 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Extreme Learning Machine (PIELM) for Tunnelling-Induced Soil-Pile Interactions
Oct 01, 2025Physics-informed machine learning has been a promising data-driven and physics-informed approach in geotechnical engineering. This study proposes a physics-informed extreme learning machine (PIELM) framework for analyzing tunneling-induced soil-pile interactions. The pile foundation is modeled as an Euler-Bernoulli beam, and the surrounding soil is modeled as a Pasternak foundation. The soil-pile interaction is formulated into a fourth-order ordinary differential equation (ODE) that constitutes the physics-informed component, while measured data are incorporated into PIELM as the data-driven component. Combining physics and data yields a loss vector of the extreme learning machine (ELM) network, which is trained within 1 second by the least squares method. After validating the PIELM approach by the boundary element method (BEM) and finite difference method (FDM), parametric studies are carried out to examine the effects of ELM network architecture, data monitoring locations and numbers on the performance of PIELM. The results indicate that monitored data should be placed at positions where the gradients of pile deflections are significant, such as at the pile tip/top and near tunneling zones. Two application examples highlight the critical role of physics-informed and data-driven approach for tunnelling-induced soil-pile interactions. The proposed approach shows great potential for real-time monitoring and safety assessment of pile foundations, and benefits for intelligent early-warning systems in geotechnical engineering.
TS-PIELM: Time-Stepping Physics-Informed Extreme Learning Machine Facilitates Soil Consolidation Analyses
Jun 11, 2025Accuracy and efficiency of the conventional physics-informed neural network (PINN) need to be improved before it can be a competitive alternative for soil consolidation analyses. This paper aims to overcome these limitations by proposing a highly accurate and efficient physics-informed machine learning (PIML) approach, termed time-stepping physics-informed extreme learning machine (TS-PIELM). In the TS-PIELM framework the consolidation process is divided into numerous time intervals, which helps overcome the limitation of PIELM in solving differential equations with sharp gradients. To accelerate network training, the solution is approximated by a single-layer feedforward extreme learning machine (ELM), rather than using a fully connected neural network in PINN. The input layer weights of the ELM network are generated randomly and fixed during the training process. Subsequently, the output layer weights are directly computed by solving a system of linear equations, which significantly enhances the training efficiency compared to the time-consuming gradient descent method in PINN. Finally, the superior performance of TS-PIELM is demonstrated by solving three typical Terzaghi consolidation problems. Compared to PINN, results show that the computational efficiency and accuracy of the novel TS-PIELM framework are improved by more than 1000 times and 100 times for one-dimensional cases, respectively. This paper provides compelling evidence that PIML can be a powerful tool for computational geotechnics.
IoT-Based 3D Pose Estimation and Motion Optimization for Athletes: Application of C3D and OpenPose
Nov 19, 2024This study proposes the IoT-Enhanced Pose Optimization Network (IE-PONet) for high-precision 3D pose estimation and motion optimization of track and field athletes. IE-PONet integrates C3D for spatiotemporal feature extraction, OpenPose for real-time keypoint detection, and Bayesian optimization for hyperparameter tuning. Experimental results on NTURGB+D and FineGYM datasets demonstrate superior performance, with AP\(^p50\) scores of 90.5 and 91.0, and mAP scores of 74.3 and 74.0, respectively. Ablation studies confirm the essential roles of each module in enhancing model accuracy. IE-PONet provides a robust tool for athletic performance analysis and optimization, offering precise technical insights for training and injury prevention. Future work will focus on further model optimization, multimodal data integration, and developing real-time feedback mechanisms to enhance practical applications.
DELIA: Diversity-Enhanced Learning for Instruction Adaptation in Large Language Models
Aug 19, 2024



Although instruction tuning is widely used to adjust behavior in Large Language Models (LLMs), extensive empirical evidence and research indicates that it is primarily a process where the model fits to specific task formats, rather than acquiring new knowledge or capabilities. We propose that this limitation stems from biased features learned during instruction tuning, which differ from ideal task-specfic features, leading to learn less underlying semantics in downstream tasks. However, ideal features are unknown and incalculable, constraining past work to rely on prior knowledge to assist reasoning or training, which limits LLMs' capabilities to the developers' abilities, rather than data-driven scalable learning. In our paper, through our novel data synthesis method, DELIA (Diversity-Enhanced Learning for Instruction Adaptation), we leverage the buffering effect of extensive diverse data in LLMs training to transform biased features in instruction tuning into approximations of ideal features, without explicit prior ideal features. Experiments show DELIA's better performance compared to common instruction tuning and other baselines. It outperforms common instruction tuning by 17.07%-33.41% on Icelandic-English translation bleurt score (WMT-21 dataset, gemma-7b-it) and improves accuracy by 36.1% on formatted text generation (Llama2-7b-chat). Notably, among knowledge injection methods we've known, DELIA uniquely align the internal representations of new special tokens with their prior semantics.
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
Nov 05, 2018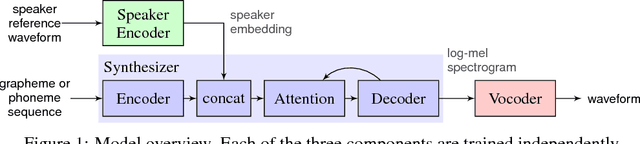

