 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset on Malicious Paper Bidding in Peer Review
Jun 24, 2022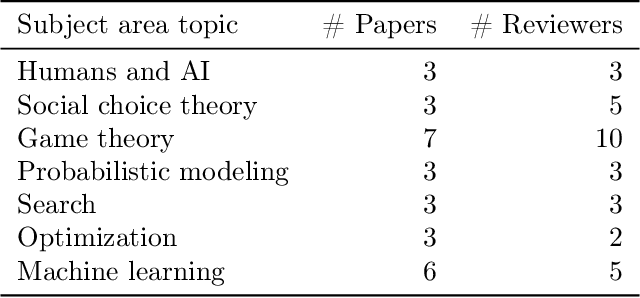

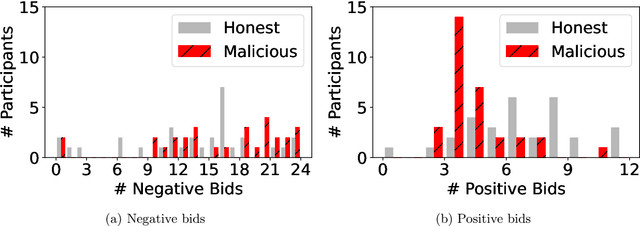
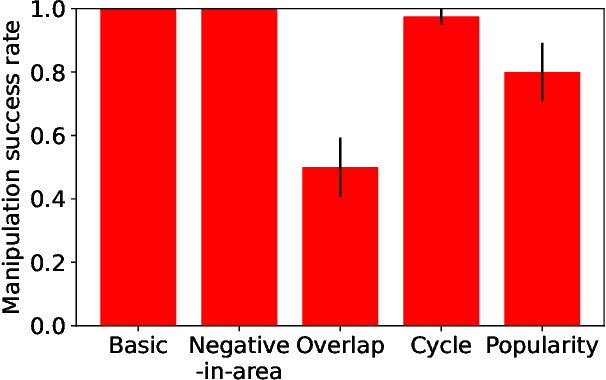
In conference peer review, reviewers are often asked to provide "bids" on each submitted paper that express their interest in reviewing that paper. A paper assignment algorithm then uses these bids (along with other data) to compute a high-quality assignment of reviewers to papers. However, this process has been exploited by malicious reviewers who strategically bid in order to unethically manipulate the paper assignment, crucially undermining the peer review process. For example, these reviewers may aim to get assigned to a friend's paper as part of a quid-pro-quo deal. A critical impediment towards creating and evaluating methods to mitigate this issue is the lack of any publicly-available data on malicious paper bidding. In this work, we collect and publicly release a novel dataset to fill this gap, collected from a mock conference activity where participants were instructed to bid either honestly or maliciously. We further provide a descriptive analysis of the bidding behavior, including our categorization of different strategies employed by participants. Finally, we evaluate the ability of each strategy to manipulate the assignment, and also evaluate the performance of some simple algorithms meant to detect malicious bidding. The performance of these detection algorithms can be taken as a baseline for future research on detecting malicious bidding.
The Real Deal: A Review of Challenges and Opportunities in Moving Reinforcement Learning-Based Traffic Signal Control Systems Towards Reality
Jun 23, 2022Traffic signal control (TSC) is a high-stakes domain that is growing in importance as traffic volume grows globally. An increasing number of works are applying reinforcement learning (RL) to TSC; RL can draw on an abundance of traffic data to improve signalling efficiency. However, RL-based signal controllers have never been deployed. In this work, we provide the first review of challenges that must be addressed before RL can be deployed for TSC. We focus on four challenges involving (1) uncertainty in detection, (2) reliability of communications, (3) compliance and interpretability, and (4) heterogeneous road users. We show that the literature on RL-based TSC has made some progress towards addressing each challenge. However, more work should take a systems thinking approach that considers the impacts of other pipeline components on RL.
