 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity Matters: Rethinking the Latent Space for Generative Modeling
Jul 17, 2023In generative modeling, numerous successful approaches leverage a low-dimensional latent space, e.g., Stable Diffusion models the latent space induced by an encoder and generates images through a paired decoder. Although the selection of the latent space is empirically pivotal, determining the optimal choice and the process of identifying it remain unclear. In this study, we aim to shed light on this under-explored topic by rethinking the latent space from the perspective of model complexity. Our investigation starts with the classic generative adversarial networks (GANs). Inspired by the GAN training objective, we propose a novel "distance" between the latent and data distributions, whose minimization coincides with that of the generator complexity. The minimizer of this distance is characterized as the optimal data-dependent latent that most effectively capitalizes on the generator's capacity. Then, we consider parameterizing such a latent distribution by an encoder network and propose a two-stage training strategy called Decoupled Autoencoder (DAE), where the encoder is only updated in the first stage with an auxiliary decoder and then frozen in the second stage while the actual decoder is being trained. DAE can improve the latent distribution and as a result, improve the generative performance. Our theoretical analyses are corroborated by comprehensive experiments on various models such as VQGAN and Diffusion Transformer, where our modifications yield significant improvements in sample quality with decreased model complexity.
BiRP: Learning Robot Generalized Bimanual Coordination using Relative Parameterization Method on Human Demonstration
Jul 12, 2023Human bimanual manipulation can perform more complex tasks than a simple combination of two single arms, which is credited to the spatio-temporal coordination between the arms. However, the description of bimanual coordination is still an open topic in robotics. This makes it difficult to give an explainable coordination paradigm, let alone applied to robotics. In this work, we divide the main bimanual tasks in human daily activities into two types: leader-follower and synergistic coordination. Then we propose a relative parameterization method to learn these types of coordination from human demonstration. It represents coordination as Gaussian mixture models from bimanual demonstration to describe the change in the importance of coordination throughout the motions by probability. The learned coordinated representation can be generalized to new task parameters while ensuring spatio-temporal coordination. We demonstrate the method using synthetic motions and human demonstration data and deploy it to a humanoid robot to perform a generalized bimanual coordination motion. We believe that this easy-to-use bimanual learning from demonstration (LfD) method has the potential to be used as a data augmentation plugin for robot large manipulation model training. The corresponding codes are open-sourced in https://github.com/Skylark0924/Rofunc.
SoftGPT: Learn Goal-oriented Soft Object Manipulation Skills by Generative Pre-trained Heterogeneous Graph Transformer
Jun 22, 2023



Soft object manipulation tasks in domestic scenes pose a significant challenge for existing robotic skill learning techniques due to their complex dynamics and variable shape characteristics. Since learning new manipulation skills from human demonstration is an effective way for robot applications, developing prior knowledge of the representation and dynamics of soft objects is necessary. In this regard, we propose a pre-trained soft object manipulation skill learning model, namely SoftGPT, that is trained using large amounts of exploration data, consisting of a three-dimensional heterogeneous graph representation and a GPT-based dynamics model. For each downstream task, a goal-oriented policy agent is trained to predict the subsequent actions, and SoftGPT generates the consequences of these actions. Integrating these two approaches establishes a thinking process in the robot's mind that provides rollout for facilitating policy learning. Our results demonstrate that leveraging prior knowledge through this thinking process can efficiently learn various soft object manipulation skills, with the potential for direct learning from human demonstrations.
