 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded Structure Tensor Framework for Robust Identification of Heavily Occluded Baggage Items from Multi-Vendor X-ray Scans
Jan 21, 2020



In the last two decades, luggage scanning has globally become one of the prime aviation security concerns. Manual screening of the baggage items is a cumbersome, subjective and inefficient process. Hence, many researchers have developed Xray imagery-based autonomous systems to address these shortcomings. However, to the best of our knowledge, there is no framework, up to now, that can recognize heavily occluded and cluttered baggage items from multi-vendor X-ray scans. This paper presents a cascaded structure tensor framework which can automatically extract and recognize suspicious items irrespective of their position and orientation in the multi-vendor X-ray scans. The proposed framework is unique, as it intelligently extracts each object by iteratively picking contour based transitional information from different orientations and uses only a single feedforward convolutional neural network for the recognition. The proposed framework has been rigorously tested on publicly available GDXray and SIXray datasets containing a total of 1,067,381 X-ray scans where it significantly outperformed the state-of-the-art solutions by achieving the mean average precision score of 0.9343 and 0.9595 for extracting and recognizing suspicious items from GDXray and SIXray scans, respectively. Furthermore, the proposed framework has achieved 15.78% better time
Accuracy vs. Complexity: A Trade-off in Visual Question Answering Models
Jan 20, 2020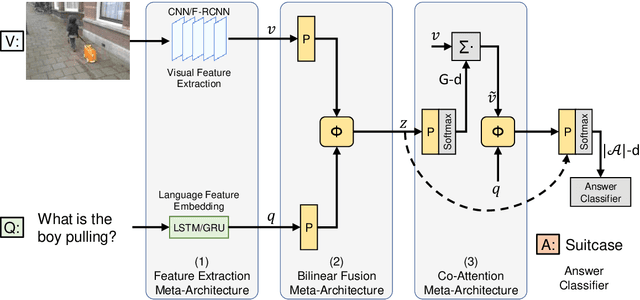
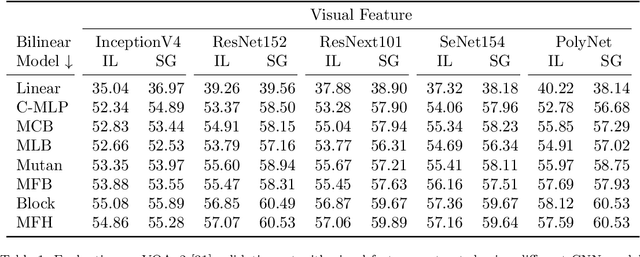
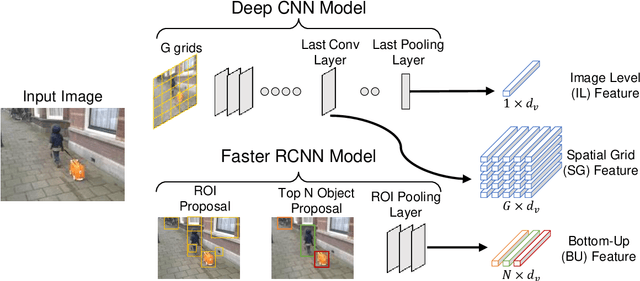
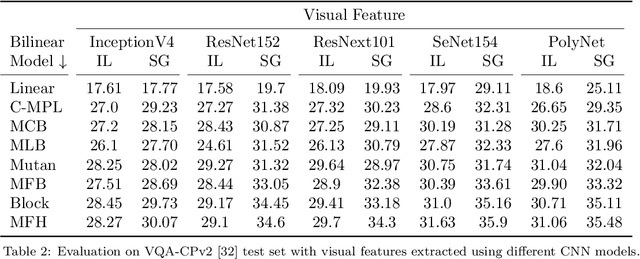
Visual Question Answering (VQA) has emerged as a Visual Turing Test to validate the reasoning ability of AI agents. The pivot to existing VQA models is the joint embedding that is learned by combining the visual features from an image and the semantic features from a given question. Consequently, a large body of literature has focused on developing complex joint embedding strategies coupled with visual attention mechanisms to effectively capture the interplay between these two modalities. However, modelling the visual and semantic features in a high dimensional (joint embedding) space is computationally expensive, and more complex models often result in trivial improvements in the VQA accuracy. In this work, we systematically study the trade-off between the model complexity and the performance on the VQA task. VQA models have a diverse architecture comprising of pre-processing, feature extraction, multimodal fusion, attention and final classification stages. We specifically focus on the effect of "multi-modal fusion" in VQA models that is typically the most expensive step in a VQA pipeline. Our thorough experimental evaluation leads us to two proposals, one optimized for minimal complexity and the other one optimized for state-of-the-art VQA performance.
