 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware multi-view co-training for semi-supervised medical image segmentation and domain adaptation
Jun 28, 2020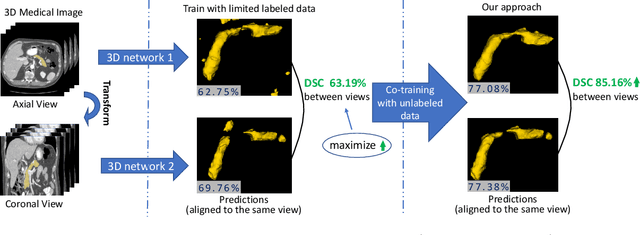
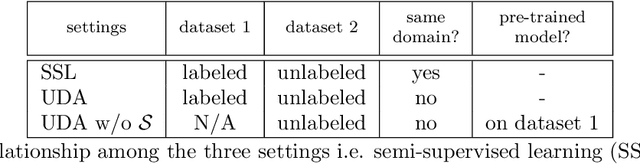
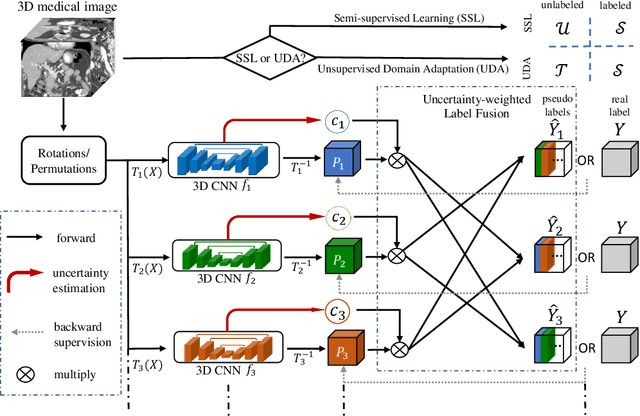
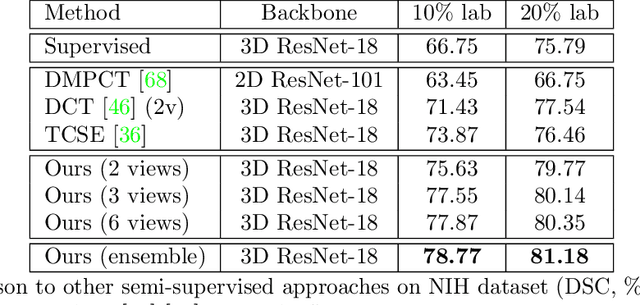
Although having achieved great success in medical image segmentation, deep learning-based approaches usually require large amounts of well-annotated data, which can be extremely expensive in the field of medical image analysis. Unlabeled data, on the other hand, is much easier to acquire. Semi-supervised learning and unsupervised domain adaptation both take the advantage of unlabeled data, and they are closely related to each other. In this paper, we propose uncertainty-aware multi-view co-training (UMCT), a unified framework that addresses these two tasks for volumetric medical image segmentation. Our framework is capable of efficiently utilizing unlabeled data for better performance. We firstly rotate and permute the 3D volumes into multiple views and train a 3D deep network on each view. We then apply co-training by enforcing multi-view consistency on unlabeled data, where an uncertainty estimation of each view is utilized to achieve accurate labeling. Experiments on the NIH pancreas segmentation dataset and a multi-organ segmentation dataset show state-of-the-art performance of the proposed framework on semi-supervised medical image segmentation. Under unsupervised domain adaptation settings, we validate the effectiveness of this work by adapting our multi-organ segmentation model to two pathological organs from the Medical Segmentation Decathlon Datasets. Additionally, we show that our UMCT-DA model can even effectively handle the challenging situation where labeled source data is inaccessible, demonstrating strong potentials for real-world applications.