MAVIPER: Learning Decision Tree Policies for Interpretable Multi-Agent Reinforcement Learning
May 25, 2022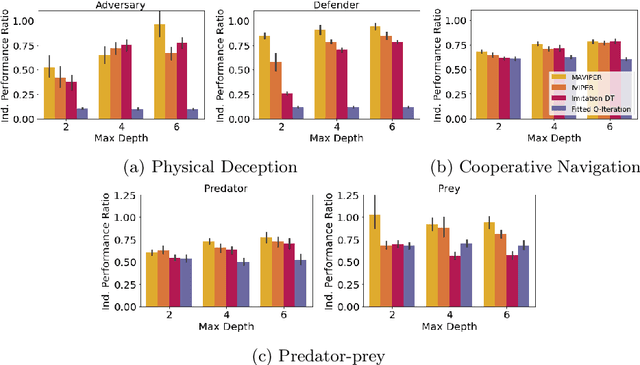
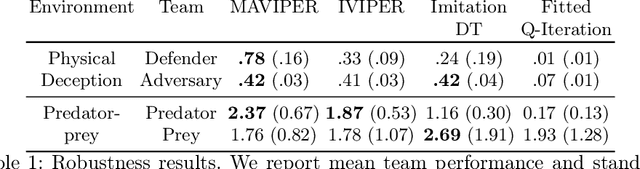
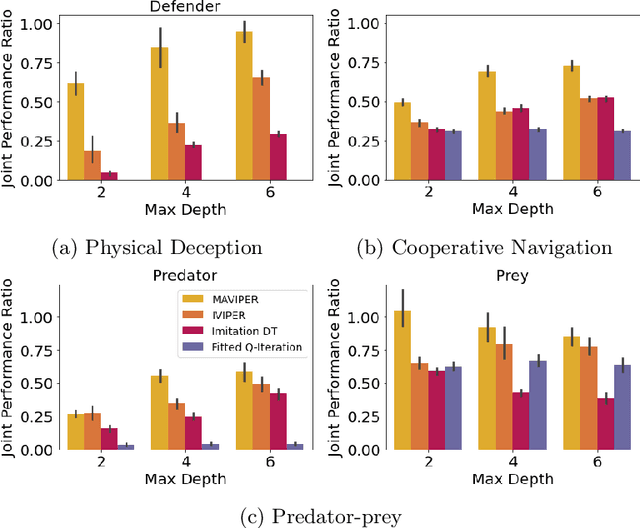
Many recent breakthroughs in multi-agent reinforcement learning (MARL) require the use of deep neural networks, which are challenging for human experts to interpret and understand. On the other hand, existing work on interpretable RL has shown promise in extracting more interpretable decision tree-based policies, but only in the single-agent setting. To fill this gap, we propose the first set of interpretable MARL algorithms that extract decision-tree policies from neural networks trained with MARL. The first algorithm, IVIPER, extends VIPER, a recent method for single-agent interpretable RL, to the multi-agent setting. We demonstrate that IVIPER can learn high-quality decision-tree policies for each agent. To better capture coordination between agents, we propose a novel centralized decision-tree training algorithm, MAVIPER. MAVIPER jointly grows the trees of each agent by predicting the behavior of the other agents using their anticipated trees, and uses resampling to focus on states that are critical for its interactions with other agents. We show that both algorithms generally outperform the baselines and that MAVIPER-trained agents achieve better-coordinated performance than IVIPER-trained agents on three different multi-agent particle-world environments.
Color Overmodification Emerges from Data-Driven Learning and Pragmatic Reasoning
May 18, 2022Speakers' referential expressions often depart from communicative ideals in ways that help illuminate the nature of pragmatic language use. Patterns of overmodification, in which a speaker uses a modifier that is redundant given their communicative goal, have proven especially informative in this regard. It seems likely that these patterns are shaped by the environment a speaker is exposed to in complex ways. Unfortunately, systematically manipulating these factors during human language acquisition is impossible. In this paper, we propose to address this limitation by adopting neural networks (NN) as learning agents. By systematically varying the environments in which these agents are trained, while keeping the NN architecture constant, we show that overmodification is more likely with environmental features that are infrequent or salient. We show that these findings emerge naturally in the context of a probabilistic model of pragmatic communication.