Deep learning radiomics for assessment of gastroesophageal varices in people with compensated advanced chronic liver disease
Jun 13, 2023



Objective: Bleeding from gastroesophageal varices (GEV) is a medical emergency associated with high mortality. We aim to construct an artificial intelligence-based model of two-dimensional shear wave elastography (2D-SWE) of the liver and spleen to precisely assess the risk of GEV and high-risk gastroesophageal varices (HRV). Design: A prospective multicenter study was conducted in patients with compensated advanced chronic liver disease. 305 patients were enrolled from 12 hospitals, and finally 265 patients were included, with 1136 liver stiffness measurement (LSM) images and 1042 spleen stiffness measurement (SSM) images generated by 2D-SWE. We leveraged deep learning methods to uncover associations between image features and patient risk, and thus conducted models to predict GEV and HRV. Results: A multi-modality Deep Learning Risk Prediction model (DLRP) was constructed to assess GEV and HRV, based on LSM and SSM images, and clinical information. Validation analysis revealed that the AUCs of DLRP were 0.91 for GEV (95% CI 0.90 to 0.93, p < 0.05) and 0.88 for HRV (95% CI 0.86 to 0.89, p < 0.01), which were significantly and robustly better than canonical risk indicators, including the value of LSM and SSM. Moreover, DLPR was better than the model using individual parameters, including LSM and SSM images. In HRV prediction, the 2D-SWE images of SSM outperform LSM (p < 0.01). Conclusion: DLRP shows excellent performance in predicting GEV and HRV over canonical risk indicators LSM and SSM. Additionally, the 2D-SWE images of SSM provided more information for better accuracy in predicting HRV than the LSM.
Modeling Viral Information Spreading via Directed Acyclic Graph Diffusion
May 09, 2023



Viral information like rumors or fake news is spread over a communication network like a virus infection in a unidirectional manner: entity $i$ conveys information to a neighbor $j$, resulting in two equally informed (infected) parties. Existing graph diffusion works focus only on bidirectional diffusion on an undirected graph. Instead, we propose a new directed acyclic graph (DAG) diffusion model to estimate the probability $x_i(t)$ of node $i$'s infection at time $t$ given a source node $s$, where $x_i(\infty)~=~1$. Specifically, given an undirected positive graph modeling node-to-node communication, we first compute its graph embedding: a latent coordinate for each node in an assumed low-dimensional manifold space from extreme eigenvectors via LOBPCG. Next, we construct a DAG based on Euclidean distances between latent coordinates. Spectrally, we prove that the asymmetric DAG Laplacian matrix contains real non-negative eigenvalues, and that the DAG diffusion converges to the all-infection vector $\x(\infty) = \1$ as $t \rightarrow \infty$. Simulation experiments show that our proposed DAG diffusion accurately models viral information spreading over a variety of graph structures at different time instants.
Mixline: A Hybrid Reinforcement Learning Framework for Long-horizon Bimanual Coffee Stirring Task
Nov 04, 2022Bimanual activities like coffee stirring, which require coordination of dual arms, are common in daily life and intractable to learn by robots. Adopting reinforcement learning to learn these tasks is a promising topic since it enables the robot to explore how dual arms coordinate together to accomplish the same task. However, this field has two main challenges: coordination mechanism and long-horizon task decomposition. Therefore, we propose the Mixline method to learn sub-tasks separately via the online algorithm and then compose them together based on the generated data through the offline algorithm. We constructed a learning environment based on the GPU-accelerated Isaac Gym. In our work, the bimanual robot successfully learned to grasp, hold and lift the spoon and cup, insert them together and stir the coffee. The proposed method has the potential to be extended to other long-horizon bimanual tasks.
* 10 pages, conference
Calibrationless Reconstruction of Uniformly-Undersampled Multi-Channel MR Data with Deep Learning Estimated ESPIRiT Maps
Oct 27, 2022Purpose: To develop a truly calibrationless reconstruction method that derives ESPIRiT maps from uniformly-undersampled multi-channel MR data by deep learning. Methods: ESPIRiT, one commonly used parallel imaging reconstruction technique, forms the images from undersampled MR k-space data using ESPIRiT maps that effectively represents coil sensitivity information. Accurate ESPIRiT map estimation requires quality coil sensitivity calibration or autocalibration data. We present a U-Net based deep learning model to estimate the multi-channel ESPIRiT maps directly from uniformly-undersampled multi-channel multi-slice MR data. The model is trained using fully-sampled multi-slice axial brain datasets from the same MR receiving coil system. To utilize subject-coil geometric parameters available for each dataset, the training imposes a hybrid loss on ESPIRiT maps at the original locations as well as their corresponding locations within the standard reference multi-slice axial stack. The performance of the approach was evaluated using publicly available T1-weighed brain and cardiac data. Results: The proposed model robustly predicted multi-channel ESPIRiT maps from uniformly-undersampled k-space data. They were highly comparable to the reference ESPIRiT maps directly computed from 24 consecutive central k-space lines. Further, they led to excellent ESPIRiT reconstruction performance even at high acceleration, exhibiting a similar level of errors and artifacts to that by using reference ESPIRiT maps. Conclusion: A new deep learning approach is developed to estimate ESPIRiT maps directly from uniformly-undersampled MR data. It presents a general strategy for calibrationless parallel imaging reconstruction through learning from coil and protocol specific data.