* 19 pages, 6 figures, to appear in Medical Image Analysis. This article is an extension of the conference paper arXiv:1811.12506
JSSR: A Joint Synthesis, Segmentation, and Registration System for 3D Multi-Modal Image Alignment of Large-scale Pathological CT Scans
May 27, 2020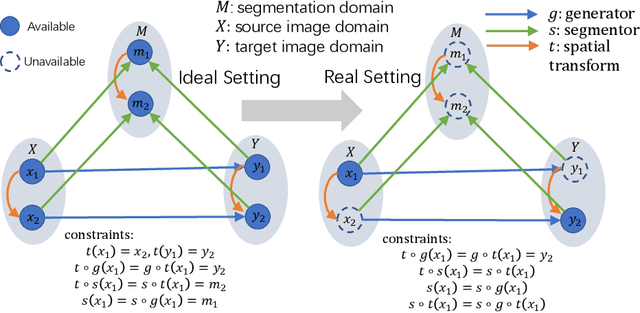
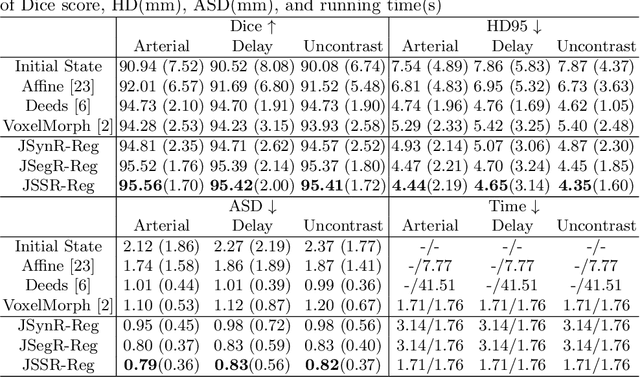
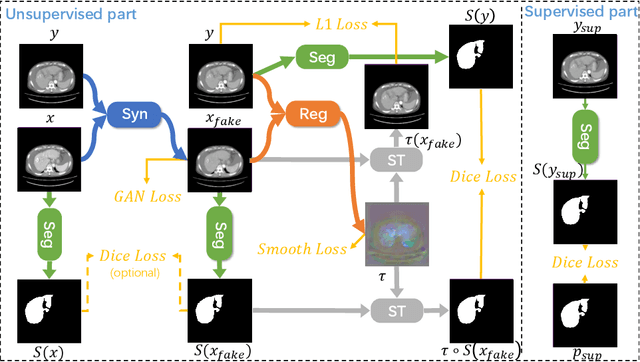
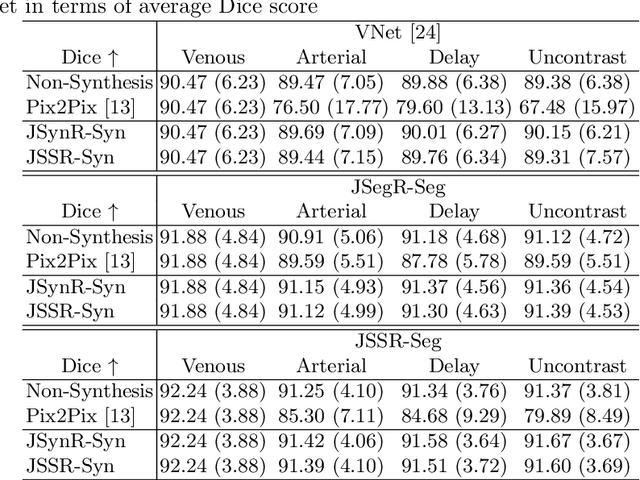
Multi-modal image registration is a challenging problem yet important clinical task in many real applications and scenarios. For medical imaging based diagnosis, deformable registration among different image modalities is often required in order to provide complementary visual information, as the first step. During the registration, the semantic information is the key to match homologous points and pixels. Nevertheless, many conventional registration methods are incapable to capture the high-level semantic anatomical dense correspondences. In this work, we propose a novel multi-task learning system, JSSR, based on an end-to-end 3D convolutional neural network that is composed of a generator, a register and a segmentor, for the tasks of synthesis, registration and segmentation, respectively. This system is optimized to satisfy the implicit constraints between different tasks unsupervisedly. It first synthesizes the source domain images into the target domain, then an intra-modal registration is applied on the synthesized images and target images. Then we can get the semantic segmentation by applying segmentors on the synthesized images and target images, which are aligned by the same deformation field generated by the registers. The supervision from another fully-annotated dataset is used to regularize the segmentors. We extensively evaluate our JSSR system on a large-scale medical image dataset containing 1,485 patient CT imaging studies of four different phases (i.e., 5,940 3D CT scans with pathological livers) on the registration, segmentation and synthesis tasks. The performance is improved after joint training on the registration and segmentation tasks by 0.9% and 1.9% respectively from a highly competitive and accurate baseline. The registration part also consistently outperforms the conventional state-of-the-art multi-modal registration methods.
Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation
Mar 18, 2020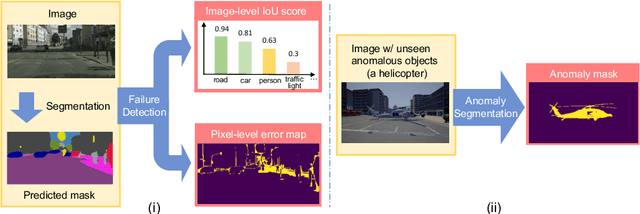
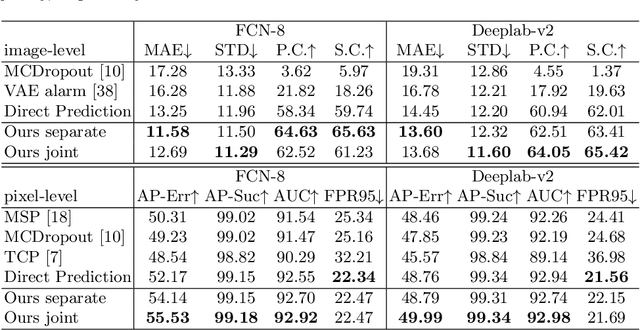
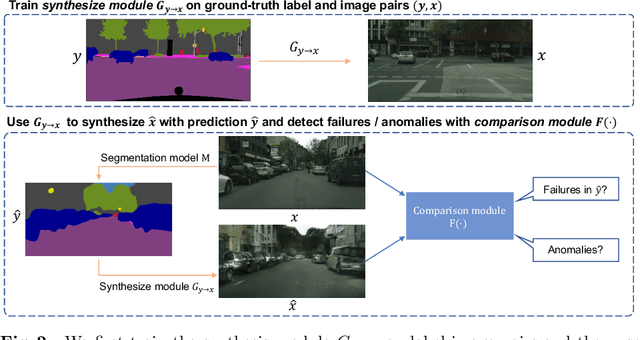
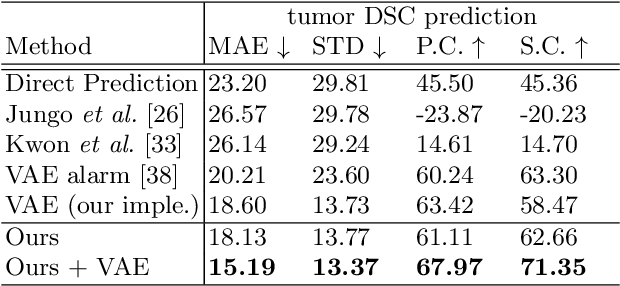
The ability to detect failures and anomalies are fundamental requirements for building reliable systems for computer vision applications, especially safety-critical applications of semantic segmentation, such as autonomous driving and medical image analysis. In this paper, we systematically study failure and anomaly detection for semantic segmentation and propose a unified framework, consisting of two modules, to address these two related problems. The first module is an image synthesis module, which generates a synthesized image from a segmentation layout map, and the second is a comparison module, which computes the difference between the synthesized image and the input image. We validate our framework on three challenging datasets and improve the state-of-the-arts by large margins, i.e., 6% AUPR-Error on Cityscapes, 10% DSC correlation on pancreatic tumor segmentation in MSD and 20% AUPR on StreetHazards anomaly segmentation.
