 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyber Deception for Mission Surveillance via Hypergame-Theoretic Deep Reinforcement Learning
Mar 21, 2026Unmanned Aerial Vehicles (UAVs) are valuable for mission-critical systems like surveillance, rescue, or delivery. Not surprisingly, such systems attract cyberattacks, including Denial-of-Service (DoS) attacks to overwhelm the resources of mission drones (MDs). How can we defend UAV mission systems against DoS attacks? We adopt cyber deception as a defense strategy, in which honey drones (HDs) are proposed to bait and divert attacks. The attack and deceptive defense hinge upon radio signal strength: The attacker selects victim MDs based on their signals, and HDs attract the attacker from afar by emitting stronger signals, despite this reducing battery life. We formulate an optimization problem for the attacker and defender to identify their respective strategies for maximizing mission performance while minimizing energy consumption. To address this problem, we propose a novel approach, called HT-DRL. HT-DRL identifies optimal solutions without a long learning convergence time by taking the solutions of hypergame theory into the neural network of deep reinforcement learning. This achieves a systematic way to intelligently deceive attackers. We analyze the performance of diverse defense mechanisms under different attack strategies. Further, the HT-DRL-based HD approach outperforms existing non-HD counterparts up to two times better in mission performance while incurring low energy consumption.
Decision Theory-Guided Deep Reinforcement Learning for Fast Learning
Feb 08, 2024



This paper introduces a novel approach, Decision Theory-guided Deep Reinforcement Learning (DT-guided DRL), to address the inherent cold start problem in DRL. By integrating decision theory principles, DT-guided DRL enhances agents' initial performance and robustness in complex environments, enabling more efficient and reliable convergence during learning. Our investigation encompasses two primary problem contexts: the cart pole and maze navigation challenges. Experimental results demonstrate that the integration of decision theory not only facilitates effective initial guidance for DRL agents but also promotes a more structured and informed exploration strategy, particularly in environments characterized by large and intricate state spaces. The results of experiment demonstrate that DT-guided DRL can provide significantly higher rewards compared to regular DRL. Specifically, during the initial phase of training, the DT-guided DRL yields up to an 184% increase in accumulated reward. Moreover, even after reaching convergence, it maintains a superior performance, ending with up to 53% more reward than standard DRL in large maze problems. DT-guided DRL represents an advancement in mitigating a fundamental challenge of DRL by leveraging functions informed by human (designer) knowledge, setting a foundation for further research in this promising interdisciplinary domain.
IoTFlowGenerator: Crafting Synthetic IoT Device Traffic Flows for Cyber Deception
May 01, 2023Over the years, honeypots emerged as an important security tool to understand attacker intent and deceive attackers to spend time and resources. Recently, honeypots are being deployed for Internet of things (IoT) devices to lure attackers, and learn their behavior. However, most of the existing IoT honeypots, even the high interaction ones, are easily detected by an attacker who can observe honeypot traffic due to lack of real network traffic originating from the honeypot. This implies that, to build better honeypots and enhance cyber deception capabilities, IoT honeypots need to generate realistic network traffic flows. To achieve this goal, we propose a novel deep learning based approach for generating traffic flows that mimic real network traffic due to user and IoT device interactions. A key technical challenge that our approach overcomes is scarcity of device-specific IoT traffic data to effectively train a generator. We address this challenge by leveraging a core generative adversarial learning algorithm for sequences along with domain specific knowledge common to IoT devices. Through an extensive experimental evaluation with 18 IoT devices, we demonstrate that the proposed synthetic IoT traffic generation tool significantly outperforms state of the art sequence and packet generators in remaining indistinguishable from real traffic even to an adaptive attacker.
