 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-communicate no more: Situated RL agents learn concise communication protocols
Nov 02, 2022



While it is known that communication facilitates cooperation in multi-agent settings, it is unclear how to design artificial agents that can learn to effectively and efficiently communicate with each other. Much research on communication emergence uses reinforcement learning (RL) and explores unsituated communication in one-step referential tasks -- the tasks are not temporally interactive and lack time pressures typically present in natural communication. In these settings, agents may successfully learn to communicate, but they do not learn to exchange information concisely -- they tend towards over-communication and an inefficient encoding. Here, we explore situated communication in a multi-step task, where the acting agent has to forgo an environmental action to communicate. Thus, we impose an opportunity cost on communication and mimic the real-world pressure of passing time. We compare communication emergence under this pressure against learning to communicate with a cost on articulation effort, implemented as a per-message penalty (fixed and progressively increasing). We find that while all tested pressures can disincentivise over-communication, situated communication does it most effectively and, unlike the cost on effort, does not negatively impact emergence. Implementing an opportunity cost on communication in a temporally extended environment is a step towards embodiment, and might be a pre-condition for incentivising efficient, human-like communication.
Emergent Communication: Generalization and Overfitting in Lewis Games
Sep 30, 2022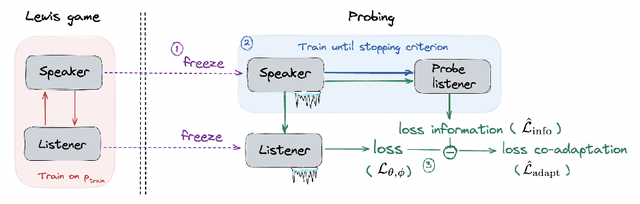

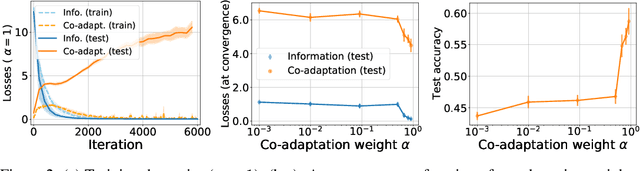

Lewis signaling games are a class of simple communication games for simulating the emergence of language. In these games, two agents must agree on a communication protocol in order to solve a cooperative task. Previous work has shown that agents trained to play this game with reinforcement learning tend to develop languages that display undesirable properties from a linguistic point of view (lack of generalization, lack of compositionality, etc). In this paper, we aim to provide better understanding of this phenomenon by analytically studying the learning problem in Lewis games. As a core contribution, we demonstrate that the standard objective in Lewis games can be decomposed in two components: a co-adaptation loss and an information loss. This decomposition enables us to surface two potential sources of overfitting, which we show may undermine the emergence of a structured communication protocol. In particular, when we control for overfitting on the co-adaptation loss, we recover desired properties in the emergent languages: they are more compositional and generalize better.
Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022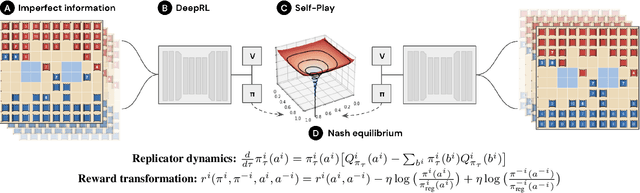
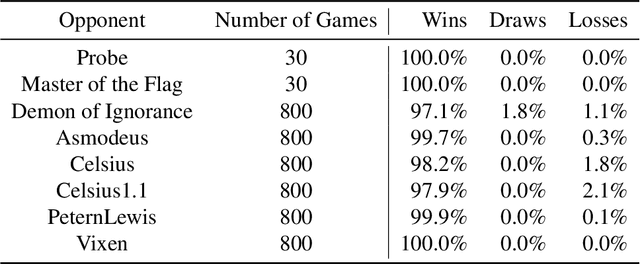
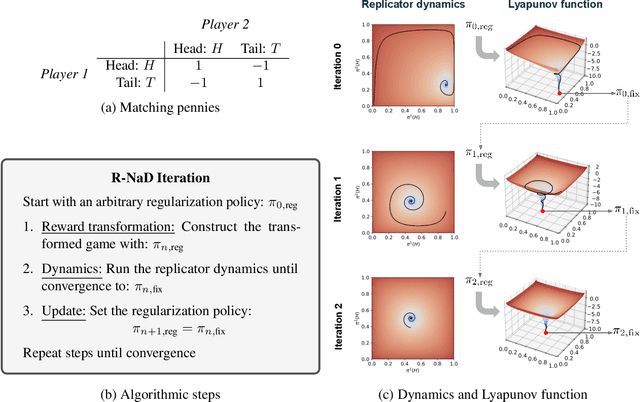

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Learning Natural Language Generation from Scratch
Sep 20, 2021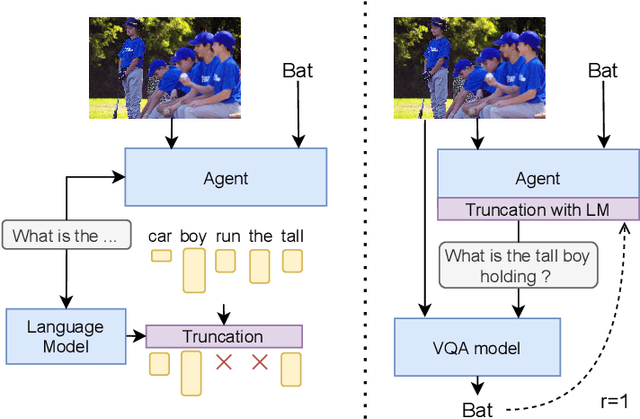
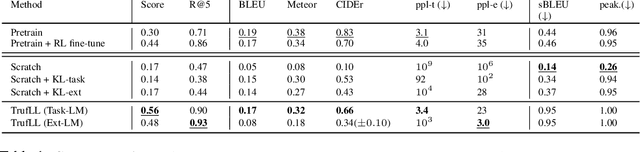

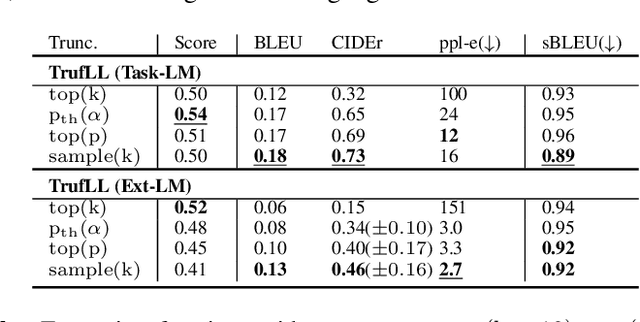
This paper introduces TRUncated ReinForcement Learning for Language (TrufLL), an original ap-proach to train conditional language models from scratch by only using reinforcement learning (RL). AsRL methods unsuccessfully scale to large action spaces, we dynamically truncate the vocabulary spaceusing a generic language model. TrufLL thus enables to train a language agent by solely interacting withits environment without any task-specific prior knowledge; it is only guided with a task-agnostic languagemodel. Interestingly, this approach avoids the dependency to labelled datasets and inherently reduces pre-trained policy flaws such as language or exposure biases. We evaluate TrufLL on two visual questiongeneration tasks, for which we report positive results over performance and language metrics, which wethen corroborate with a human evaluation. To our knowledge, it is the first approach that successfullylearns a language generation policy (almost) from scratch.