Cross-Domain Transferability of Adversarial Perturbations
Jun 10, 2019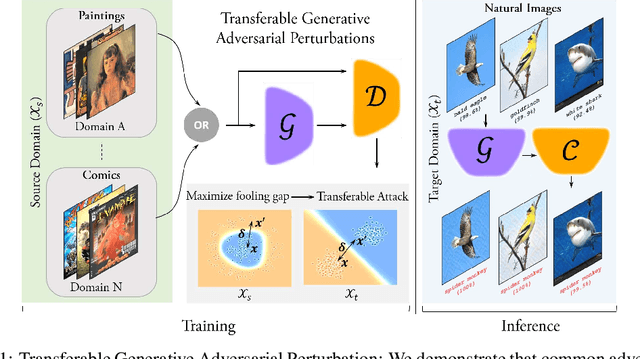
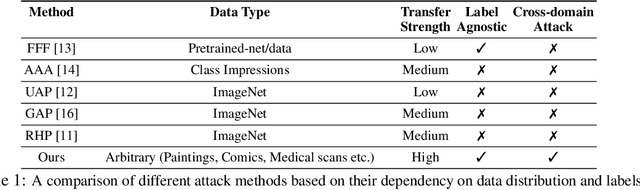
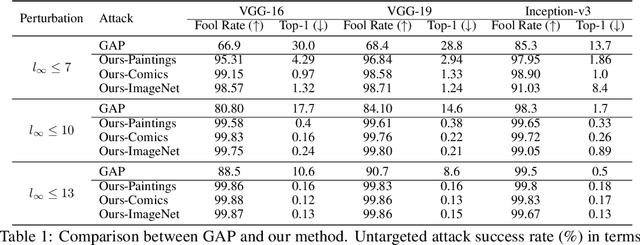

Adversarial examples reveal the blind spots of deep neural networks (DNNs) and represent a major concern for security-critical applications. The transferability of adversarial examples makes real-world attacks possible in black-box settings, where the attacker is forbidden to access the internal parameters of the model. The underlying assumption in most adversary generation methods, whether learning an instance-specific or an instance-agnostic perturbation, is the direct or indirect reliance on the original domain-specific data distribution. In this work, for the first time, we demonstrate the existence of domain-invariant adversaries, thereby showing common adversarial space among different datasets and models. To this end, we propose a framework capable of launching highly transferable attacks that crafts adversarial patterns to mislead networks trained on wholly different domains. For instance, an adversarial function learned on Paintings, Cartoons or Medical images can successfully perturb ImageNet samples to fool the classifier, with success rates as high as $\sim$99\% ($\ell_{\infty} \le 10$). The core of our proposed adversarial function is a generative network that is trained using a relativistic supervisory signal that enables domain-invariant perturbations. Our approach sets the new state-of-the-art for fooling rates, both under the white-box and black-box scenarios. Furthermore, despite being an instance-agnostic perturbation function, our attack outperforms the conventionally much stronger instance-specific attack methods.
