 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Old Photos Back to Life
Apr 20, 2020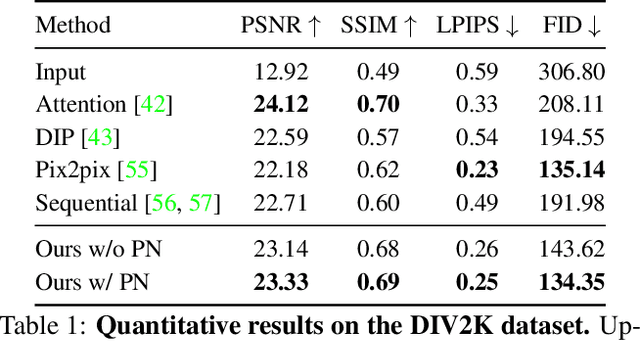
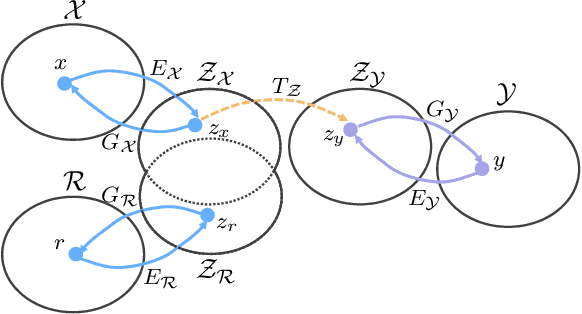
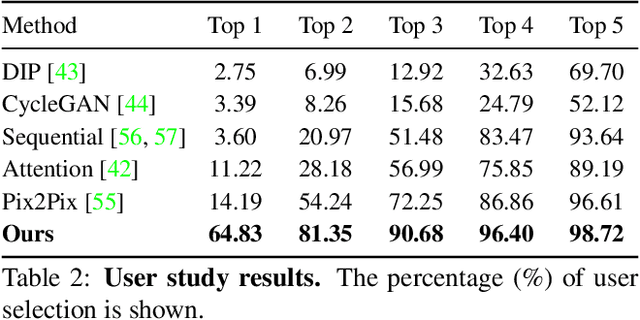
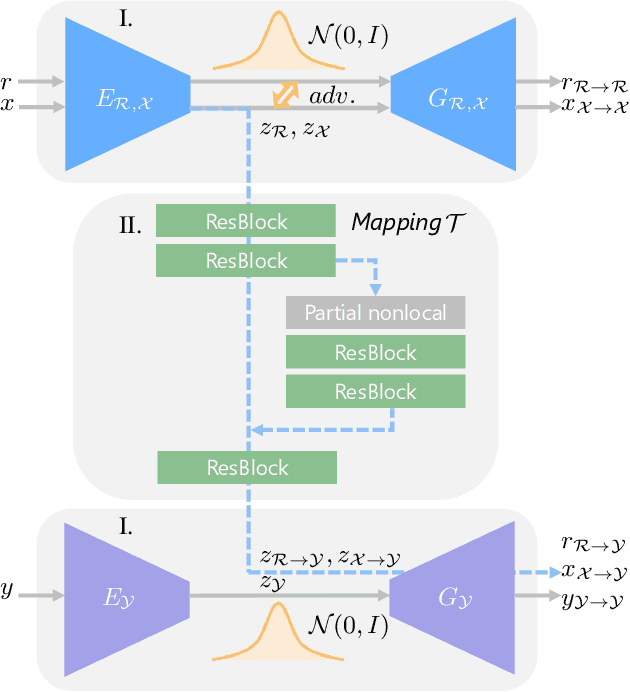
We propose to restore old photos that suffer from severe degradation through a deep learning approach. Unlike conventional restoration tasks that can be solved through supervised learning, the degradation in real photos is complex and the domain gap between synthetic images and real old photos makes the network fail to generalize. Therefore, we propose a novel triplet domain translation network by leveraging real photos along with massive synthetic image pairs. Specifically, we train two variational autoencoders (VAEs) to respectively transform old photos and clean photos into two latent spaces. And the translation between these two latent spaces is learned with synthetic paired data. This translation generalizes well to real photos because the domain gap is closed in the compact latent space. Besides, to address multiple degradations mixed in one old photo, we design a global branch with a partial nonlocal block targeting to the structured defects, such as scratches and dust spots, and a local branch targeting to the unstructured defects, such as noises and blurriness. Two branches are fused in the latent space, leading to improved capability to restore old photos from multiple defects. The proposed method outperforms state-of-the-art methods in terms of visual quality for old photos restoration.
