 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Fast and Accurate Neutral Atom Readout through Image Denoising
Oct 29, 2025



Neutral atom quantum computers hold promise for scaling up to hundreds of thousands of qubits, but their progress is constrained by slow qubit readout. Measuring qubits currently takes milliseconds-much longer than the underlying quantum gate operations-making readout the primary bottleneck in deploying quantum error correction. Because each round of QEC depends on measurement, long readout times increase cycle duration and slow down program execution. Reducing the readout duration speeds up cycles and reduces decoherence errors that accumulate while qubits idle, but it also lowers the number of collected photons, making measurements noisier and more error-prone. This tradeoff leaves neutral atom systems stuck between slow but accurate readout and fast but unreliable readout. We show that image denoising can resolve this tension. Our framework, GANDALF, uses explicit denoising using image translation to reconstruct clear signals from short, low-photon measurements, enabling reliable classification at up to 1.6x shorter readout times. Combined with lightweight classifiers and a pipelined readout design, our approach both reduces logical error rate by up to 35x and overall QEC cycle time up to 1.77x compared to state-of-the-art CNN-based readout for Cesium (Cs) Neutral Atom arrays.
Color Overmodification Emerges from Data-Driven Learning and Pragmatic Reasoning
May 18, 2022Speakers' referential expressions often depart from communicative ideals in ways that help illuminate the nature of pragmatic language use. Patterns of overmodification, in which a speaker uses a modifier that is redundant given their communicative goal, have proven especially informative in this regard. It seems likely that these patterns are shaped by the environment a speaker is exposed to in complex ways. Unfortunately, systematically manipulating these factors during human language acquisition is impossible. In this paper, we propose to address this limitation by adopting neural networks (NN) as learning agents. By systematically varying the environments in which these agents are trained, while keeping the NN architecture constant, we show that overmodification is more likely with environmental features that are infrequent or salient. We show that these findings emerge naturally in the context of a probabilistic model of pragmatic communication.
A Hybrid Approach to Word Sense Disambiguation Combining Supervised and Unsupervised Learning
Nov 19, 2015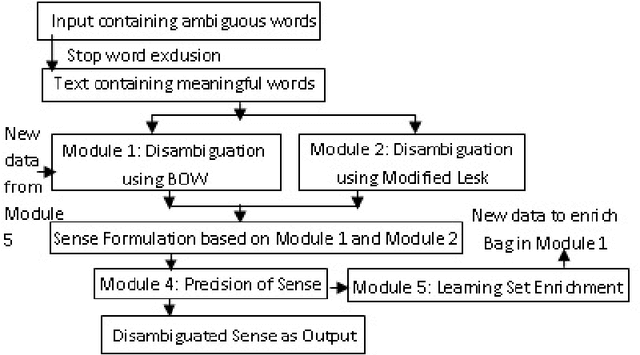
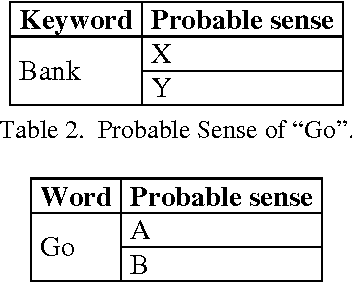
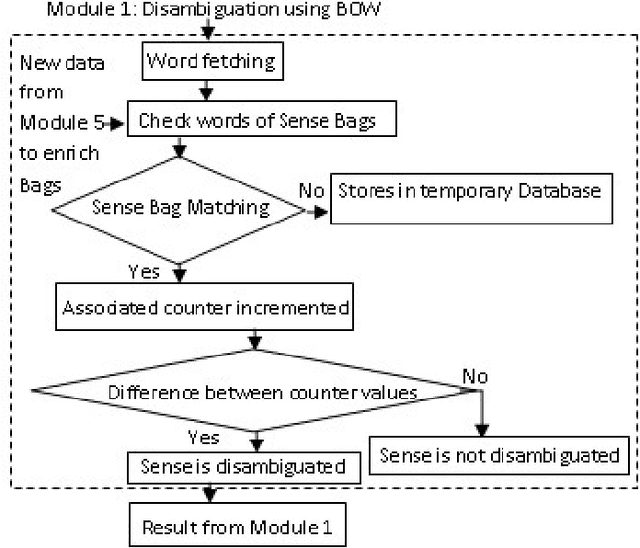
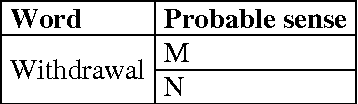
In this paper, we are going to find meaning of words based on distinct situations. Word Sense Disambiguation is used to find meaning of words based on live contexts using supervised and unsupervised approaches. Unsupervised approaches use online dictionary for learning, and supervised approaches use manual learning sets. Hand tagged data are populated which might not be effective and sufficient for learning procedure. This limitation of information is main flaw of the supervised approach. Our proposed approach focuses to overcome the limitation using learning set which is enriched in dynamic way maintaining new data. Trivial filtering method is utilized to achieve appropriate training data. We introduce a mixed methodology having Modified Lesk approach and Bag-of-Words having enriched bags using learning methods. Our approach establishes the superiority over individual Modified Lesk and Bag-of-Words approaches based on experimentation.