 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterministic Hallucination Detection in Medical VQA via Confidence-Evidence Bayesian Gain
Mar 23, 2026Multimodal large language models (MLLMs) have shown strong potential for medical Visual Question Answering (VQA), yet they remain prone to hallucinations, defined as generating responses that contradict the input image, posing serious risks in clinical settings. Current hallucination detection methods, such as Semantic Entropy (SE) and Vision-Amplified Semantic Entropy (VASE), require 10 to 20 stochastic generations per sample together with an external natural language inference model for semantic clustering, making them computationally expensive and difficult to deploy in practice. We observe that hallucinated responses exhibit a distinctive signature directly in the model's own log-probabilities: inconsistent token-level confidence and weak sensitivity to visual evidence. Based on this observation, we propose Confidence-Evidence Bayesian Gain (CEBaG), a deterministic hallucination detection method that requires no stochastic sampling, no external models, and no task-specific hyperparameters. CEBaG combines two complementary signals: token-level predictive variance, which captures inconsistent confidence across response tokens, and evidence magnitude, which measures how much the image shifts per-token predictions relative to text-only inference. Evaluated across four medical MLLMs and three VQA benchmarks (16 experimental settings), CEBaG achieves the highest AUC in 13 of 16 settings and improves over VASE by 8 AUC points on average, while being fully deterministic and self-contained. The code will be made available upon acceptance.
Mirage The Illusion of Visual Understanding
Mar 23, 2026Multimodal AI systems have achieved remarkable performance across a broad range of real-world tasks, yet the mechanisms underlying visual-language reasoning remain surprisingly poorly understood. We report three findings that challenge prevailing assumptions about how these systems process and integrate visual information. First, Frontier models readily generate detailed image descriptions and elaborate reasoning traces, including pathology-biased clinical findings, for images never provided; we term this phenomenon mirage reasoning. Second, without any image input, models also attain strikingly high scores across general and medical multimodal benchmarks, bringing into question their utility and design. In the most extreme case, our model achieved the top rank on a standard chest X-ray question-answering benchmark without access to any images. Third, when models were explicitly instructed to guess answers without image access, rather than being implicitly prompted to assume images were present, performance declined markedly. Explicit guessing appears to engage a more conservative response regime, in contrast to the mirage regime in which models behave as though images have been provided. These findings expose fundamental vulnerabilities in how visual-language models reason and are evaluated, pointing to an urgent need for private benchmarks that eliminate textual cues enabling non-visual inference, particularly in medical contexts where miscalibrated AI carries the greatest consequence. We introduce B-Clean as a principled solution for fair, vision-grounded evaluation of multimodal AI systems.
A Generalizable Deep Learning System for Cardiac MRI
Dec 01, 2023



Cardiac MRI allows for a comprehensive assessment of myocardial structure, function, and tissue characteristics. Here we describe a foundational vision system for cardiac MRI, capable of representing the breadth of human cardiovascular disease and health. Our deep learning model is trained via self-supervised contrastive learning, by which visual concepts in cine-sequence cardiac MRI scans are learned from the raw text of the accompanying radiology reports. We train and evaluate our model on data from four large academic clinical institutions in the United States. We additionally showcase the performance of our models on the UK BioBank, and two additional publicly available external datasets. We explore emergent zero-shot capabilities of our system, and demonstrate remarkable performance across a range of tasks; including the problem of left ventricular ejection fraction regression, and the diagnosis of 35 different conditions such as cardiac amyloidosis and hypertrophic cardiomyopathy. We show that our deep learning system is capable of not only understanding the staggering complexity of human cardiovascular disease, but can be directed towards clinical problems of interest yielding impressive, clinical grade diagnostic accuracy with a fraction of the training data typically required for such tasks.