AIIPot: Adaptive Intelligent-Interaction Honeypot for IoT Devices
Mar 22, 2023



The proliferation of the Internet of Things (IoT) has raised concerns about the security of connected devices. There is a need to develop suitable and cost-efficient methods to identify vulnerabilities in IoT devices in order to address them before attackers seize opportunities to compromise them. The deception technique is a prominent approach to improving the security posture of IoT systems. Honeypot is a popular deception technique that mimics interaction in real fashion and encourages unauthorised users (attackers) to launch attacks. Due to the large number and the heterogeneity of IoT devices, manually crafting the low and high-interaction honeypots is not affordable. This has forced researchers to seek innovative ways to build honeypots for IoT devices. In this paper, we propose a honeypot for IoT devices that uses machine learning techniques to learn and interact with attackers automatically. The evaluation of the proposed model indicates that our system can improve the session length with attackers and capture more attacks on the IoT network.
MAVIPER: Learning Decision Tree Policies for Interpretable Multi-Agent Reinforcement Learning
May 25, 2022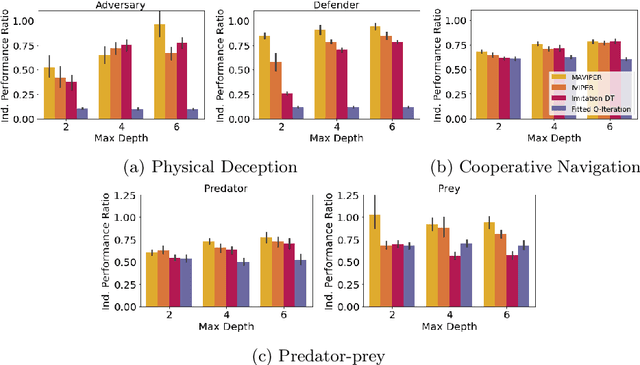
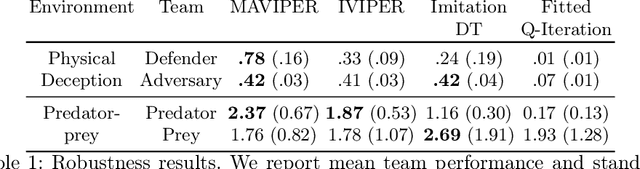
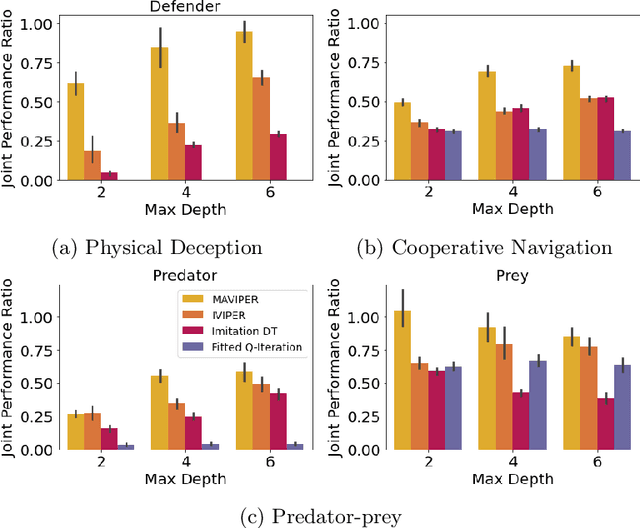
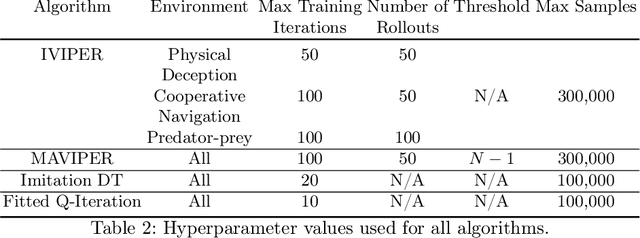
Many recent breakthroughs in multi-agent reinforcement learning (MARL) require the use of deep neural networks, which are challenging for human experts to interpret and understand. On the other hand, existing work on interpretable RL has shown promise in extracting more interpretable decision tree-based policies, but only in the single-agent setting. To fill this gap, we propose the first set of interpretable MARL algorithms that extract decision-tree policies from neural networks trained with MARL. The first algorithm, IVIPER, extends VIPER, a recent method for single-agent interpretable RL, to the multi-agent setting. We demonstrate that IVIPER can learn high-quality decision-tree policies for each agent. To better capture coordination between agents, we propose a novel centralized decision-tree training algorithm, MAVIPER. MAVIPER jointly grows the trees of each agent by predicting the behavior of the other agents using their anticipated trees, and uses resampling to focus on states that are critical for its interactions with other agents. We show that both algorithms generally outperform the baselines and that MAVIPER-trained agents achieve better-coordinated performance than IVIPER-trained agents on three different multi-agent particle-world environments.
