 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuxAdapt: Stable and Efficient Test-Time Adaptation for Temporally Consistent Video Semantic Segmentation
Oct 24, 2021
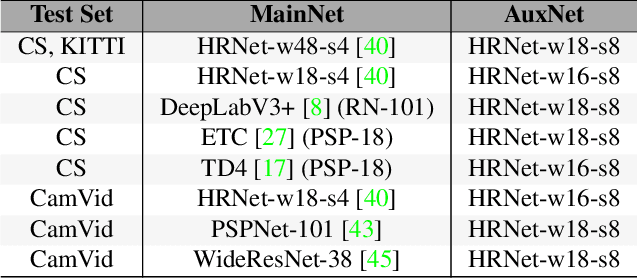
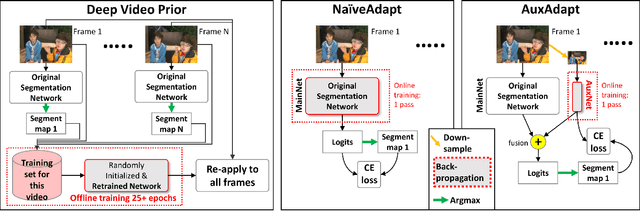
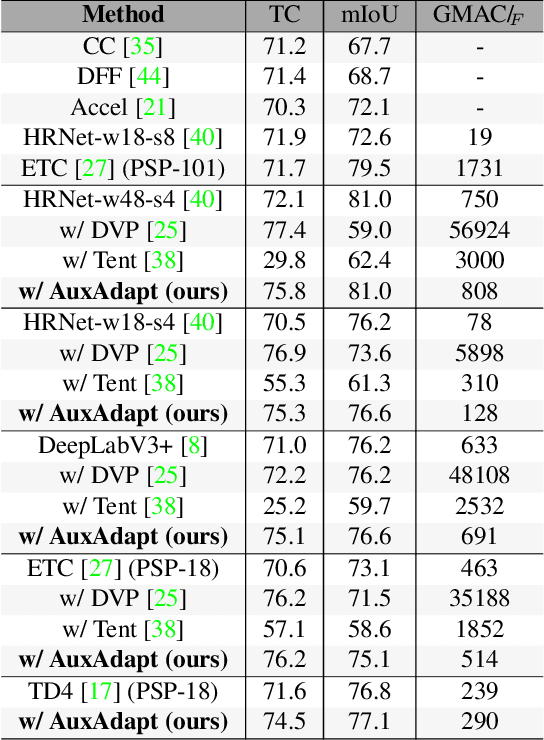
In video segmentation, generating temporally consistent results across frames is as important as achieving frame-wise accuracy. Existing methods rely either on optical flow regularization or fine-tuning with test data to attain temporal consistency. However, optical flow is not always avail-able and reliable. Besides, it is expensive to compute. Fine-tuning the original model in test time is cost sensitive. This paper presents an efficient, intuitive, and unsupervised online adaptation method, AuxAdapt, for improving the temporal consistency of most neural network models. It does not require optical flow and only takes one pass of the video. Since inconsistency mainly arises from the model's uncertainty in its output, we propose an adaptation scheme where the model learns from its own segmentation decisions as it streams a video, which allows producing more confident and temporally consistent labeling for similarly-looking pixels across frames. For stability and efficiency, we leverage a small auxiliary segmentation network (AuxNet) to assist with this adaptation. More specifically, AuxNet readjusts the decision of the original segmentation network (Main-Net) by adding its own estimations to that of MainNet. At every frame, only AuxNet is updated via back-propagation while keeping MainNet fixed. We extensively evaluate our test-time adaptation approach on standard video benchmarks, including Cityscapes, CamVid, and KITTI. The results demonstrate that our approach provides label-wise accurate, temporally consistent, and computationally efficient adaptation (5+ folds overhead reduction comparing to state-of-the-art test-time adaptation methods).
