 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Benchmark: LLMs Evaluation with an Anthropomorphic and Value-oriented Roadmap
Aug 26, 2025For Large Language Models (LLMs), a disconnect persists between benchmark performance and real-world utility. Current evaluation frameworks remain fragmented, prioritizing technical metrics while neglecting holistic assessment for deployment. This survey introduces an anthropomorphic evaluation paradigm through the lens of human intelligence, proposing a novel three-dimensional taxonomy: Intelligence Quotient (IQ)-General Intelligence for foundational capacity, Emotional Quotient (EQ)-Alignment Ability for value-based interactions, and Professional Quotient (PQ)-Professional Expertise for specialized proficiency. For practical value, we pioneer a Value-oriented Evaluation (VQ) framework assessing economic viability, social impact, ethical alignment, and environmental sustainability. Our modular architecture integrates six components with an implementation roadmap. Through analysis of 200+ benchmarks, we identify key challenges including dynamic assessment needs and interpretability gaps. It provides actionable guidance for developing LLMs that are technically proficient, contextually relevant, and ethically sound. We maintain a curated repository of open-source evaluation resources at: https://github.com/onejune2018/Awesome-LLM-Eval.
LangPert: Detecting and Handling Task-level Perturbations for Robust Object Rearrangement
Apr 14, 2025Task execution for object rearrangement could be challenged by Task-Level Perturbations (TLP), i.e., unexpected object additions, removals, and displacements that can disrupt underlying visual policies and fundamentally compromise task feasibility and progress. To address these challenges, we present LangPert, a language-based framework designed to detect and mitigate TLP situations in tabletop rearrangement tasks. LangPert integrates a Visual Language Model (VLM) to comprehensively monitor policy's skill execution and environmental TLP, while leveraging the Hierarchical Chain-of-Thought (HCoT) reasoning mechanism to enhance the Large Language Model (LLM)'s contextual understanding and generate adaptive, corrective skill-execution plans. Our experimental results demonstrate that LangPert handles diverse TLP situations more effectively than baseline methods, achieving higher task completion rates, improved execution efficiency, and potential generalization to unseen scenarios.
OpenSlot: Mixed Open-set Recognition with Object-centric Learning
Jul 02, 2024



Existing open-set recognition (OSR) studies typically assume that each image contains only one class label, and the unknown test set (negative) has a disjoint label space from the known test set (positive), a scenario termed full-label shift. This paper introduces the mixed OSR problem, where test images contain multiple class semantics, with known and unknown classes co-occurring in negatives, leading to a more challenging super-label shift. Addressing the mixed OSR requires classification models to accurately distinguish different class semantics within images and measure their "knowness". In this study, we propose the OpenSlot framework, built upon object-centric learning. OpenSlot utilizes slot features to represent diverse class semantics and produce class predictions. Through our proposed anti-noise-slot (ANS) technique, we mitigate the impact of noise (invalid and background) slots during classification training, effectively addressing the semantic misalignment between class predictions and the ground truth. We conduct extensive experiments with OpenSlot on mixed & conventional OSR benchmarks. Without elaborate designs, OpenSlot not only exceeds existing OSR studies in detecting super-label shifts across single & multi-label mixed OSR tasks but also achieves state-of-the-art performance on conventional benchmarks. Remarkably, our method can localize class objects without using bounding boxes during training. The competitive performance in open-set object detection demonstrates OpenSlot's ability to explicitly explain label shifts and benefits in computational efficiency and generalization.
Fine-grained Background Representation for Weakly Supervised Semantic Segmentation
Jun 22, 2024



Generating reliable pseudo masks from image-level labels is challenging in the weakly supervised semantic segmentation (WSSS) task due to the lack of spatial information. Prevalent class activation map (CAM)-based solutions are challenged to discriminate the foreground (FG) objects from the suspicious background (BG) pixels (a.k.a. co-occurring) and learn the integral object regions. This paper proposes a simple fine-grained background representation (FBR) method to discover and represent diverse BG semantics and address the co-occurring problems. We abandon using the class prototype or pixel-level features for BG representation. Instead, we develop a novel primitive, negative region of interest (NROI), to capture the fine-grained BG semantic information and conduct the pixel-to-NROI contrast to distinguish the confusing BG pixels. We also present an active sampling strategy to mine the FG negatives on-the-fly, enabling efficient pixel-to-pixel intra-foreground contrastive learning to activate the entire object region. Thanks to the simplicity of design and convenience in use, our proposed method can be seamlessly plugged into various models, yielding new state-of-the-art results under various WSSS settings across benchmarks. Leveraging solely image-level (I) labels as supervision, our method achieves 73.2 mIoU and 45.6 mIoU segmentation results on Pascal Voc and MS COCO test sets, respectively. Furthermore, by incorporating saliency maps as an additional supervision signal (I+S), we attain 74.9 mIoU on Pascal Voc test set. Concurrently, our FBR approach demonstrates meaningful performance gains in weakly-supervised instance segmentation (WSIS) tasks, showcasing its robustness and strong generalization capabilities across diverse domains.
Holistic Inverse Rendering of Complex Facade via Aerial 3D Scanning
Nov 20, 2023



