 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDHR: Dual Features-Driven Hierarchical Rebalancing in Inter- and Intra-Class Regions for Weakly-Supervised Semantic Segmentation
Mar 30, 2024



Weakly-supervised semantic segmentation (WSS) ensures high-quality segmentation with limited data and excels when employed as input seed masks for large-scale vision models such as Segment Anything. However, WSS faces challenges related to minor classes since those are overlooked in images with adjacent multiple classes, a limitation originating from the overfitting of traditional expansion methods like Random Walk. We first address this by employing unsupervised and weakly-supervised feature maps instead of conventional methodologies, allowing for hierarchical mask enhancement. This method distinctly categorizes higher-level classes and subsequently separates their associated lower-level classes, ensuring all classes are correctly restored in the mask without losing minor ones. Our approach, validated through extensive experimentation, significantly improves WSS across five benchmarks (VOC: 79.8\%, COCO: 53.9\%, Context: 49.0\%, ADE: 32.9\%, Stuff: 37.4\%), reducing the gap with fully supervised methods by over 84\% on the VOC validation set. Code is available at https://github.com/shjo-april/DHR.
ImageNet-D: Benchmarking Neural Network Robustness on Diffusion Synthetic Object
Mar 27, 2024



We establish rigorous benchmarks for visual perception robustness. Synthetic images such as ImageNet-C, ImageNet-9, and Stylized ImageNet provide specific type of evaluation over synthetic corruptions, backgrounds, and textures, yet those robustness benchmarks are restricted in specified variations and have low synthetic quality. In this work, we introduce generative model as a data source for synthesizing hard images that benchmark deep models' robustness. Leveraging diffusion models, we are able to generate images with more diversified backgrounds, textures, and materials than any prior work, where we term this benchmark as ImageNet-D. Experimental results show that ImageNet-D results in a significant accuracy drop to a range of vision models, from the standard ResNet visual classifier to the latest foundation models like CLIP and MiniGPT-4, significantly reducing their accuracy by up to 60\%. Our work suggests that diffusion models can be an effective source to test vision models. The code and dataset are available at https://github.com/chenshuang-zhang/imagenet_d.
Zero-shot Building Attribute Extraction from Large-Scale Vision and Language Models
Dec 19, 2023



Existing building recognition methods, exemplified by BRAILS, utilize supervised learning to extract information from satellite and street-view images for classification and segmentation. However, each task module requires human-annotated data, hindering the scalability and robustness to regional variations and annotation imbalances. In response, we propose a new zero-shot workflow for building attribute extraction that utilizes large-scale vision and language models to mitigate reliance on external annotations. The proposed workflow contains two key components: image-level captioning and segment-level captioning for the building images based on the vocabularies pertinent to structural and civil engineering. These two components generate descriptive captions by computing feature representations of the image and the vocabularies, and facilitating a semantic match between the visual and textual representations. Consequently, our framework offers a promising avenue to enhance AI-driven captioning for building attribute extraction in the structural and civil engineering domains, ultimately reducing reliance on human annotations while bolstering performance and adaptability.
MoDA: Leveraging Motion Priors from Videos for Advancing Unsupervised Domain Adaptation in Semantic Segmentation
Sep 21, 2023



Unsupervised domain adaptation (UDA) is an effective approach to handle the lack of annotations in the target domain for the semantic segmentation task. In this work, we consider a more practical UDA setting where the target domain contains sequential frames of the unlabeled videos which are easy to collect in practice. A recent study suggests self-supervised learning of the object motion from unlabeled videos with geometric constraints. We design a motion-guided domain adaptive semantic segmentation framework (MoDA), that utilizes self-supervised object motion to learn effective representations in the target domain. MoDA differs from previous methods that use temporal consistency regularization for the target domain frames. Instead, MoDA deals separately with the domain alignment on the foreground and background categories using different strategies. Specifically, MoDA contains foreground object discovery and foreground semantic mining to align the foreground domain gaps by taking the instance-level guidance from the object motion. Additionally, MoDA includes background adversarial training which contains a background category-specific discriminator to handle the background domain gaps. Experimental results on multiple benchmarks highlight the effectiveness of MoDA against existing approaches in the domain adaptive image segmentation and domain adaptive video segmentation. Moreover, MoDA is versatile and can be used in conjunction with existing state-of-the-art approaches to further improve performance.