Cross-domain Correspondence Learning for Exemplar-based Image Translation
Apr 12, 2020
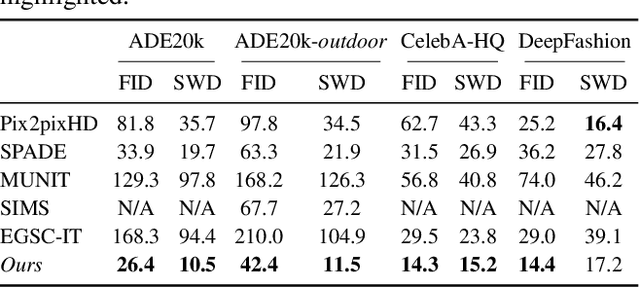
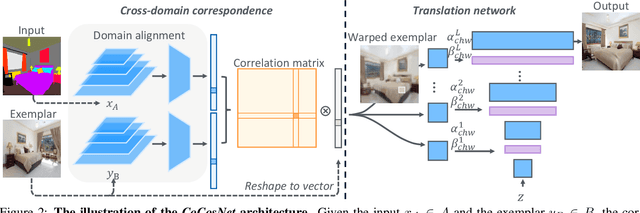
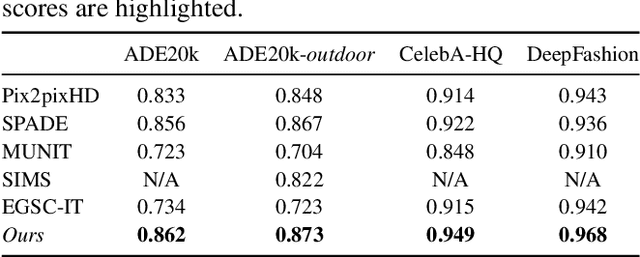
We present a general framework for exemplar-based image translation, which synthesizes a photo-realistic image from the input in a distinct domain (e.g., semantic segmentation mask, or edge map, or pose keypoints), given an exemplar image. The output has the style (e.g., color, texture) in consistency with the semantically corresponding objects in the exemplar. We propose to jointly learn the crossdomain correspondence and the image translation, where both tasks facilitate each other and thus can be learned with weak supervision. The images from distinct domains are first aligned to an intermediate domain where dense correspondence is established. Then, the network synthesizes images based on the appearance of semantically corresponding patches in the exemplar. We demonstrate the effectiveness of our approach in several image translation tasks. Our method is superior to state-of-the-art methods in terms of image quality significantly, with the image style faithful to the exemplar with semantic consistency. Moreover, we show the utility of our method for several applications
* Accepted as a CVPR 2020 oral paper
GIQA: Generated Image Quality Assessment
Mar 19, 2020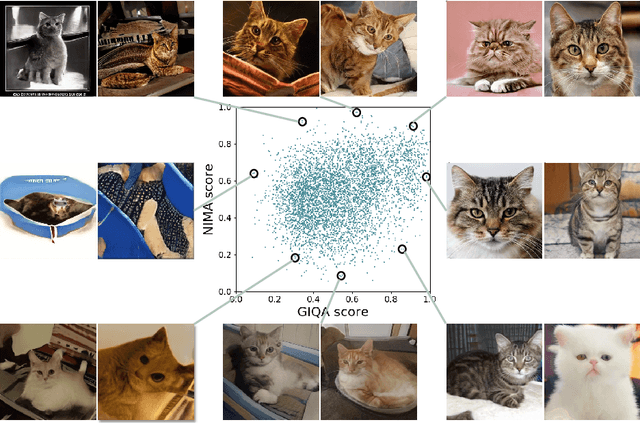
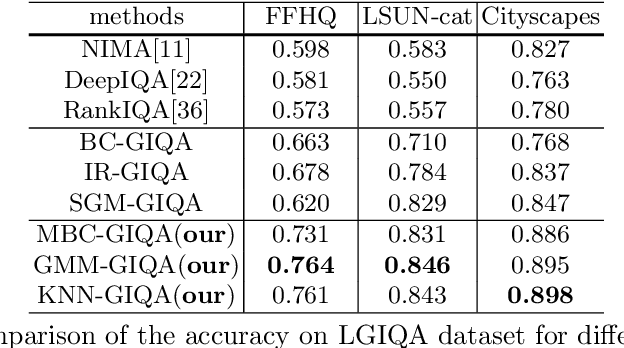
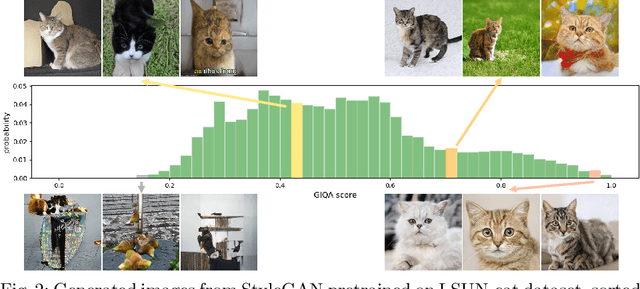

Generative adversarial networks (GANs) have achieved impressive results today, but not all generated images are perfect. A number of quantitative criteria have recently emerged for generative model, but none of them are designed for a single generated image. In this paper, we propose a new research topic, Generated Image Quality Assessment (GIQA), which