 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive and Prescriptive AI toward Optimizing Wildfire Suppression
May 06, 2026Intense wildfire seasons require critical prioritization decisions to allocate scarce suppression resources over a dispersed geographical area. This paper develops a predictive and prescriptive approach to jointly optimize crew assignments and wildfire suppression. The problem features a discrete resource-allocation structure with endogenous wildfire demand and non-linear wildfire dynamics. We formulate an integer optimization model with crew assignments on a time-space-rest network, wildfire dynamics on a time-state network, and linking constraints between them. We develop a two-sided branch-and-price-and-cut algorithm based on: (i) a two-sided column generation scheme that generates fire suppression plans and crew routes iteratively; (ii) a new family of cuts exploiting the knapsack structure of the linking constraints; and (iii) novel branching rules to accommodate non-linear wildfire dynamics. We also propose a data-driven double machine learning approach to estimate wildfire spread as a function of covariate information and suppression efforts, mitigating observed confounding between historical crew assignments and wildfire growth. Extensive computational experiments show that the optimization algorithm scales to otherwise intractable real-world instances; and that the methodology can enhance suppression effectiveness in practice, resulting in significant reductions in area burned over a wildfire season and guiding resource sharing across wildfire jurisdictions.
Let's Have a Conversation: Designing and Evaluating LLM Agents for Interactive Optimization
Apr 03, 2026Optimization is as much about modeling the right problem as solving it. Identifying the right objectives, constraints, and trade-offs demands extensive interaction between researchers and stakeholders. Large language models can empower decision-makers with optimization capabilities through interactive optimization agents that can propose, interpret and refine solutions. However, it is fundamentally harder to evaluate a conversation-based interaction than traditional one-shot approaches. This paper proposes a scalable and replicable methodology for evaluating optimization agents through conversations. We build LLM-powered decision agents that role-play diverse stakeholders, each governed by an internal utility function but communicating like a real decision-maker. We generate thousands of conversations in a school scheduling case study. Results show that one-shot evaluation is severely limiting: the same optimization agent converges to much higher-quality solutions through conversations. Then, this paper uses this methodology to demonstrate that tailored optimization agents, endowed with domain-specific prompts and structured tools, can lead to significant improvements in solution quality in fewer interactions, as compared to general-purpose chatbots. These findings provide evidence of the benefits of emerging solutions at the AI-optimization interface to expand the reach of optimization technologies in practice. They also uncover the impact of operations research expertise to facilitate interactive deployments through the design of effective and reliable optimization agents.
Robotic warehousing operations: a learn-then-optimize approach to large-scale neighborhood search
Aug 29, 2024



The rapid deployment of robotics technologies requires dedicated optimization algorithms to manage large fleets of autonomous agents. This paper supports robotic parts-to-picker operations in warehousing by optimizing order-workstation assignments, item-pod assignments and the schedule of order fulfillment at workstations. The model maximizes throughput, while managing human workload at the workstations and congestion in the facility. We solve it via large-scale neighborhood search, with a novel learn-then-optimize approach to subproblem generation. The algorithm relies on an offline machine learning procedure to predict objective improvements based on subproblem features, and an online optimization model to generate a new subproblem at each iteration. In collaboration with Amazon Robotics, we show that our model and algorithm generate much stronger solutions for practical problems than state-of-the-art approaches. In particular, our solution enhances the utilization of robotic fleets by coordinating robotic tasks for human operators to pick multiple items at once, and by coordinating robotic routes to avoid congestion in the facility.
Learning to Cover: Online Learning and Optimization with Irreversible Decisions
Jun 20, 2024We define an online learning and optimization problem with irreversible decisions contributing toward a coverage target. At each period, a decision-maker selects facilities to open, receives information on the success of each one, and updates a machine learning model to guide future decisions. The goal is to minimize costs across a finite horizon under a chance constraint reflecting the coverage target. We derive an optimal algorithm and a tight lower bound in an asymptotic regime characterized by a large target number of facilities $m\to\infty$ but a finite horizon $T\in\mathbb{Z}_+$. We find that the regret grows sub-linearly at a rate $\Theta\left(m^{\frac{1}{2}\cdot\frac{1}{1-2^{-T}}}\right)$, thus converging exponentially fast to $\Theta(\sqrt{m})$. We establish the robustness of this result to the learning environment; we also extend it to a more complicated facility location setting in a bipartite facility-customer graph with a target on customer coverage. Throughout, constructive proofs identify a policy featuring limited exploration initially for learning purposes, and fast exploitation later on for optimization purposes once uncertainty gets mitigated. These findings underscore the benefits of limited online learning and optimization, in that even a few rounds can provide significant benefits as compared to a no-learning baseline.
