 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLUE: New Benchmark Tasks for Spoken Language Understanding Evaluation on Natural Speech
Nov 19, 2021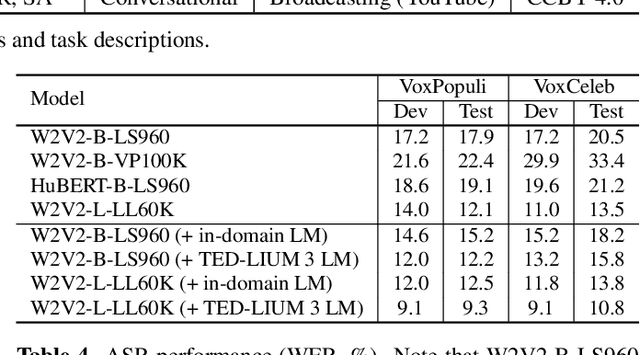
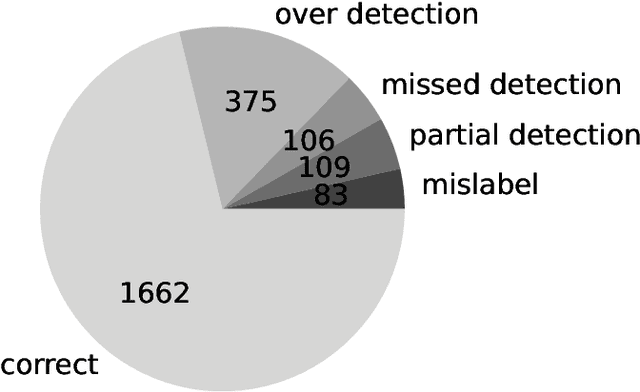
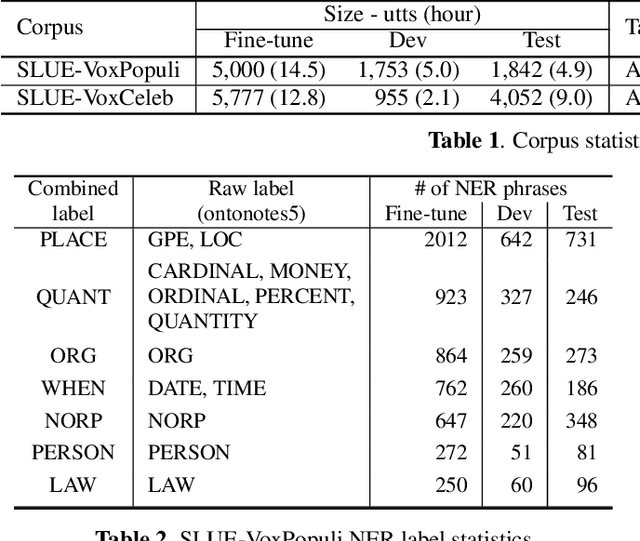
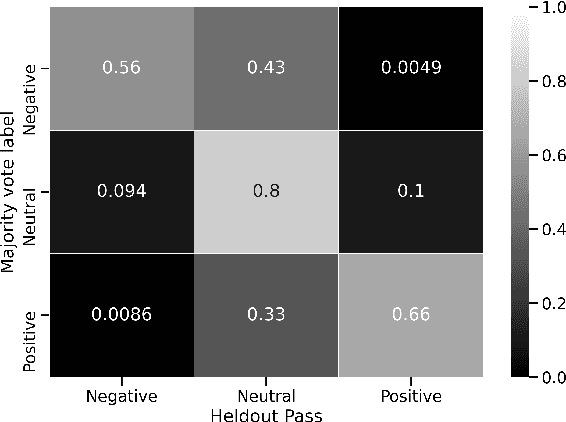
Progress in speech processing has been facilitated by shared datasets and benchmarks. Historically these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. Interest has been growing in higher-level spoken language understanding tasks, including using end-to-end models, but there are fewer annotated datasets for such tasks. At the same time, recent work shows the possibility of pre-training generic representations and then fine-tuning for several tasks using relatively little labeled data. We propose to create a suite of benchmark tasks for Spoken Language Understanding Evaluation (SLUE) consisting of limited-size labeled training sets and corresponding evaluation sets. This resource would allow the research community to track progress, evaluate pre-trained representations for higher-level tasks, and study open questions such as the utility of pipeline versus end-to-end approaches. We present the first phase of the SLUE benchmark suite, consisting of named entity recognition, sentiment analysis, and ASR on the corresponding datasets. We focus on naturally produced (not read or synthesized) speech, and freely available datasets. We provide new transcriptions and annotations on subsets of the VoxCeleb and VoxPopuli datasets, evaluation metrics and results for baseline models, and an open-source toolkit to reproduce the baselines and evaluate new models.
