 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparkles: Unlocking Chats Across Multiple Images for Multimodal Instruction-Following Models
Aug 31, 2023



Large language models exhibit enhanced zero-shot performance on various tasks when fine-tuned with instruction-following data. Multimodal instruction-following models extend these capabilities by integrating both text and images. However, existing models such as MiniGPT-4 face challenges in maintaining dialogue coherence in scenarios involving multiple images. A primary reason is the lack of a specialized dataset for this critical application. To bridge these gaps, we present SparklesChat, a multimodal instruction-following model for open-ended dialogues across multiple images. To support the training, we introduce SparklesDialogue, the first machine-generated dialogue dataset tailored for word-level interleaved multi-image and text interactions. Furthermore, we construct SparklesEval, a GPT-assisted benchmark for quantitatively assessing a model's conversational competence across multiple images and dialogue turns. Our experiments validate the effectiveness of SparklesChat in understanding and reasoning across multiple images and dialogue turns. Specifically, SparklesChat outperformed MiniGPT-4 on established vision-and-language benchmarks, including the BISON binary image selection task and the NLVR2 visual reasoning task. Moreover, SparklesChat scored 8.56 out of 10 on SparklesEval, substantially exceeding MiniGPT-4's score of 3.91 and nearing GPT-4's score of 9.26. Qualitative evaluations further demonstrate SparklesChat's generality in handling real-world applications. All resources will be available at https://github.com/HYPJUDY/Sparkles.
Compositional Zero-Shot Domain Transfer with Text-to-Text Models
Mar 23, 2023Label scarcity is a bottleneck for improving task performance in specialised domains. We propose a novel compositional transfer learning framework (DoT5 - domain compositional zero-shot T5) for zero-shot domain transfer. Without access to in-domain labels, DoT5 jointly learns domain knowledge (from MLM of unlabelled in-domain free text) and task knowledge (from task training on more readily available general-domain data) in a multi-task manner. To improve the transferability of task training, we design a strategy named NLGU: we simultaneously train NLG for in-domain label-to-data generation which enables data augmentation for self-finetuning and NLU for label prediction. We evaluate DoT5 on the biomedical domain and the resource-lean subdomain of radiology, focusing on NLI, text summarisation and embedding learning. DoT5 demonstrates the effectiveness of compositional transfer learning through multi-task learning. In particular, DoT5 outperforms the current SOTA in zero-shot transfer by over 7 absolute points in accuracy on RadNLI. We validate DoT5 with ablations and a case study demonstrating its ability to solve challenging NLI examples requiring in-domain expertise.
SAT: Size-Aware Transformer for 3D Point Cloud Semantic Segmentation
Jan 17, 2023



Transformer models have achieved promising performances in point cloud segmentation. However, most existing attention schemes provide the same feature learning paradigm for all points equally and overlook the enormous difference in size among scene objects. In this paper, we propose the Size-Aware Transformer (SAT) that can tailor effective receptive fields for objects of different sizes. Our SAT achieves size-aware learning via two steps: introduce multi-scale features to each attention layer and allow each point to choose its attentive fields adaptively. It contains two key designs: the Multi-Granularity Attention (MGA) scheme and the Re-Attention module. The MGA addresses two challenges: efficiently aggregating tokens from distant areas and preserving multi-scale features within one attention layer. Specifically, point-voxel cross attention is proposed to address the first challenge, and the shunted strategy based on the standard multi-head self attention is applied to solve the second. The Re-Attention module dynamically adjusts the attention scores to the fine- and coarse-grained features output by MGA for each point. Extensive experimental results demonstrate that SAT achieves state-of-the-art performances on S3DIS and ScanNetV2 datasets. Our SAT also achieves the most balanced performance on categories among all referred methods, which illustrates the superiority of modelling categories of different sizes. Our code and model will be released after the acceptance of this paper.
DePlot: One-shot visual language reasoning by plot-to-table translation
Dec 20, 2022