Unsupervised Primitive Discovery for Improved 3D Generative Modeling
Jun 09, 2019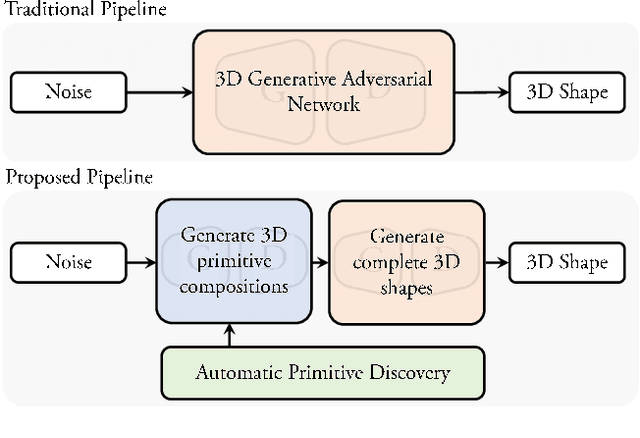
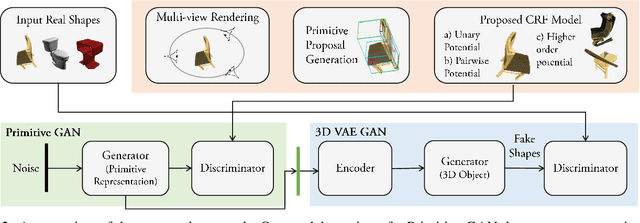
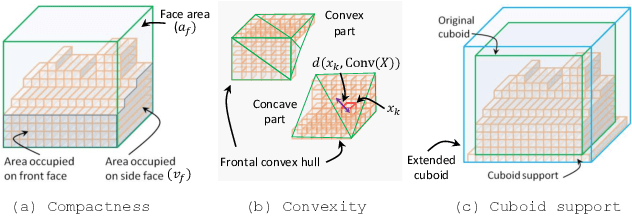
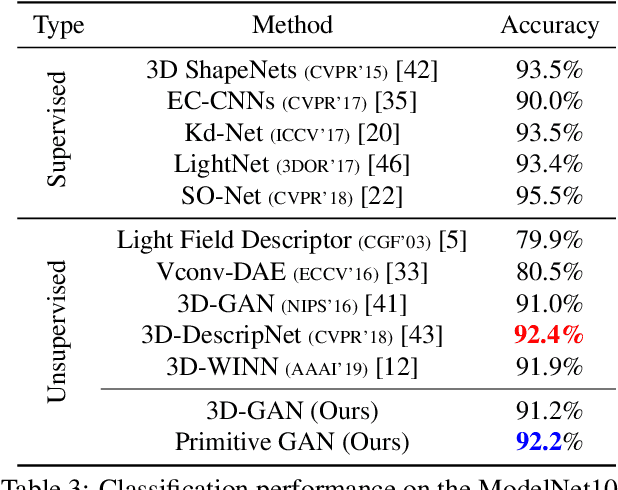
3D shape generation is a challenging problem due to the high-dimensional output space and complex part configurations of real-world objects. As a result, existing algorithms experience difficulties in accurate generative modeling of 3D shapes. Here, we propose a novel factorized generative model for 3D shape generation that sequentially transitions from coarse to fine scale shape generation. To this end, we introduce an unsupervised primitive discovery algorithm based on a higher-order conditional random field model. Using the primitive parts for shapes as attributes, a parameterized 3D representation is modeled in the first stage. This representation is further refined in the next stage by adding fine scale details to shape. Our results demonstrate improved representation ability of the generative model and better quality samples of newly generated 3D shapes. Further, our primitive generation approach can accurately parse common objects into a simplified representation.
Image Super-Resolution as a Defense Against Adversarial Attacks
Jan 07, 2019
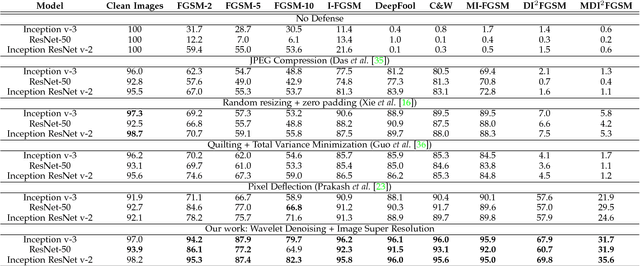
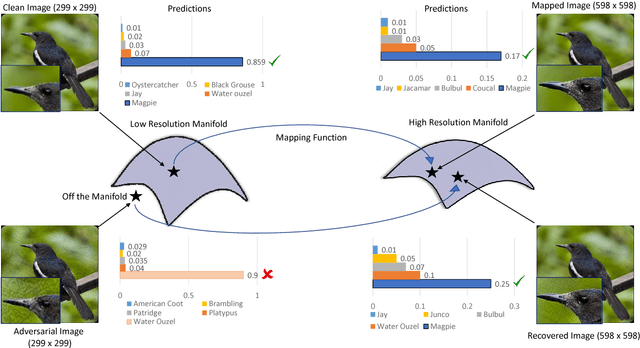
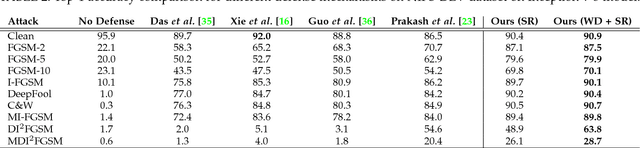
Convolutional Neural Networks have achieved significant success across multiple computer vision tasks. However, they are vulnerable to carefully crafted, human imperceptible adversarial noise patterns which constrain their deployment in critical security-sensitive systems. This paper proposes a computationally efficient image enhancement approach that provides a strong defense mechanism to effectively mitigate the effect of such adversarial perturbations. We show that the deep image restoration networks learn mapping functions that can bring \textit{off-the-manifold} adversarial samples onto the natural image manifold, thus restoring classifier beliefs towards correct classes. A distinguishing feature of our approach is that, in addition to providing robustness against attacks, it simultaneously enhances image quality and retains models performance on clean images. Furthermore, the proposed method does not modify the classifier or requires a separate mechanism to detect adversarial images. The effectiveness of the scheme has been demonstrated through extensive experiments, where it has proven a strong defense in both white-box and black-box attack settings. The proposed scheme is simple and has the following advantages: (1) it does not require any model training or parameter optimization, (2) it complements other existing defense mechanisms, (3) it is agnostic to the attacked model and attack type and (4) it provides superior performance across all popular attack algorithms. Our codes are publicly available at https://github.com/aamir-mustafa/super-resolution-adversarial-defense.