Don't Do What Doesn't Matter: Intrinsic Motivation with Action Usefulness
May 31, 2021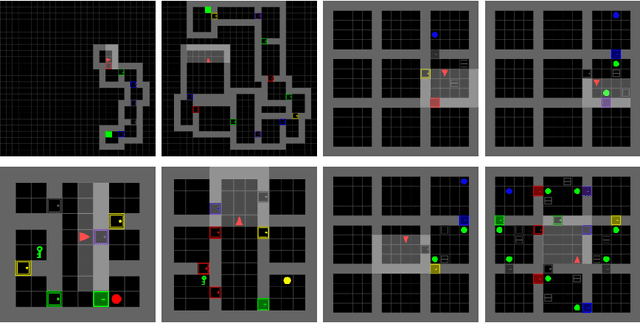
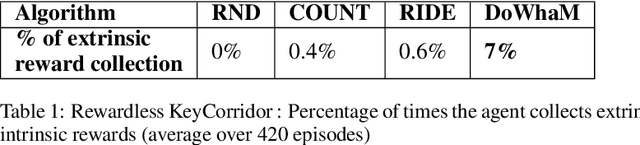
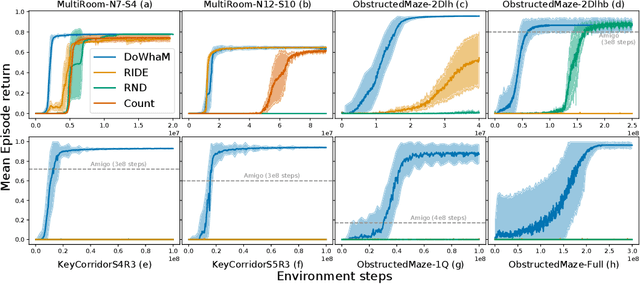
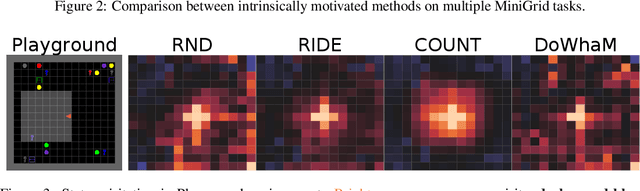
Sparse rewards are double-edged training signals in reinforcement learning: easy to design but hard to optimize. Intrinsic motivation guidances have thus been developed toward alleviating the resulting exploration problem. They usually incentivize agents to look for new states through novelty signals. Yet, such methods encourage exhaustive exploration of the state space rather than focusing on the environment's salient interaction opportunities. We propose a new exploration method, called Don't Do What Doesn't Matter (DoWhaM), shifting the emphasis from state novelty to state with relevant actions. While most actions consistently change the state when used, \textit{e.g.} moving the agent, some actions are only effective in specific states, \textit{e.g.}, \emph{opening} a door, \emph{grabbing} an object. DoWhaM detects and rewards actions that seldom affect the environment. We evaluate DoWhaM on the procedurally-generated environment MiniGrid, against state-of-the-art methods and show that DoWhaM greatly reduces sample complexity.
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021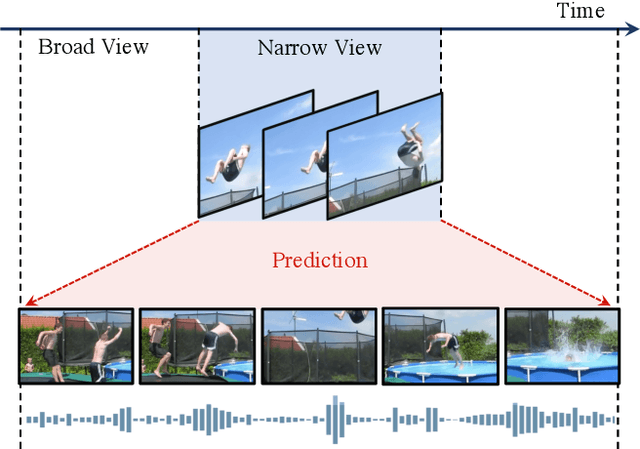
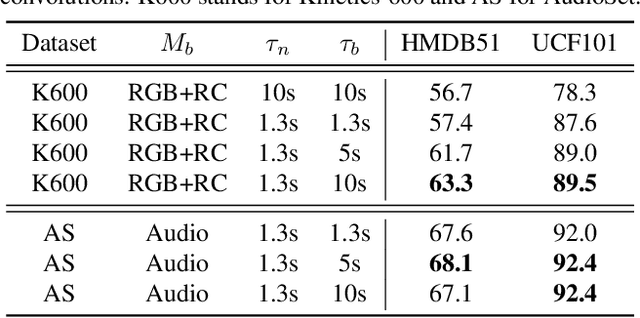
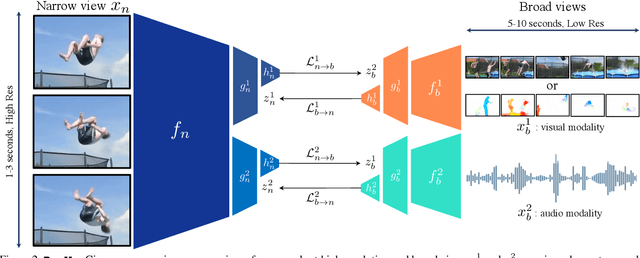
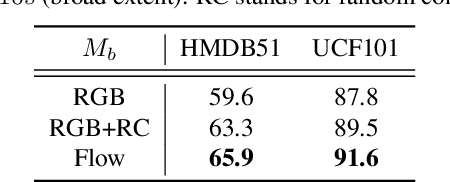
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
BYOL works even without batch statistics
Oct 20, 2020

Bootstrap Your Own Latent (BYOL) is a self-supervised learning approach for image representation. From an augmented view of an image, BYOL trains an online network to predict a target network representation of a different augmented view of the same image. Unlike contrastive methods, BYOL does not explicitly use a repulsion term built from negative pairs in its training