Dual-View Selective Instance Segmentation Network for Unstained Live Adherent Cells in Differential Interference Contrast Images
Jan 27, 2023



Despite recent advances in data-independent and deep-learning algorithms, unstained live adherent cell instance segmentation remains a long-standing challenge in cell image processing. Adherent cells' inherent visual characteristics, such as low contrast structures, fading edges, and irregular morphology, have made it difficult to distinguish from one another, even by human experts, let alone computational methods. In this study, we developed a novel deep-learning algorithm called dual-view selective instance segmentation network (DVSISN) for segmenting unstained adherent cells in differential interference contrast (DIC) images. First, we used a dual-view segmentation (DVS) method with pairs of original and rotated images to predict the bounding box and its corresponding mask for each cell instance. Second, we used a mask selection (MS) method to filter the cell instances predicted by the DVS to keep masks closest to the ground truth only. The developed algorithm was trained and validated on our dataset containing 520 images and 12198 cells. Experimental results demonstrate that our algorithm achieves an AP_segm of 0.555, which remarkably overtakes a benchmark by a margin of 23.6%. This study's success opens up a new possibility of using rotated images as input for better prediction in cell images.
ML-BPM: Multi-teacher Learning with Bidirectional Photometric Mixing for Open Compound Domain Adaptation in Semantic Segmentation
Jul 19, 2022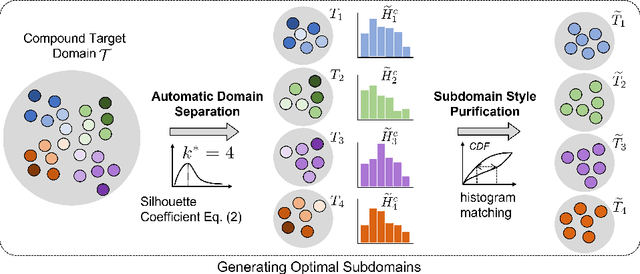
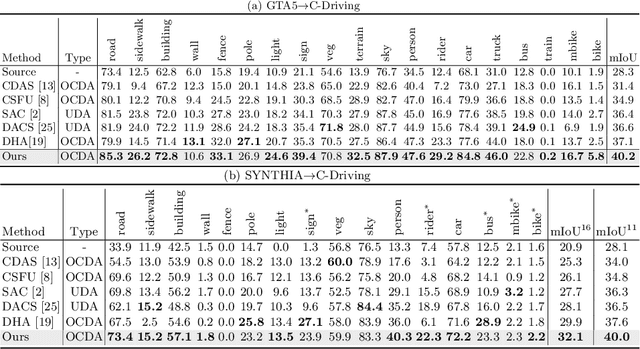

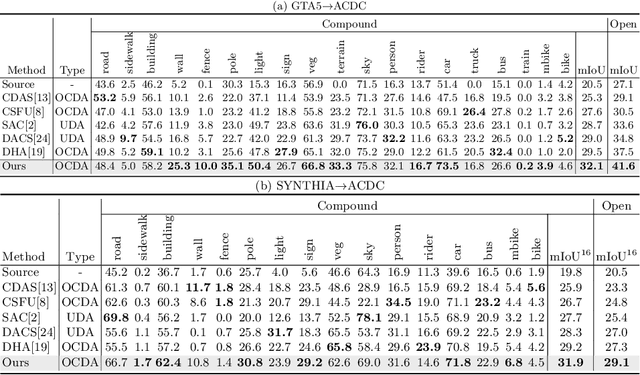
Open compound domain adaptation (OCDA) considers the target domain as the compound of multiple unknown homogeneous subdomains. The goal of OCDA is to minimize the domain gap between the labeled source domain and the unlabeled compound target domain, which benefits the model generalization to the unseen domains. Current OCDA for semantic segmentation methods adopt manual domain separation and employ a single model to simultaneously adapt to all the target subdomains. However, adapting to a target subdomain might hinder the model from adapting to other dissimilar target subdomains, which leads to limited performance. In this work, we introduce a multi-teacher framework with bidirectional photometric mixing to separately adapt to every target subdomain. First, we present an automatic domain separation to find the optimal number of subdomains. On this basis, we propose a multi-teacher framework in which each teacher model uses bidirectional photometric mixing to adapt to one target subdomain. Furthermore, we conduct an adaptive distillation to learn a student model and apply consistency regularization to improve the student generalization. Experimental results on benchmark datasets show the efficacy of the proposed approach for both the compound domain and the open domains against existing state-of-the-art approaches.