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
Sep 14, 2021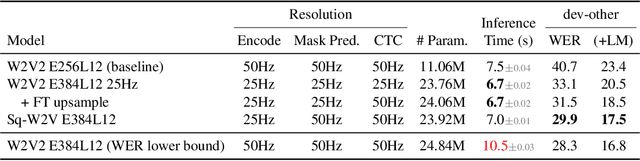
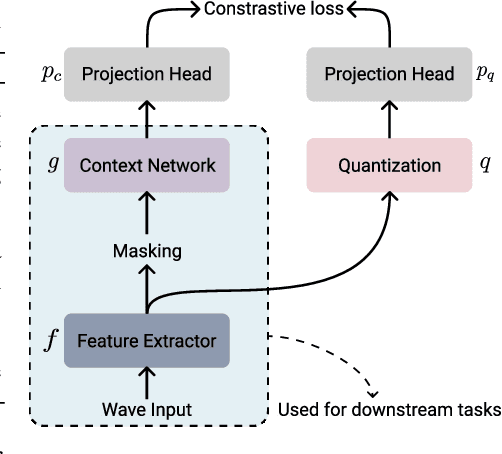
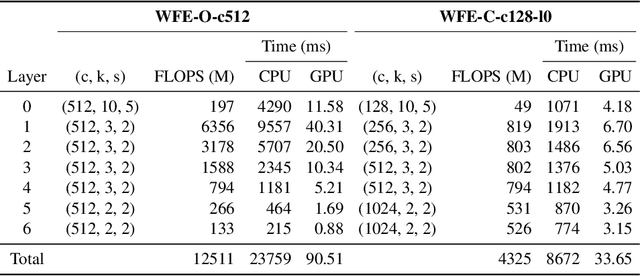
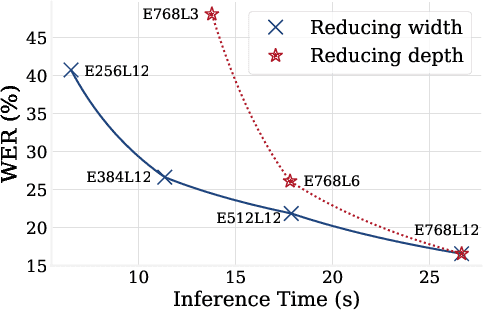
This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition (ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference time, SEW reduces word error rate by 25-50% across different model sizes.
