 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-supervised Approach for Adversarial Robustness
Jun 08, 2020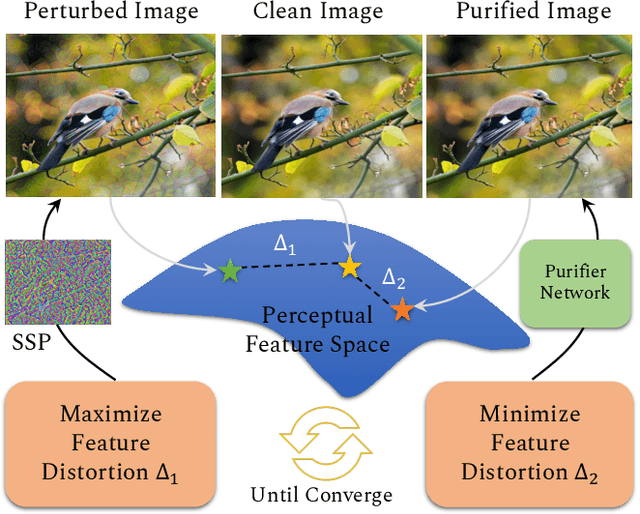
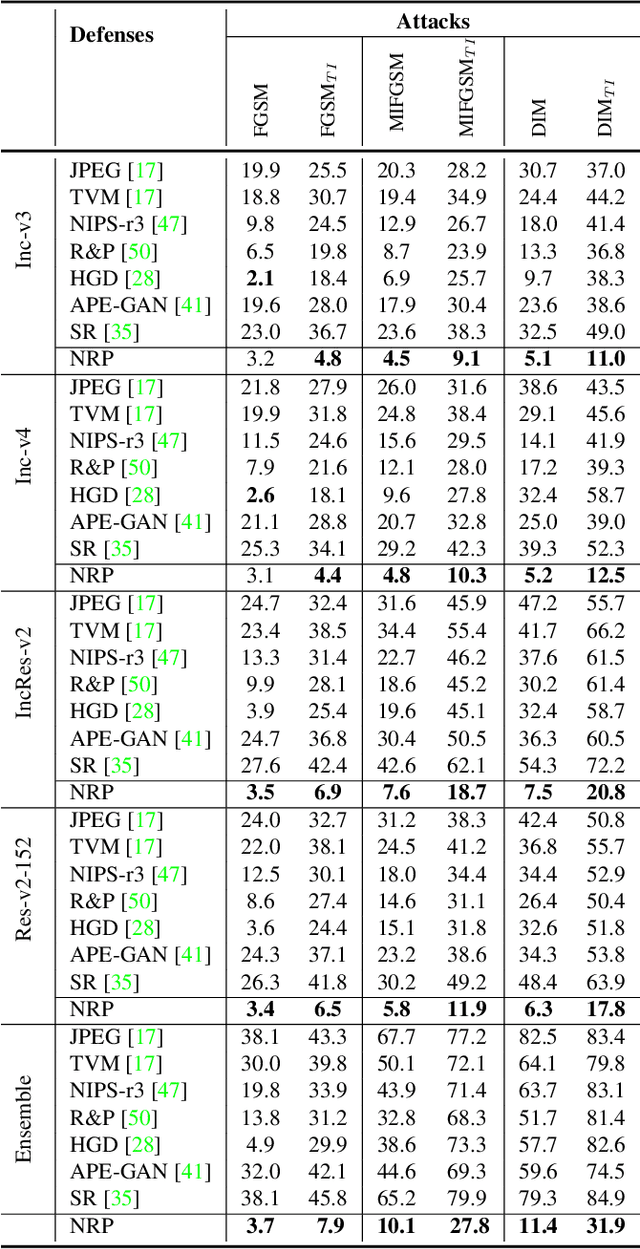
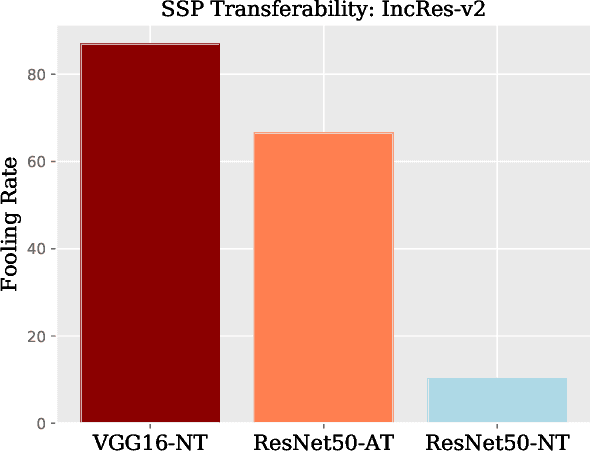
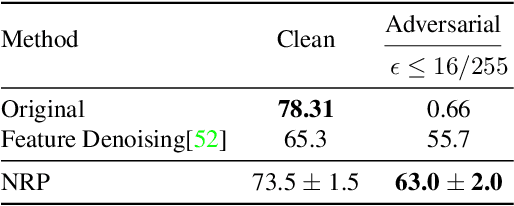
Adversarial examples can cause catastrophic mistakes in Deep Neural Network (DNNs) based vision systems e.g., for classification, segmentation and object detection. The vulnerability of DNNs against such attacks can prove a major roadblock towards their real-world deployment. Transferability of adversarial examples demand generalizable defenses that can provide cross-task protection. Adversarial training that enhances robustness by modifying target model's parameters lacks such generalizability. On the other hand, different input processing based defenses fall short in the face of continuously evolving attacks. In this paper, we take the first step to combine the benefits of both approaches and propose a self-supervised adversarial training mechanism in the input space. By design, our defense is a generalizable approach and provides significant robustness against the \textbf{unseen} adversarial attacks (\eg by reducing the success rate of translation-invariant \textbf{ensemble} attack from 82.6\% to 31.9\% in comparison to previous state-of-the-art). It can be deployed as a plug-and-play solution to protect a variety of vision systems, as we demonstrate for the case of classification, segmentation and detection. Code is available at: {\small\url{https://github.com/Muzammal-Naseer/NRP}}.
Identity Enhanced Residual Image Denoising
Apr 26, 2020
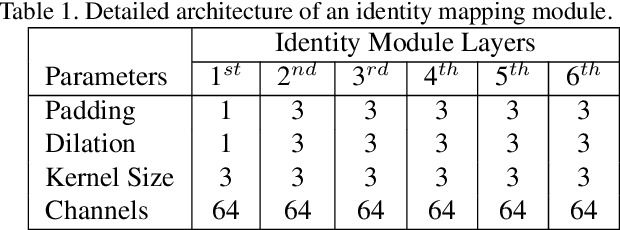

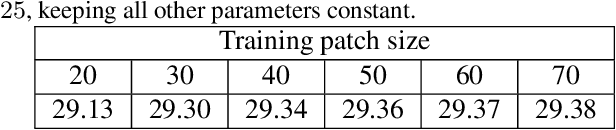
We propose to learn a fully-convolutional network model that consists of a Chain of Identity Mapping Modules and residual on the residual architecture for image denoising. Our network structure possesses three distinctive features that are important for the noise removal task. Firstly, each unit employs identity mappings as the skip connections and receives pre-activated input to preserve the gradient magnitude propagated in both the forward and backward directions. Secondly, by utilizing dilated kernels