Labeling Where Adapting Fails: Cross-Domain Semantic Segmentation with Point Supervision via Active Selection
Jun 04, 2022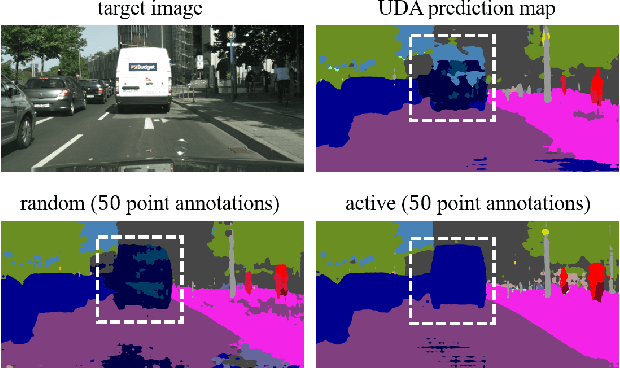
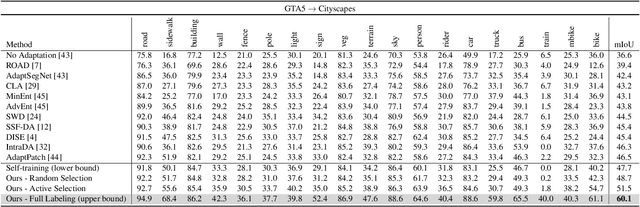
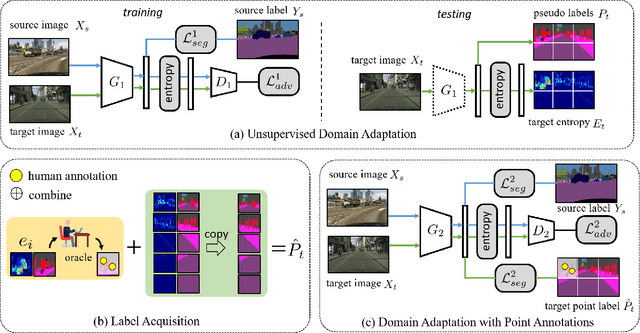
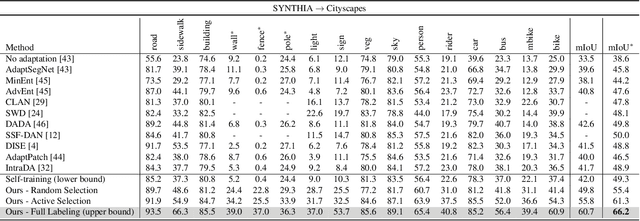
Training models dedicated to semantic segmentation requires a large amount of pixel-wise annotated data. Due to their costly nature, these annotations might not be available for the task at hand. To alleviate this problem, unsupervised domain adaptation approaches aim at aligning the feature distributions between the labeled source and the unlabeled target data. While these strategies lead to noticeable improvements, their effectiveness remains limited. To guide the domain adaptation task more efficiently, previous works attempted to include human interactions in this process under the form of sparse single-pixel annotations in the target data. In this work, we propose a new domain adaptation framework for semantic segmentation with annotated points via active selection. First, we conduct an unsupervised domain adaptation of the model; from this adaptation, we use an entropy-based uncertainty measurement for target points selection. Finally, to minimize the domain gap, we propose a domain adaptation framework utilizing these target points annotated by human annotators. Experimental results on benchmark datasets show the effectiveness of our methods against existing unsupervised domain adaptation approaches. The propose pipeline is generic and can be included as an extra module to existing domain adaptation strategies.