A Survey on Deep Learning Technique for Video Segmentation
Jul 02, 2021
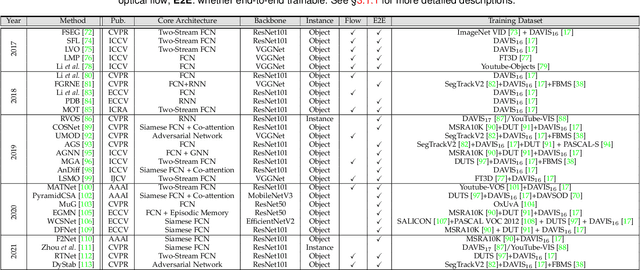
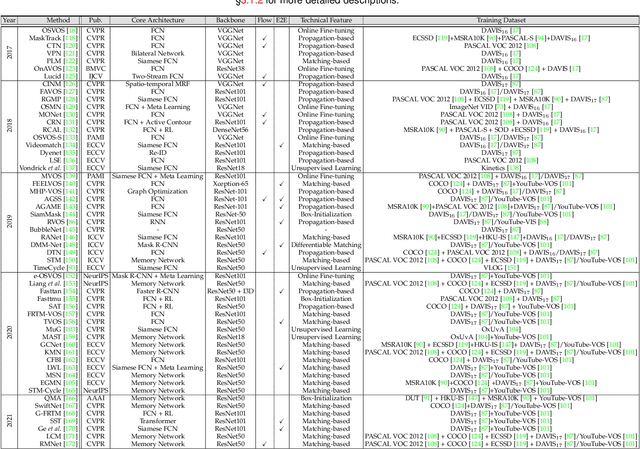

Video segmentation, i.e., partitioning video frames into multiple segments or objects, plays a critical role in a broad range of practical applications, e.g., visual effect assistance in movie, scene understanding in autonomous driving, and virtual background creation in video conferencing, to name a few. Recently, due to the renaissance of connectionism in computer vision, there has been an influx of numerous deep learning based approaches that have been dedicated to video segmentation and delivered compelling performance. In this survey, we comprehensively review two basic lines of research in this area, i.e., generic object segmentation (of unknown categories) in videos and video semantic segmentation, by introducing their respective task settings, background concepts, perceived need, development history, and main challenges. We also provide a detailed overview of representative literature on both methods and datasets. Additionally, we present quantitative performance comparisons of the reviewed methods on benchmark datasets. At last, we point out a set of unsolved open issues in this field, and suggest possible opportunities for further research.
On Improving Adversarial Transferability of Vision Transformers
Jun 08, 2021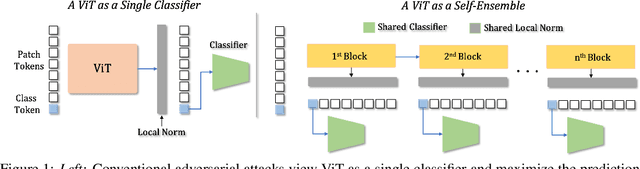
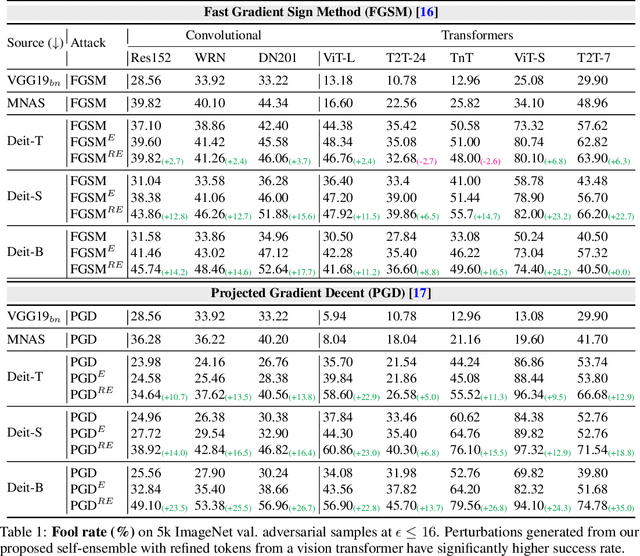
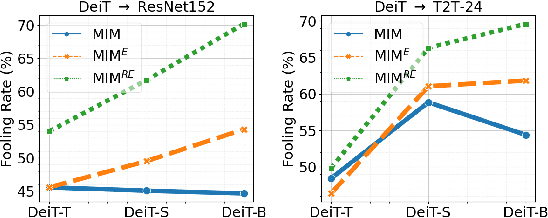
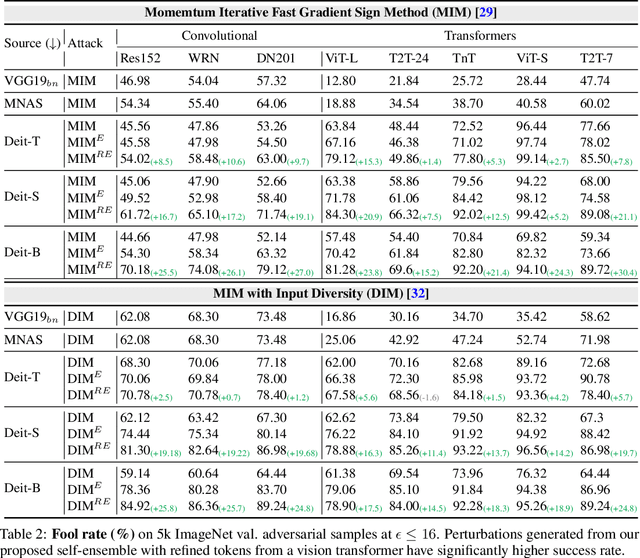
Vision transformers (ViTs) process input images as sequences of patches via self-attention; a radically different architecture than convolutional neural networks (CNNs). This makes it interesting to study the adversarial feature space of ViT models and their transferability. In particular, we observe that adversarial patterns found via conventional adversarial attacks show very low black-box transferability even for large ViT models. However, we show that this phenomenon is only due to the sub-optimal attack procedures that do not leverage the true representation potential of ViTs. A deep ViT is composed of multiple blocks, with a consistent architecture comprising of self-attention and feed-forward layers, where each block is capable of independently producing a class token. Formulating an attack using only the last class token (conventional approach) does not directly leverage the discriminative information stored in the earlier tokens, leading to poor adversarial transferability of ViTs. Using the compositional nature of ViT models, we enhance the transferability of existing attacks by introducing two novel strategies specific to the architecture of ViT models. (i) Self-Ensemble: We propose a method to find multiple discriminative pathways by dissecting a single ViT model into an ensemble of networks. This allows explicitly utilizing class-specific information at each ViT block. (ii) Token Refinement: We then propose to refine the tokens to further enhance the discriminative capacity at each block of ViT. Our token refinement systematically combines the class tokens with structural information preserved within the patch tokens. An adversarial attack, when applied to such refined tokens within the ensemble of classifiers found in a single vision transformer, has significantly higher transferability.
