 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Calligraphy using Pseudospectral Optimal Control in Conjunction with a Simulated Brush Model
Nov 18, 2019
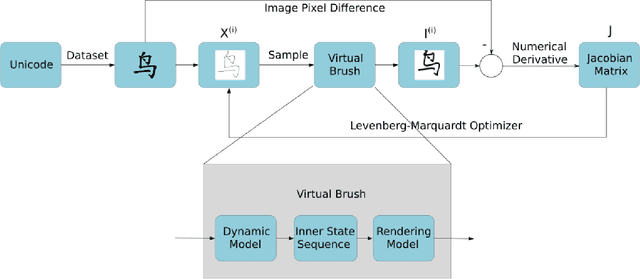
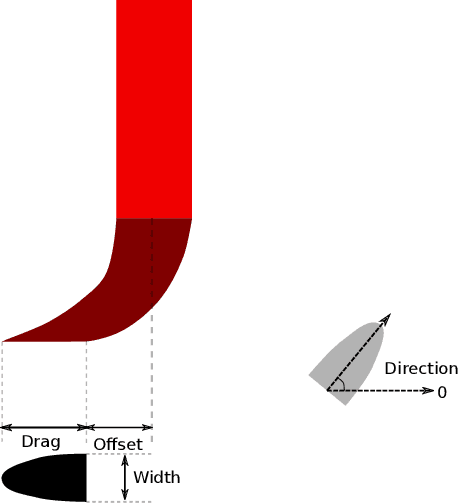
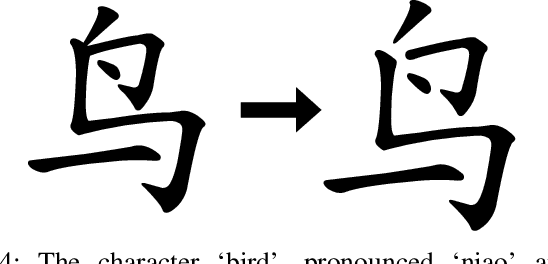
Chinese calligraphy is a unique form of art that has great artistic value but is difficult to master. In this paper, we make robots write calligraphy. Learning methods could teach robots to write, but may not be able to generalize to new characters. As such, we formulate the calligraphy writing problem as a trajectory optimization problem, and propose a new virtual brush model for simulating the real dynamic writing process. Our optimization approach is taken from pseudospectral optimal control, where the proposed dynamic virtual brush model plays a key role in formulating the objective function to be optimized. We also propose a stroke-level optimization to achieve better performance compared to the character-level optimization proposed in previous work. Our methodology shows good performance in drawing aesthetically pleasing characters.
Robotic Sculpting with Collision-free Motion Planning in Voxel Space
Nov 17, 2019
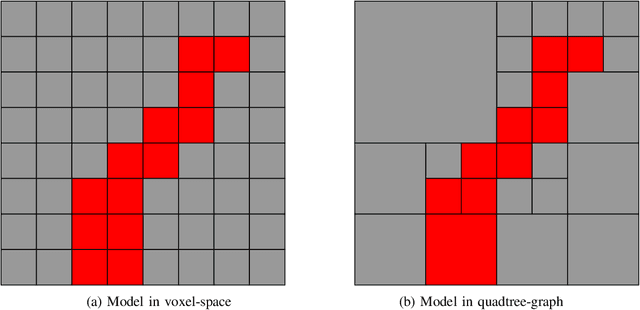
In this paper, we explore the task of robot sculpting. We propose a search based planning algorithm to solve the problem of sculpting by material removal with a multi-axis manipulator. We generate collision free trajectories for a manipulator using best-first search in voxel space. We also show significant speedup of our algorithm by using octrees to decompose the voxel space. We demonstrate our algorithm on a multi-axis manipulator in simulation by sculpting Michelangelo's Statue of David, evaluate certain metrics of our algorithm and discuss future goals for the project.