Dual-Curriculum Teacher for Domain-Inconsistent Object Detection in Autonomous Driving
Oct 17, 2022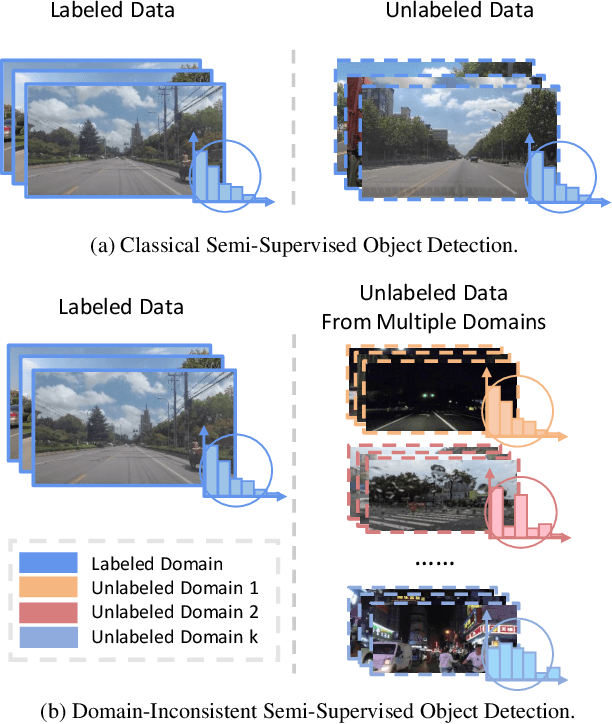
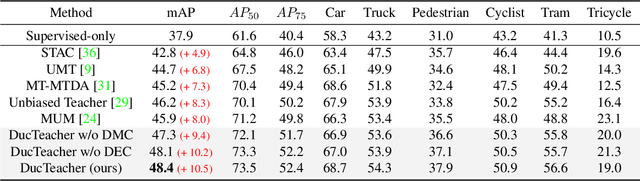
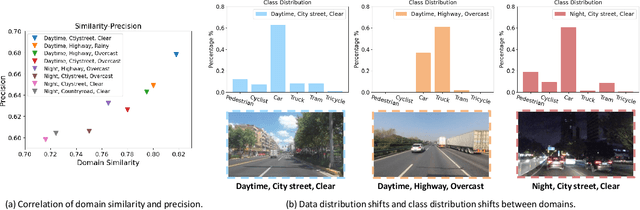
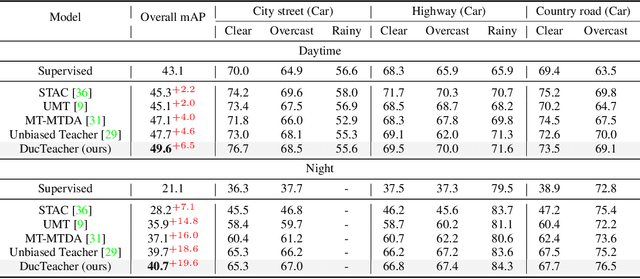
Object detection for autonomous vehicles has received increasing attention in recent years, where labeled data are often expensive while unlabeled data can be collected readily, calling for research on semi-supervised learning for this area. Existing semi-supervised object detection (SSOD) methods usually assume that the labeled and unlabeled data come from the same data distribution. In autonomous driving, however, data are usually collected from different scenarios, such as different weather conditions or different times in a day. Motivated by this, we study a novel but challenging domain inconsistent SSOD problem. It involves two kinds of distribution shifts among different domains, including (1) data distribution discrepancy, and (2) class distribution shifts, making existing SSOD methods suffer from inaccurate pseudo-labels and hurting model performance. To address this problem, we propose a novel method, namely Dual-Curriculum Teacher (DucTeacher). Specifically, DucTeacher consists of two curriculums, i.e., (1) domain evolving curriculum seeks to learn from the data progressively to handle data distribution discrepancy by estimating the similarity between domains, and (2) distribution matching