Data-driven Weight Initialization with Sylvester Solvers
May 02, 2021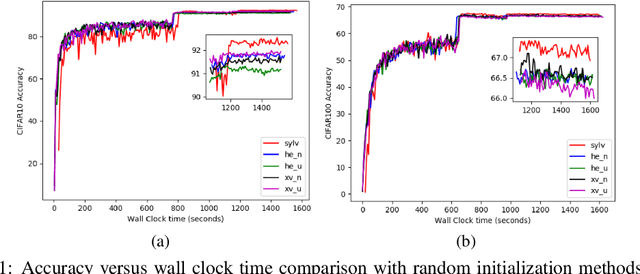
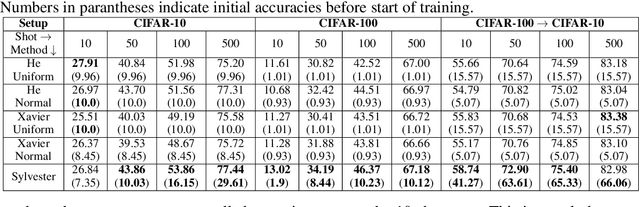
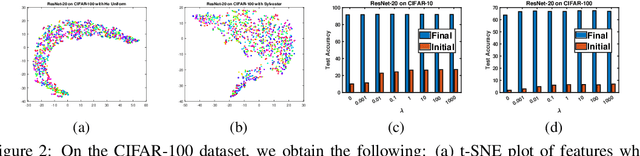

In this work, we propose a data-driven scheme to initialize the parameters of a deep neural network. This is in contrast to traditional approaches which randomly initialize parameters by sampling from transformed standard distributions. Such methods do not use the training data to produce a more informed initialization. Our method uses a sequential layer-wise approach where each layer is initialized using its input activations. The initialization is cast as an optimization problem where we minimize a combination of encoding and decoding losses of the input activations, which is further constrained by a user-defined latent code. The optimization problem is then restructured into the well-known Sylvester equation, which has fast and efficient gradient-free solutions. Our data-driven method achieves a boost in performance compared to random initialization methods, both before start of training and after training is over. We show that our proposed method is especially effective in few-shot and fine-tuning settings. We conclude this paper with analyses on time complexity and the effect of different latent codes on the recognition performance.