Efficiency, Fairness, and Stability in Non-Commercial Peer-to-Peer Ridesharing
Oct 04, 2021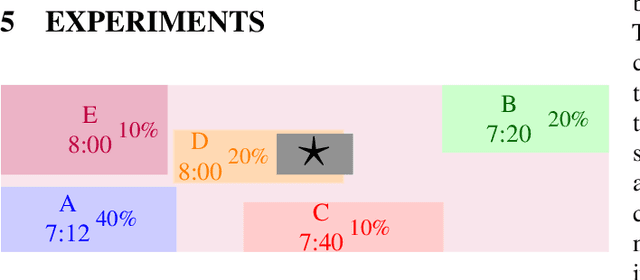
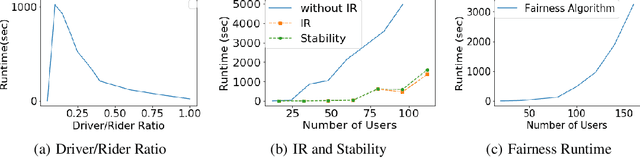
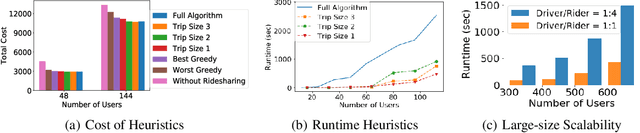
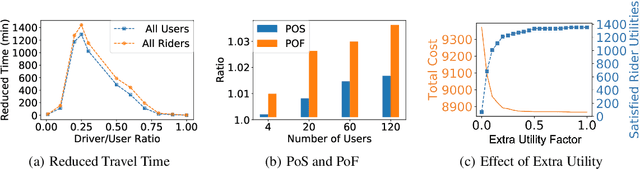
Unlike commercial ridesharing, non-commercial peer-to-peer (P2P) ridesharing has been subject to limited research -- although it can promote viable solutions in non-urban communities. This paper focuses on the core problem in P2P ridesharing: the matching of riders and drivers. We elevate users' preferences as a first-order concern and introduce novel notions of fairness and stability in P2P ridesharing. We propose algorithms for efficient matching while considering user-centric factors, including users' preferred departure time, fairness, and stability. Results suggest that fair and stable solutions can be obtained in reasonable computational times and can improve baseline outcomes based on system-wide efficiency exclusively.
From predictions to prescriptions: A data-driven response to COVID-19
Jun 30, 2020The COVID-19 pandemic has created unprecedented challenges worldwide. Strained healthcare providers make difficult decisions on patient triage, treatment and care management on a daily basis. Policy makers have imposed social distancing measures to slow the disease, at a steep economic price. We design analytical tools to support these decisions and combat the pandemic. Specifically, we propose a comprehensive data-driven approach to understand the clinical characteristics of COVID-19, predict its mortality, forecast its evolution, and ultimately alleviate its impact. By leveraging cohort-level clinical data, patient-level hospital data, and census-level epidemiological data, we develop an integrated four-step approach, combining descriptive, predictive and prescriptive analytics. First, we aggregate hundreds of clinical studies into the most comprehensive database on COVID-19 to paint a new macroscopic picture of the disease. Second, we build personalized calculators to predict the risk of infection and mortality as a function of demographics, symptoms, comorbidities, and lab values. Third, we develop a novel epidemiological model to project the pandemic's spread and inform social distancing policies. Fourth, we propose an optimization model to re-allocate ventilators and alleviate shortages. Our results have been used at the clinical level by several hospitals to triage patients, guide care management, plan ICU capacity, and re-distribute ventilators. At the policy level, they are currently supporting safe back-to-work policies at a major institution and equitable vaccine distribution planning at a major pharmaceutical company, and have been integrated into the US Center for Disease Control's pandemic forecast.