Ranked Prioritization of Groups in Combinatorial Bandit Allocation
May 11, 2022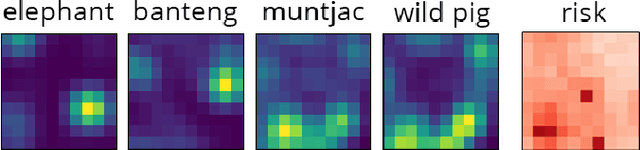
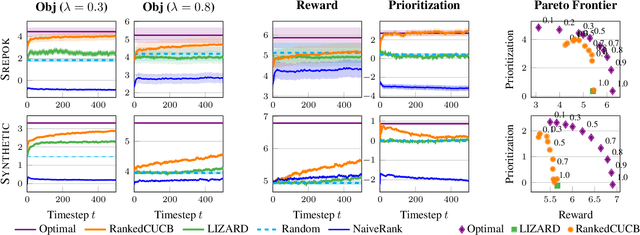
Preventing poaching through ranger patrols protects endangered wildlife, directly contributing to the UN Sustainable Development Goal 15 of life on land. Combinatorial bandits have been used to allocate limited patrol resources, but existing approaches overlook the fact that each location is home to multiple species in varying proportions, so a patrol benefits each species to differing degrees. When some species are more vulnerable, we ought to offer more protection to these animals; unfortunately, existing combinatorial bandit approaches do not offer a way to prioritize important species. To bridge this gap, (1) We propose a novel combinatorial bandit objective that trades off between reward maximization and also accounts for prioritization over species, which we call ranked prioritization. We show this objective can be expressed as a weighted linear sum of Lipschitz-continuous reward functions. (2) We provide RankedCUCB, an algorithm to select combinatorial actions that optimize our prioritization-based objective, and prove that it achieves asymptotic no-regret. (3) We demonstrate empirically that RankedCUCB leads to up to 38% improvement in outcomes for endangered species using real-world wildlife conservation data. Along with adapting to other challenges such as preventing illegal logging and overfishing, our no-regret algorithm addresses the general combinatorial bandit problem with a weighted linear objective.
PerfectDou: Dominating DouDizhu with Perfect Information Distillation
Apr 05, 2022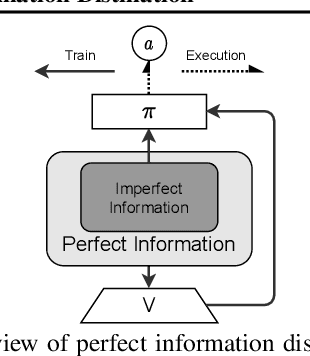

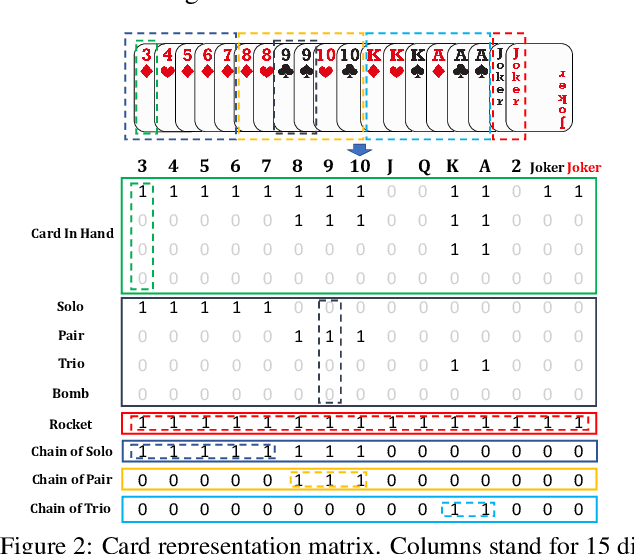
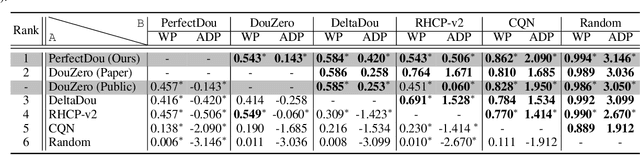
As a challenging multi-player card game, DouDizhu has recently drawn much attention for analyzing competition and collaboration in imperfect-information games. In this paper, we propose PerfectDou, a state-of-the-art DouDizhu AI system that dominates the game, in an actor-critic framework with a proposed technique named perfect information distillation. In detail, we adopt a perfect-training-imperfect-execution framework that allows the agents to utilize the global information to guide the training of the policies as if it is a perfect information game and the trained policies can be used to play the imperfect information game during the actual gameplay. To this end, we characterize card and game features for DouDizhu to represent the perfect and imperfect information. To train our system, we adopt proximal policy optimization with generalized advantage estimation in a parallel training paradigm. In experiments we show how and why PerfectDou beats all existing AI programs, and achieves state-of-the-art performance.