InverseForm: A Loss Function for Structured Boundary-Aware Segmentation
Apr 08, 2021
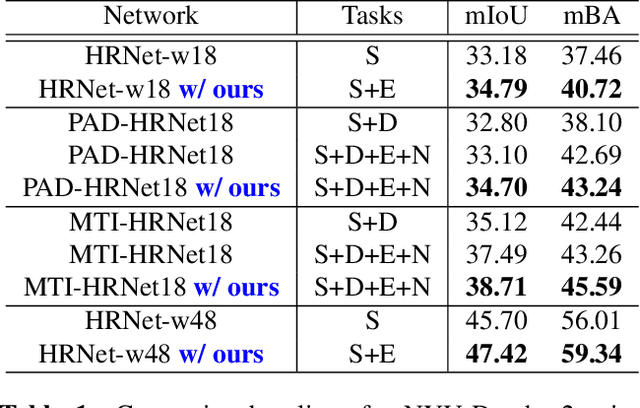
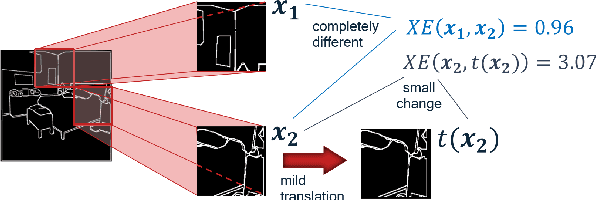
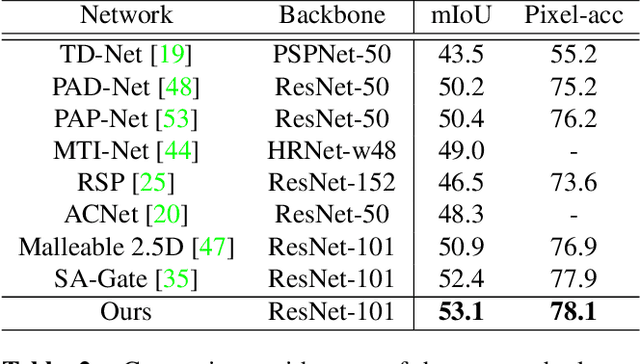
We present a novel boundary-aware loss term for semantic segmentation using an inverse-transformation network, which efficiently learns the degree of parametric transformations between estimated and target boundaries. This plug-in loss term complements the cross-entropy loss in capturing boundary transformations and allows consistent and significant performance improvement on segmentation backbone models without increasing their size and computational complexity. We analyze the quantitative and qualitative effects of our loss function on three indoor and outdoor segmentation benchmarks, including Cityscapes, NYU-Depth-v2, and PASCAL, integrating it into the training phase of several backbone networks in both single-task and multi-task settings. Our extensive experiments show that the proposed method consistently outperforms baselines, and even sets the new state-of-the-art on two datasets.
On Generating Transferable Targeted Perturbations
Mar 26, 2021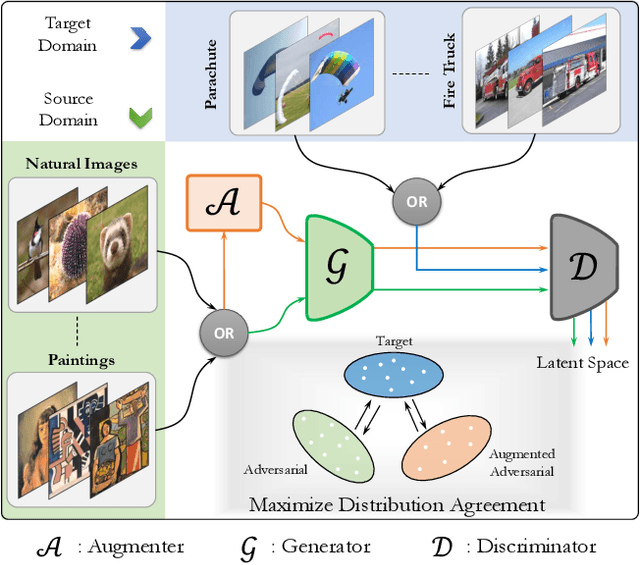
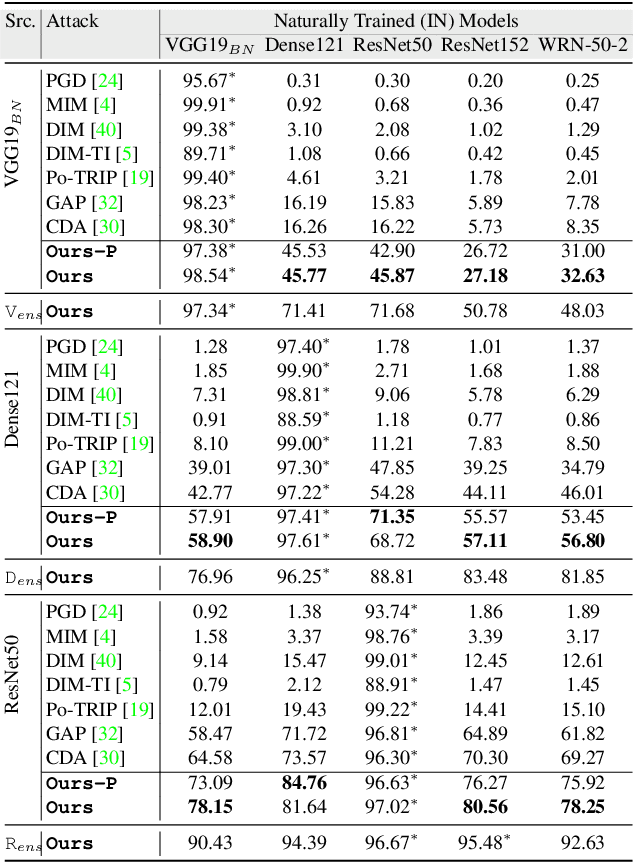

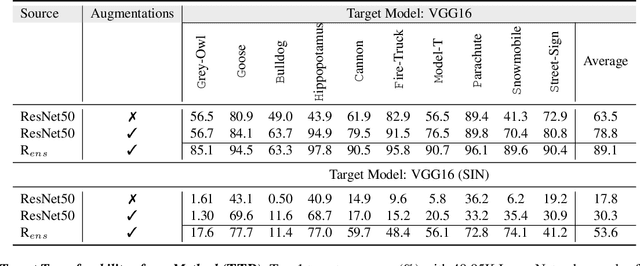