Fast 3D Pose Refinement with RGB Images
Nov 17, 2019
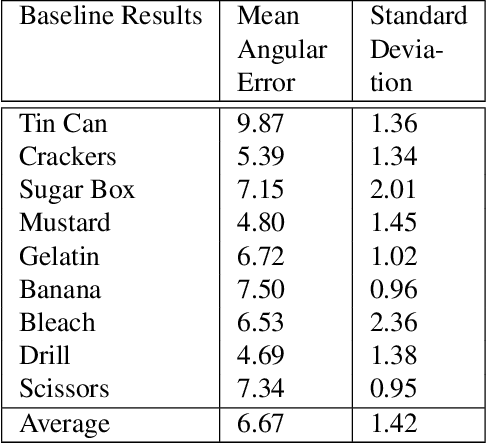

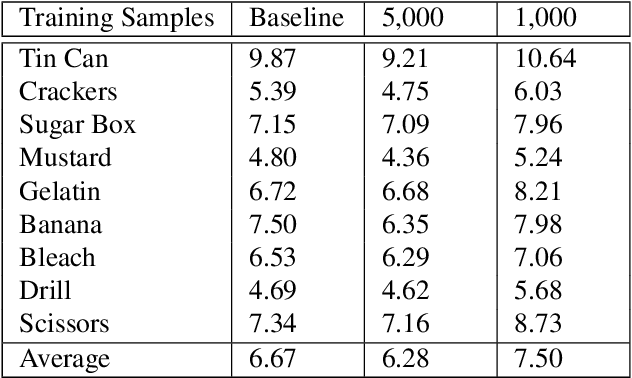
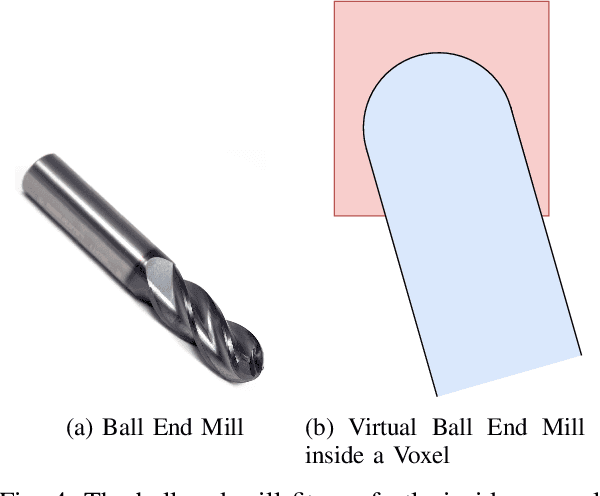
Pose estimation is a vital step in many robotics and perception tasks such as robotic manipulation, autonomous vehicle navigation, etc. Current state-of-the-art pose estimation methods rely on deep neural networks with complicated structures and long inference times. While highly robust, they require computing power often unavailable on mobile robots. We propose a CNN-based pose refinement system which takes a coarsely estimated 3D pose from a computationally cheaper algorithm along with a bounding box image of the object, and returns a highly refined pose. Our experiments on the YCB-Video dataset show that our system can refine 3D poses to an extremely high precision with minimal training data.
Taking a Deeper Look at the Inverse Compositional Algorithm
Dec 17, 2018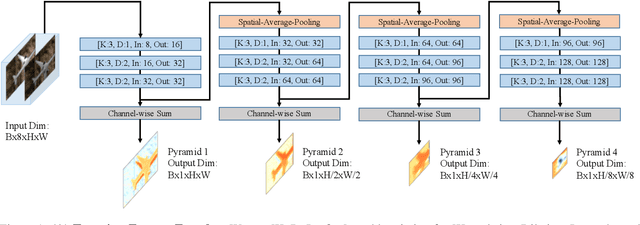

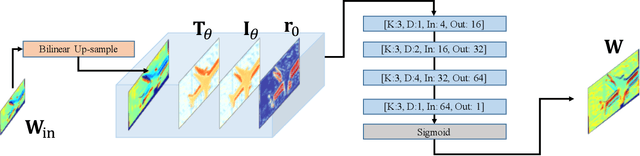
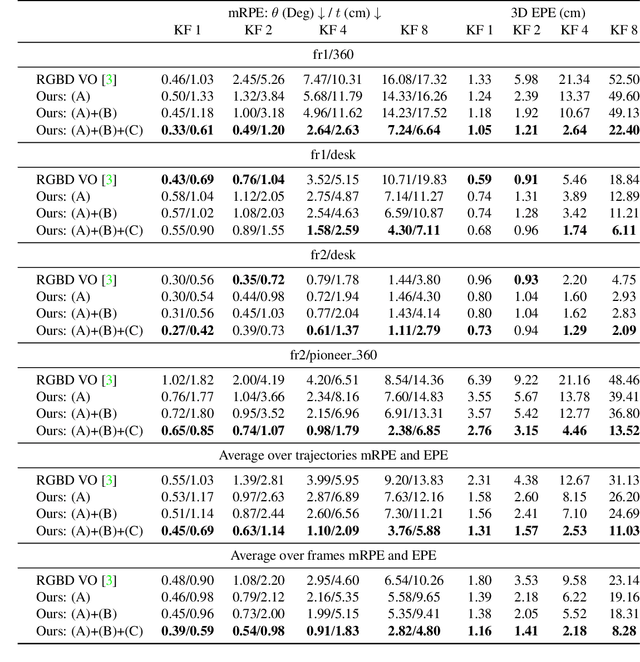
In this paper, we provide a modern synthesis of the classic inverse compositional algorithm for dense image alignment. We first discuss the assumptions made by this well-established technique, and subsequently propose to relax these assumptions by incorporating data-driven priors into this model. More specifically, we unroll a robust version of the inverse compositional algorithm and replace multiple components of this algorithm using more expressive models whose parameters we train in an end-to-end fashion from data. Our experiments on several challenging 3D rigid motion estimation tasks demonstrate the advantages of combining optimization with learning-based techniques, outperforming the classic inverse compositional algorithm as well as data-driven image-to-pose regression approaches.