for the convolution layers in the residual branch, each neuron in the last convolution layer of each module can observe the full receptive field of the first layer. Lastly, we employ the residual on the residual architecture to ease the propagation of the high-level information. Contrary to current state-of-the-art real denoising networks, we also present a straightforward and single-stage network for real image denoising. The proposed network produces remarkably higher numerical accuracy and better visual image quality than the classical state-of-the-art and CNN algorithms when being evaluated on the three conventional benchmark and three real-world datasets.
See More, Know More: Unsupervised Video Object Segmentation with Co-Attention Siamese Networks
Jan 19, 2020
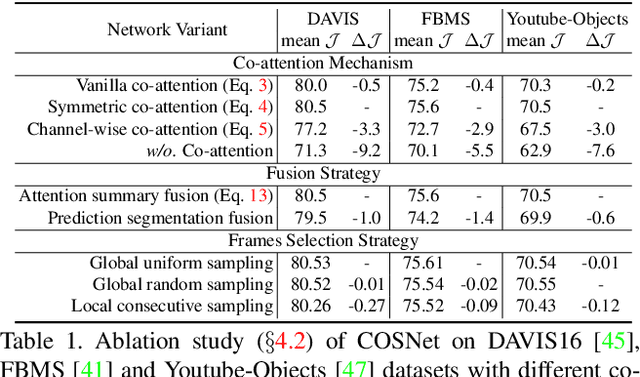
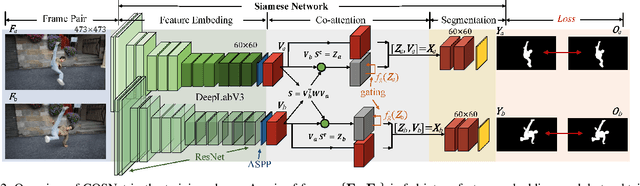
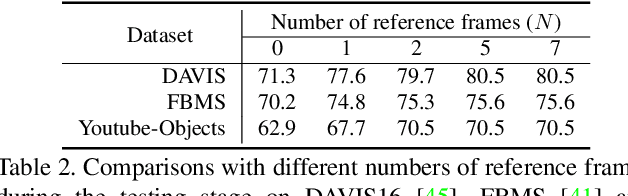
We introduce a novel network, called CO-attention Siamese Network (COSNet), to address the unsupervised video object segmentation task from a holistic view. We emphasize the importance of inherent correlation among video frames and incorporate a global co-attention mechanism to improve further the state-of-the-art deep learning based solutions that primarily focus on learning discriminative foreground representations over appearance and motion in short-term temporal segments. The co-attention layers in our network provide efficient and competent stages for capturing global correlations and scene context by jointly computing and appending co-attention responses into a joint feature space. We train COSNet with pairs of video frames, which naturally augments training data and allows increased learning capacity. During the segmentation stage, the co-attention model encodes useful information by processing multiple reference frames together, which is leveraged to infer the frequently reappearing and salient foreground objects better. We propose a unified and end-to-end trainable framework where different co-attention variants can be derived for mining the rich context within videos. Our extensive experiments over three large benchmarks manifest that COSNet outperforms the current alternatives by a large margin.
