feature dimensions via a dedicated algorithm design for subproblems that enhances them utilizing iterative quadratic approximations and backtracking. Finally, we provide the first proof of global convergence for an ADMM-based method (dlADMM) in a deep neural network problem under mild conditions. Experiments on benchmark datasets demonstrated that our proposed dlADMM algorithm outperforms most of the comparison methods.
DoPa: A Fast and Comprehensive CNN Defense Methodology against Physical Adversarial Attacks
May 21, 2019
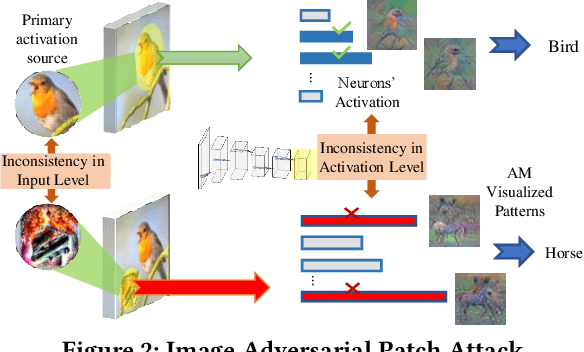
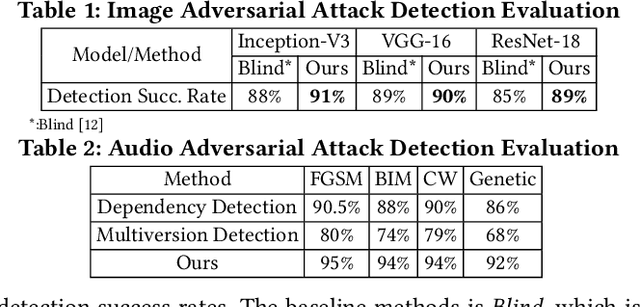
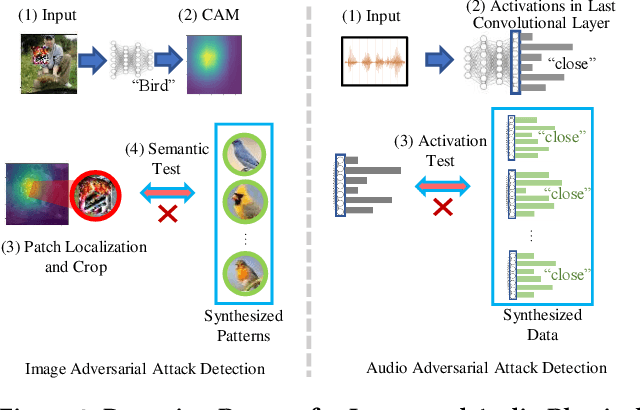
Recently, Convolutional Neural Networks (CNNs) demonstrate a considerable vulnerability to adversarial attacks, which can be easily misled by adversarial perturbations. With more aggressive methods proposed, adversarial attacks can be also applied to the physical world, causing practical issues to various CNN powered applications. Most existing defense works for physical adversarial attacks only focus on eliminating explicit perturbation patterns from inputs, ignoring interpretation and solution to CNN's intrinsic vulnerability. Therefore, most of them depend on considerable data processing costs and lack the expected versatility to different attacks. In this paper, we propose DoPa - a fast and comprehensive CNN defense methodology against physical adversarial attacks. By interpreting the CNN's vulnerability, we find that non-semantic adversarial perturbations can activate CNN with significantly abnormal activations and even overwhelm other semantic input patterns' activations. We improve the CNN recognition process by adding a self-verification stage to analyze the semantics of distinguished activation patterns with only one CNN inference involved. Based on the detection result, we further propose a data recovery methodology to defend the physical adversarial attacks. We apply such detection and defense methodology into both image and audio CNN recognition process. Experiments show that our methodology can achieve an average rate of 90% success for attack detection and 81% accuracy recovery for image physical adversarial attacks. Also, the proposed defense method can achieve a 92% detection successful rate and 77.5% accuracy recovery for audio recognition applications. Moreover, the proposed defense methods are at most 2.3x faster compared to the state-of-the-art defense methods, making them feasible to resource-constrained platforms, such as mobile devices.