Distorting Neural Representations to Generate Highly Transferable Adversarial Examples
Nov 22, 2018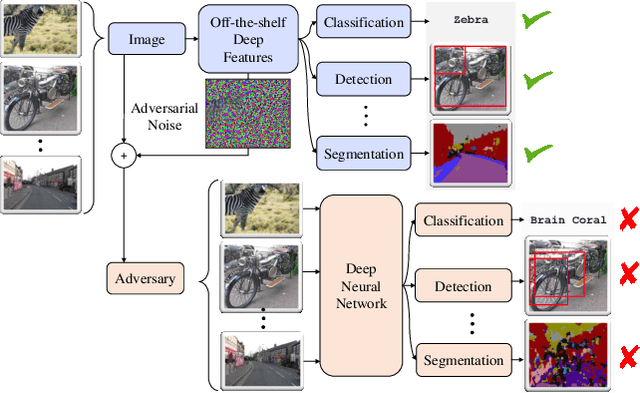

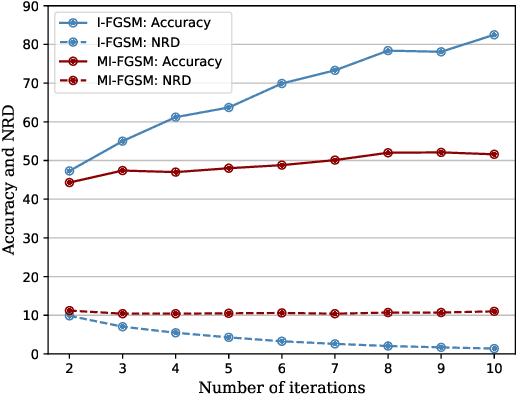

Deep neural networks (DNN) can be easily fooled by adding human imperceptible perturbations to the images. These perturbed images are known as the `adversarial examples' that pose a serious threat to security and safety critical systems. A litmus test for the strength of adversarial examples is their transferability across different DNN models in a black box setting (i.i. when target model's architecture and parameters are not known to attacker). Current attack algorithms that seek to enhance adversarial transferability work on the decision level i.e. generate perturbations that alter the network decisions. This leads to two key limitations: (a) An attack is dependent on the task-specific loss function (e.g. softmax cross-entropy for object recognition) and therefore does not generalize beyond its original task. (b) The adversarial examples are specific to the network architecture and demonstrate poor transferability to other network architectures. We propose a novel approach to create adversarial examples that can broadly fool different networks on multiple tasks. Our approach is based on the following intuition: "Deep features are highly generalizable and show excellent performance across different tasks, therefore an ideal attack must create maximum distortions in the feature space to realize highly transferable examples". Specifically, for an input image, we calculate perturbations that push its feature representations furthest away from the original image features. We report extensive experiments to show how adversarial examples generalize across multiple networks across classification, object detection and segmentation tasks.