Deep Distance Transform for Tubular Structure Segmentation in CT Scans
Dec 06, 2019
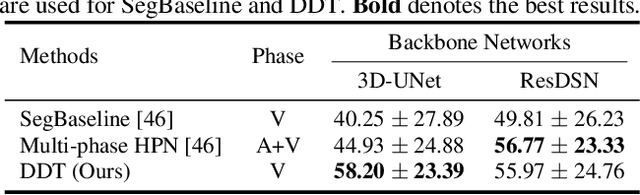
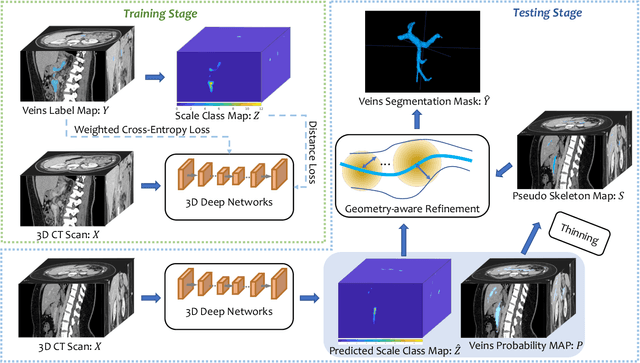
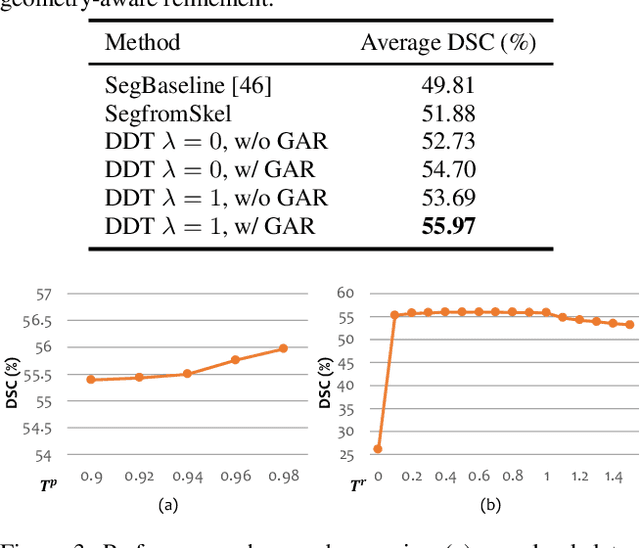
Tubular structure segmentation in medical images, e.g., segmenting vessels in CT scans, serves as a vital step in the use of computers to aid in screening early stages of related diseases. But automatic tubular structure segmentation in CT scans is a challenging problem, due to issues such as poor contrast, noise and complicated background. A tubular structure usually has a cylinder-like shape which can be well represented by its skeleton and cross-sectional radii (scales). Inspired by this, we propose a geometry-aware tubular structure segmentation method, Deep Distance Transform (DDT), which combines intuitions from the classical distance transform for skeletonization and modern deep segmentation networks. DDT first learns a multi-task network to predict a segmentation mask for a tubular structure and a distance map. Each value in the map represents the distance from each tubular structure voxel to the tubular structure surface. Then the segmentation mask is refined by leveraging the shape prior reconstructed from the distance map. We apply our DDT on six medical image datasets. The experiments show that (1) DDT can boost tubular structure segmentation performance significantly (e.g., over 13% improvement measured by DSC for pancreatic duct segmentation), and (2) DDT additionally provides a geometrical measurement for a tubular structure, which is important for clinical diagnosis (e.g., the cross-sectional scale of a pancreatic duct can be an indicator for pancreatic cancer).