Interpreting and Evaluating Neural Network Robustness
May 10, 2019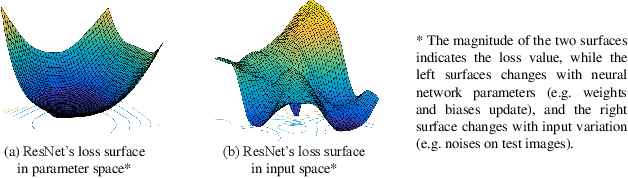
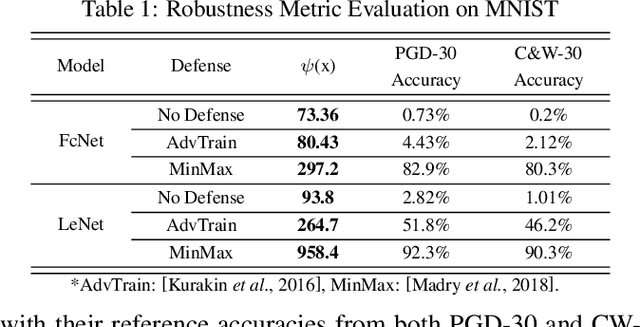
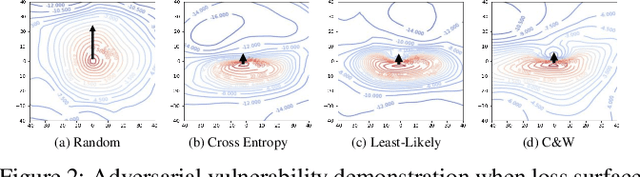
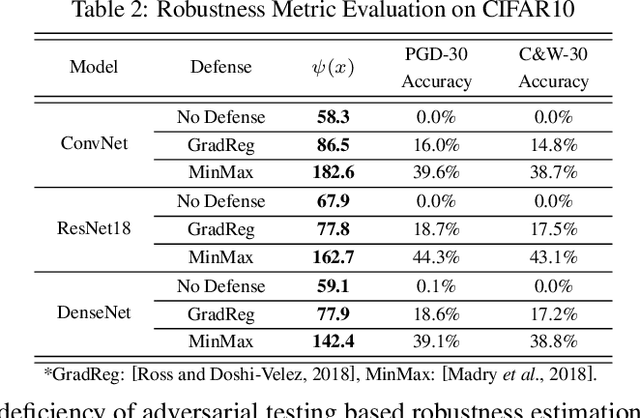
Recently, adversarial deception becomes one of the most considerable threats to deep neural networks. However, compared to extensive research in new designs of various adversarial attacks and defenses, the neural networks' intrinsic robustness property is still lack of thorough investigation. This work aims to qualitatively interpret the adversarial attack and defense mechanism through loss visualization, and establish a quantitative metric to evaluate the neural network model's intrinsic robustness. The proposed robustness metric identifies the upper bound of a model's prediction divergence in the given domain and thus indicates whether the model can maintain a stable prediction. With extensive experiments, our metric demonstrates several advantages over conventional adversarial testing accuracy based robustness estimation: (1) it provides a uniformed evaluation to models with different structures and parameter scales; (2) it over-performs conventional accuracy based robustness estimation and provides a more reliable evaluation that is invariant to different test settings; (3) it can be fast generated without considerable testing cost.