Adversarial Training of Variational Auto-encoders for High Fidelity Image Generation
Apr 27, 2018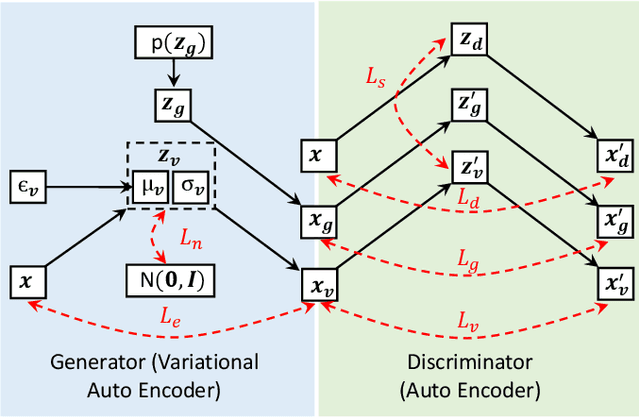
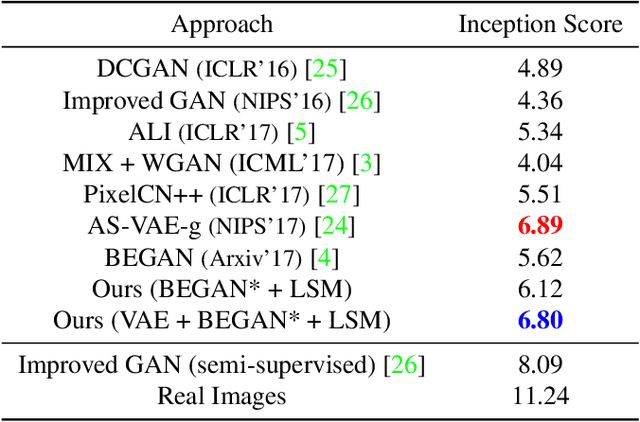


Variational auto-encoders (VAEs) provide an attractive solution to image generation problem. However, they tend to produce blurred and over-smoothed images due to their dependence on pixel-wise reconstruction loss. This paper introduces a new approach to alleviate this problem in the VAE based generative models. Our model simultaneously learns to match the data, reconstruction loss and the latent distributions of real and fake images to improve the quality of generated samples. To compute the loss distributions, we introduce an auto-encoder based discriminator model which allows an adversarial learning procedure. The discriminator in our model also provides perceptual guidance to the VAE by matching the learned similarity metric of the real and fake samples in the latent space. To stabilize the overall training process, our model uses an error feedback approach to maintain the equilibrium between competing networks in the model. Our experiments show that the generated samples from our proposed model exhibit a diverse set of attributes and facial expressions and scale up to high-resolution images very well.
A Unified approach for Conventional Zero-shot, Generalized Zero-shot and Few-shot Learning
Oct 26, 2017



Prevalent techniques in zero-shot learning do not generalize well to other related problem scenarios. Here, we present a unified approach for conventional zero-shot, generalized zero-shot and few-shot learning problems. Our approach is based on a novel Class Adapting Principal Directions (CAPD) concept that allows multiple embeddings of image features into a semantic space. Given an image, our method produces one principal direction for each seen class. Then, it learns how to combine these directions to obtain the principal direction for each unseen class such that the CAPD of the test image is aligned with the semantic embedding of the true class, and opposite to the other classes. This allows efficient and class-adaptive information transfer from seen to unseen classes. In addition, we propose an automatic process for selection of the most useful seen classes for each unseen class to achieve robustness in zero-shot learning. Our method can update the unseen CAPD taking the advantages of few unseen images to work in a few-shot learning scenario. Furthermore, our method can generalize the seen CAPDs by estimating seen-unseen diversity that significantly improves the performance of generalized zero-shot learning. Our extensive evaluations demonstrate that the proposed approach consistently achieves superior performance in zero-shot, generalized zero-shot and few/one-shot learning problems.