Robust Reinforcement Learning as a Stackelberg Game via Adaptively-Regularized Adversarial Training
Feb 19, 2022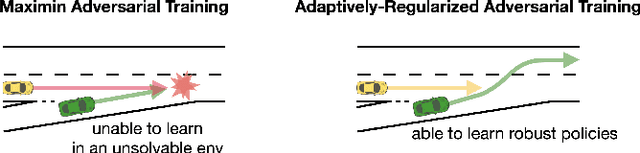
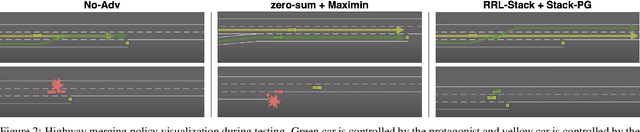
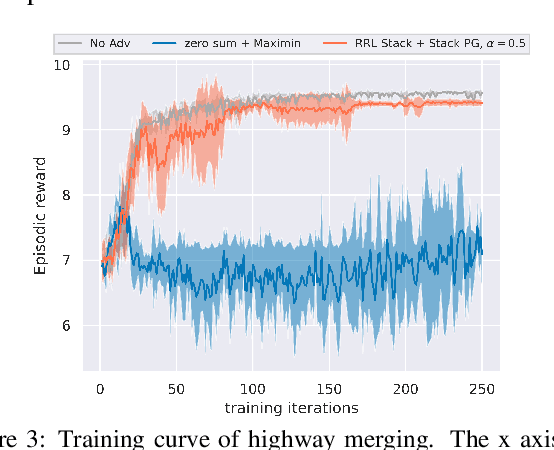
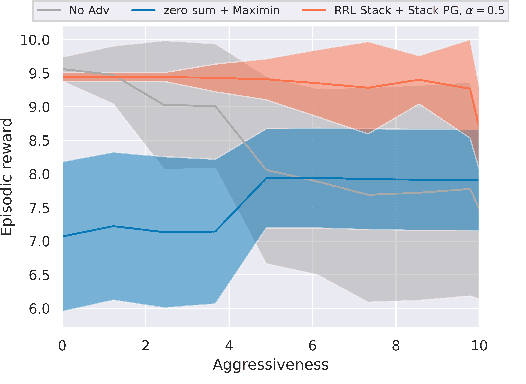
Robust Reinforcement Learning (RL) focuses on improving performances under model errors or adversarial attacks, which facilitates the real-life deployment of RL agents. Robust Adversarial Reinforcement Learning (RARL) is one of the most popular frameworks for robust RL. However, most of the existing literature models RARL as a zero-sum simultaneous game with Nash equilibrium as the solution concept, which could overlook the sequential nature of RL deployments, produce overly conservative agents, and induce training instability. In this paper, we introduce a novel hierarchical formulation of robust RL - a general-sum Stackelberg game model called RRL-Stack - to formalize the sequential nature and provide extra flexibility for robust training. We develop the Stackelberg Policy Gradient algorithm to solve RRL-Stack, leveraging the Stackelberg learning dynamics by considering the adversary's response. Our method generates challenging yet solvable adversarial environments which benefit RL agents' robust learning. Our algorithm demonstrates better training stability and robustness against different testing conditions in the single-agent robotics control and multi-agent highway merging tasks.