Progressive Weight Pruning of Deep Neural Networks using ADMM
Nov 04, 2018
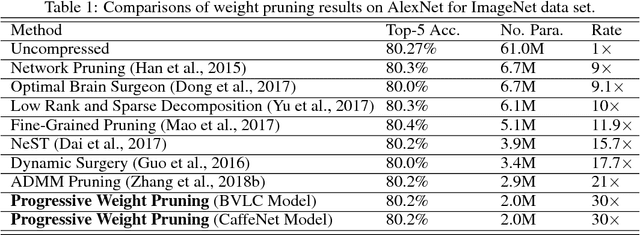
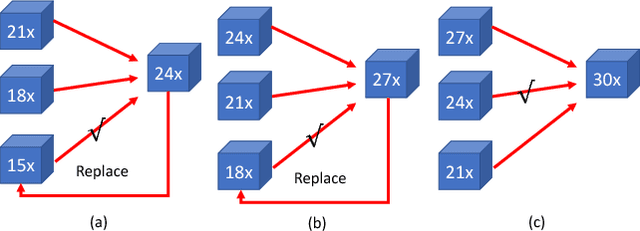

Deep neural networks (DNNs) although achieving human-level performance in many domains, have very large model size that hinders their broader applications on edge computing devices. Extensive research work have been conducted on DNN model compression or pruning. However, most of the previous work took heuristic approaches. This work proposes a progressive weight pruning approach based on ADMM (Alternating Direction Method of Multipliers), a powerful technique to deal with non-convex optimization problems with potentially combinatorial constraints. Motivated by dynamic programming, the proposed method reaches extremely high pruning rate by using partial prunings with moderate pruning rates. Therefore, it resolves the accuracy degradation and long convergence time problems when pursuing extremely high pruning ratios. It achieves up to 34 times pruning rate for ImageNet dataset and 167 times pruning rate for MNIST dataset, significantly higher than those reached by the literature work. Under the same number of epochs, the proposed method also achieves faster convergence and higher compression rates. The codes and pruned DNN models are released in the link bit.ly/2zxdlss
Interpreting Adversarial Robustness: A View from Decision Surface in Input Space
Oct 12, 2018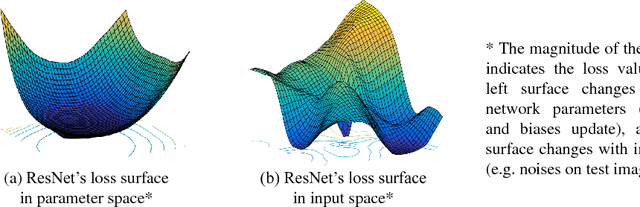
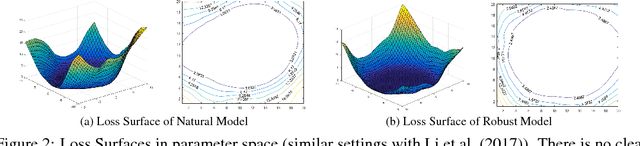
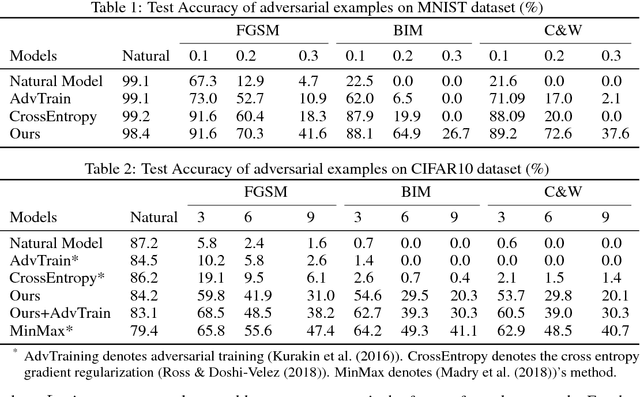
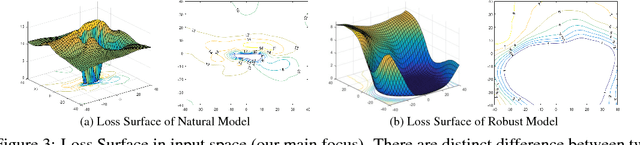
One popular hypothesis of neural network generalization is that the flat local minima of loss surface in parameter space leads to good generalization. However, we demonstrate that loss surface in parameter space has no obvious relationship with generalization, especially under adversarial settings. Through visualizing decision surfaces in both parameter space and input space, we instead show that the geometry property of decision surface in input space correlates well with the adversarial robustness. We then propose an adversarial robustness indicator, which can evaluate a neural network's intrinsic robustness property without testing its accuracy under adversarial attacks. Guided by it, we further propose our robust training method. Without involving adversarial training, our method could enhance network's intrinsic adversarial robustness against various adversarial attacks.