While the untargeted black-box transferability of adversarial perturbations has been extensively studied before, changing an unseen model's decisions to a specific `targeted' class remains a challenging feat. In this paper, we propose a new generative approach for highly transferable targeted perturbations (\ours). We note that the existing methods are less suitable for this task due to their reliance on class-boundary information that changes from one model to another, thus reducing transferability. In contrast, our approach matches the perturbed image `distribution' with that of the target class, leading to high targeted transferability rates. To this end, we propose a new objective function that not only aligns the global distributions of source and target images, but also matches the local neighbourhood structure between the two domains. Based on the proposed objective, we train a generator function that can adaptively synthesize perturbations specific to a given input. Our generative approach is independent of the source or target domain labels, while consistently performs well against state-of-the-art methods on a wide range of attack settings. As an example, we achieve $32.63\%$ target transferability from (an adversarially weak) VGG19$_{BN}$ to (a strong) WideResNet on ImageNet val. set, which is 4$\times$ higher than the previous best generative attack and 16$\times$ better than instance-specific iterative attack. Code is available at: {\small\url{https://github.com/Muzammal-Naseer/TTP}}.
Cascade Weight Shedding in Deep Neural Networks: Benefits and Pitfalls for Network Pruning
Mar 19, 2021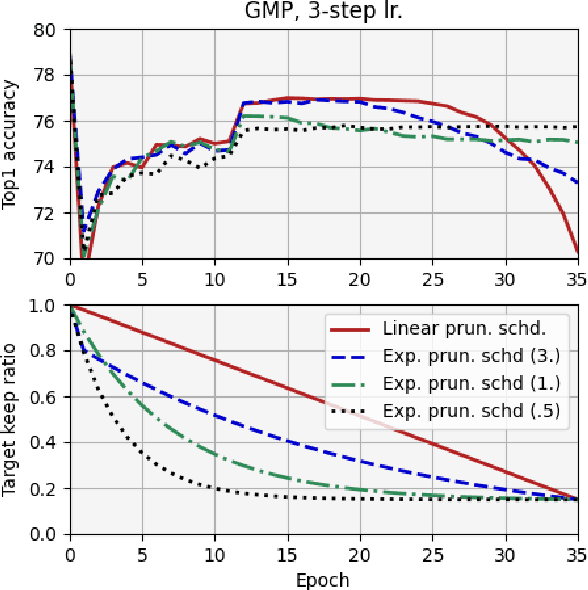
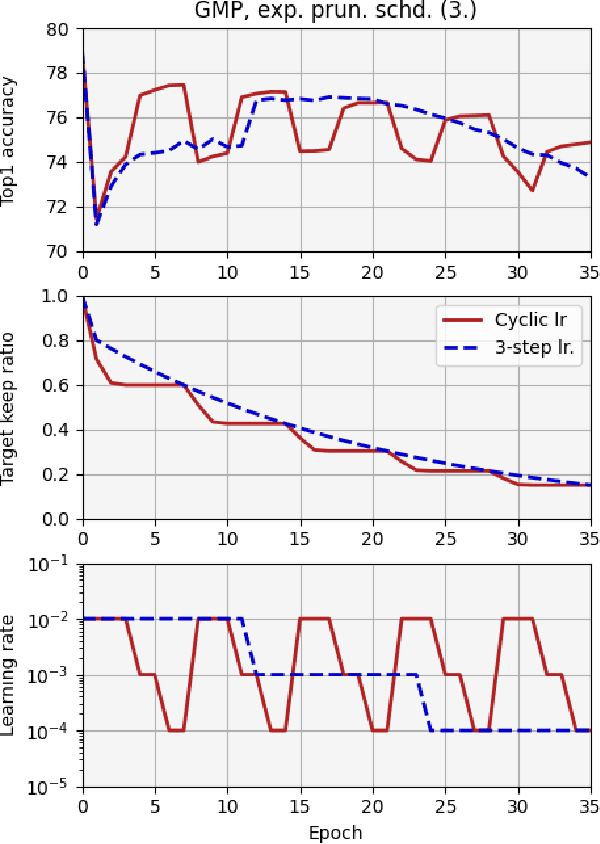
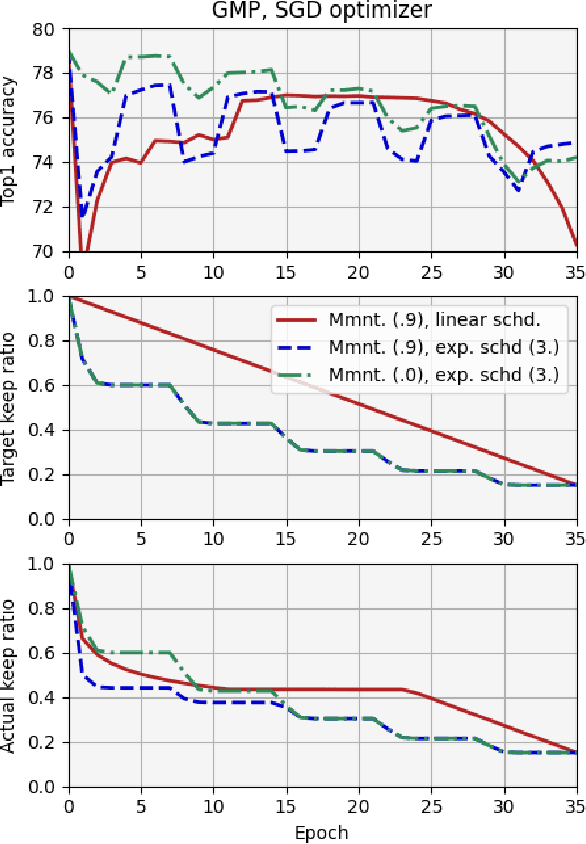
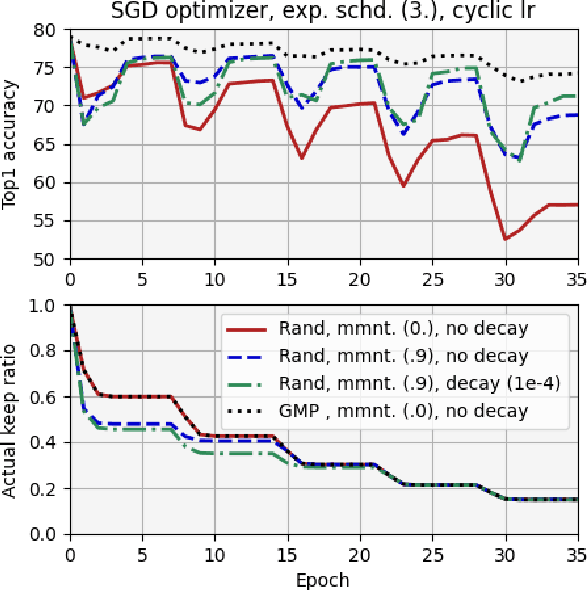
We report, for the first time, on the cascade weight shedding phenomenon in deep neural networks where in response to pruning a small percentage of a network's weights, a large percentage of the remaining is shed over a few epochs during the ensuing fine-tuning phase. We show that cascade weight shedding, when present, can significantly improve the performance of an otherwise sub-optimal scheme such as random pruning. This explains why some pruning methods may perform well under certain circumstances, but poorly under others, e.g., ResNet50 vs. MobileNetV3. We provide insight into why the global magnitude-based pruning, i.e., GMP, despite its simplicity, provides a competitive performance for a wide range of scenarios. We also demonstrate cascade weight shedding's potential for improving GMP's accuracy, and reduce its computational complexity. In doing so, we highlight the importance of pruning and learning-rate schedules. We shed light on weight and learning-rate rewinding methods of re-training, showing their possible connections to the cascade weight shedding and reason for their advantage over fine-tuning. We also investigate cascade weight shedding's effect on the set of kept weights, and its implications for semi-structured pruning. Finally, we give directions for future research.