* CVPR2019. Weblink: https://github.com/carrierlxk/COSNet
Image Segmentation Using Deep Learning: A Survey
Jan 18, 2020
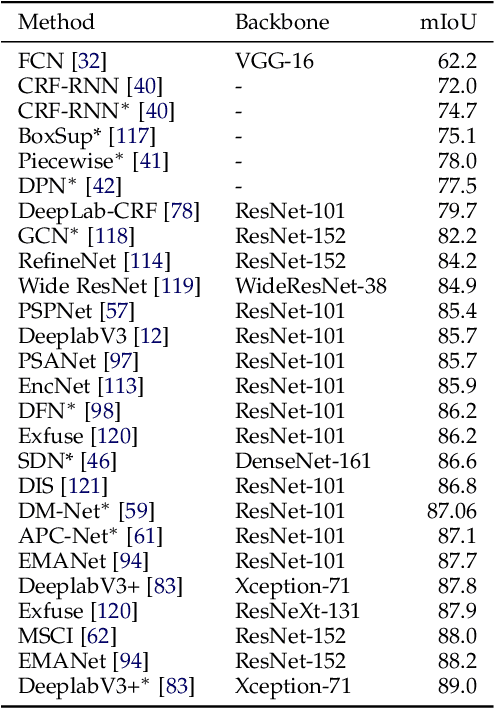
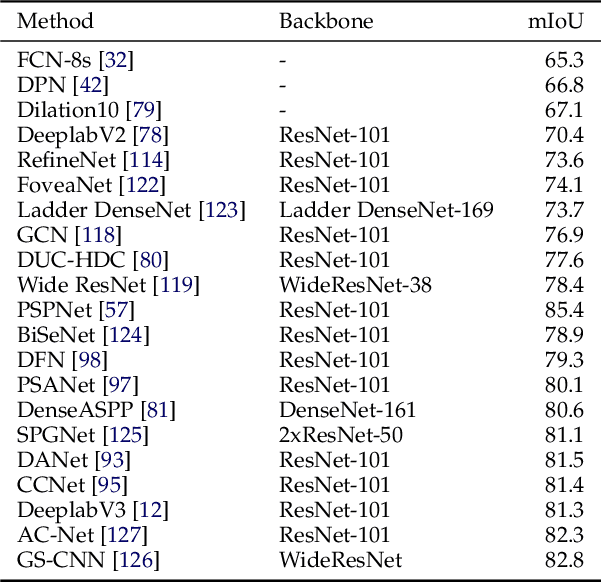
Image segmentation is a key topic in image processing and computer vision with applications such as scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality, and image compression, among many others. Various algorithms for image segmentation have been developed in the literature. Recently, due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of works aimed at developing image segmentation approaches using deep learning models. In this survey, we provide a comprehensive review of the literature at the time of this writing, covering a broad spectrum of pioneering works for semantic and instance-level segmentation, including fully convolutional pixel-labeling networks, encoder-decoder architectures, multi-scale and pyramid based approaches, recurrent networks, visual attention models, and generative models in adversarial settings. We investigate the similarity, strengths and challenges of these deep learning models, examine the most widely used datasets, report performances, and discuss promising future research directions in this area.