quantitatively evaluates the quality of each generated image. We introduce three GIQA algorithms from two perspectives: learning-based and data-based. We evaluate a number of images generated by various recent GAN models on different datasets and demonstrate that they are consistent with human assessments. Furthermore, GIQA is available to many applications, like separately evaluating the realism and diversity of generative models, and enabling online hard negative mining (OHEM) in the training of GANs to improve the results.
Face X-ray for More General Face Forgery Detection
Dec 31, 2019
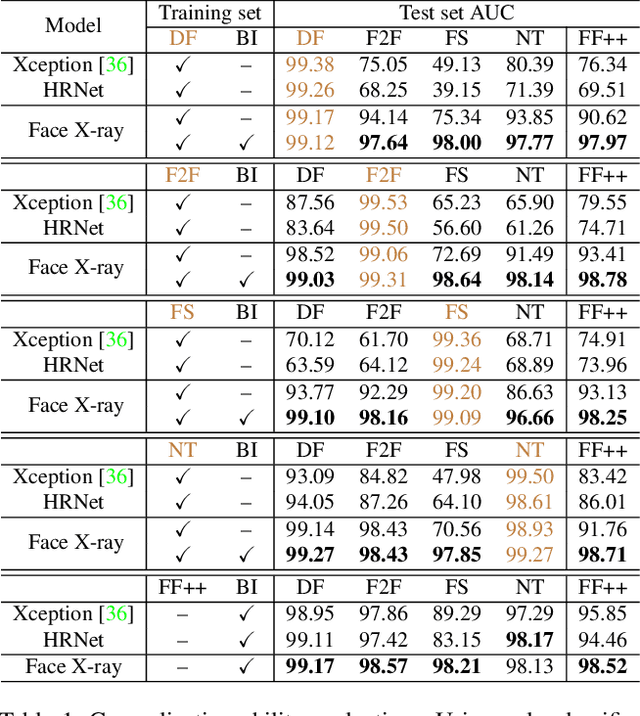


In this paper we propose a novel image representation called face X-ray for detecting forgery in face images. The face X-ray of an input face image is a greyscale image that reveals whether the input image can be decomposed into the blending of two images from different sources. It does so by showing the blending boundary for a forged image and the absence of blending for a real image. We observe that most existing face manipulation methods share a common step: blending the altered face into an existing background image. For this reason, face X-ray provides an effective way for detecting forgery generated by most existing face manipulation algorithms. Face X-ray is general in the sense that it only assumes the existence of a blending step and does not rely on any knowledge of the artifacts associated with a specific face manipulation technique. Indeed, the algorithm for computing face X-ray can be trained without fake images generated by any of the state-of-the-art face manipulation methods. Extensive experiments show that face X-ray remains effective when applied to forgery generated by unseen face manipulation techniques, while most existing face forgery detection algorithms experience a significant performance drop.
FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping
Dec 31, 2019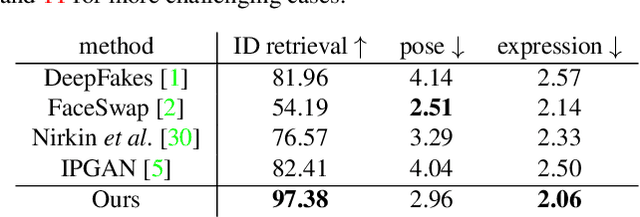


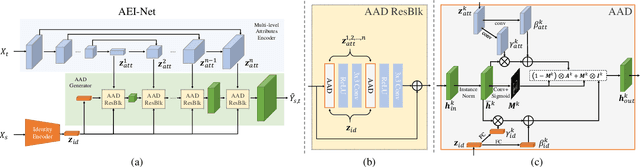
In this work, we propose a novel two-stage framework, called FaceShifter, for high fidelity and occlusion aware face swapping. Unlike many existing face swapping works that leverage only limited information from the target image when synthesizing the swapped face, our framework, in its first stage, generates the swapped face in high-fidelity by exploiting and integrating the target attributes thoroughly and adaptively. We propose a novel attributes encoder for extracting multi-level target face attributes, and a new generator with carefully designed Adaptive Attentional Denormalization (AAD) layers to adaptively integrate the identity and the attributes for face synthesis. To address the challenging facial occlusions, we append a second stage consisting of a novel Heuristic Error Acknowledging Refinement Network (HEAR-Net). It is trained to recover anomaly regions in a self-supervised way without any manual annotations. Extensive experiments on wild faces demonstrate that our face swapping results are not only considerably more perceptually appealing, but also better identity preserving in comparison to other state-of-the-art methods.
Face Parsing with RoI Tanh-Warping
Jun 04, 2019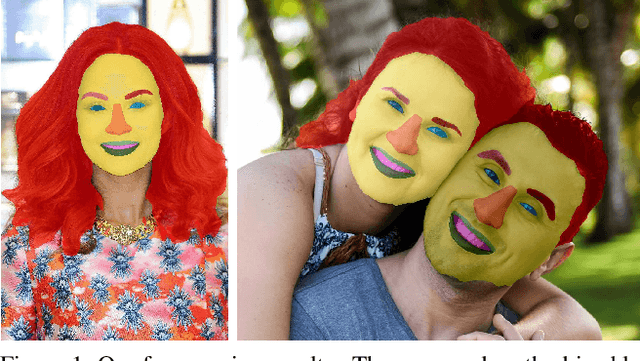
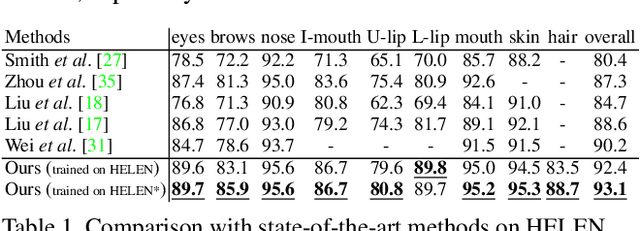
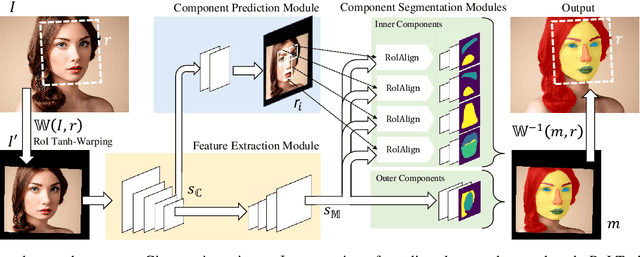
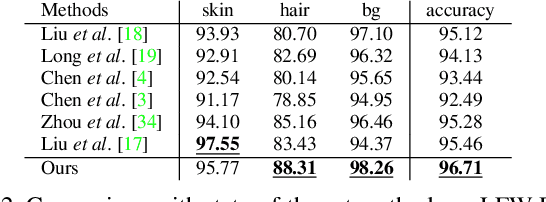
Face parsing computes pixel-wise label maps for different semantic components (e.g., hair, mouth, eyes) from face images. Existing face parsing literature have illustrated significant advantages by focusing on individual regions of interest (RoIs) for faces and facial components. However, the traditional crop-and-resize focusing mechanism ignores all contextual area outside the RoIs, and thus is not suitable when the component area is unpredictable, e.g. hair. Inspired by the physiological vision system of human, we propose a novel RoI Tanh-warping operator that combines the central vision and the peripheral vision together. It addresses the dilemma between a limited sized RoI for focusing and an unpredictable area of surrounding context for peripheral information. To this end, we propose a novel hybrid convolutional neural network for face parsing. It uses hierarchical local based method for inner facial components and global methods for outer facial components. The whole framework is simple and principled, and can be trained end-to-end. To facilitate future research of face parsing, we also manually relabel the training data of the HELEN dataset and will make it public. Experiments on both HELEN and LFW-PL benchmarks demonstrate that our method surpasses state-of-the-art methods.