Multi-mode Transformer Transducer with Stochastic Future Context
Jun 17, 2021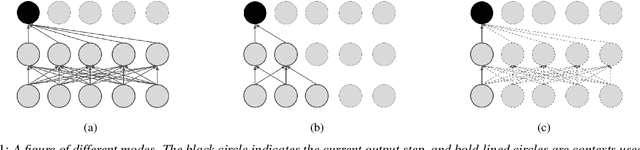
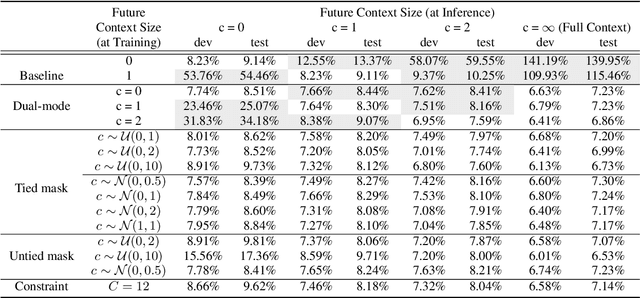
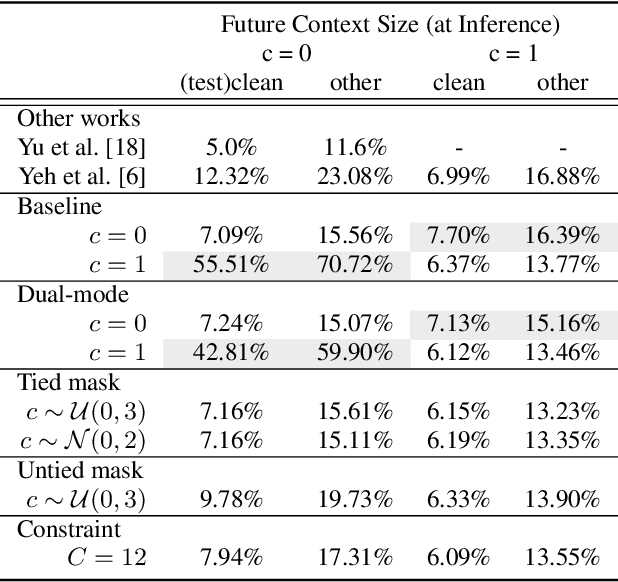
Automatic speech recognition (ASR) models make fewer errors when more surrounding speech information is presented as context. Unfortunately, acquiring a larger future context leads to higher latency. There exists an inevitable trade-off between speed and accuracy. Naively, to fit different latency requirements, people have to store multiple models and pick the best one under the constraints. Instead, a more desirable approach is to have a single model that can dynamically adjust its latency based on different constraints, which we refer to as Multi-mode ASR. A Multi-mode ASR model can fulfill various latency requirements during inference -- when a larger latency becomes acceptable, the model can process longer future context to achieve higher accuracy and when a latency budget is not flexible, the model can be less dependent on future context but still achieve reliable accuracy. In pursuit of Multi-mode ASR, we propose Stochastic Future Context, a simple training procedure that samples one streaming configuration in each iteration. Through extensive experiments on AISHELL-1 and LibriSpeech datasets, we show that a Multi-mode ASR model rivals, if not surpasses, a set of competitive streaming baselines trained with different latency budgets.
Making Paper Reviewing Robust to Bid Manipulation Attacks
Feb 22, 2021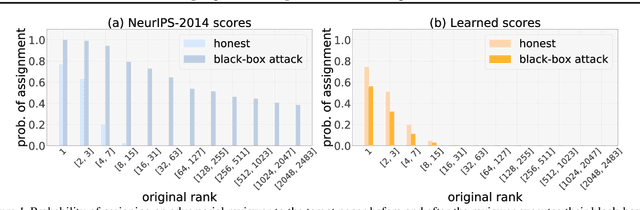
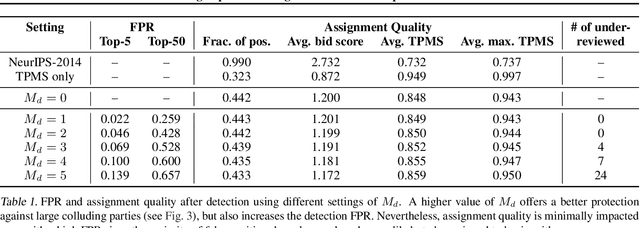
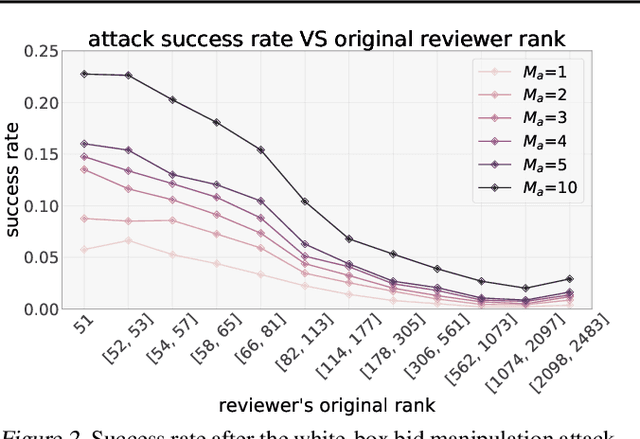
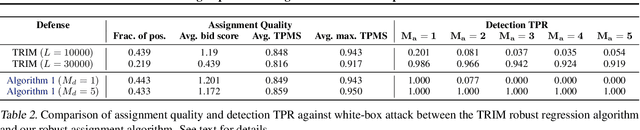