Continuous-Time Gaussian Process Motion Planning via Probabilistic Inference
Nov 22, 2018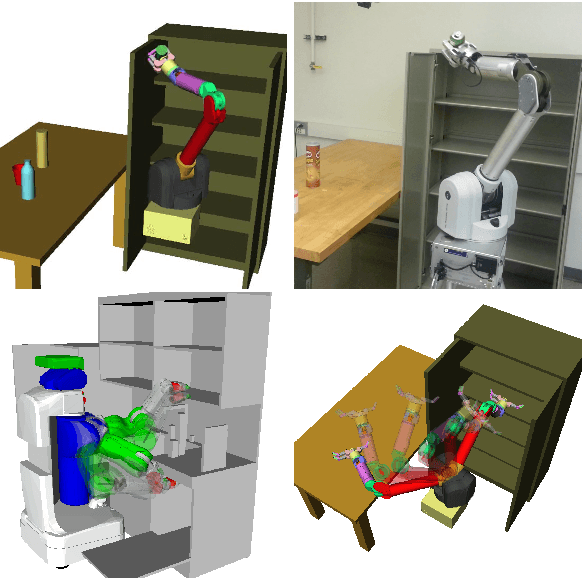


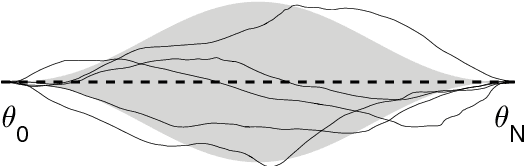
We introduce a novel formulation of motion planning, for continuous-time trajectories, as probabilistic inference. We first show how smooth continuous-time trajectories can be represented by a small number of states using sparse Gaussian process (GP) models. We next develop an efficient gradient-based optimization algorithm that exploits this sparsity and GP interpolation. We call this algorithm the Gaussian Process Motion Planner (GPMP). We then detail how motion planning problems can be formulated as probabilistic inference on a factor graph. This forms the basis for GPMP2, a very efficient algorithm that combines GP representations of trajectories with fast, structure-exploiting inference via numerical optimization. Finally, we extend GPMP2 to an incremental algorithm, iGPMP2, that can efficiently replan when conditions change. We benchmark our algorithms against several sampling-based and trajectory optimization-based motion planning algorithms on planning problems in multiple environments. Our evaluation reveals that GPMP2 is several times faster than previous algorithms while retaining robustness. We also benchmark iGPMP2 on replanning problems, and show that it can find successful solutions in a fraction of the time required by GPMP2 to replan from scratch.