Sparse Coding on Cascaded Residuals
Nov 07, 2019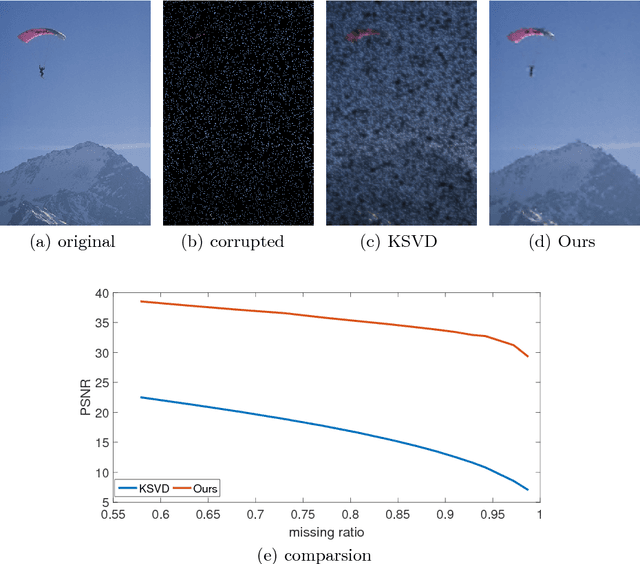
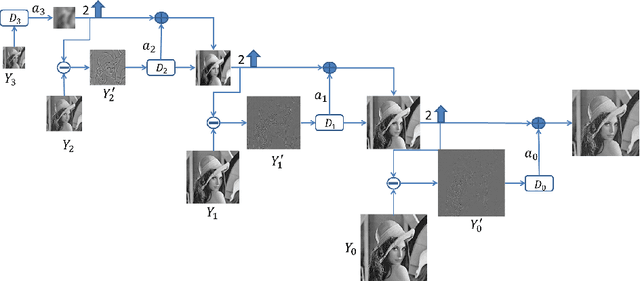
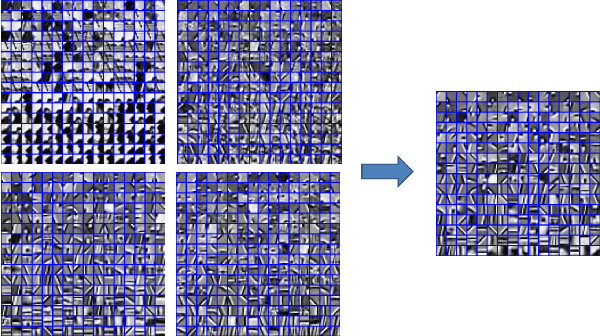
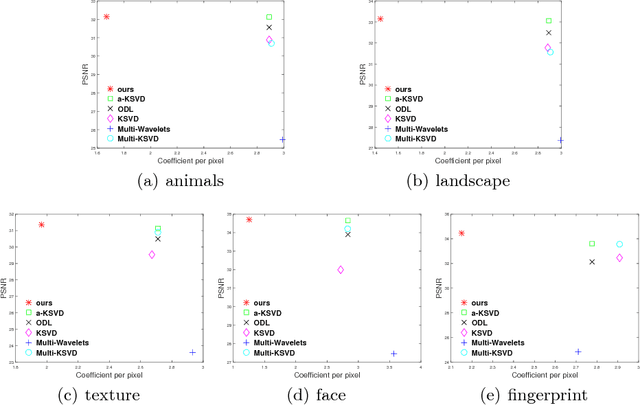
This paper seeks to combine dictionary learning and hierarchical image representation in a principled way. To make dictionary atoms capturing additional information from extended receptive fields and attain improved descriptive capacity, we present a two-pass multi-resolution cascade framework for dictionary learning and sparse coding. The cascade allows collaborative reconstructions at different resolutions using the same dimensional dictionary atoms. Our jointly learned dictionary comprises atoms that adapt to the information available at the coarsest layer where the support of atoms reaches their maximum range and the residual images where the supplementary details progressively refine the reconstruction objective. The residual at a layer is computed by the difference between the aggregated reconstructions of the previous layers and the downsampled original image at that layer. Our method generates more flexible and accurate representations using much less number of coefficients. Its computational efficiency stems from encoding at the coarsest resolution, which is minuscule, and encoding the residuals, which are relatively much sparse. Our extensive experiments on multiple datasets demonstrate that this new method is powerful in image coding, denoising, inpainting and artifact removal tasks outperforming the state-of-the-art techniques.