objective. Yet, it avoids collapse to a trivial, constant representation. Thus, it has recently been hypothesized that batch normalization (BN) is critical to prevent collapse in BYOL. Indeed, BN flows gradients across batch elements, and could leak information about negative views in the batch, which could act as an implicit negative (contrastive) term. However, we experimentally show that replacing BN with a batch-independent normalization scheme (namely, a combination of group normalization and weight standardization) achieves performance comparable to vanilla BYOL ($73.9\%$ vs. $74.3\%$ top-1 accuracy under the linear evaluation protocol on ImageNet with ResNet-$50$). Our finding disproves the hypothesis that the use of batch statistics is a crucial ingredient for BYOL to learn useful representations.
Supervised Seeded Iterated Learning for Interactive Language Learning
Oct 06, 2020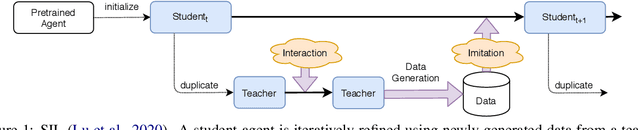
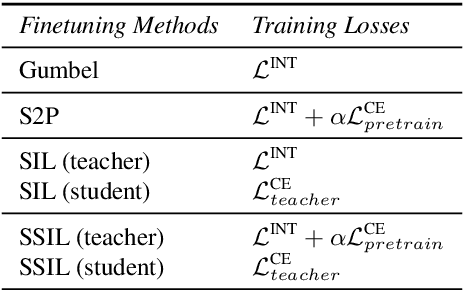
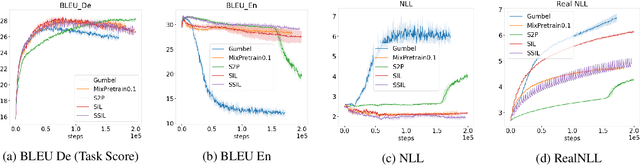
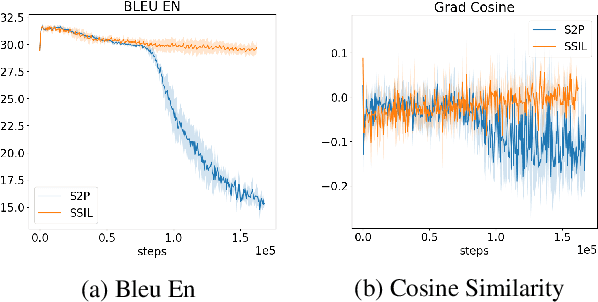
Language drift has been one of the major obstacles to train language models through interaction. When word-based conversational agents are trained towards completing a task, they tend to invent their language rather than leveraging natural language. In recent literature, two general methods partially counter this phenomenon: Supervised Selfplay (S2P) and Seeded Iterated Learning (SIL). While S2P jointly trains interactive and supervised losses to counter the drift, SIL changes the training dynamics to prevent language drift from occurring. In this paper, we first highlight their respective weaknesses, i.e., late-stage training collapses and higher negative likelihood when evaluated on human corpus. Given these observations, we introduce Supervised Seeded Iterated Learning to combine both methods to minimize their respective weaknesses. We then show the effectiveness of \algo in the language-drift translation game.