FusionNet: Incorporating Shape and Texture for Abnormality Detection in 3D Abdominal CT Scans
Aug 27, 2019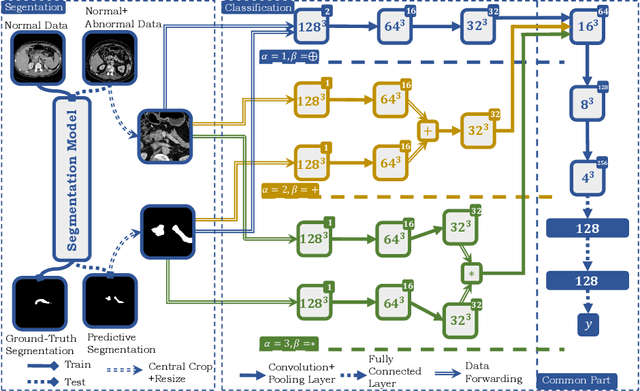
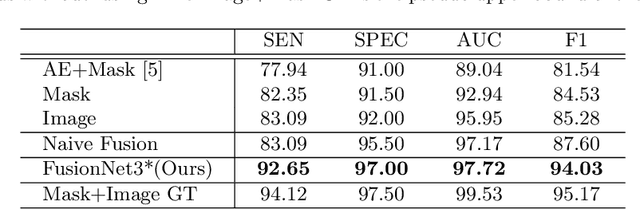
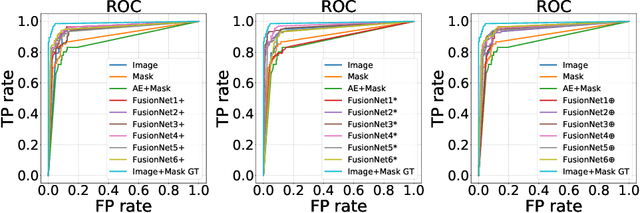
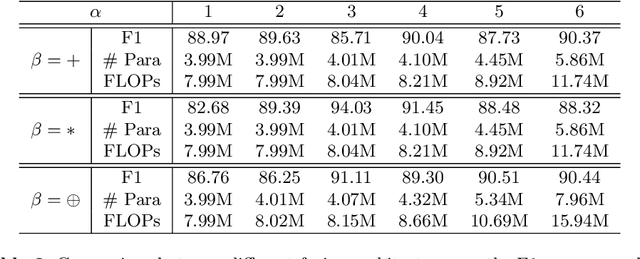
Automatic abnormality detection in abdominal CT scans can help doctors improve the accuracy and efficiency in diagnosis. In this paper we aim at detecting pancreatic ductal adenocarcinoma (PDAC), the most common pancreatic cancer. Taking the fact that the existence of tumor can affect both the shape and the texture of pancreas, we design a system to extract the shape and texture feature at the same time for detecting PDAC. In this paper we propose a two-stage method for this 3D classification task. First, we segment the pancreas into a binary mask. Second, a FusionNet is proposed to take both the binary mask and CT image as input and perform a binary classification. The optimal architecture of the FusionNet is obtained by searching a pre-defined functional space. We show that the classification results using either shape or texture information are complementary, and by fusing them with the optimized architecture, the performance improves by a large margin. Our method achieves a specificity of 97% and a sensitivity of 92% on 200 normal scans and 136 scans with PDAC.