Mask-Guided Portrait Editing with Conditional GANs
May 24, 2019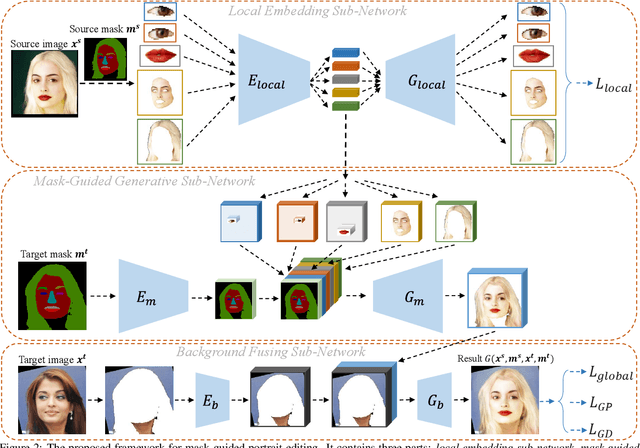
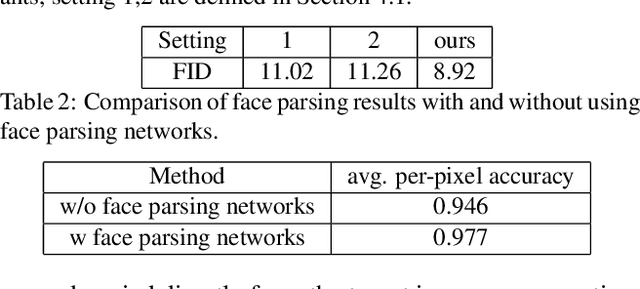


Portrait editing is a popular subject in photo manipulation. The Generative Adversarial Network (GAN) advances the generating of realistic faces and allows more face editing. In this paper, we argue about three issues in existing techniques: diversity, quality, and controllability for portrait synthesis and editing. To address these issues, we propose a novel end-to-end learning framework that leverages conditional GANs guided by provided face masks for generating faces. The framework learns feature embeddings for every face component (e.g., mouth, hair, eye), separately, contributing to better correspondences for image translation, and local face editing. With the mask, our network is available to many applications, like face synthesis driven by mask, face Swap+ (including hair in swapping), and local manipulation. It can also boost the performance of face parsing a bit as an option of data augmentation.