A Survey of Explainable Reinforcement Learning
Feb 17, 2022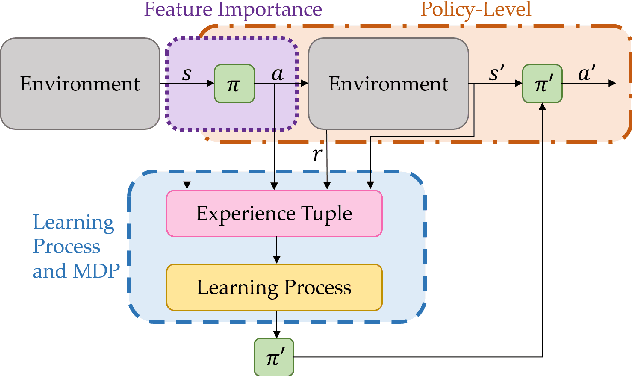
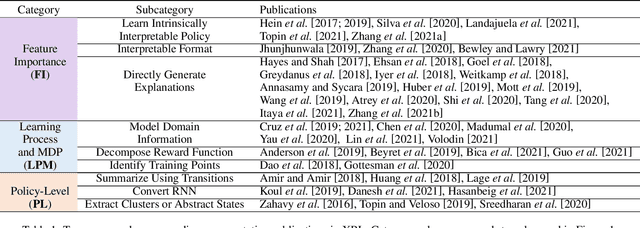
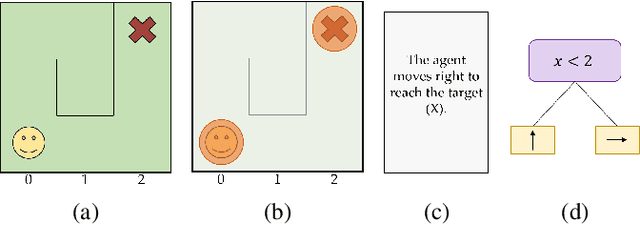
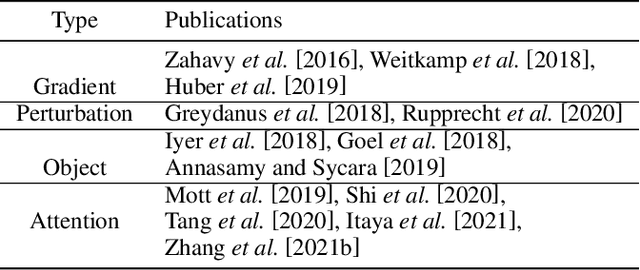
Explainable reinforcement learning (XRL) is an emerging subfield of explainable machine learning that has attracted considerable attention in recent years. The goal of XRL is to elucidate the decision-making process of learning agents in sequential decision-making settings. In this survey, we propose a novel taxonomy for organizing the XRL literature that prioritizes the RL setting. We overview techniques according to this taxonomy. We point out gaps in the literature, which we use to motivate and outline a roadmap for future work.
Efficiency, Fairness, and Stability in Non-Commercial Peer-to-Peer Ridesharing
Oct 04, 2021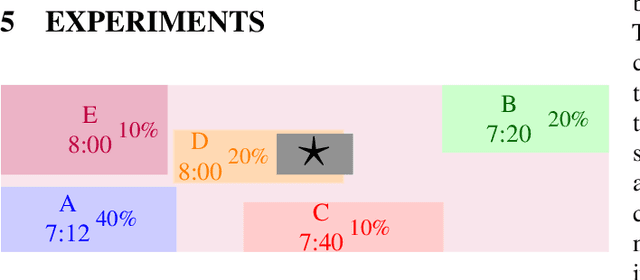
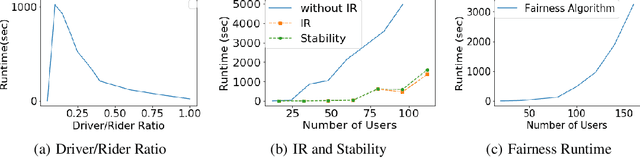
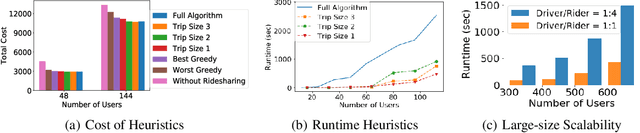
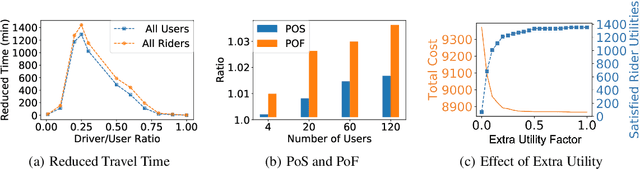
Unlike commercial ridesharing, non-commercial peer-to-peer (P2P) ridesharing has been subject to limited research -- although it can promote viable solutions in non-urban communities. This paper focuses on the core problem in P2P ridesharing: the matching of riders and drivers. We elevate users' preferences as a first-order concern and introduce novel notions of fairness and stability in P2P ridesharing. We propose algorithms for efficient matching while considering user-centric factors, including users' preferred departure time, fairness, and stability. Results suggest that fair and stable solutions can be obtained in reasonable computational times and can improve baseline outcomes based on system-wide efficiency exclusively.