DeepBeat: A multi-task deep learning approach to assess signal quality and arrhythmia detection in wearable devices
Jan 25, 2020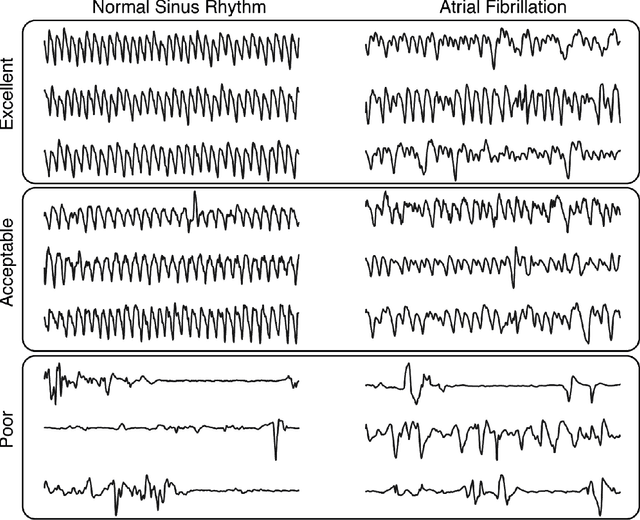
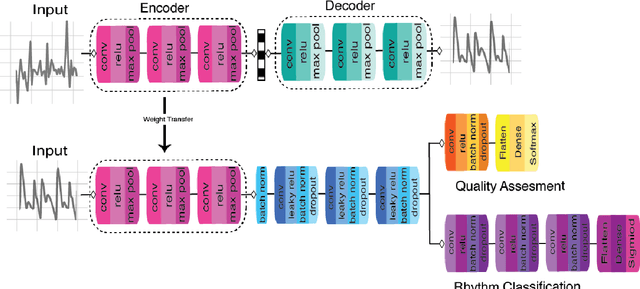
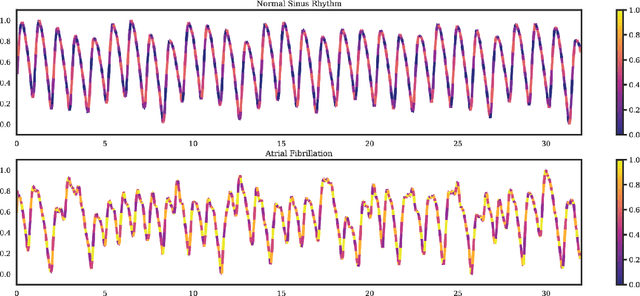
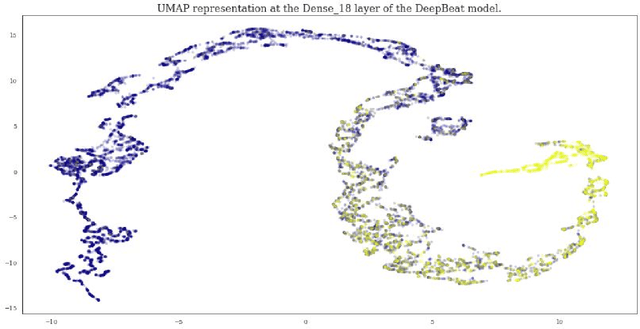
Wearable devices enable theoretically continuous, longitudinal monitoring of physiological measurements like step count, energy expenditure, and heart rate. Although the classification of abnormal cardiac rhythms such as atrial fibrillation from wearable devices has great potential, commercial algorithms remain proprietary and tend to focus on heart rate variability derived from green spectrum LED sensors placed on the wrist where noise remains an unsolved problem. Here, we develop a multi-task deep learning method to assess signal quality and arrhythmia event detection in wearable photoplethysmography devices for real-time detection of atrial fibrillation (AF). We train our algorithm on over one million simulated unlabeled physiological signals and fine-tune on a curated dataset of over 500K labeled signals from over 100 individuals from 3 different wearable devices. We demonstrate that in comparison with a traditional random forest-based approach (precision:0.24, recall:0.58, f1:0.34, auPRC:0.44) and a single task CNN (precision:0.59, recall:0.69, f1:0.64, auPRC:0.68) our architecture using unsupervised transfer learning through convolutional denoising autoencoders dramatically improves the performance of AF detection in participants at rest (pr:0.94, rc:0.98, f1:0.96, auPRC:0.96). In addition, we validate algorithm performance on a prospectively derived replication cohort of ambulatory subjects using data derived from an independently engineered device. We show that two-stage training can help address the unbalanced data problem common to biomedical applications where large well-annotated datasets are scarce. In conclusion, though a combination of simulation and transfer learning and we develop and apply a multitask architecture to the problem of AF detection from wearable wrist sensors demonstrating high levels of accuracy and a solution for the vexing challenge of mechanical noise.