Learning to Align Images using Weak Geometric Supervision
Aug 04, 2018
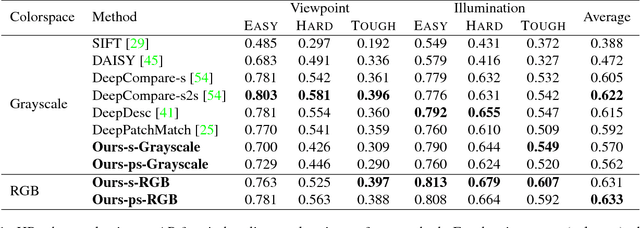
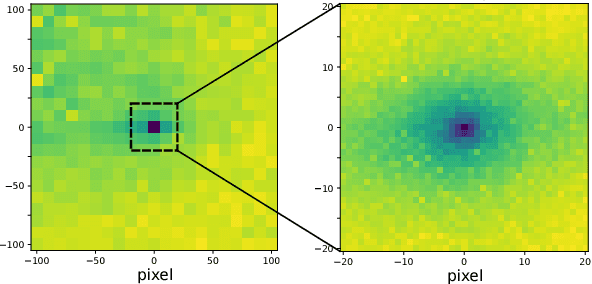
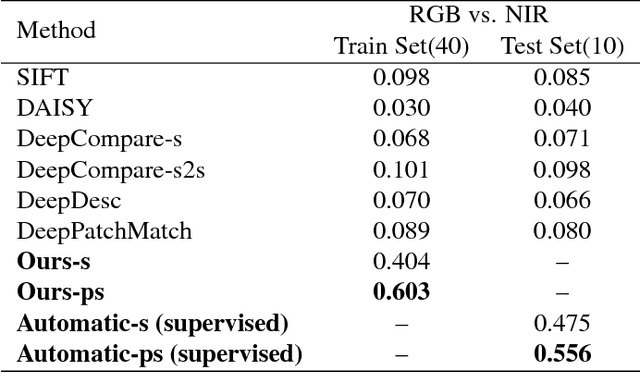
Image alignment tasks require accurate pixel correspondences, which are usually recovered by matching local feature descriptors. Such descriptors are often derived using supervised learning on existing datasets with ground truth correspondences. However, the cost of creating such datasets is usually prohibitive. In this paper, we propose a new approach to align two images related by an unknown 2D homography where the local descriptor is learned from scratch from the images and the homography is estimated simultaneously. Our key insight is that a siamese convolutional neural network can be trained jointly while iteratively updating the homography parameters by optimizing a single loss function. Our method is currently weakly supervised because the input images need to be roughly aligned. We have used this method to align images of different modalities such as RGB and near-infra-red (NIR) without using any prior labeled data. Images automatically aligned by our method were then used to train descriptors that generalize to new images. We also evaluated our method on RGB images. On the HPatches benchmark, our method achieves comparable accuracy to deep local descriptors that were trained offline in a supervised setting.
STEAP: simultaneous trajectory estimation and planning
Jul 27, 2018


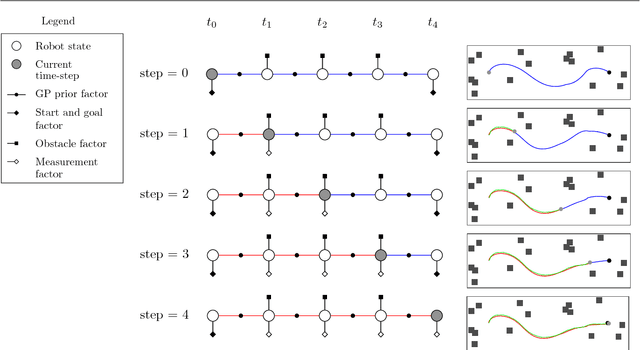
We present a unified probabilistic framework for simultaneous trajectory estimation and planning (STEAP). Estimation and planning problems are usually considered separately, however, within our framework we show that solving them simultaneously can be more accurate and efficient. The key idea is to compute the full continuous-time trajectory from start to goal at each time-step. While the robot traverses the trajectory, the history portion of the trajectory signifies the solution to the estimation problem, and the future portion of the trajectory signifies a solution to the planning problem. Building on recent probabilistic inference approaches to continuous-time localization and mapping and continuous-time motion planning, we solve the joint problem by iteratively recomputing the maximum a posteriori trajectory conditioned on all available sensor data and cost information. Our approach can contend with high-degree-of-freedom (DOF) trajectory spaces, uncertainty due to limited sensing capabilities, model inaccuracy, the stochastic effect of executing actions, and can find a solution in real-time. We evaluate our framework empirically in both simulation and on a mobile manipulator.
