 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDial HEALTHDIAL for Advice: A Multilingual and Multi-Parallel Spoken Dialogue Dataset for Knowledge-Grounded Information Seeking
May 28, 2026Creating spoken dialogue datasets is methodologically challenging, and these challenges are amplified when the goal is to build multilingual, multi-parallel datasets at scale. This work introduces HEALTHDIAL, a large-scale, multilingual, and multi-parallel dataset for developing and evaluating retrieval-augmented generation (RAG)-based spoken dialogue systems. The dataset comprises 6,000 information-seeking dialogues (1,500 per language) grounded in trusted content from the World Health Organization (WHO) and 163 hours of user speech recorded from native speakers of diverse dialects across four official WHO languages: Arabic, Chinese, English, and Spanish. Each speaker is annotated with demographic (e.g., gender, age) and sociolinguistic (e.g., primary language, region of origin) variables. We report benchmark results across key dialogue tasks, which reveal consistent performance disparities across languages, even among high-resource ones. To support future research, we release the dataset, a prototype system, and a toolkit for data collection and system evaluation.
Multilinguality at the Edge: Developing Language Models for the Global South
Apr 23, 2026Where and how language models (LMs) are deployed determines who can benefit from them. However, there are several challenges that prevent effective deployment of LMs in non-English-speaking and hardware constrained communities in the Global South. We call this challenge the last mile: the intersection of multilinguality and edge deployment, where the goals are aligned but the technical requirements often compete. Studying these two fields together is both a need, as linguistically diverse communities often face the most severe infrastructure constraints, and an opportunity, as edge and multilingual NLP research remain largely siloed. To understand the state of the art and the challenges of combining the two areas, we survey 232 papers that tackle this problem across the language modelling pipeline, from data collection to development and deployment. We also discuss open questions and provide actionable recommendations for different stakeholders in the NLP ecosystem. Finally, we hope that this work contributes to the development of inclusive and equitable language technologies.
Minimalist Compliance Control
Mar 01, 2026Compliance control is essential for safe physical interaction, yet its adoption is limited by hardware requirements such as force torque sensors. While recent reinforcement learning approaches aim to bypass these constraints, they often suffer from sim-to-real gaps, lack safety guarantees, and add system complexity. We propose Minimalist Compliance Control, which enables compliant behavior using only motor current or voltage signals readily available in modern servos and quasi-direct-drive motors, without force sensors, current control, or learning. External wrenches are estimated from actuator signals and Jacobians and incorporated into a task-space admittance controller, preserving sufficient force measurement accuracy for stable and responsive compliance control. Our method is embodiment-agnostic and plug-and-play with diverse high-level planners. We validate our approach on a robot arm, a dexterous hand, and two humanoid robots across multiple contact-rich tasks, using vision-language models, imitation learning, and model-based planning. The results demonstrate robust, safe, and compliant interaction across embodiments and planning paradigms.
Artificial intelligence is creating a new global linguistic hierarchy
Feb 12, 2026Artificial intelligence (AI) has the potential to transform healthcare, education, governance and socioeconomic equity, but its benefits remain concentrated in a small number of languages (Bender, 2019; Blasi et al., 2022; Joshi et al., 2020; Ranathunga and de Silva, 2022; Young, 2015). Language AI - the technologies that underpin widely-used conversational systems such as ChatGPT - could provide major benefits if available in people's native languages, yet most of the world's 7,000+ linguistic communities currently lack access and face persistent digital marginalization. Here we present a global longitudinal analysis of social, economic and infrastructural conditions across languages to assess systemic inequalities in language AI. We first analyze the existence of AI resources for 6003 languages. We find that despite efforts of the community to broaden the reach of language technologies (Bapna et al., 2022; Costa-Jussà et al., 2022), the dominance of a handful of languages is exacerbating disparities on an unprecedented scale, with divides widening exponentially rather than narrowing. Further, we contrast the longitudinal diffusion of AI with that of earlier IT technologies, revealing a distinctive hype-driven pattern of spread. To translate our findings into practical insights and guide prioritization efforts, we introduce the Language AI Readiness Index (EQUATE), which maps the state of technological, socio-economic, and infrastructural prerequisites for AI deployment across languages. The index highlights communities where capacity exists but remains underutilized, and provides a framework for accelerating more equitable diffusion of language AI. Our work contributes to setting the baseline for a transition towards more sustainable and equitable language technologies.