Interpretable Convolutional Filter Pruning
Oct 12, 2018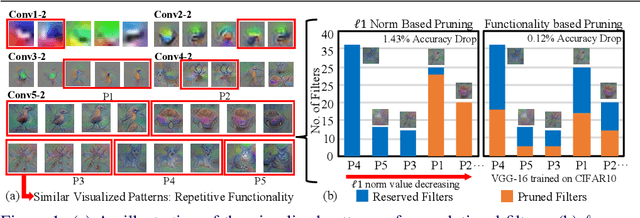
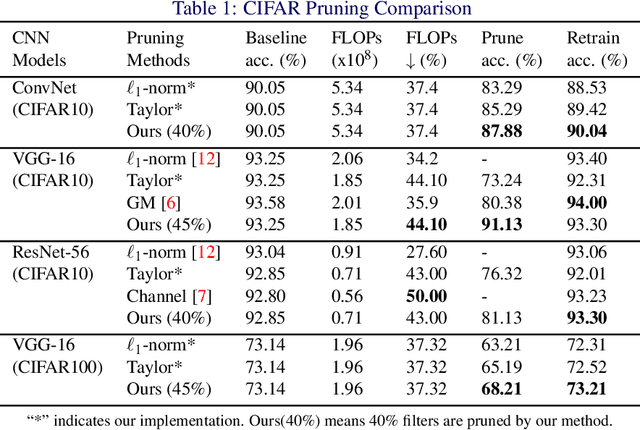
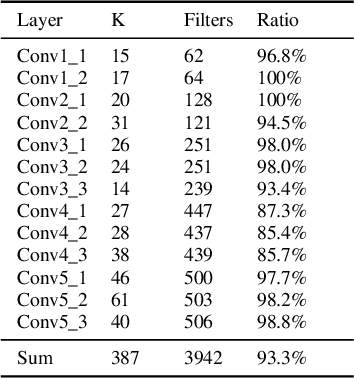
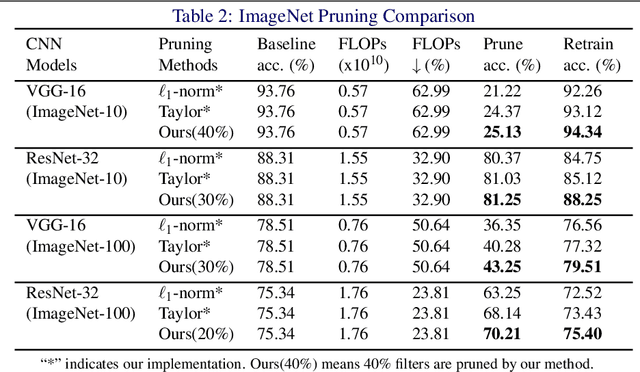
The sophisticated structure of Convolutional Neural Network (CNN) allows for outstanding performance, but at the cost of intensive computation. As significant redundancies inevitably present in such a structure, many works have been proposed to prune the convolutional filters for computation cost reduction. Although extremely effective, most works are based only on quantitative characteristics of the convolutional filters, and highly overlook the qualitative interpretation of individual filter's specific functionality. In this work, we interpreted the functionality and redundancy of the convolutional filters from different perspectives, and proposed a functionality-oriented filter pruning method. With extensive experiment results, we proved the convolutional filters' qualitative significance regardless of magnitude, demonstrated significant neural network redundancy due to repetitive filter functions, and analyzed the filter functionality defection under inappropriate retraining process. Such an interpretable pruning approach not only offers outstanding computation cost optimization over previous filter pruning methods, but also interprets filter pruning process.
HASP: A High-Performance Adaptive Mobile Security Enhancement Against Malicious Speech Recognition