Towards Open-Set Identity Preserving Face Synthesis
Aug 09, 2018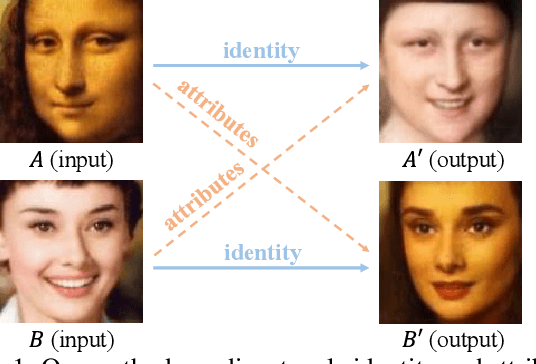

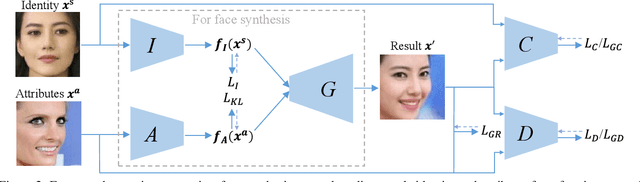
We propose a framework based on Generative Adversarial Networks to disentangle the identity and attributes of faces, such that we can conveniently recombine different identities and attributes for identity preserving face synthesis in open domains. Previous identity preserving face synthesis processes are largely confined to synthesizing faces with known identities that are already in the training dataset. To synthesize a face with identity outside the training dataset, our framework requires one input image of that subject to produce an identity vector, and any other input face image to extract an attribute vector capturing, e.g., pose, emotion, illumination, and even the background. We then recombine the identity vector and the attribute vector to synthesize a new face of the subject with the extracted attribute. Our proposed framework does not need to annotate the attributes of faces in any way. It is trained with an asymmetric loss function to better preserve the identity and stabilize the training process. It can also effectively leverage large amounts of unlabeled training face images to further improve the fidelity of the synthesized faces for subjects that are not presented in the labeled training face dataset. Our experiments demonstrate the efficacy of the proposed framework. We also present its usage in a much broader set of applications including face frontalization, face attribute morphing, and face adversarial example detection.
CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training
Oct 12, 2017
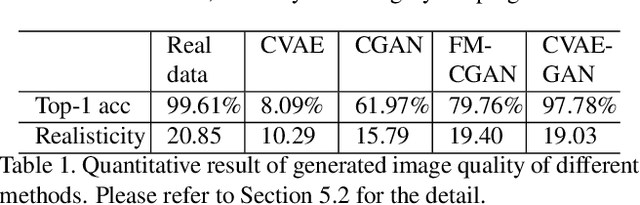
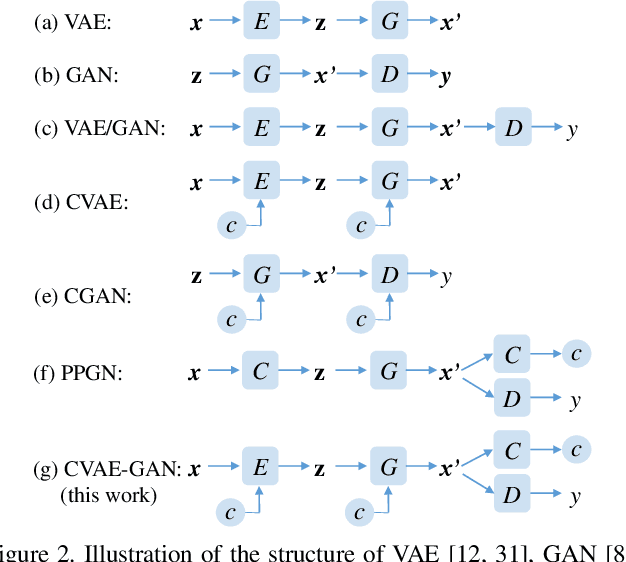
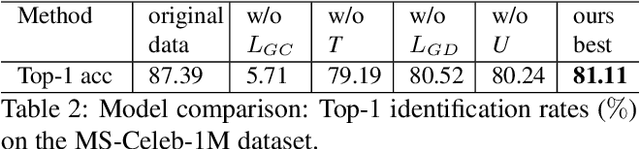
We present variational generative adversarial networks, a general learning framework that combines a variational auto-encoder with a generative adversarial network, for synthesizing images in fine-grained categories, such as faces of a specific person or objects in a category. Our approach models an image as a composition of label and latent attributes in a probabilistic model. By varying the fine-grained category label fed into the resulting generative model, we can generate images in a specific category with randomly drawn values on a latent attribute vector. Our approach has two novel aspects. First, we adopt a cross entropy loss for the discriminative and classifier network, but a mean discrepancy objective for the generative network. This kind of asymmetric loss function makes the GAN training more stable. Second, we adopt an encoder network to learn the relationship between the latent space and the real image space, and use pairwise feature matching to keep the structure of generated images. We experiment with natural images of faces, flowers, and birds, and demonstrate that the proposed models are capable of generating realistic and diverse samples with fine-grained category labels. We further show that our models can be applied to other tasks, such as image inpainting, super-resolution, and data augmentation for training better face recognition models.