An Alarm System For Segmentation Algorithm Based On Shape Model
Mar 27, 2019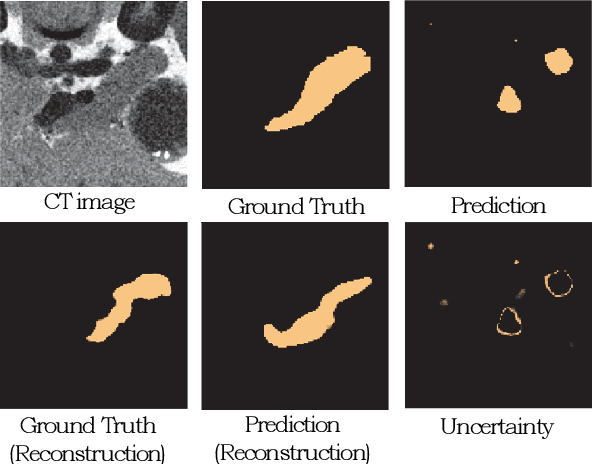
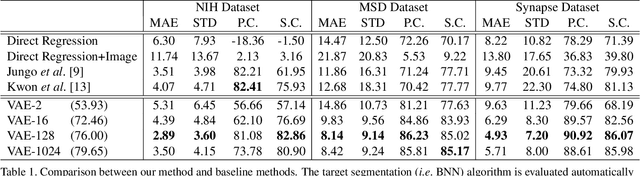
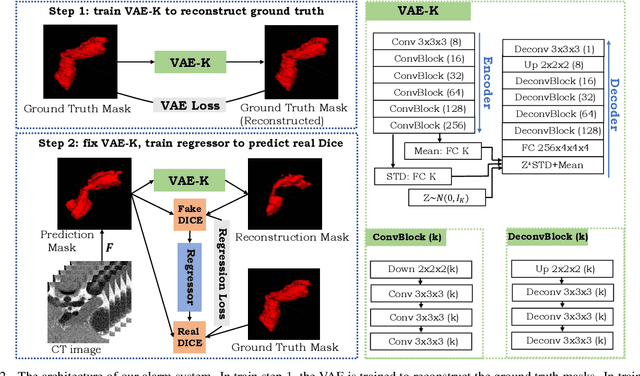
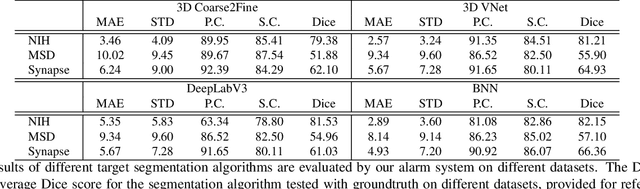
It is usually hard for a learning system to predict correctly on rare events that never occur in the training data, and there is no exception for segmentation algorithms. Meanwhile, manual inspection of each case to locate the failures becomes infeasible due to the trend of large data scale and limited human resource.Therefore, we build an alarm system that will set off alerts when the segmentation result is possibly unsatisfactory, assuming no corresponding ground truth mask is provided. One plausible solution is to project the segmentation results into a low dimensional feature space; then learn classifiers/regressors to predict their qualities. Motivated by this, in this paper, we learn a feature space using the shape information which is a strong prior shared among different datasets and robust to the appearance variation of input data.The shape feature is captured using a Variational Auto-Encoder (VAE) network that trained with only the ground truth masks. During testing, the segmentation results with bad shapes shall not fit the shape prior well, resulting in large loss values. Thus, the VAE is able to evaluate the quality of segmentation result on unseen data, without using ground truth. Finally, we learn a regressor in the one-dimensional feature space to predict the qualities of segmentation results. Our alarm system is evaluated on several recent state-of-art segmentation algorithms for 3D medical segmentation tasks. Compared with other standard quality assessment methods, our system consistently provides more reliable prediction on the qualities of segmentation results.
3D Semi-Supervised Learning with Uncertainty-Aware Multi-View Co-Training
Nov 29, 2018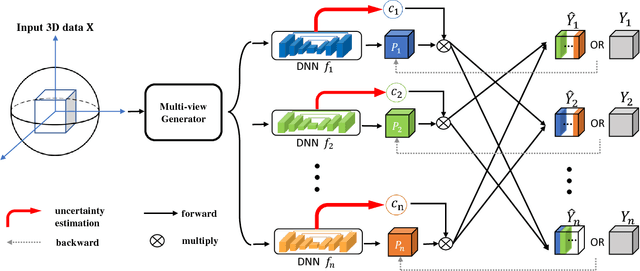
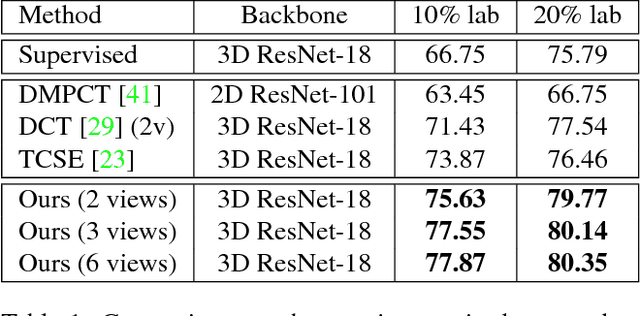
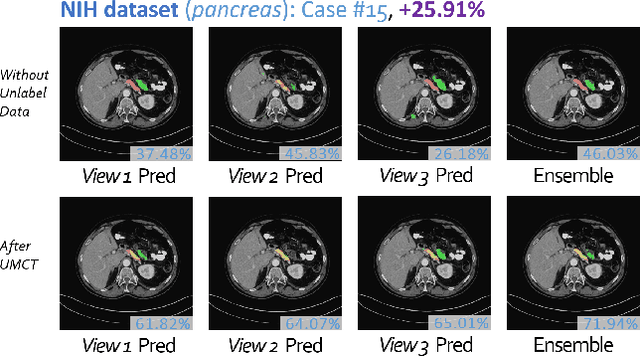
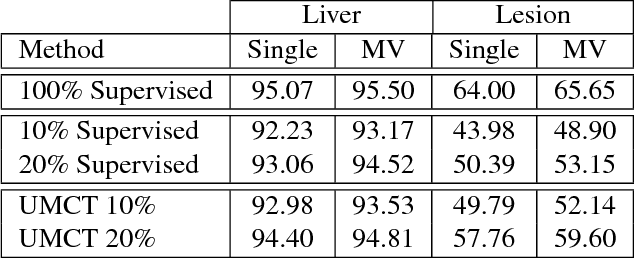