Attentive and Contrastive Learning for Joint Depth and Motion Field Estimation
Oct 13, 2021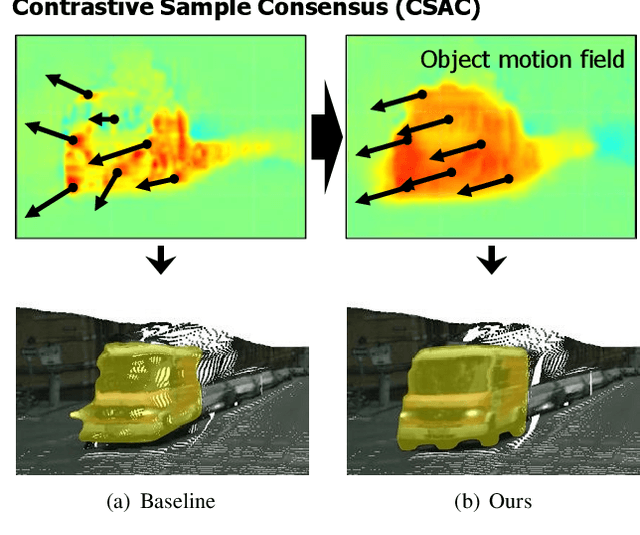
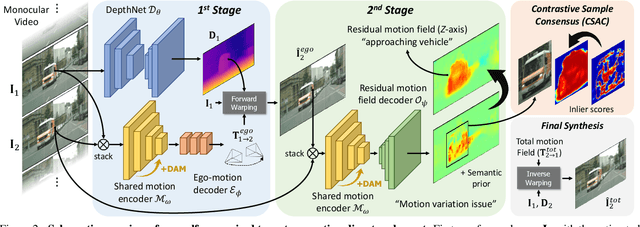

Estimating the motion of the camera together with the 3D structure of the scene from a monocular vision system is a complex task that often relies on the so-called scene rigidity assumption. When observing a dynamic environment, this assumption is violated which leads to an ambiguity between the ego-motion of the camera and the motion of the objects. To solve this problem, we present a self-supervised learning framework for 3D object motion field estimation from monocular videos. Our contributions are two-fold. First, we propose a two-stage projection pipeline to explicitly disentangle the camera ego-motion and the object motions with dynamics attention module, called DAM. Specifically, we design an integrated motion model that estimates the motion of the camera and object in the first and second warping stages, respectively, controlled by the attention module through a shared motion encoder. Second, we propose an object motion field estimation through contrastive sample consensus, called CSAC, taking advantage of weak semantic prior (bounding box from an object detector) and geometric constraints (each object respects the rigid body motion model). Experiments on KITTI, Cityscapes, and Waymo Open Dataset demonstrate the relevance of our approach and show that our method outperforms state-of-the-art algorithms for the tasks of self-supervised monocular depth estimation, object motion segmentation, monocular scene flow estimation, and visual odometry.
Transductive Maximum Margin Classifier for Few-Shot Learning
Jul 26, 2021
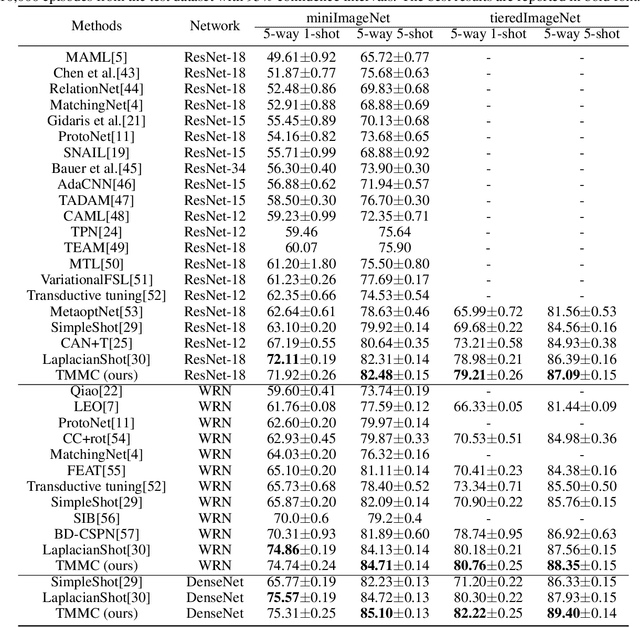
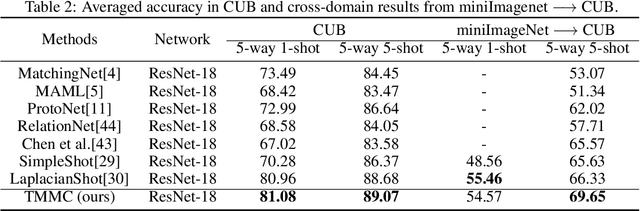
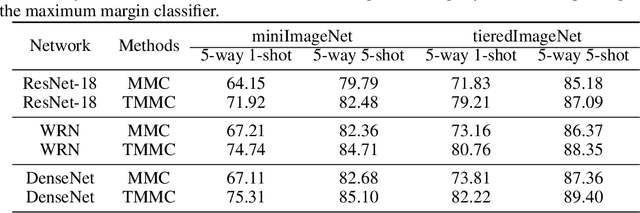
Few-shot learning aims to train a classifier that can generalize well when just a small number of labeled samples per class are given. We introduce Transductive Maximum Margin Classifier (TMMC) for few-shot learning. The basic idea of the classical maximum margin classifier is to solve an optimal prediction function that the corresponding separating hyperplane can correctly divide the training data and the resulting classifier has the largest geometric margin. In few-shot learning scenarios, the training samples are scarce, not enough to find a separating hyperplane with good generalization ability on unseen data. TMMC is constructed using a mixture of the labeled support set and the unlabeled query set in a given task. The unlabeled samples in the query set can adjust the separating hyperplane so that the prediction function is optimal on both the labeled and unlabeled samples. Furthermore, we leverage an efficient and effective quasi-Newton algorithm, the L-BFGS method to optimize TMMC. Experimental results on three standard few-shot learning benchmarks including miniImagenet, tieredImagenet and CUB suggest that our TMMC achieves state-of-the-art accuracies.