Learning Generative Deception Strategies in Combinatorial Masking Games
Sep 23, 2021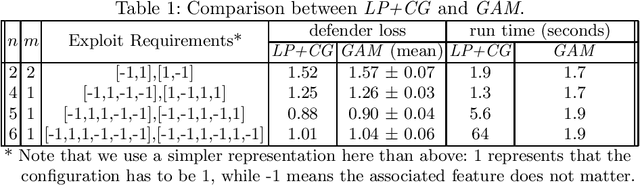
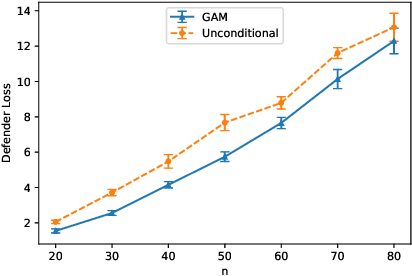
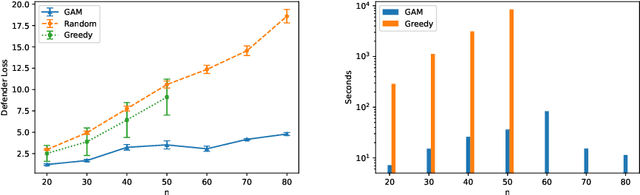
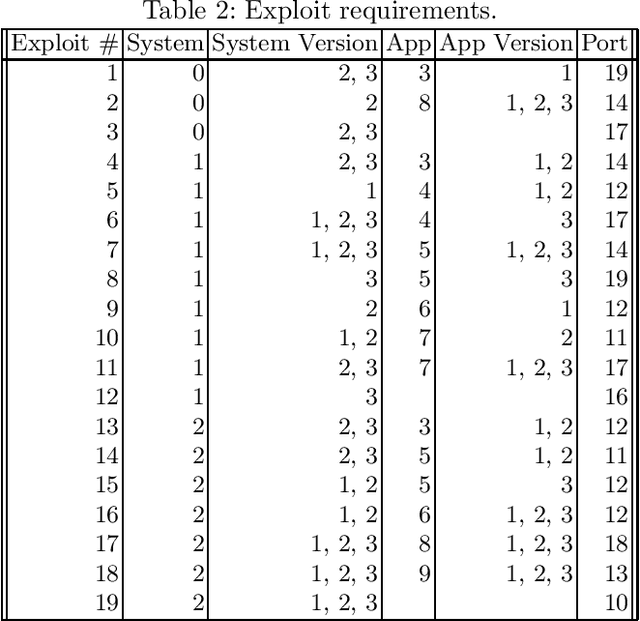
Deception is a crucial tool in the cyberdefence repertoire, enabling defenders to leverage their informational advantage to reduce the likelihood of successful attacks. One way deception can be employed is through obscuring, or masking, some of the information about how systems are configured, increasing attacker's uncertainty about their targets. We present a novel game-theoretic model of the resulting defender-attacker interaction, where the defender chooses a subset of attributes to mask, while the attacker responds by choosing an exploit to execute. The strategies of both players have combinatorial structure with complex informational dependencies, and therefore even representing these strategies is not trivial. First, we show that the problem of computing an equilibrium of the resulting zero-sum defender-attacker game can be represented as a linear program with a combinatorial number of system configuration variables and constraints, and develop a constraint generation approach for solving this problem. Next, we present a novel highly scalable approach for approximately solving such games by representing the strategies of both players as neural networks. The key idea is to represent the defender's mixed strategy using a deep neural network generator, and then using alternating gradient-descent-ascent algorithm, analogous to the training of Generative Adversarial Networks. Our experiments, as well as a case study, demonstrate the efficacy of the proposed approach.