Structured Convolutions for Efficient Neural Network Design
Aug 06, 2020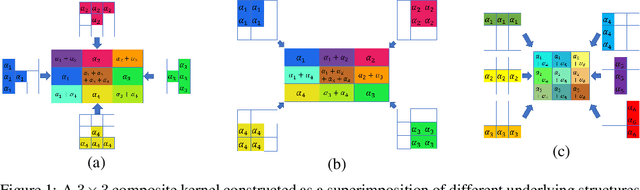
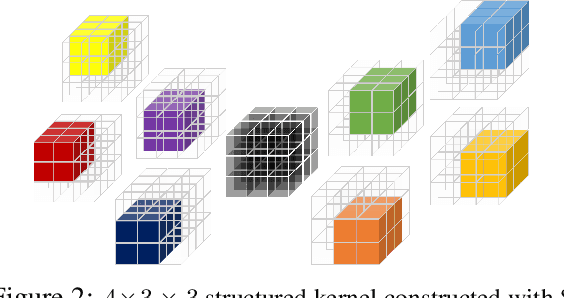
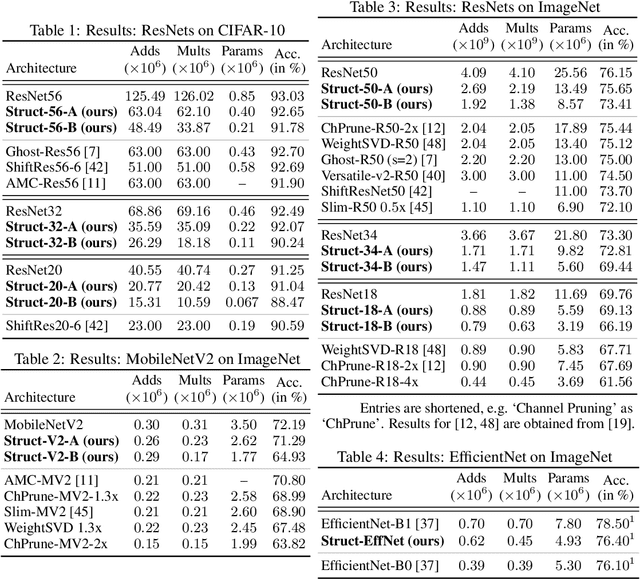
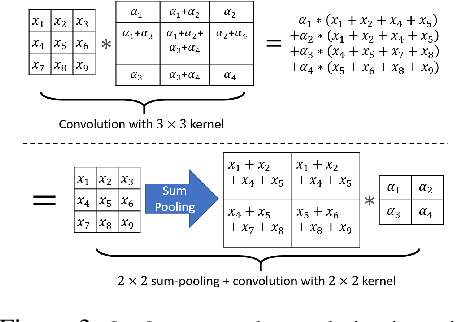
In this work, we tackle model efficiency by exploiting redundancy in the \textit{implicit structure} of the building blocks of convolutional neural networks. We start our analysis by introducing a general definition of Composite Kernel structures that enable the execution of convolution operations in the form of efficient, scaled, sum-pooling components. As its special case, we propose \textit{Structured Convolutions} and show that these allow decomposition of the convolution operation into a sum-pooling operation followed by a convolution with significantly lower complexity and fewer weights. We show how this decomposition can be applied to 2D and 3D kernels as well as the fully-connected layers. Furthermore, we present a Structural Regularization loss that promotes neural network layers to leverage on this desired structure in a way that, after training, they can be decomposed with negligible performance loss. By applying our method to a wide range of CNN architectures, we demonstrate "structured" versions of the ResNets that are up to 2$\times$ smaller and a new Structured-MobileNetV2 that is more efficient while staying within an accuracy loss of 1% on ImageNet and CIFAR-10 datasets. We also show similar structured versions of EfficientNet on ImageNet and HRNet architecture for semantic segmentation on the Cityscapes dataset. Our method performs equally well or superior in terms of the complexity reduction in comparison to the existing tensor decomposition and channel pruning methods.
Towards Purely Unsupervised Disentanglement of Appearance and Shape for Person Images Generation
Jul 30, 2020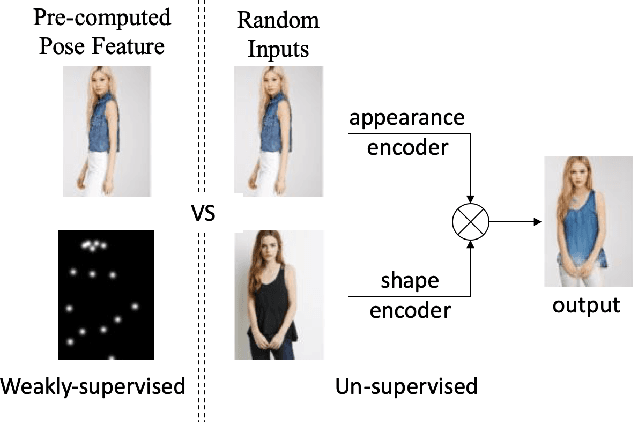
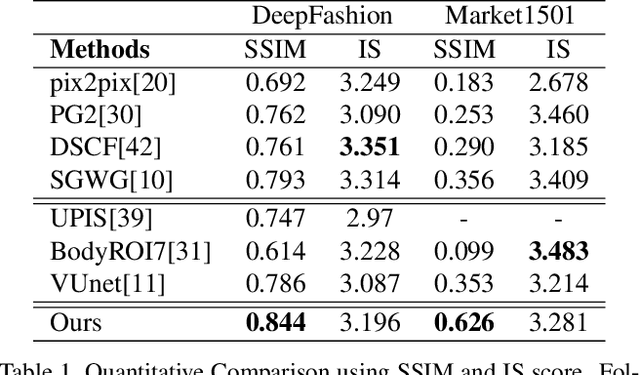
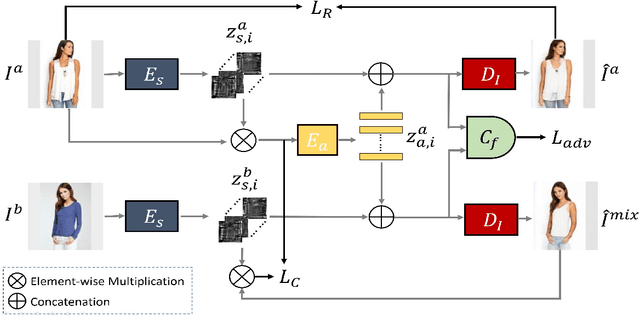

There have been a fairly of research interests in exploring the disentanglement of appearance and shape from human images. Most existing endeavours pursuit this goal by either using training images with annotations or regulating the training process with external clues such as human skeleton, body segmentation or cloth patches etc. In this paper, we aim to address this challenge in a more unsupervised manner---we do not require any annotation nor any external task-specific clues. To this end, we formulate an encoder-decoder-like network to extract both the shape and appearance features from input images at the same time, and