A Machine of Few Words -- Interactive Speaker Recognition with Reinforcement Learning
Aug 07, 2020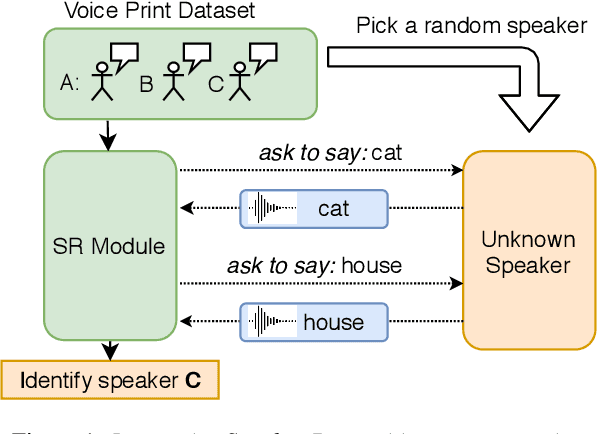
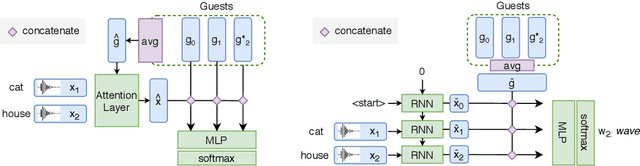
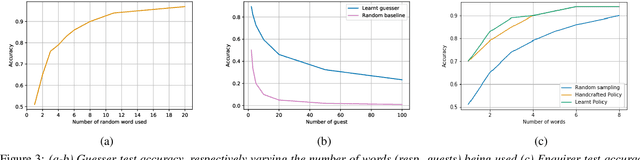
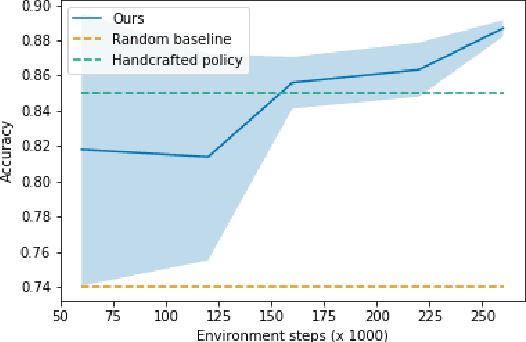
Speaker recognition is a well known and studied task in the speech processing domain. It has many applications, either for security or speaker adaptation of personal devices. In this paper, we present a new paradigm for automatic speaker recognition that we call Interactive Speaker Recognition (ISR). In this paradigm, the recognition system aims to incrementally build a representation of the speakers by requesting personalized utterances to be spoken in contrast to the standard text-dependent or text-independent schemes. To do so, we cast the speaker recognition task into a sequential decision-making problem that we solve with Reinforcement Learning. Using a standard dataset, we show that our method achieves excellent performance while using little speech signal amounts. This method could also be applied as an utterance selection mechanism for building speech synthesis systems.