Component Attention Guided Face Super-Resolution Network: CAGFace
Oct 19, 2019
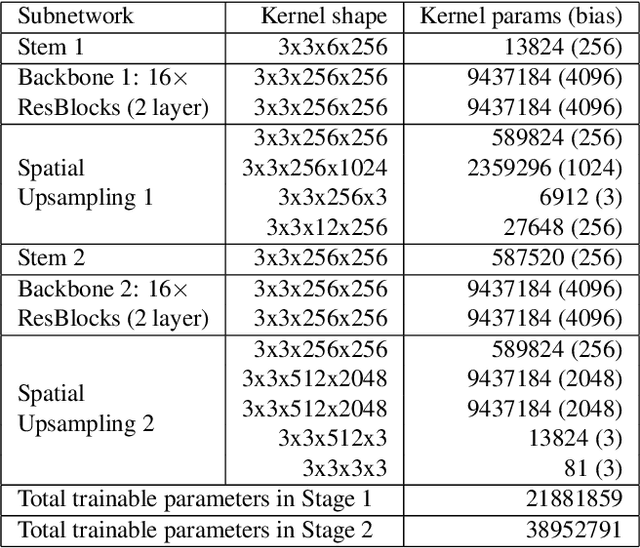
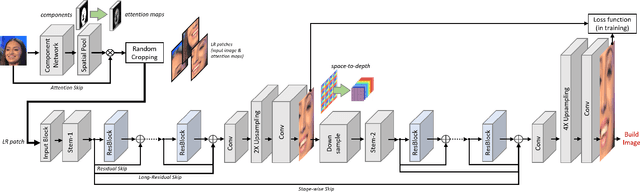
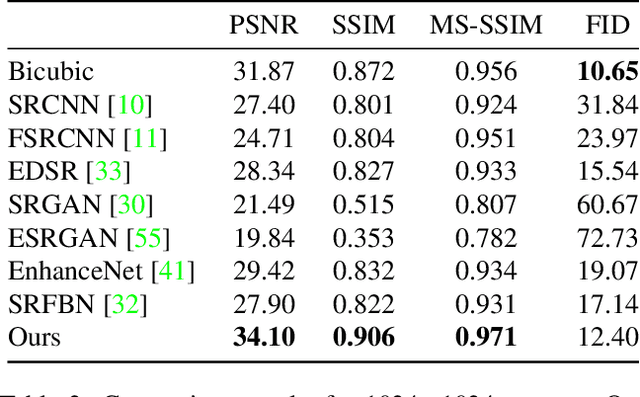
To make the best use of the underlying structure of faces, the collective information through face datasets and the intermediate estimates during the upsampling process, here we introduce a fully convolutional multi-stage neural network for 4$\times$ super-resolution for face images. We implicitly impose facial component-wise attention maps using a segmentation network to allow our network to focus on face-inherent patterns. Each stage of our network is composed of a stem layer, a residual backbone, and spatial upsampling layers. We recurrently apply stages to reconstruct an intermediate image, and then reuse its space-to-depth converted versions to bootstrap and enhance image quality progressively. Our experiments show that our face super-resolution method achieves quantitatively superior and perceptually pleasing results in comparison to state of the art.
Sketch-Specific Data Augmentation for Freehand Sketch Recognition
Oct 14, 2019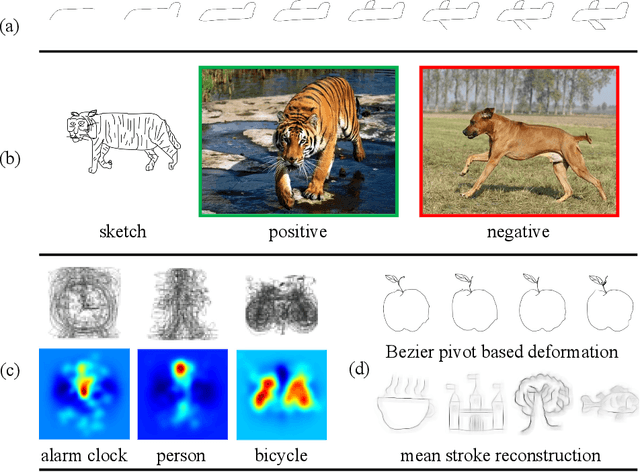
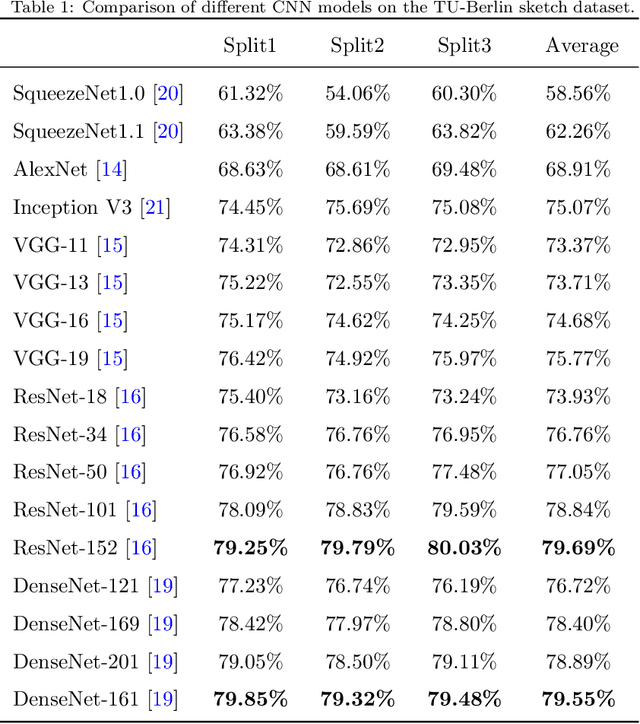
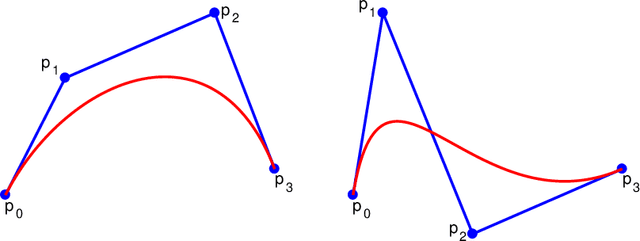
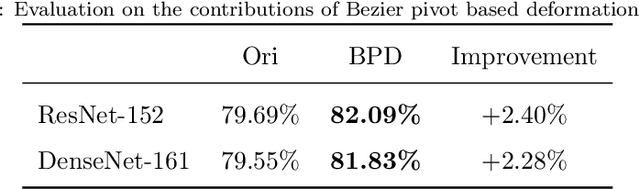
Sketch recognition remains a significant challenge due to the limited training data and the substantial intra-class variance of freehand sketches for the same object. Conventional methods for this task often rely on the availability of the temporal order of sketch strokes, additional cues acquired from different modalities and supervised augmentation of sketch datasets with real images, which also limit the applicability and feasibility of these methods in real scenarios. In this paper, we propose a novel sketch-specific data augmentation (SSDA) method that leverages the quantity and quality of the sketches automatically. From the aspect of quantity, we introduce a Bezier pivot based deformation (BPD) strategy to enrich the training data. Towards quality improvement, we present a mean stroke reconstruction (MSR) approach to generate a set of novel types of sketches with smaller intra-class variances. Both of these solutions are unrestricted from any multi-source data and temporal cues of sketches. Furthermore, we show that some recent deep convolutional neural network models that are trained on generic classes of real images can be better choices than most of the elaborate architectures that are designed explicitly for sketch recognition. As SSDA can be integrated with any convolutional neural networks, it has a distinct advantage over the existing methods. Our extensive experimental evaluations demonstrate that the proposed method achieves state-of-the-art results (84.27%) on the TU-Berlin dataset, outperforming the human performance by a remarkable 11.17% increase. We also present a new benchmark named Sketchy-R to facilitate future research in sketch recognition. Finally, more experiments show the practical value of our approach to the task of sketch-based image retrieval.
Joint Stereo Video Deblurring, Scene Flow Estimation and Moving Object Segmentation
Oct 06, 2019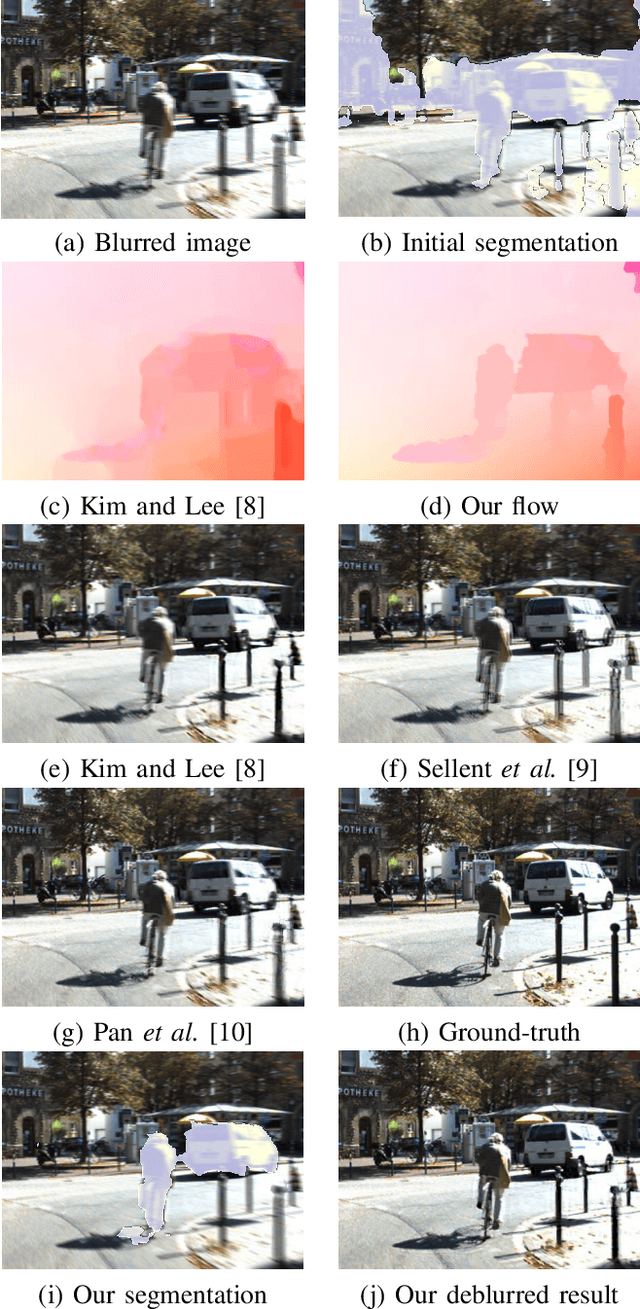
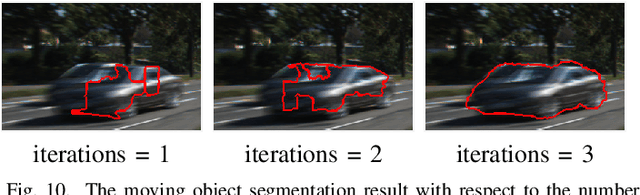


Stereo videos for the dynamic scenes often show unpleasant blurred effects due to the camera motion and the multiple moving objects with large depth variations. Given consecutive blurred stereo video frames, we aim to recover the latent clean images, estimate the 3D scene flow and segment the multiple moving objects. These three tasks have been previously addressed separately, which fail to exploit the internal connections among these tasks and cannot achieve optimality. In this paper, we propose to jointly solve these three tasks in a unified framework by exploiting their intrinsic connections. To this end, we represent the dynamic scenes with the piece-wise planar model, which exploits the local structure of the