Neural Aggregation Network for Video Face Recognition
Aug 02, 2017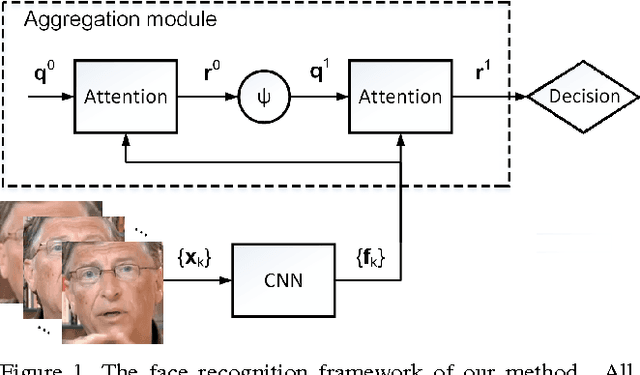
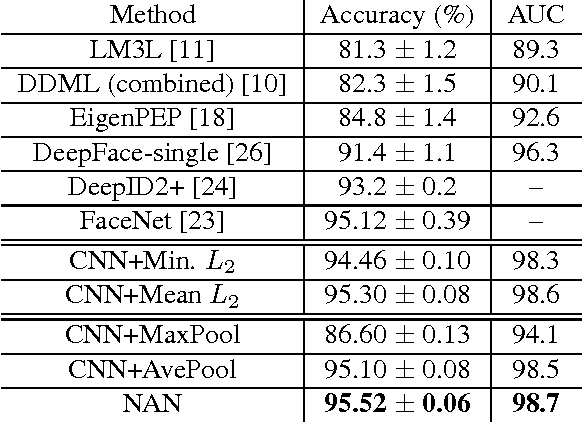
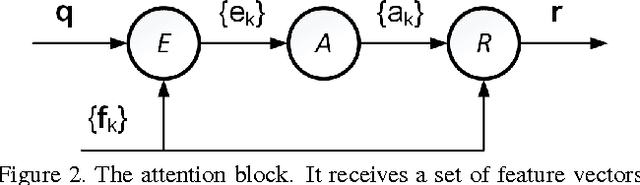
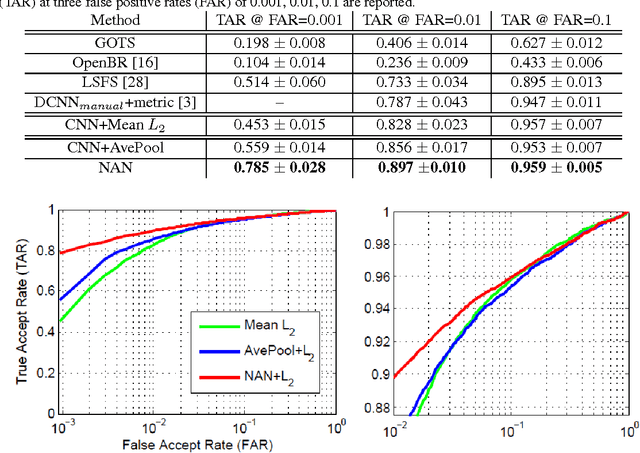
This paper presents a Neural Aggregation Network (NAN) for video face recognition. The network takes a face video or face image set of a person with a variable number of face images as its input, and produces a compact, fixed-dimension feature representation for recognition. The whole network is composed of two modules. The feature embedding module is a deep Convolutional Neural Network (CNN) which maps each face image to a feature vector. The aggregation module consists of two attention blocks which adaptively aggregate the feature vectors to form a single feature inside the convex hull spanned by them. Due to the attention mechanism, the aggregation is invariant to the image order. Our NAN is trained with a standard classification or verification loss without any extra supervision signal, and we found that it automatically learns to advocate high-quality face images while repelling low-quality ones such as blurred, occluded and improperly exposed faces. The experiments on IJB-A, YouTube Face, Celebrity-1000 video face recognition benchmarks show that it consistently outperforms naive aggregation methods and achieves the state-of-the-art accuracy.