Sparse Gaussian Processes for Continuous-Time Trajectory Estimation on Matrix Lie Groups
May 17, 2017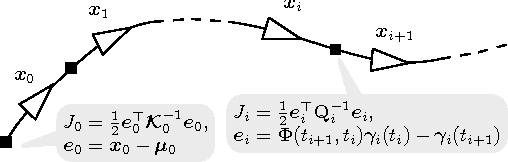
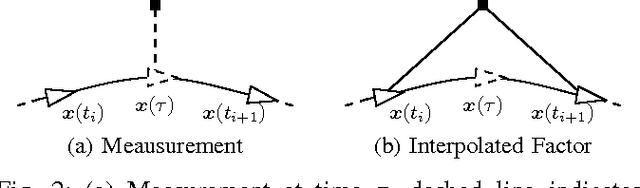
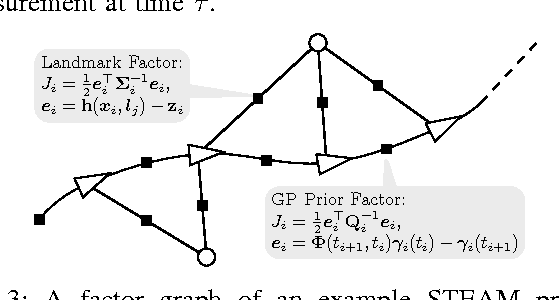
Continuous-time trajectory representations are a powerful tool that can be used to address several issues in many practical simultaneous localization and mapping (SLAM) scenarios, like continuously collected measurements distorted by robot motion, or during with asynchronous sensor measurements. Sparse Gaussian processes (GP) allow for a probabilistic non-parametric trajectory representation that enables fast trajectory estimation by sparse GP regression. However, previous approaches are limited to dealing with vector space representations of state only. In this technical report we extend the work by Barfoot et al. [1] to general matrix Lie groups, by applying constant-velocity prior, and defining locally linear GP. This enables using sparse GP approach in a large space of practical SLAM settings. In this report we give the theory and leave the experimental evaluation in future publications.
Distributed Mapping with Privacy and Communication Constraints: Lightweight Algorithms and Object-based Models
Feb 11, 2017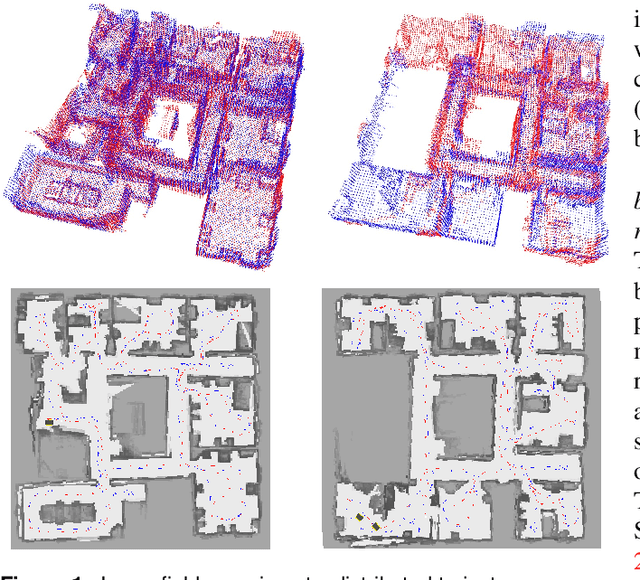
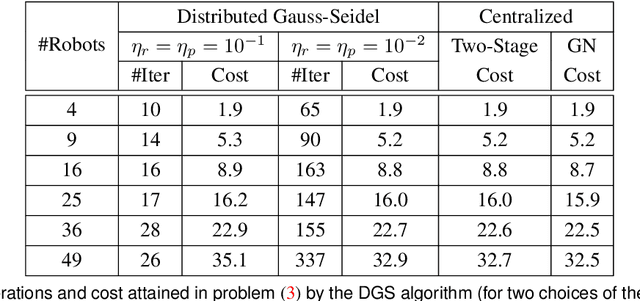
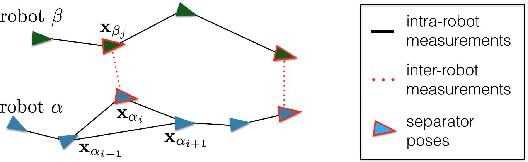
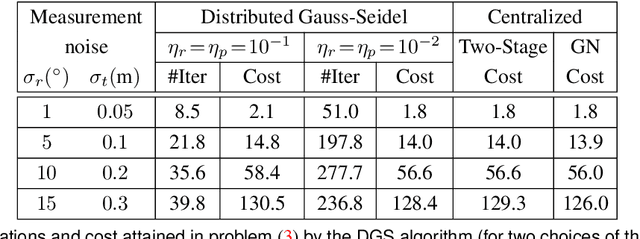
We consider the following problem: a team of robots is deployed in an unknown environment and it has to collaboratively build a map of the area without a reliable infrastructure for communication. The backbone for modern mapping techniques is pose graph optimization, which estimates the trajectory of the robots, from which the map can be easily built. The first contribution of this paper is a set of distributed algorithms for pose graph optimization: rather than sending all sensor data to a remote sensor fusion server, the robots exchange very partial and noisy information to reach an agreement on the pose graph configuration. Our approach can be considered as a distributed implementation of the two-stage approach of Carlone et al., where we use the Successive Over-Relaxation (SOR) and the Jacobi Over-Relaxation (JOR) as workhorses to split the computation among the robots. As a second contribution, we extend %and demonstrate the applicability of the proposed distributed algorithms to work with object-based map models. The use of object-based models avoids the exchange of raw sensor measurements (e.g., point clouds) further reducing the communication burden. Our