Temporal Induced Self-Play for Stochastic Bayesian Games
Aug 21, 2021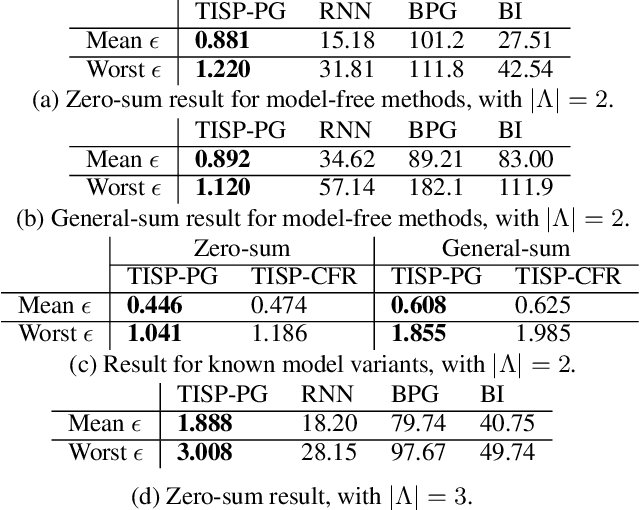
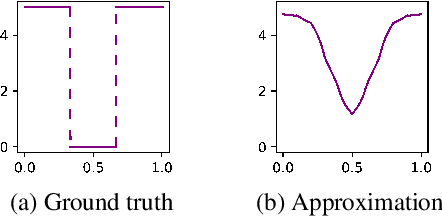
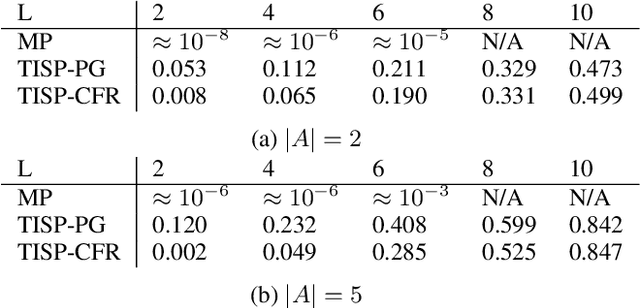
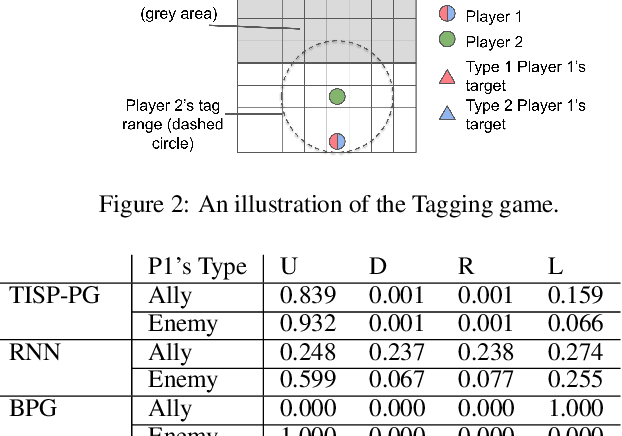
One practical requirement in solving dynamic games is to ensure that the players play well from any decision point onward. To satisfy this requirement, existing efforts focus on equilibrium refinement, but the scalability and applicability of existing techniques are limited. In this paper, we propose Temporal-Induced Self-Play (TISP), a novel reinforcement learning-based framework to find strategies with decent performances from any decision point onward. TISP uses belief-space representation, backward induction, policy learning, and non-parametric approximation. Building upon TISP, we design a policy-gradient-based algorithm TISP-PG. We prove that TISP-based algorithms can find approximate Perfect Bayesian Equilibrium in zero-sum one-sided stochastic Bayesian games with finite horizon. We test TISP-based algorithms in various games, including finitely repeated security games and a grid-world game. The results show that TISP-PG is more scalable than existing mathematical programming-based methods and significantly outperforms other learning-based methods.