scene and expresses various dynamic scenes. Under our model, these three tasks are naturally connected and expressed as the parameter estimation of 3D scene structure and camera motion (structure and motion for the dynamic scenes). By exploiting the blur model constraint, the moving objects and the 3D scene structure, we reach an energy minimization formulation for joint deblurring, scene flow and segmentation. We evaluate our approach extensively on both synthetic datasets and publicly available real datasets with fast-moving objects, camera motion, uncontrolled lighting conditions and shadows. Experimental results demonstrate that our method can achieve significant improvement in stereo video deblurring, scene flow estimation and moving object segmentation, over state-of-the-art methods.
CoinNet: Deep Ancient Roman Republican Coin Classification via Feature Fusion and Attention
Aug 26, 2019
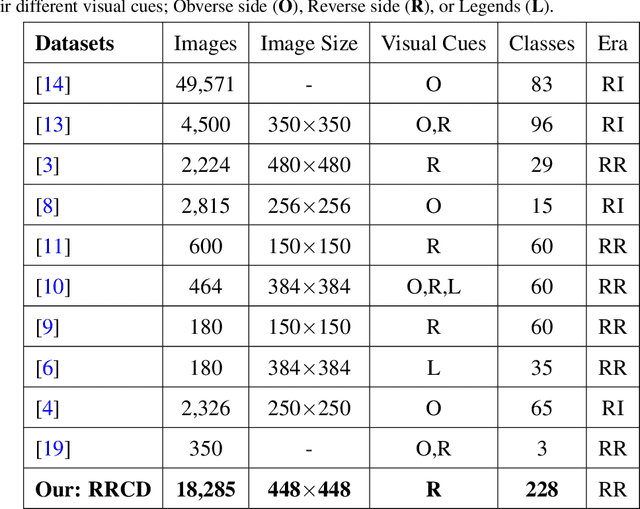
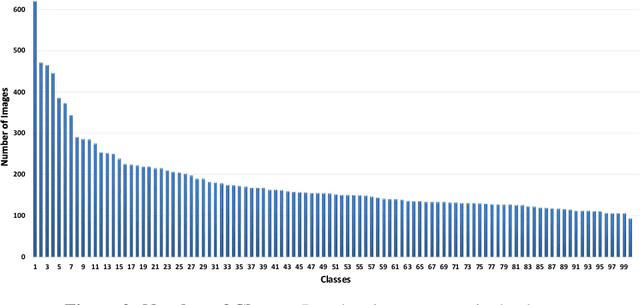
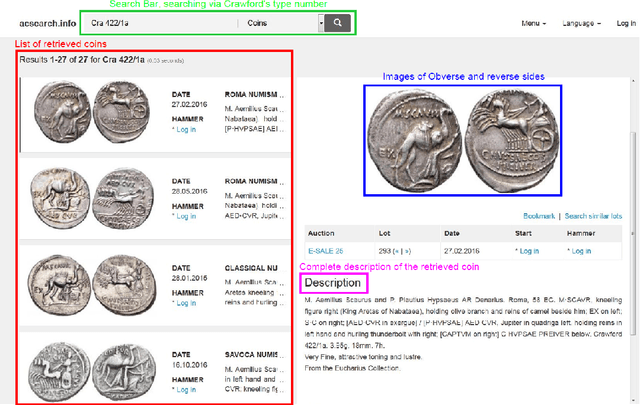
We perform classification of ancient Roman Republican coins via recognizing their reverse motifs where various objects, faces, scenes, animals, and buildings are minted along with legends. Most of these coins are eroded due to their age and varying degrees of preservation, thereby affecting their informative attributes for visual recognition. Changes in the positions of principal symbols on the reverse motifs also cause huge variations among the coin types. Lastly, in-plane orientations, uneven illumination, and a moderate background clutter further make the task of classification non-trivial and challenging. To this end, we present a novel network model, CoinNet, that employs compact bilinear pooling, residual groups, and feature attention layers. Furthermore, we gathered the largest and most diverse image dataset of the Roman Republican coins that contains more than 18,000 images belonging to 228 different reverse motifs. On this dataset, our model achieves a classification accuracy of more than \textbf{98\%} and outperforms the conventional bag-of-visual-words based approaches and more recent state-of-the-art deep learning methods. We also provide a detailed ablation study of our network and its generalization capability.