4D Visual Pre-training for Robot Learning
Aug 24, 2025



General visual representations learned from web-scale datasets for robotics have achieved great success in recent years, enabling data-efficient robot learning on manipulation tasks; yet these pre-trained representations are mostly on 2D images, neglecting the inherent 3D nature of the world. However, due to the scarcity of large-scale 3D data, it is still hard to extract a universal 3D representation from web datasets. Instead, we are seeking a general visual pre-training framework that could improve all 3D representations as an alternative. Our framework, called FVP, is a novel 4D Visual Pre-training framework for real-world robot learning. FVP frames the visual pre-training objective as a next-point-cloud-prediction problem, models the prediction model as a diffusion model, and pre-trains the model on the larger public datasets directly. Across twelve real-world manipulation tasks, FVP boosts the average success rate of 3D Diffusion Policy (DP3) for these tasks by 28%. The FVP pre-trained DP3 achieves state-of-the-art performance across imitation learning methods. Moreover, the efficacy of FVP adapts across various point cloud encoders and datasets. Finally, we apply FVP to the RDT-1B, a larger Vision-Language-Action robotic model, enhancing its performance on various robot tasks. Our project page is available at: https://4d- visual-pretraining.github.io/.
Quantifying Language Disparities in Multilingual Large Language Models
Aug 23, 2025Results reported in large-scale multilingual evaluations are often fragmented and confounded by factors such as target languages, differences in experimental setups, and model choices. We propose a framework that disentangles these confounding variables and introduces three interpretable metrics--the performance realisation ratio, its coefficient of variation, and language potential--enabling a finer-grained and more insightful quantification of actual performance disparities across both (i) models and (ii) languages. Through a case study of 13 model variants on 11 multilingual datasets, we demonstrate that our framework provides a more reliable measurement of model performance and language disparities, particularly for low-resource languages, which have so far proven challenging to evaluate. Importantly, our results reveal that higher overall model performance does not necessarily imply greater fairness across languages.
DOGlove: Dexterous Manipulation with a Low-Cost Open-Source Haptic Force Feedback Glove
Feb 11, 2025



Dexterous hand teleoperation plays a pivotal role in enabling robots to achieve human-level manipulation dexterity. However, current teleoperation systems often rely on expensive equipment and lack multi-modal sensory feedback, restricting human operators' ability to perceive object properties and perform complex manipulation tasks. To address these limitations, we present DOGlove, a low-cost, precise, and haptic force feedback glove system for teleoperation and manipulation. DoGlove can be assembled in hours at a cost under 600 USD. It features a customized joint structure for 21-DoF motion capture, a compact cable-driven torque transmission mechanism for 5-DoF multidirectional force feedback, and a linear resonate actuator for 5-DoF fingertip haptic feedback. Leveraging action and haptic force retargeting, DOGlove enables precise and immersive teleoperation of dexterous robotic hands, achieving high success rates in complex, contact-rich tasks. We further evaluate DOGlove in scenarios without visual feedback, demonstrating the critical role of haptic force feedback in task performance. In addition, we utilize the collected demonstrations to train imitation learning policies, highlighting the potential and effectiveness of DOGlove. DOGlove's hardware and software system will be fully open-sourced at https://do-glove.github.io/.
Large Language Models and Thematic Analysis: Human-AI Synergy in Researching Hate Speech on Social Media
Aug 09, 2024
In the dynamic field of artificial intelligence (AI), the development and application of Large Language Models (LLMs) for text analysis are of significant academic interest. Despite the promising capabilities of various LLMs in conducting qualitative analysis, their use in the humanities and social sciences has not been thoroughly examined. This article contributes to the emerging literature on LLMs in qualitative analysis by documenting an experimental study involving GPT-4. The study focuses on performing thematic analysis (TA) using a YouTube dataset derived from an EU-funded project, which was previously analyzed by other researchers. This dataset is about the representation of Roma migrants in Sweden during 2016, a period marked by the aftermath of the 2015 refugee crisis and preceding the Swedish national elections in 2017. Our study seeks to understand the potential of combining human intelligence with AI's scalability and efficiency, examining the advantages and limitations of employing LLMs in qualitative research within the humanities and social sciences. Additionally, we discuss future directions for applying LLMs in these fields.