curriculum seeks to estimate the class distribution for each unlabeled domain to handle class distribution shifts. In this way, DucTeacher can calibrate biased pseudo-labels and handle the domain-inconsistent SSOD problem effectively. DucTeacher shows its advantages on SODA10M, the largest public semi-supervised autonomous driving dataset, and COCO, a widely used SSOD benchmark. Experiments show that DucTeacher achieves new state-of-the-art performance on SODA10M with 2.2 mAP improvement and on COCO with 0.8 mAP improvement.
6DOF Pose Estimation of a 3D Rigid Object based on Edge-enhanced Point Pair Features
Sep 17, 2022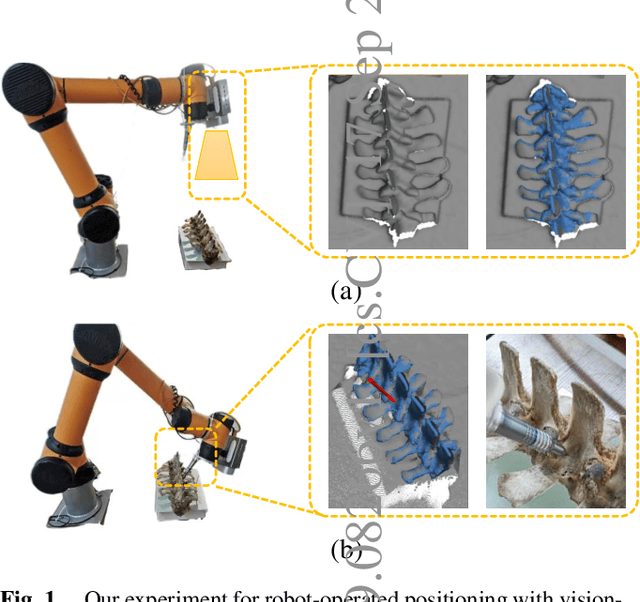
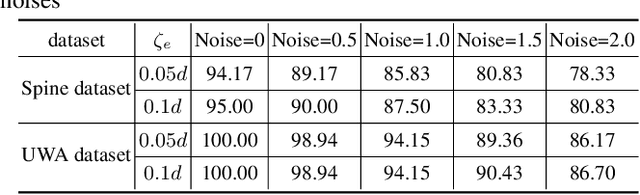
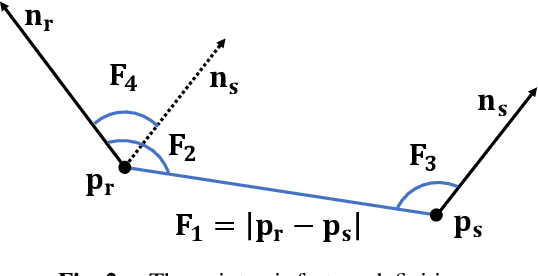
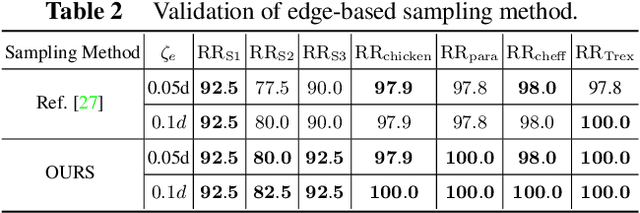
The point pair feature (PPF) is widely used for 6D pose estimation. In this paper, we propose an efficient 6D pose estimation method based on the PPF framework. We introduce a well-targeted down-sampling strategy that focuses more on edge area for efficient feature extraction of complex geometry. A pose hypothesis validation approach is proposed to resolve the symmetric ambiguity by calculating edge matching degree. We perform evaluations on two challenging datasets and one real-world collected dataset, demonstrating the superiority of our method on pose estimation of geometrically complex, occluded, symmetrical objects. We further validate our method by applying it to simulated punctures.