We propose a novel framework, uncertainty-aware multi-view co-training (UMCT), to address semi-supervised learning on 3D data, such as volumetric data in medical imaging. The original co-training method was applied to non-visual data. It requires different sources, or representations, of the data, which are called different views and differ from viewpoint in computer vision. Co-training was recently applied to visual tasks where the views were deep networks learnt by adversarial training. In our work, targeted at 3D data, co-training is achieved by exploiting multi-viewpoint consistency. We generate different views by rotating the 3D data and utilize asymmetrical 3D kernels to further encourage diversified features of each sub-net. In addition, we propose an uncertainty-aware attention mechanism to estimate the reliability of each view prediction with Bayesian deep learning. As one view requires the supervision from other views in co-training, our self-adaptive approach computes a confidence score for the prediction of each unlabeled sample, in order to assign a reliable pseudo label and thus achieve better performance. We show the effectiveness of our proposed method on several open datasets from medical image segmentation tasks (NIH pancreas & LiTS liver tumor dataset). A method based on our approach achieved the state-of-the-art performances on both the LiTS liver tumor segmentation and the Medical Segmentation Decathlon (MSD) challenge, demonstrating the robustness and value of our framework even when fully supervised training is feasible.
Bridging the Gap Between 2D and 3D Organ Segmentation with Volumetric Fusion Net
Jun 09, 2018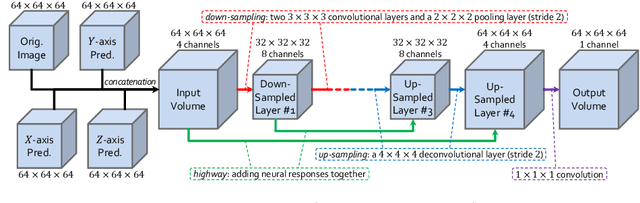
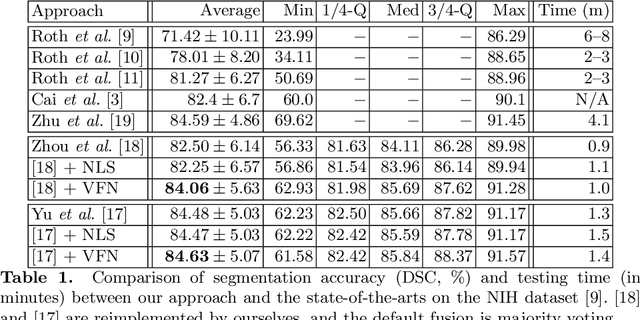

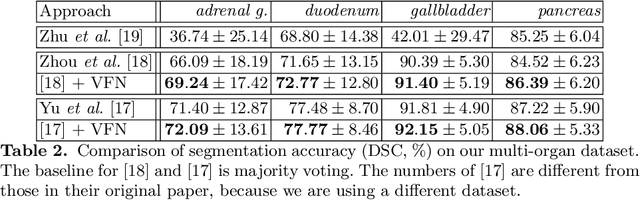
There has been a debate on whether to use 2D or 3D deep neural networks for volumetric organ segmentation. Both 2D and 3D models have their advantages and disadvantages. In this paper, we present an alternative framework, which trains 2D networks on different viewpoints for segmentation, and builds a 3D Volumetric Fusion Net (VFN) to fuse the 2D segmentation results. VFN is relatively shallow and contains much fewer parameters than most 3D networks, making our framework more efficient at integrating 3D information for segmentation. We train and test the segmentation and fusion modules individually, and propose a novel strategy, named cross-cross-augmentation, to make full use of the limited training data. We evaluate our framework on several challenging abdominal organs, and verify its superiority in segmentation accuracy and stability over existing 2D and 3D approaches.