DIALIGHT: Lightweight Multilingual Development and Evaluation of Task-Oriented Dialogue Systems with Large Language Models
Jan 04, 2024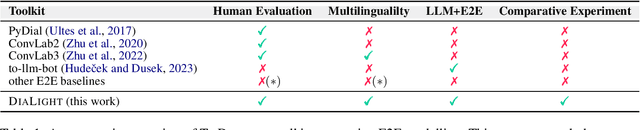
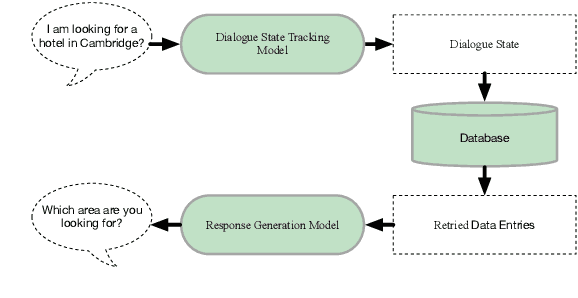
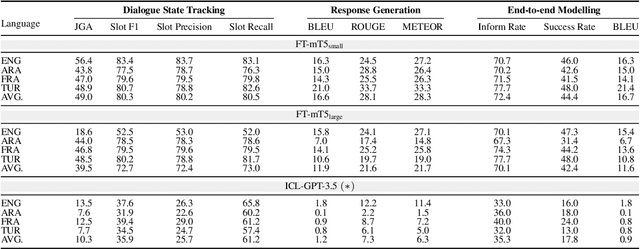
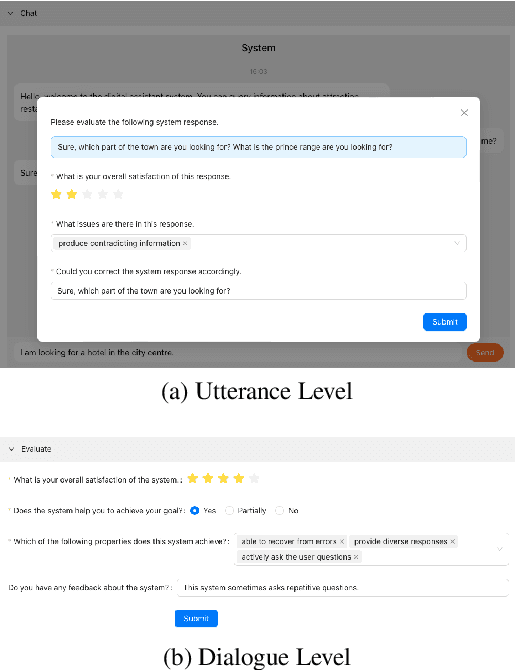
We present DIALIGHT, a toolkit for developing and evaluating multilingual Task-Oriented Dialogue (ToD) systems which facilitates systematic evaluations and comparisons between ToD systems using fine-tuning of Pretrained Language Models (PLMs) and those utilising the zero-shot and in-context learning capabilities of Large Language Models (LLMs). In addition to automatic evaluation, this toolkit features (i) a secure, user-friendly web interface for fine-grained human evaluation at both local utterance level and global dialogue level, and (ii) a microservice-based backend, improving efficiency and scalability. Our evaluations reveal that while PLM fine-tuning leads to higher accuracy and coherence, LLM-based systems excel in producing diverse and likeable responses. However, we also identify significant challenges of LLMs in adherence to task-specific instructions and generating outputs in multiple languages, highlighting areas for future research. We hope this open-sourced toolkit will serve as a valuable resource for researchers aiming to develop and properly evaluate multilingual ToD systems and will lower, currently still high, entry barriers in the field.
A Systematic Study of Performance Disparities in Multilingual Task-Oriented Dialogue Systems
Oct 19, 2023



Achieving robust language technologies that can perform well across the world's many languages is a central goal of multilingual NLP. In this work, we take stock of and empirically analyse task performance disparities that exist between multilingual task-oriented dialogue (ToD) systems. We first define new quantitative measures of absolute and relative equivalence in system performance, capturing disparities across languages and within individual languages. Through a series of controlled experiments, we demonstrate that performance disparities depend on a number of factors: the nature of the ToD task at hand, the underlying pretrained language model, the target language, and the amount of ToD annotated data. We empirically prove the existence of the adaptation and intrinsic biases in current ToD systems: e.g., ToD systems trained for Arabic or Turkish using annotated ToD data fully parallel to English ToD data still exhibit diminished ToD task performance. Beyond providing a series of insights into the performance disparities of ToD systems in different languages, our analyses offer practical tips on how to approach ToD data collection and system development for new languages.