Temporal Alignment Prediction for Few-Shot Video Classification
Jul 26, 2021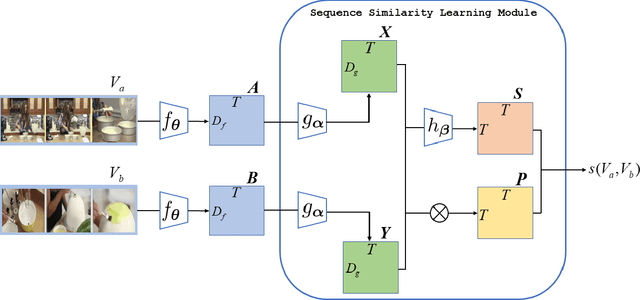
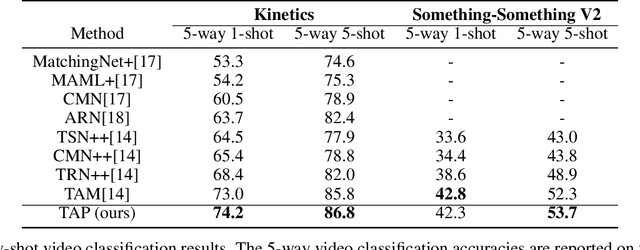
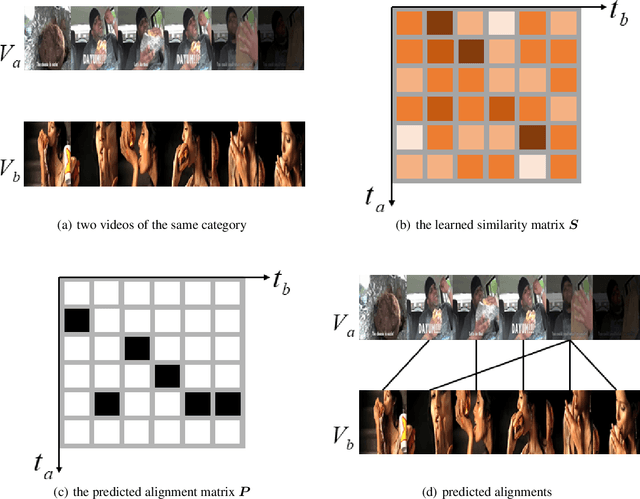
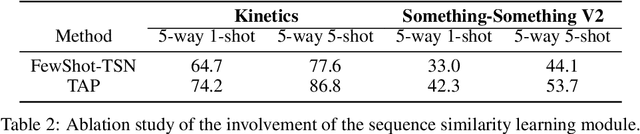
The goal of few-shot video classification is to learn a classification model with good generalization ability when trained with only a few labeled videos. However, it is difficult to learn discriminative feature representations for videos in such a setting. In this paper, we propose Temporal Alignment Prediction (TAP) based on sequence similarity learning for few-shot video classification. In order to obtain the similarity of a pair of videos, we predict the alignment scores between all pairs of temporal positions in the two videos with the temporal alignment prediction function. Besides, the inputs to this function are also equipped with the context information in the temporal domain. We evaluate TAP on two video classification benchmarks including Kinetics and Something-Something V2. The experimental results verify the effectiveness of TAP and show its superiority over state-of-the-art methods.