Most computer science conferences rely on paper bidding to assign reviewers to papers. Although paper bidding enables high-quality assignments in days of unprecedented submission numbers, it also opens the door for dishonest reviewers to adversarially influence paper reviewing assignments. Anecdotal evidence suggests that some reviewers bid on papers by "friends" or colluding authors, even though these papers are outside their area of expertise, and recommend them for acceptance without considering the merit of the work. In this paper, we study the efficacy of such bid manipulation attacks and find that, indeed, they can jeopardize the integrity of the review process. We develop a novel approach for paper bidding and assignment that is much more robust against such attacks. We show empirically that our approach provides robustness even when dishonest reviewers collude, have full knowledge of the assignment system's internal workings, and have access to the system's inputs. In addition to being more robust, the quality of our paper review assignments is comparable to that of current, non-robust assignment approaches.
Revisiting Few-sample BERT Fine-tuning
Jul 02, 2020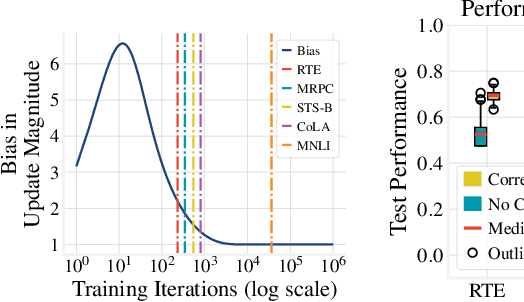
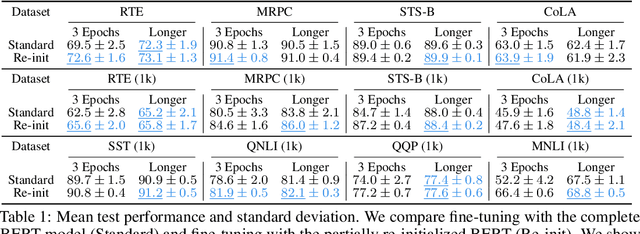

We study the problem of few-sample fine-tuning of BERT contextual representations, and identify three sub-optimal choices in current, broadly adopted practices. First, we observe that the omission of the gradient bias correction in the BERTAdam optimizer results in fine-tuning instability. We also find that parts of the BERT network provide a detrimental starting point for fine-tuning, and simply re-initializing these layers speeds up learning and improves performance. Finally, we study the effect of training time, and observe that commonly used recipes often do not allocate sufficient time for training. In light of these findings, we re-visit recently proposed methods to improve few-sample fine-tuning with BERT and re-evaluate their effectiveness. Generally, we observe a decrease in their relative impact when modifying the fine-tuning process based on our findings.