Joint Shape Representation and Classification for Detecting PDAC
Apr 27, 2018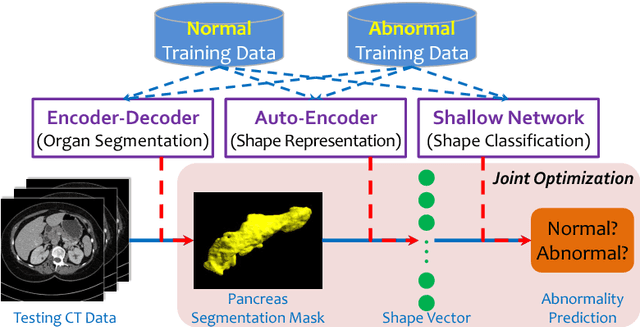
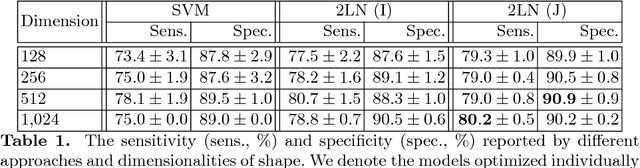
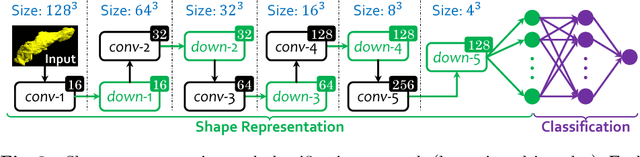
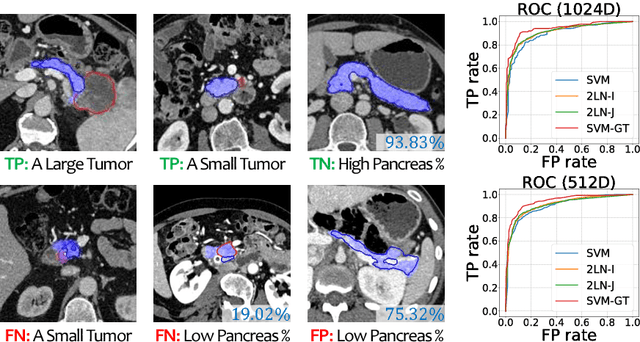
We aim to detect pancreatic ductal adenocarcinoma (PDAC) in abdominal CT scans, which sheds light on early diagnosis of pancreatic cancer. This is a 3D volume classification task with little training data. We propose a two-stage framework, which first segments the pancreas into a binary mask, then compresses the mask into a shape vector and performs abnormality classification. Shape representation and classification are performed in a {\em joint} manner, both to exploit the knowledge that PDAC often changes the {\bf shape} of the pancreas and to prevent over-fitting. Experiments are performed on $300$ normal scans and $156$ PDAC cases. We achieve a specificity of $90.2\%$ (false alarm occurs on less than $1/10$ normal cases) at a sensitivity of $80.2\%$ (less than $1/5$ PDAC cases are not detected), which show promise for clinical applications.