Sep 04, 2018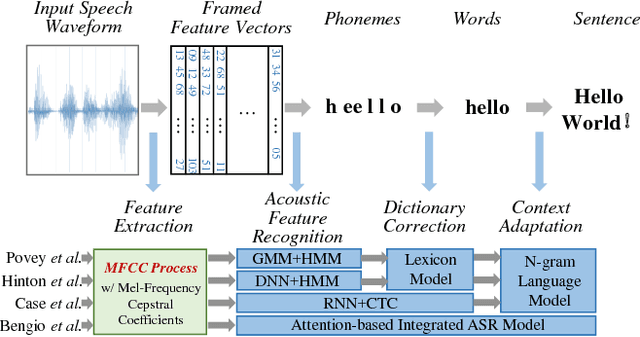
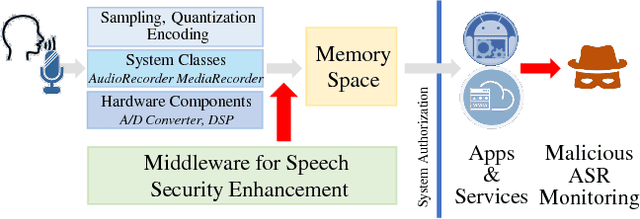
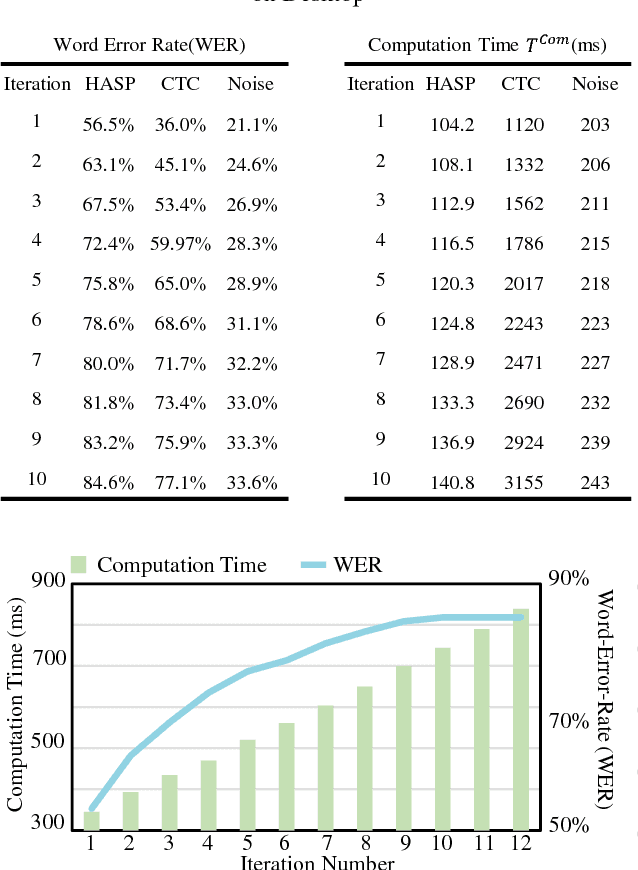
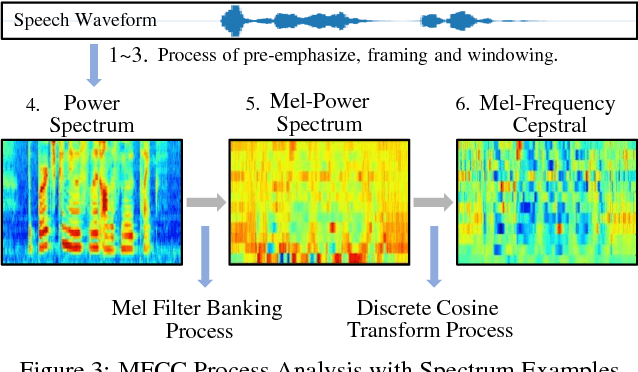
Nowadays, machine learning based Automatic Speech Recognition (ASR) technique has widely spread in smartphones, home devices, and public facilities. As convenient as this technology can be, a considerable security issue also raises -- the users' speech content might be exposed to malicious ASR monitoring and cause severe privacy leakage. In this work, we propose HASP -- a high-performance security enhancement approach to solve this security issue on mobile devices. Leveraging ASR systems' vulnerability to the adversarial examples, HASP is designed to cast human imperceptible adversarial noises to real-time speech and effectively perturb malicious ASR monitoring by increasing the Word Error Rate (WER). To enhance the practical performance on mobile devices, HASP is also optimized for effective adaptation to the human speech characteristics, environmental noises, and mobile computation scenarios. The experiments show that HASP can achieve optimal real-time security enhancement: it can lead an average WER of 84.55% for perturbing the malicious ASR monitoring, and the data processing speed is 15x to 40x faster compared to the state-of-the-art methods. Moreover, HASP can effectively perturb various ASR systems, demonstrating a strong transferability.