third contribution is an extensive experimental evaluation of the proposed techniques, including tests in realistic Gazebo simulations and field experiments in a military test facility. Abundant experimental evidence suggests that one of the proposed algorithms (the Distributed Gauss-Seidel method or DGS) has excellent performance. The DGS requires minimal information exchange, has an anytime flavor, scales well to large teams, is robust to noise, and is easy to implement. Our field tests show that the combined use of our distributed algorithms and object-based models reduces the communication requirements by several orders of magnitude and enables distributed mapping with large teams of robots in real-world problems.
On-Manifold Preintegration for Real-Time Visual-Inertial Odometry
Oct 30, 2016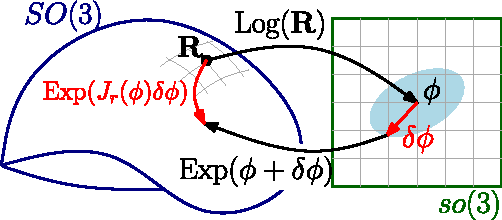
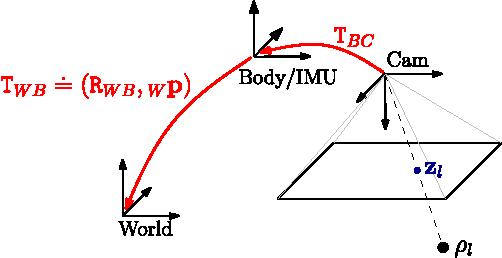
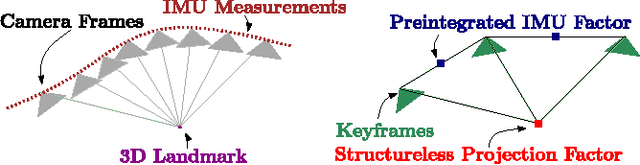
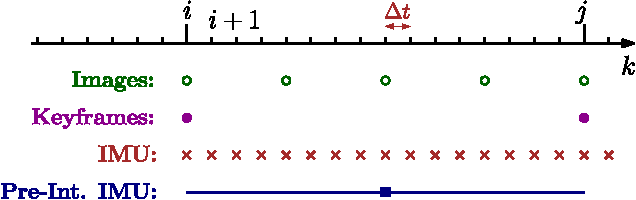
Current approaches for visual-inertial odometry (VIO) are able to attain highly accurate state estimation via nonlinear optimization. However, real-time optimization quickly becomes infeasible as the trajectory grows over time, this problem is further emphasized by the fact that inertial measurements come at high rate, hence leading to fast growth of the number of variables in the optimization. In this paper, we address this issue by preintegrating inertial measurements between selected keyframes into single relative motion constraints. Our first contribution is a \emph{preintegration theory} that properly addresses the manifold structure of the rotation group. We formally discuss the generative measurement model as well as the nature of the rotation noise and derive the expression for the \emph{maximum a posteriori} state estimator. Our theoretical development enables the computation of all necessary Jacobians for the optimization and a-posteriori bias correction in analytic form. The second contribution is to show that the preintegrated IMU model can be seamlessly integrated into a visual-inertial pipeline under the unifying framework of factor graphs. This enables the application of incremental-smoothing algorithms and the use of a \emph{structureless} model for visual measurements, which avoids optimizing over the 3D points, further accelerating the computation. We perform an extensive evaluation of our monocular \VIO pipeline on real and simulated datasets. The results confirm that our modelling effort leads to accurate state estimation in real-time, outperforming state-of-the-art approaches.