Understanding Adversarial Examples Through Deep Neural Network's Response Surface and Uncertainty Regions
Jun 30, 2021

Deep neural network (DNN) is a popular model implemented in many systems to handle complex tasks such as image classification, object recognition, natural language processing etc. Consequently DNN structural vulnerabilities become part of the security vulnerabilities in those systems. In this paper we study the root cause of DNN adversarial examples. We examine the DNN response surface to understand its classification boundary. Our study reveals the structural problem of DNN classification boundary that leads to the adversarial examples. Existing attack algorithms can generate from a handful to a few hundred adversarial examples given one clean image. We show there are infinitely many adversarial images given one clean sample, all within a small neighborhood of the clean sample. We then define DNN uncertainty regions and show transferability of adversarial examples is not universal. We also argue that generalization error, the large sample theoretical guarantee established for DNN, cannot adequately capture the phenomenon of adversarial examples. We need new theory to measure DNN robustness.
Pareto GAN: Extending the Representational Power of GANs to Heavy-Tailed Distributions
Jan 22, 2021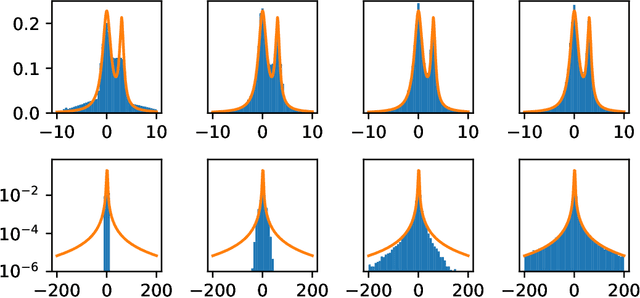
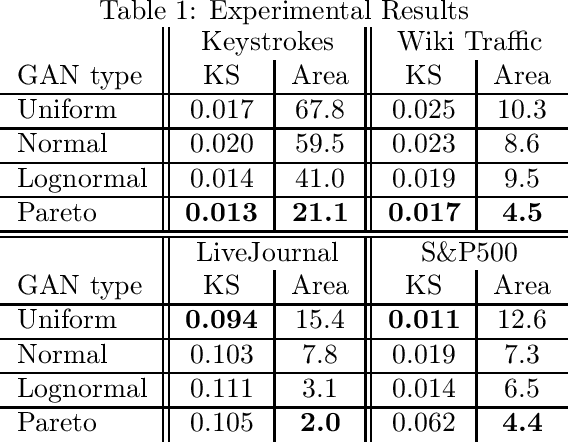
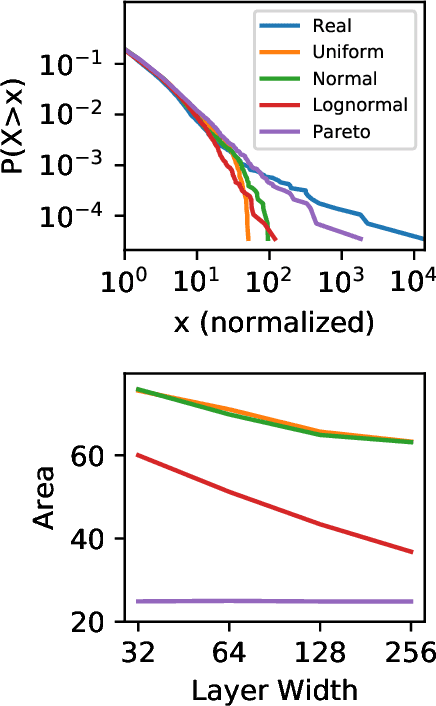
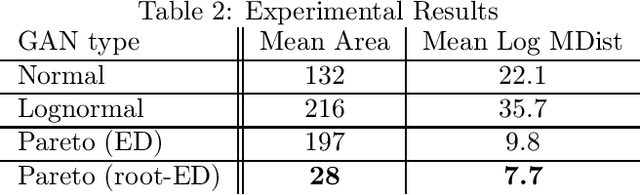
Generative adversarial networks (GANs) are often billed as "universal distribution learners", but precisely what distributions they can represent and learn is still an open question. Heavy-tailed distributions are prevalent in many different domains such as financial risk-assessment, physics, and epidemiology. We observe that existing GAN architectures do a poor job of matching the asymptotic behavior of heavy-tailed distributions, a problem that we show stems from their construction. Additionally, when faced with the infinite moments and large distances between outlier points that are characteristic of heavy-tailed distributions, common loss functions produce unstable or near-zero gradients. We address these problems with the Pareto GAN. A Pareto GAN leverages extreme value theory and the functional properties of neural networks to learn a distribution that matches the asymptotic behavior of the marginal distributions of the features. We identify issues with standard loss functions and propose the use of alternative metric spaces that enable stable and efficient learning. Finally, we evaluate our proposed approach on a variety of heavy-tailed datasets.
