 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Test-time Adaptation by Entropy Minimization
Jun 18, 2020
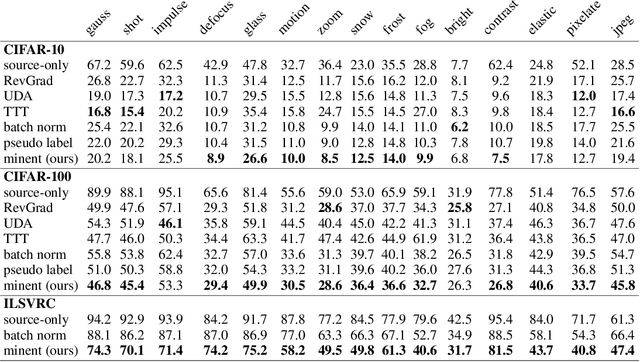

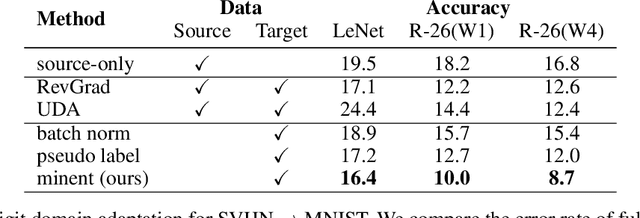
Faced with new and different data during testing, a model must adapt itself. We consider the setting of fully test-time adaptation, in which a supervised model confronts unlabeled test data from a different distribution, without the help of its labeled training data. We propose an entropy minimization approach for adaptation: we take the model's confidence as our objective as measured by the entropy of its predictions. During testing, we adapt the model by modulating its representation with affine transformations to minimize entropy. Our experiments show improved robustness to corruptions for image classification on CIFAR-10/100 and ILSVRC and demonstrate the feasibility of target-only domain adaptation for digit classification on MNIST and SVHN.
Dynamic Scale Inference by Entropy Minimization
Aug 08, 2019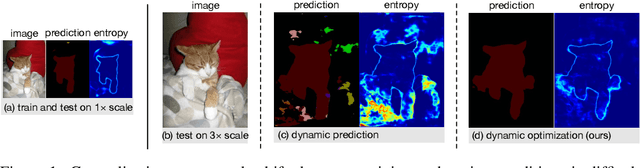
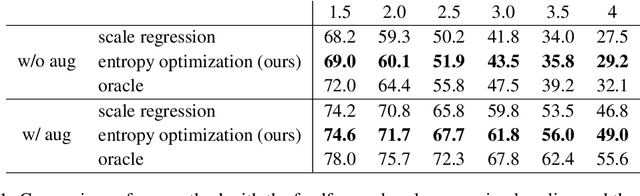
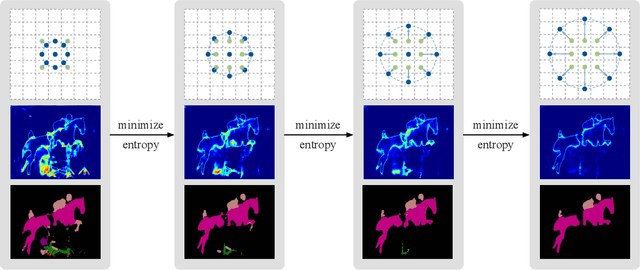
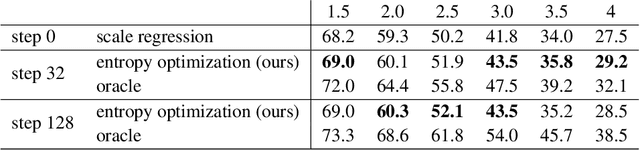
Given the variety of the visual world there is not one true scale for recognition: objects may appear at drastically different sizes across the visual field. Rather than enumerate variations across filter channels or pyramid levels, dynamic models locally predict scale and adapt receptive fields accordingly. The degree of variation and diversity of inputs makes this a difficult task. Existing methods either learn a feedforward predictor, which is not itself totally immune to the scale variation it is meant to counter, or select scales by a fixed algorithm, which cannot learn from the given task and data. We extend dynamic scale inference from feedforward prediction to iterative optimization for further adaptivity. We propose a novel entropy minimization objective for inference and optimize over task and structure parameters to tune the model to each input. Optimization during inference improves semantic segmentation accuracy and generalizes better to extreme scale variations that cause feedforward dynamic inference to falter.
Blurring the Line Between Structure and Learning to Optimize and Adapt Receptive Fields
Apr 25, 2019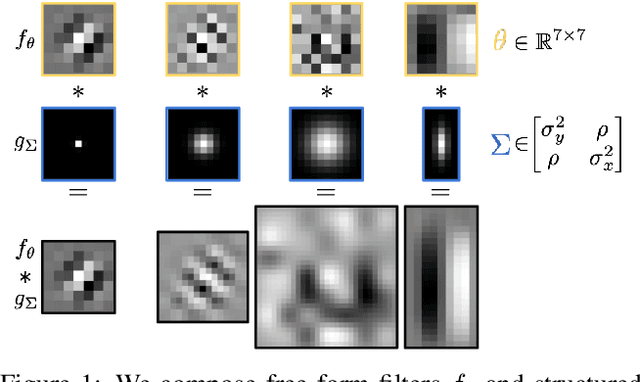
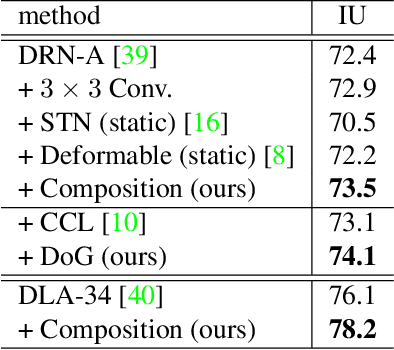