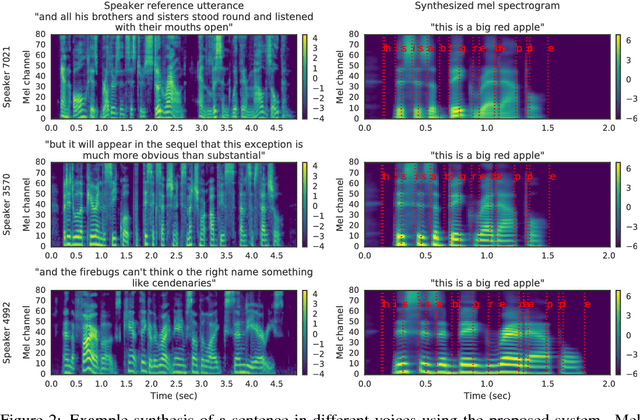
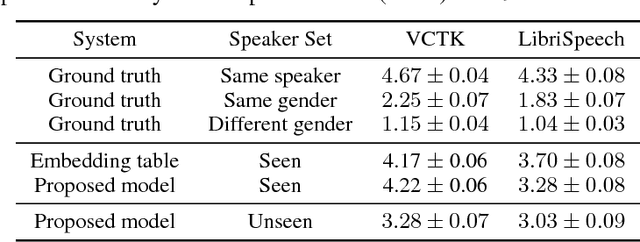
We describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of many different speakers, including those unseen during training. Our system consists of three independently trained components: (1) a speaker encoder network, trained on a speaker verification task using an independent dataset of noisy speech from thousands of speakers without transcripts, to generate a fixed-dimensional embedding vector from seconds of reference speech from a target speaker; (2) a sequence-to-sequence synthesis network based on Tacotron 2, which generates a mel spectrogram from text, conditioned on the speaker embedding; (3) an auto-regressive WaveNet-based vocoder that converts the mel spectrogram into a sequence of time domain waveform samples. We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the new task, and is able to synthesize natural speech from speakers that were not seen during training. We quantify the importance of training the speaker encoder on a large and diverse speaker set in order to obtain the best generalization performance. Finally, we show that randomly sampled speaker embeddings can be used to synthesize speech in the voice of novel speakers dissimilar from those used in training, indicating that the model has learned a high quality speaker representation.
Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis
Mar 23, 2018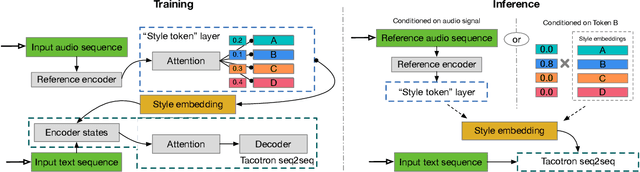
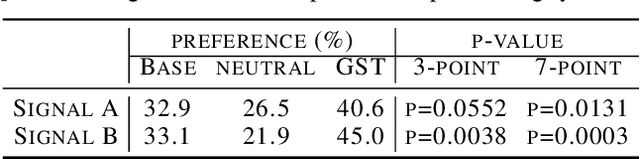
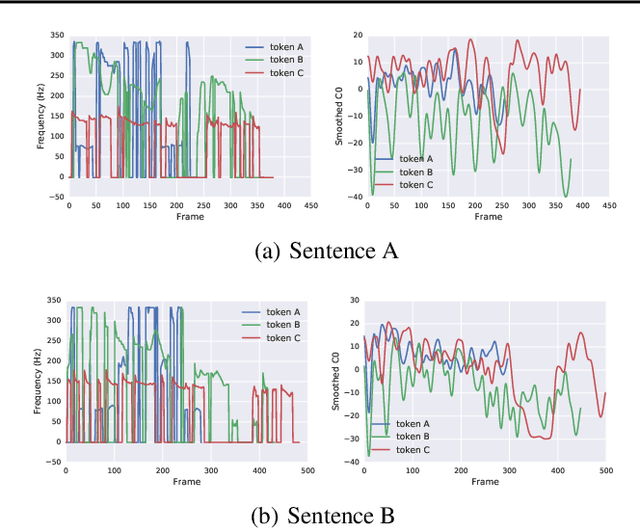

In this work, we propose "global style tokens" (GSTs), a bank of embeddings that are jointly trained within Tacotron, a state-of-the-art end-to-end speech synthesis system. The embeddings are trained with no explicit labels, yet learn to model a large range of acoustic expressiveness. GSTs lead to a rich set of significant results. The soft interpretable "labels" they generate can be used to control synthesis in novel ways, such as varying speed and speaking style - independently of the text content. They can also be used for style transfer, replicating the speaking style of a single audio clip across an entire long-form text corpus. When trained on noisy, unlabeled found data, GSTs learn to factorize noise and speaker identity, providing a path towards highly scalable but robust speech synthesis.