Game-Theoretic and Machine Learning-based Approaches for Defensive Deception: A Survey
Jan 21, 2021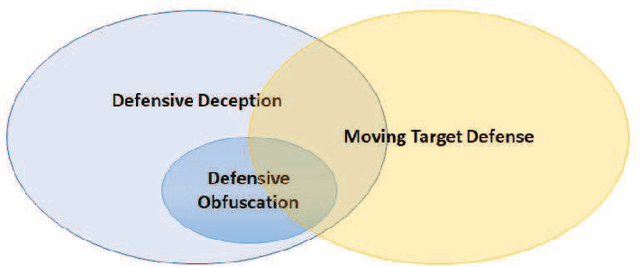
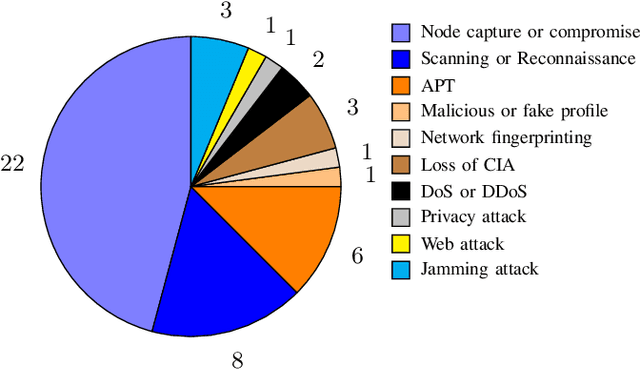
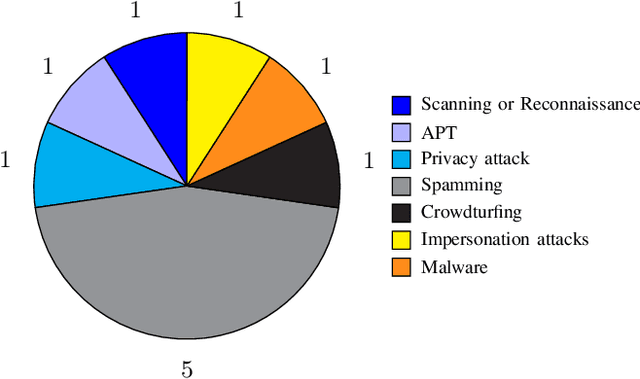
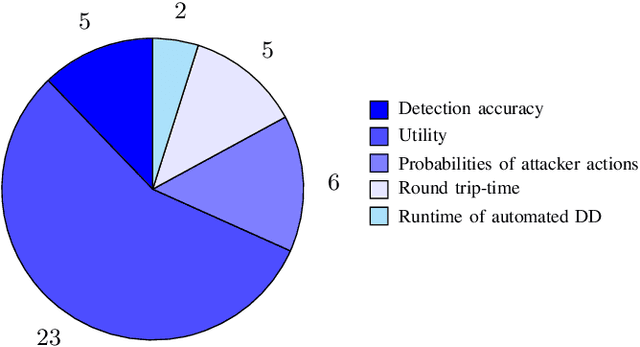
Defensive deception is a promising approach for cyberdefense. Although defensive deception is increasingly popular in the research community, there has not been a systematic investigation of its key components, the underlying principles, and its tradeoffs in various problem settings. This survey paper focuses on defensive deception research centered on game theory and machine learning, since these are prominent families of artificial intelligence approaches that are widely employed in defensive deception. This paper brings forth insights, lessons, and limitations from prior work. It closes with an outline of some research directions to tackle major gaps in current defensive deception research.