Cross-Domain Transferability of Adversarial Perturbations
Jun 10, 2019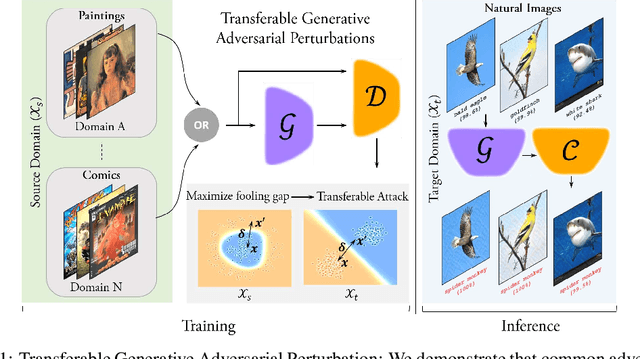
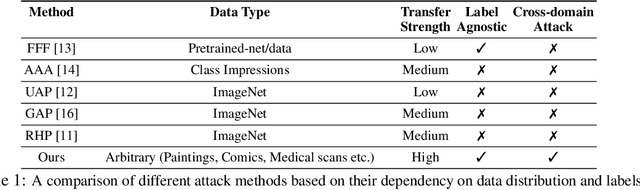
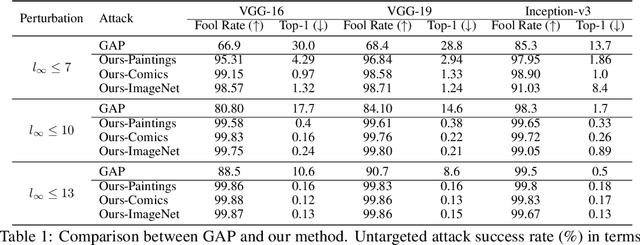

Adversarial examples reveal the blind spots of deep neural networks (DNNs) and represent a major concern for security-critical applications. The transferability of adversarial examples makes real-world attacks possible in black-box settings, where the attacker is forbidden to access the internal parameters of the model. The underlying assumption in most adversary generation methods, whether learning an instance-specific or an instance-agnostic perturbation, is the direct or indirect reliance on the original domain-specific data distribution. In this work, for the first time, we demonstrate the existence of domain-invariant adversaries, thereby showing common adversarial space among different datasets and models. To this end, we propose a framework capable of launching highly transferable attacks that crafts adversarial patterns to mislead networks trained on wholly different domains. For instance, an adversarial function learned on Paintings, Cartoons or Medical images can successfully perturb ImageNet samples to fool the classifier, with success rates as high as $\sim$99\% ($\ell_{\infty} \le 10$). The core of our proposed adversarial function is a generative network that is trained using a relativistic supervisory signal that enables domain-invariant perturbations. Our approach sets the new state-of-the-art for fooling rates, both under the white-box and black-box scenarios. Furthermore, despite being an instance-agnostic perturbation function, our attack outperforms the conventionally much stronger instance-specific attack methods.