In this work, we use multi-view aerial images to reconstruct the geometry, lighting, and material of facades using neural signed distance fields (SDFs). Without the requirement of complex equipment, our method only takes simple RGB images captured by a drone as inputs to enable physically based and photorealistic novel-view rendering, relighting, and editing. However, a real-world facade usually has complex appearances ranging from diffuse rocks with subtle details to large-area glass windows with specular reflections, making it hard to attend to everything. As a result, previous methods can preserve the geometry details but fail to reconstruct smooth glass windows or verse vise. In order to address this challenge, we introduce three spatial- and semantic-adaptive optimization strategies, including a semantic regularization approach based on zero-shot segmentation techniques to improve material consistency, a frequency-aware geometry regularization to balance surface smoothness and details in different surfaces, and a visibility probe-based scheme to enable efficient modeling of the local lighting in large-scale outdoor environments. In addition, we capture a real-world facade aerial 3D scanning image set and corresponding point clouds for training and benchmarking. The experiment demonstrates the superior quality of our method on facade holistic inverse rendering, novel view synthesis, and scene editing compared to state-of-the-art baselines.
MoDA: Leveraging Motion Priors from Videos for Advancing Unsupervised Domain Adaptation in Semantic Segmentation
Sep 21, 2023



Unsupervised domain adaptation (UDA) is an effective approach to handle the lack of annotations in the target domain for the semantic segmentation task. In this work, we consider a more practical UDA setting where the target domain contains sequential frames of the unlabeled videos which are easy to collect in practice. A recent study suggests self-supervised learning of the object motion from unlabeled videos with geometric constraints. We design a motion-guided domain adaptive semantic segmentation framework (MoDA), that utilizes self-supervised object motion to learn effective representations in the target domain. MoDA differs from previous methods that use temporal consistency regularization for the target domain frames. Instead, MoDA deals separately with the domain alignment on the foreground and background categories using different strategies. Specifically, MoDA contains foreground object discovery and foreground semantic mining to align the foreground domain gaps by taking the instance-level guidance from the object motion. Additionally, MoDA includes background adversarial training which contains a background category-specific discriminator to handle the background domain gaps. Experimental results on multiple benchmarks highlight the effectiveness of MoDA against existing approaches in the domain adaptive image segmentation and domain adaptive video segmentation. Moreover, MoDA is versatile and can be used in conjunction with existing state-of-the-art approaches to further improve performance.
Contour-Aware Equipotential Learning for Semantic Segmentation
Oct 01, 2022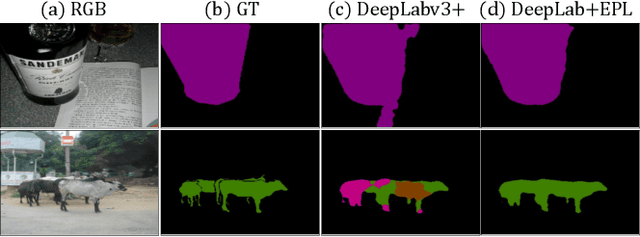