Attention-based Quantum Tomography
Jun 22, 2020
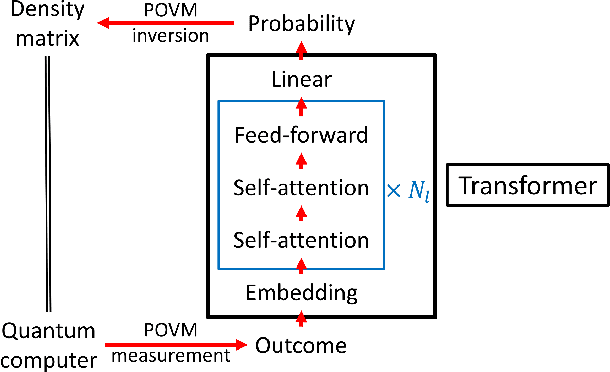
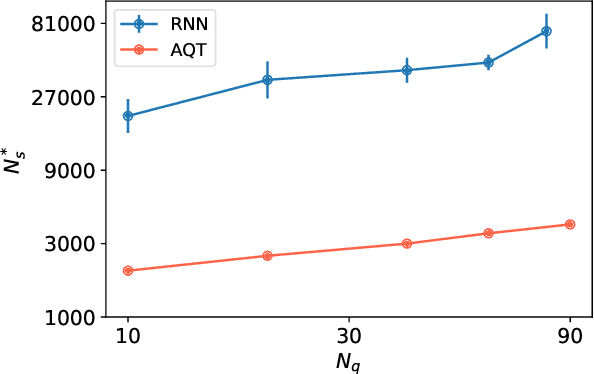
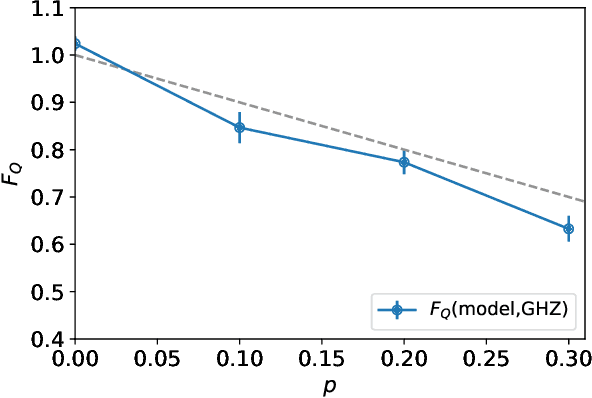
With rapid progress across platforms for quantum systems, the problem of many-body quantum state reconstruction for noisy quantum states becomes an important challenge. Recent works found promise in recasting the problem of quantum state reconstruction to learning the probability distribution of quantum state measurement vectors using generative neural network models. Here we propose the "Attention-based Quantum Tomography" (AQT), a quantum state reconstruction using an attention mechanism-based generative network that learns the mixed state density matrix of a noisy quantum state. The AQT is based on the model proposed in "Attention is all you need" by Vishwani et al (2017) that is designed to learn long-range correlations in natural language sentences and thereby outperform previous natural language processing models. We demonstrate not only that AQT outperforms earlier neural-network-based quantum state reconstruction on identical tasks but that AQT can accurately reconstruct the density matrix associated with a noisy quantum state experimentally realized in an IBMQ quantum computer. We speculate the success of the AQT stems from its ability to model quantum entanglement across the entire quantum system much as the attention model for natural language processing captures the correlations among words in a sentence.
On Feature Normalization and Data Augmentation
Mar 06, 2020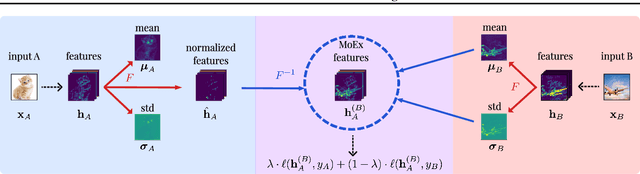
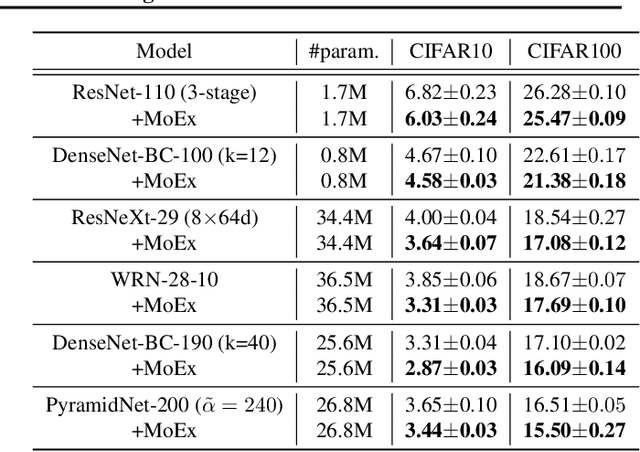
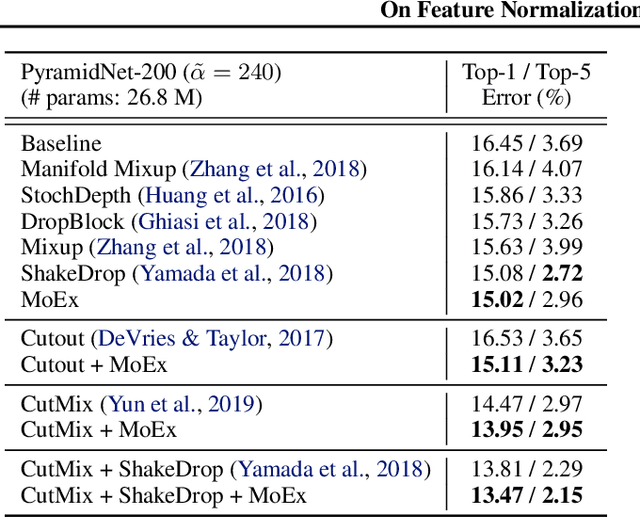
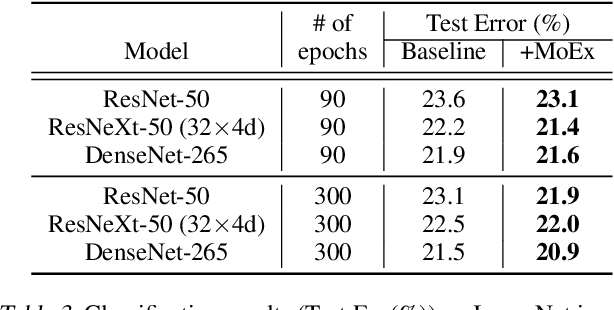