ASP:A Fast Adversarial Attack Example Generation Framework based on Adversarial Saliency Prediction
Jun 12, 2018
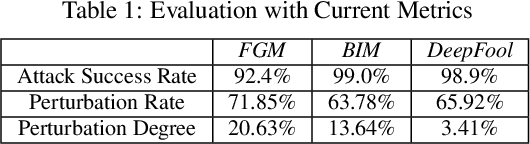
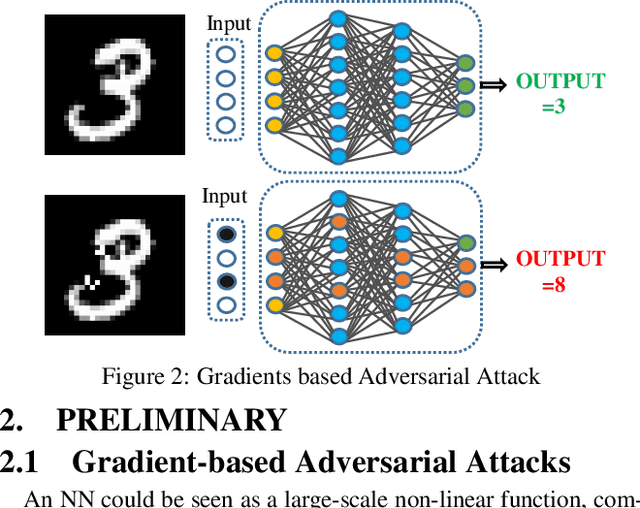

With the excellent accuracy and feasibility, the Neural Networks have been widely applied into the novel intelligent applications and systems. However, with the appearance of the Adversarial Attack, the NN based system performance becomes extremely vulnerable:the image classification results can be arbitrarily misled by the adversarial examples, which are crafted images with human unperceivable pixel-level perturbation. As this raised a significant system security issue, we implemented a series of investigations on the adversarial attack in this work: We first identify an image's pixel vulnerability to the adversarial attack based on the adversarial saliency analysis. By comparing the analyzed saliency map and the adversarial perturbation distribution, we proposed a new evaluation scheme to comprehensively assess the adversarial attack precision and efficiency. Then, with a novel adversarial saliency prediction method, a fast adversarial example generation framework, namely "ASP", is proposed with significant attack efficiency improvement and dramatic computation cost reduction. Compared to the previous methods, experiments show that ASP has at most 12 times speed-up for adversarial example generation, 2 times lower perturbation rate, and high attack success rate of 87% on both MNIST and Cifar10. ASP can be also well utilized to support the data-hungry NN adversarial training. By reducing the attack success rate as much as 90%, ASP can quickly and effectively enhance the defense capability of NN based system to the adversarial attacks.
Towards Robust Training of Neural Networks by Regularizing Adversarial Gradients
Jun 07, 2018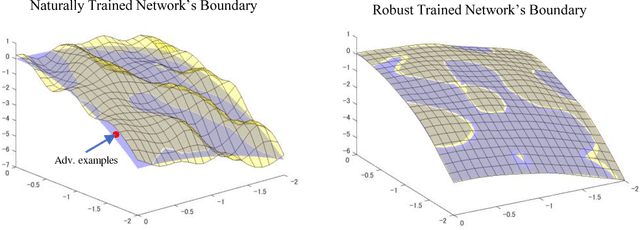
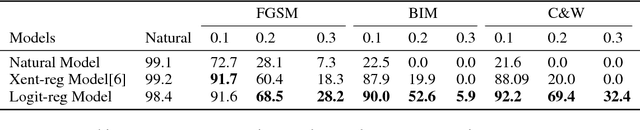

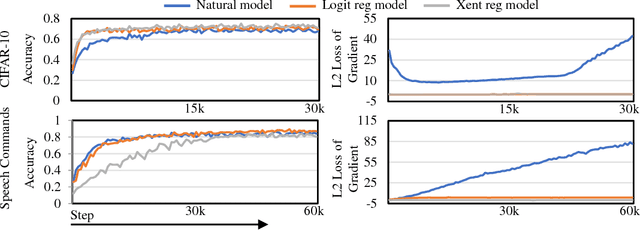
In recent years, neural networks have demonstrated outstanding effectiveness in a large amount of applications.However, recent works have shown that neural networks are susceptible to adversarial examples, indicating possible flaws intrinsic to the network structures. To address this problem and improve the robustness of neural networks, we investigate the fundamental mechanisms behind adversarial examples and propose a novel robust training method via regulating adversarial gradients. The regulation effectively squeezes the adversarial gradients of neural networks and significantly increases the difficulty of adversarial example generation.Without any adversarial example involved, the robust training method could generate naturally robust networks, which are near-immune to various types of adversarial examples. Experiments show the naturally robust networks can achieve optimal accuracy against Fast Gradient Sign Method (FGSM) and C\&W attacks on MNIST, Cifar10, and Google Speech Command dataset. Moreover, our proposed method also provides neural networks with consistent robustness against transferable attacks.