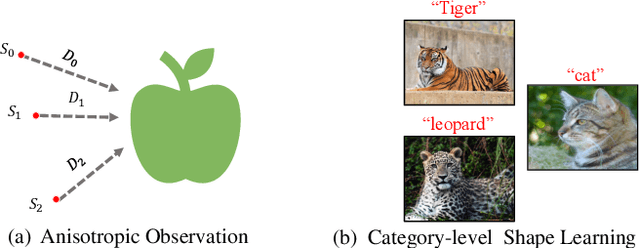
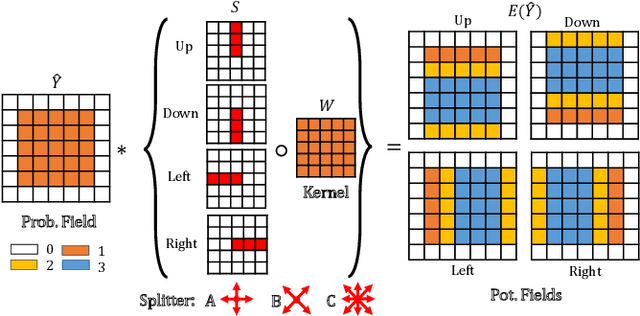
With increasing demands for high-quality semantic segmentation in the industry, hard-distinguishing semantic boundaries have posed a significant threat to existing solutions. Inspired by real-life experience, i.e., combining varied observations contributes to higher visual recognition confidence, we present the equipotential learning (EPL) method. This novel module transfers the predicted/ground-truth semantic labels to a self-defined potential domain to learn and infer decision boundaries along customized directions. The conversion to the potential domain is implemented via a lightweight differentiable anisotropic convolution without incurring any parameter overhead. Besides, the designed two loss functions, the point loss and the equipotential line loss implement anisotropic field regression and category-level contour learning, respectively, enhancing prediction consistencies in the inter/intra-class boundary areas. More importantly, EPL is agnostic to network architectures, and thus it can be plugged into most existing segmentation models. This paper is the first attempt to address the boundary segmentation problem with field regression and contour learning. Meaningful performance improvements on Pascal Voc 2012 and Cityscapes demonstrate that the proposed EPL module can benefit the off-the-shelf fully convolutional network models when recognizing semantic boundary areas. Besides, intensive comparisons and analysis show the favorable merits of EPL for distinguishing semantically-similar and irregular-shaped categories.
Understanding and Improving Group Normalization
Jul 05, 2022
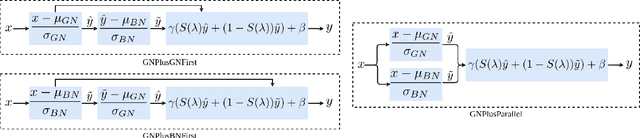
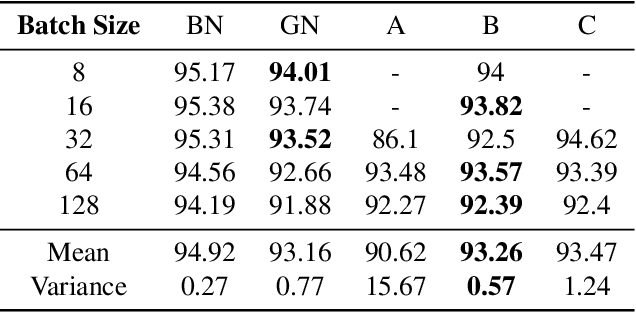
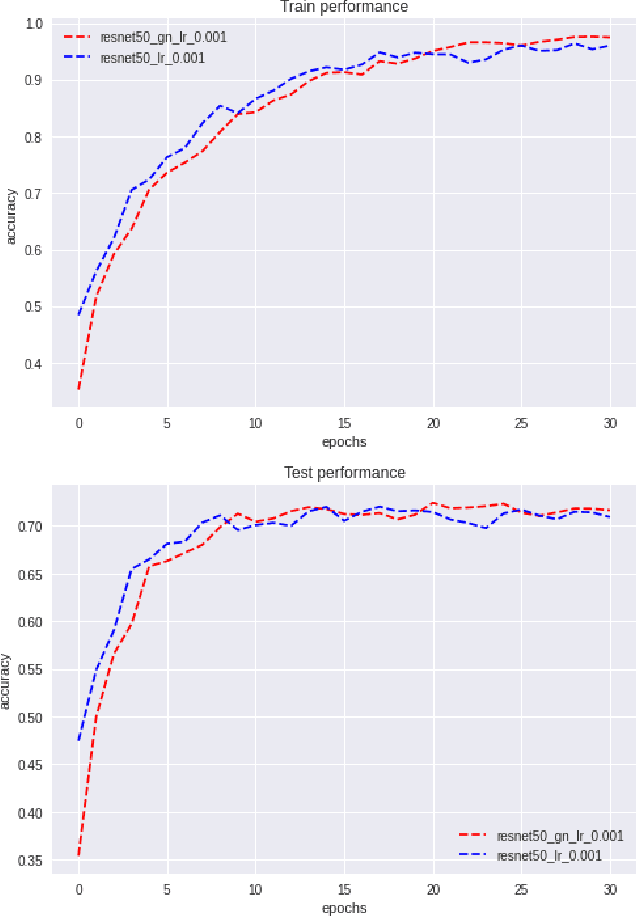
Various normalization layers have been proposed to help the training of neural networks. Group Normalization (GN) is one of the effective and attractive studies that achieved significant performances in the visual recognition task. Despite the great success achieved, GN still has several issues that may negatively impact neural network training. In this paper, we introduce an analysis framework and discuss the working principles of GN in affecting the training process of the neural network. From experimental results, we conclude the real cause of GN's inferior performance against Batch normalization (BN): 1) \textbf{unstable training performance}, 2) \textbf{more sensitive} to distortion, whether it comes from external noise or perturbations introduced by the regularization. In addition, we found that GN can only help the neural network training in some specific period, unlike BN, which helps the network throughout the training. To solve these issues, we propose a new normalization layer built on top of GN, by incorporating the advantages of BN. Experimental results on the image classification task demonstrated that the proposed normalization layer outperforms the official GN to improve recognition accuracy regardless of the batch sizes and stabilize the network training.