Modern neural network training relies heavily on data augmentation for improved generalization. After the initial success of label-preserving augmentations, there has been a recent surge of interest in label-perturbing approaches, which combine features and labels across training samples to smooth the learned decision surface. In this paper, we propose a new augmentation method that leverages the first and second moments extracted and re-injected by feature normalization. We replace the moments of the learned features of one training image by those of another, and also interpolate the target labels. As our approach is fast, operates entirely in feature space, and mixes different signals than prior methods, one can effectively combine it with existing augmentation methods. We demonstrate its efficacy across benchmark data sets in computer vision, speech, and natural language processing, where it consistently improves the generalization performance of highly competitive baseline networks.
Integrated Triaging for Fast Reading Comprehension
Sep 28, 2019
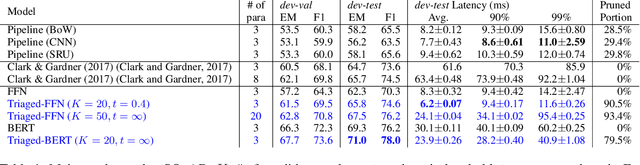
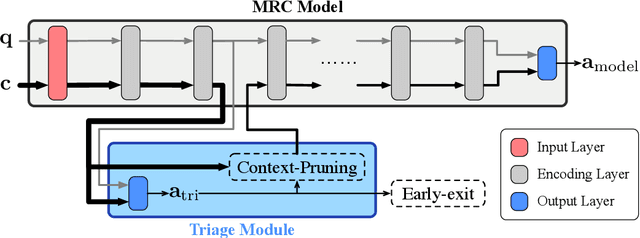
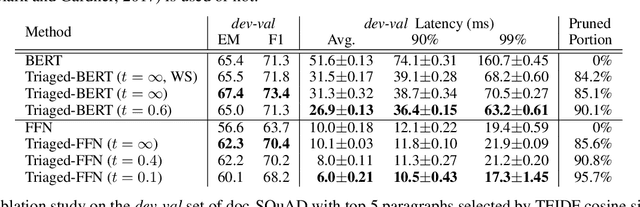
Although according to several benchmarks automatic machine reading comprehension (MRC) systems have recently reached super-human performance, less attention has been paid to their computational efficiency. However, efficiency is of crucial importance for training and deployment in real world applications. This paper introduces Integrated Triaging, a framework that prunes almost all context in early layers of a network, leaving the remaining (deep) layers to scan only a tiny fraction of the full corpus. This pruning drastically increases the efficiency of MRC models and further prevents the later layers from overfitting to prevalent short paragraphs in the training set. Our framework is extremely flexible and naturally applicable to a wide variety of models. Our experiment on doc-SQuAD and TriviaQA tasks demonstrates its effectiveness in consistently improving both speed and quality of several diverse MRC models.