train the parameters by three losses: feature adversarial loss, color consistency loss and reconstruction loss. The feature adversarial loss mainly impose little to none mutual information between the extracted shape and appearance features, while the color consistency loss is to encourage the invariance of person appearance conditioned on different shapes. More importantly, our unsupervised (Unsupervised learning has many interpretations in different tasks. To be clear, in this paper, we refer unsupervised learning as learning without task-specific human annotations, pairs or any form of weak supervision.) framework utilizes learned shape features as masks which are applied to the input itself in order to obtain clean appearance features. Without using fixed input human skeleton, our network better preserves the conditional human posture while requiring less supervision. Experimental results on DeepFashion and Market1501 demonstrate that the proposed method achieves clean disentanglement and is able to synthesis novel images of comparable quality with state-of-the-art weakly-supervised or even supervised methods.
Stylized Adversarial Defense
Jul 29, 2020
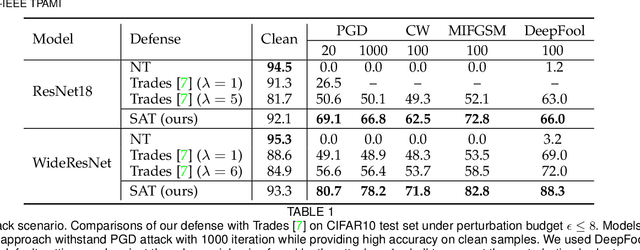
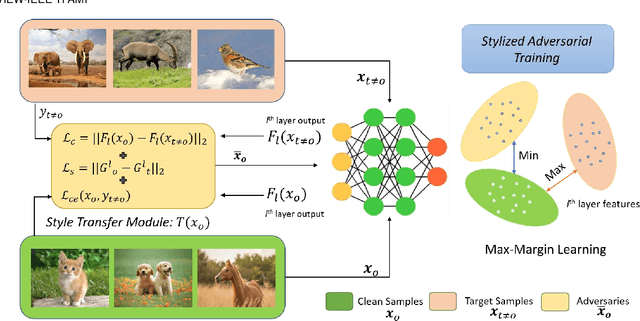
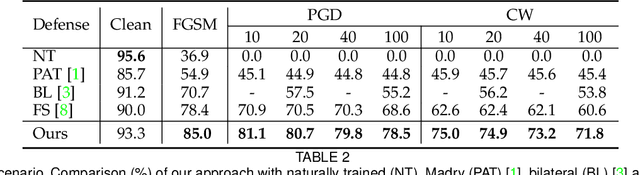
Deep Convolution Neural Networks (CNNs) can easily be fooled by subtle, imperceptible changes to the input images. To address this vulnerability, adversarial training creates perturbation patterns and includes them in the training set to robustify the model. In contrast to existing adversarial training methods that only use class-boundary information (e.g., using a cross entropy loss), we propose to exploit additional information from the feature space to craft stronger adversaries that are in turn used to learn a robust model. Specifically, we use the style and content information of the target sample from another class, alongside its class boundary information to create adversarial perturbations. We apply our proposed multi-task objective in a deeply supervised manner, extracting multi-scale feature knowledge to create maximally separating adversaries. Subsequently, we propose a max-margin adversarial training approach that minimizes the distance between source image and its adversary and maximizes the distance between the adversary and the target image. Our adversarial training approach demonstrates strong robustness compared to state of the art defenses, generalizes well to naturally occurring corruptions and data distributional shifts, and retains the model accuracy on clean examples.