Visual language such as charts and plots is ubiquitous in the human world. Comprehending plots and charts requires strong reasoning skills. Prior state-of-the-art (SOTA) models require at least tens of thousands of training examples and their reasoning capabilities are still much limited, especially on complex human-written queries. This paper presents the first one-shot solution to visual language reasoning. We decompose the challenge of visual language reasoning into two steps: (1) plot-to-text translation, and (2) reasoning over the translated text. The key in this method is a modality conversion module, named as DePlot, which translates the image of a plot or chart to a linearized table. The output of DePlot can then be directly used to prompt a pretrained large language model (LLM), exploiting the few-shot reasoning capabilities of LLMs. To obtain DePlot, we standardize the plot-to-table task by establishing unified task formats and metrics, and train DePlot end-to-end on this task. DePlot can then be used off-the-shelf together with LLMs in a plug-and-play fashion. Compared with a SOTA model finetuned on more than >28k data points, DePlot+LLM with just one-shot prompting achieves a 24.0% improvement over finetuned SOTA on human-written queries from the task of chart QA.
On-the-fly Denoising for Data Augmentation in Natural Language Understanding
Dec 20, 2022Data Augmentation (DA) is frequently used to automatically provide additional training data without extra human annotation. However, data augmentation may introduce noisy data that impairs training. To guarantee the quality of augmented data, existing methods either assume no noise exists in the augmented data and adopt consistency training or use simple heuristics such as training loss and diversity constraints to filter out ``noisy'' data. However, those filtered examples may still contain useful information, and dropping them completely causes loss of supervision signals. In this paper, based on the assumption that the original dataset is cleaner than the augmented data, we propose an on-the-fly denoising technique for data augmentation that learns from soft augmented labels provided by an organic teacher model trained on the cleaner original data. A simple self-regularization module is applied to force the model prediction to be consistent across two distinct dropouts to further prevent overfitting on noisy labels. Our method can be applied to augmentation techniques in general and can consistently improve the performance on both text classification and question-answering tasks.
MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering
Dec 19, 2022



Visual language data such as plots, charts, and infographics are ubiquitous in the human world. However, state-of-the-art vision-language models do not perform well on these data. We propose MatCha (Math reasoning and Chart derendering pretraining) to enhance visual language models' capabilities in jointly modeling charts/plots and language data. Specifically, we propose several pretraining tasks that cover plot deconstruction and numerical reasoning which are the key capabilities in visual language modeling. We perform the MatCha pretraining starting from Pix2Struct, a recently proposed image-to-text visual language model. On standard benchmarks such as PlotQA and ChartQA, the MatCha model outperforms state-of-the-art methods by as much as nearly 20%. We also examine how well MatCha pretraining transfers to domains such as screenshots, textbook diagrams, and document figures and observe overall improvement, verifying the usefulness of MatCha pretraining on broader visual language tasks.
Reranking Overgenerated Responses for End-to-End Task-Oriented Dialogue Systems
Nov 07, 2022End-to-end (E2E) task-oriented dialogue (ToD) systems are prone to fall into the so-called 'likelihood trap', resulting in generated responses which are dull, repetitive, and often inconsistent with dialogue history. Comparing ranked lists of multiple generated responses against the 'gold response' (from training data) reveals a wide diversity in response quality, with many good responses placed lower in the ranked list. The main challenge, addressed in this work, is then how to reach beyond greedily generated system responses, that is, how to obtain and select such high-quality responses from the list of overgenerated responses at inference without availability of the gold response. To this end, we propose a simple yet effective reranking method which aims to select high-quality items from the lists of responses initially overgenerated by the system. The idea is to use any sequence-level (similarity) scoring function to divide the semantic space of responses into high-scoring versus low-scoring partitions. At training, the high-scoring partition comprises all generated responses whose similarity to the gold response is higher than the similarity of the greedy response to the gold response. At inference, the aim is to estimate the probability that each overgenerated response belongs to the high-scoring partition, given only previous dialogue history. We validate the robustness and versatility of our proposed method on the standard MultiWOZ dataset: our methods improve a state-of-the-art E2E ToD system by 2.4 BLEU, 3.2 ROUGE, and 2.8 METEOR scores, achieving new peak results. Additional experiments on the BiTOD dataset and human evaluation further ascertain the generalisability and effectiveness of the proposed framework.
Improving Bilingual Lexicon Induction with Cross-Encoder Reranking
Oct 30, 2022