Less is More: Adaptive Curriculum Learning for Thyroid Nodule Diagnosis
Jul 02, 2022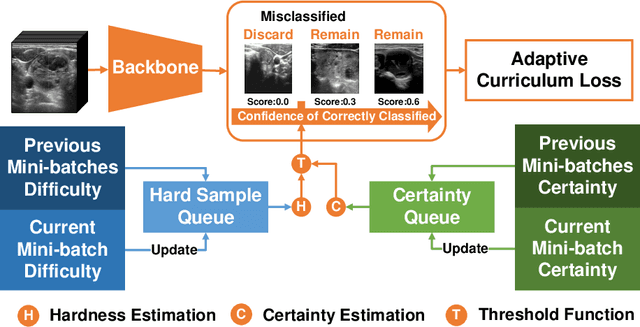
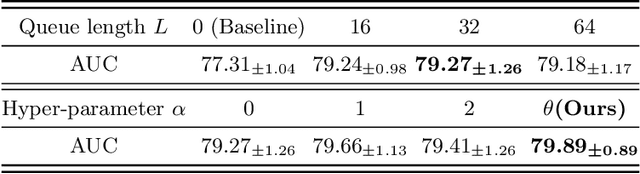
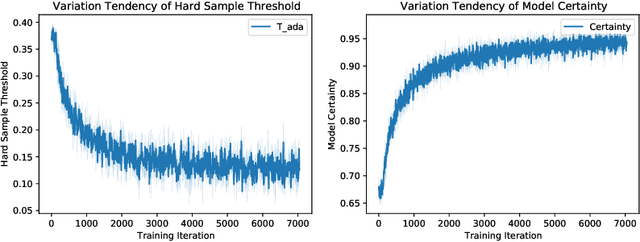
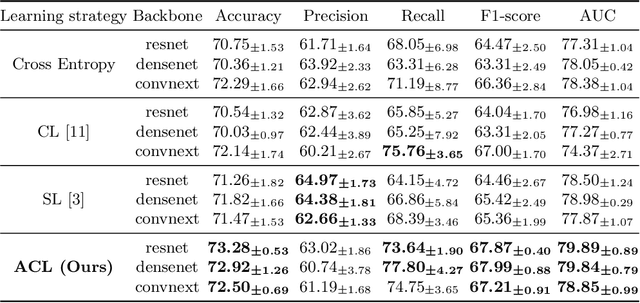
Thyroid nodule classification aims at determining whether the nodule is benign or malignant based on a given ultrasound image. However, the label obtained by the cytological biopsy which is the golden standard in clinical medicine is not always consistent with the ultrasound imaging TI-RADS criteria. The information difference between the two causes the existing deep learning-based classification methods to be indecisive. To solve the Inconsistent Label problem, we propose an Adaptive Curriculum Learning (ACL) framework, which adaptively discovers and discards the samples with inconsistent labels. Specifically, ACL takes both hard sample and model certainty into account, and could accurately determine the threshold to distinguish the samples with Inconsistent Label. Moreover, we contribute TNCD: a Thyroid Nodule Classification Dataset to facilitate future related research on the thyroid nodules. Extensive experimental results on TNCD based on three different backbone networks not only demonstrate the superiority of our method but also prove that the less-is-more principle which strategically discards the samples with Inconsistent Label could yield performance gains. Source code and data are available at https://github.com/chenghui-666/ACL/.