Learning and Planning in Feature Deception Games
May 13, 2019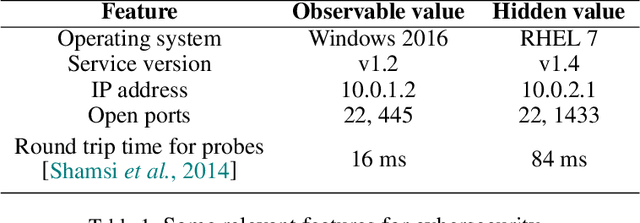
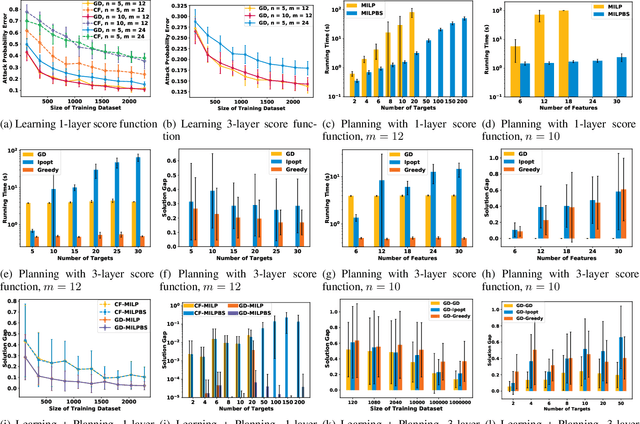
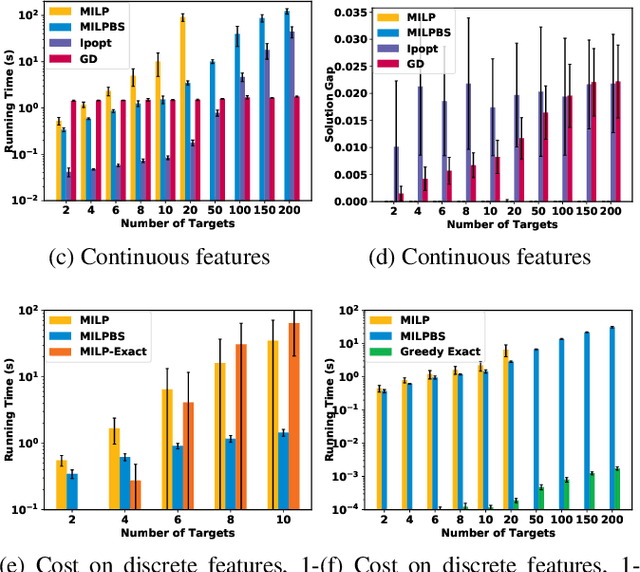

Today's high-stakes adversarial interactions feature attackers who constantly breach the ever-improving security measures. Deception mitigates the defender's loss by misleading the attacker to make suboptimal decisions. In order to formally reason about deception, we introduce the feature deception game (FDG), a domain-independent game-theoretic model and present a learning and planning framework. We make the following contributions. (1) We show that we can uniformly learn the adversary's preferences using data from a modest number of deception strategies. (2) We propose an approximation algorithm for finding the optimal deception strategy and show that the problem is NP-hard. (3) We perform extensive experiments to empirically validate our methods and results.