Cost Sensitive Learning of Deep Feature Representations from Imbalanced Data
Mar 23, 2017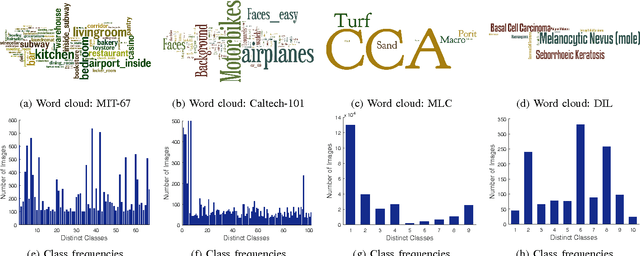

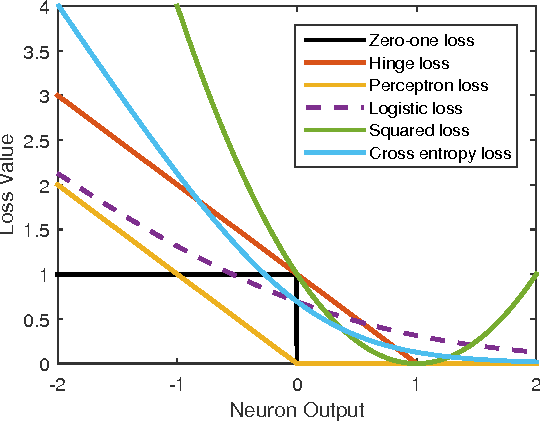
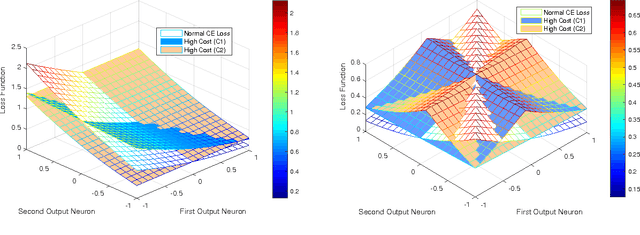
Class imbalance is a common problem in the case of real-world object detection and classification tasks. Data of some classes is abundant making them an over-represented majority, and data of other classes is scarce, making them an under-represented minority. This imbalance makes it challenging for a classifier to appropriately learn the discriminating boundaries of the majority and minority classes. In this work, we propose a cost sensitive deep neural network which can automatically learn robust feature representations for both the majority and minority classes. During training, our learning procedure jointly optimizes the class dependent costs and the neural network parameters. The proposed approach is applicable to both binary and multi-class problems without any modification. Moreover, as opposed to data level approaches, we do not alter the original data distribution which results in a lower computational cost during the training process. We report the results of our experiments on six major image classification datasets and show that the proposed approach significantly outperforms the baseline algorithms. Comparisons with popular data sampling techniques and cost sensitive classifiers demonstrate the superior performance of our proposed method.
A Spatial Layout and Scale Invariant Feature Representation for Indoor Scene Classification
Aug 14, 2015
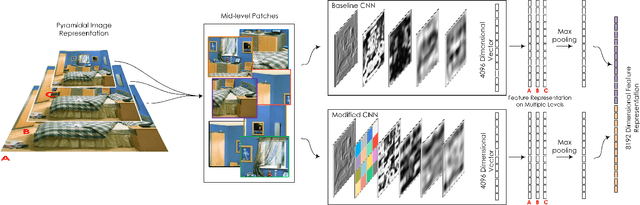
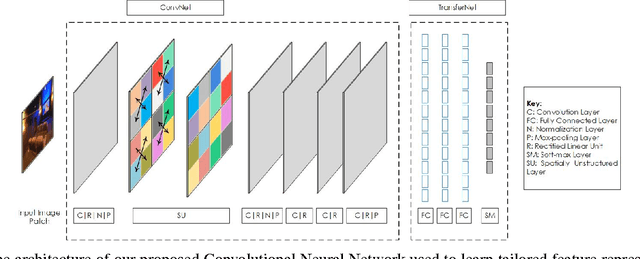

Unlike standard object classification, where the image to be classified contains one or multiple instances of the same object, indoor scene classification is quite different since the image consists of multiple distinct objects. Further, these objects can be of varying sizes and are present across numerous spatial locations in different layouts. For automatic indoor scene categorization, large scale spatial layout deformations and scale variations are therefore two major challenges and the design of rich feature descriptors which are robust to these challenges is still an open problem. This paper introduces a new learnable feature descriptor called "spatial layout and scale invariant convolutional activations" to deal with these challenges. For this purpose, a new Convolutional Neural Network architecture is designed which incorporates a novel 'Spatially Unstructured' layer to introduce robustness against spatial layout deformations. To achieve scale invariance, we present a pyramidal image representation. For feasible training of the proposed network for images of indoor scenes, the paper proposes a new methodology which efficiently adapts a trained network model (on a large scale data) for our task with only a limited amount of available training data. Compared with existing state of the art, the proposed approach achieves a relative performance improvement of 3.2%, 3.8%, 7.0%, 11.9% and 2.1% on MIT-67, Scene-15, Sports-8, Graz-02 and NYU datasets respectively.