Positional Normalization
Jul 09, 2019
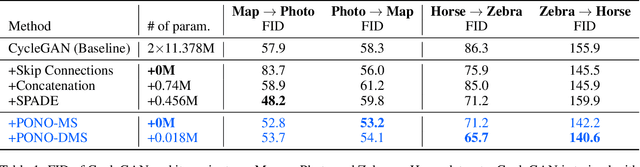


A widely deployed method for reducing the training time of deep neural networks is to normalize activations at each layer. Although various normalization schemes have been proposed, they all follow a common theme: normalize across spatial dimensions and discard the extracted statistics. In this paper, we propose a novel normalization method that noticeably departs from this convention. Our approach, which we refer to as Positional Normalization (PONO), normalizes exclusively across channels --- a naturally appealing dimension, which captures the first and second moments of features extracted at a particular image position. We argue that these moments convey structural information about the input image and the extracted features, which opens a new avenue along which a network can benefit from feature normalization: Instead of disregarding the PONO normalization constants, we propose to re-inject them into later layers to preserve or transfer structural information in generative networks.
BERTScore: Evaluating Text Generation with BERT
Apr 21, 2019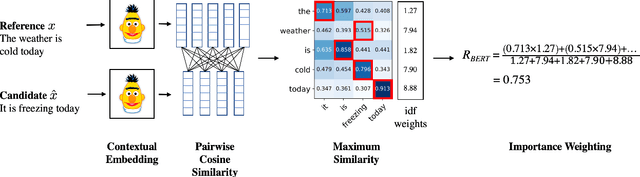
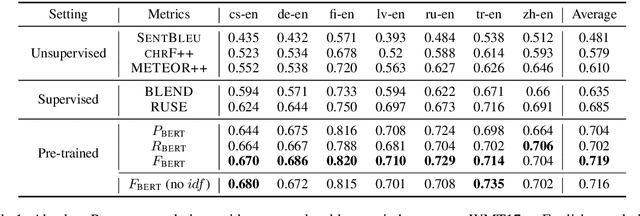
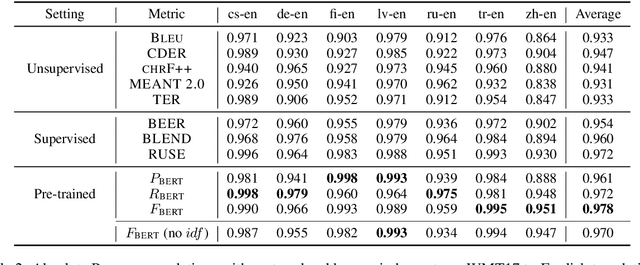
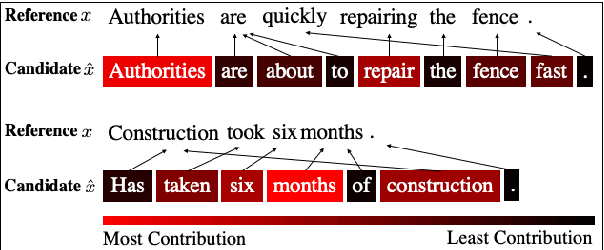
We propose BERTScore, an automatic evaluation metric for text generation. Analogous to common metrics, \method computes a similarity score for each token in the candidate sentence with each token in the reference. However, instead of looking for exact matches, we compute similarity using contextualized BERT embeddings. We evaluate on several machine translation and image captioning benchmarks, and show that BERTScore correlates better with human judgments than existing metrics, often significantly outperforming even task-specific supervised metrics.