Bilingual lexicon induction (BLI) with limited bilingual supervision is a crucial yet challenging task in multilingual NLP. Current state-of-the-art BLI methods rely on the induction of cross-lingual word embeddings (CLWEs) to capture cross-lingual word similarities; such CLWEs are obtained 1) via traditional static models (e.g., VecMap), or 2) by extracting type-level CLWEs from multilingual pretrained language models (mPLMs), or 3) through combining the former two options. In this work, we propose a novel semi-supervised post-hoc reranking method termed BLICEr (BLI with Cross-Encoder Reranking), applicable to any precalculated CLWE space, which improves their BLI capability. The key idea is to 'extract' cross-lingual lexical knowledge from mPLMs, and then combine it with the original CLWEs. This crucial step is done via 1) creating a word similarity dataset, comprising positive word pairs (i.e., true translations) and hard negative pairs induced from the original CLWE space, and then 2) fine-tuning an mPLM (e.g., mBERT or XLM-R) in a cross-encoder manner to predict the similarity scores. At inference, we 3) combine the similarity score from the original CLWE space with the score from the BLI-tuned cross-encoder. BLICEr establishes new state-of-the-art results on two standard BLI benchmarks spanning a wide spectrum of diverse languages: it substantially outperforms a series of strong baselines across the board. We also validate the robustness of BLICEr with different CLWEs.
How to tackle an emerging topic? Combining strong and weak labels for Covid news NER
Oct 08, 2022
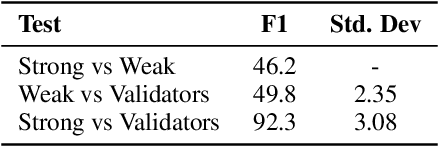

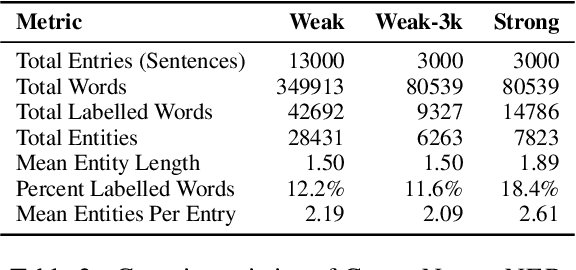
Being able to train Named Entity Recognition (NER) models for emerging topics is crucial for many real-world applications especially in the medical domain where new topics are continuously evolving out of the scope of existing models and datasets. For a realistic evaluation setup, we introduce a novel COVID-19 news NER dataset (COVIDNEWS-NER) and release 3000 entries of hand annotated strongly labelled sentences and 13000 auto-generated weakly labelled sentences. Besides the dataset, we propose CONTROSTER, a recipe to strategically combine weak and strong labels in improving NER in an emerging topic through transfer learning. We show the effectiveness of CONTROSTER on COVIDNEWS-NER while providing analysis on combining weak and strong labels for training. Our key findings are: (1) Using weak data to formulate an initial backbone before tuning on strong data outperforms methods trained on only strong or weak data. (2) A combination of out-of-domain and in-domain weak label training is crucial and can overcome saturation when being training on weak labels from a single source.
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
Oct 07, 2022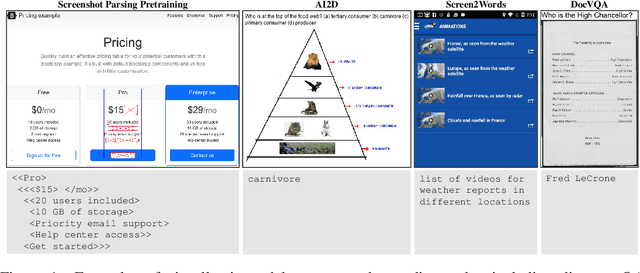


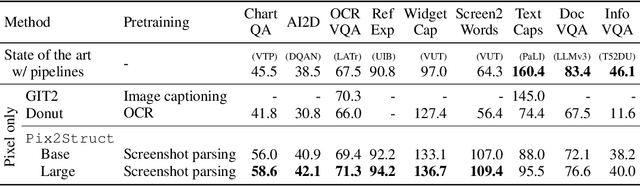
Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.