The visual world is vast and varied, but its variations divide into structured and unstructured factors. We compose free-form filters and structured Gaussian filters, optimized end-to-end, to factorize deep representations and learn both local features and their degree of locality. Our semi-structured composition is strictly more expressive than free-form filtering, and changes in its structured parameters would require changes in free-form architecture. In effect this optimizes over receptive field size and shape, tuning locality to the data and task. Dynamic inference, in which the Gaussian structure varies with the input, adapts receptive field size to compensate for local scale variation. Optimizing receptive field size improves semantic segmentation accuracy on Cityscapes by 1-2 points for strong dilated and skip architectures and by up to 10 points for suboptimal designs. Adapting receptive fields by dynamic Gaussian structure further improves results, equaling the accuracy of free-form deformation while improving efficiency.
Infinite Mixture Prototypes for Few-Shot Learning
Feb 12, 2019

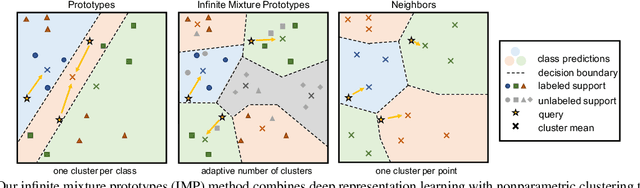

We propose infinite mixture prototypes to adaptively represent both simple and complex data distributions for few-shot learning. Our infinite mixture prototypes represent each class by a set of clusters, unlike existing prototypical methods that represent each class by a single cluster. By inferring the number of clusters, infinite mixture prototypes interpolate between nearest neighbor and prototypical representations, which improves accuracy and robustness in the few-shot regime. We show the importance of adaptive capacity for capturing complex data distributions such as alphabets, with 25% absolute accuracy improvements over prototypical networks, while still maintaining or improving accuracy on the standard Omniglot and mini-ImageNet benchmarks. In clustering labeled and unlabeled data by the same clustering rule, infinite mixture prototypes achieves state-of-the-art semi-supervised accuracy. As a further capability, we show that infinite mixture prototypes can perform purely unsupervised clustering, unlike existing prototypical methods.
Few-Shot Segmentation Propagation with Guided Networks
May 25, 2018

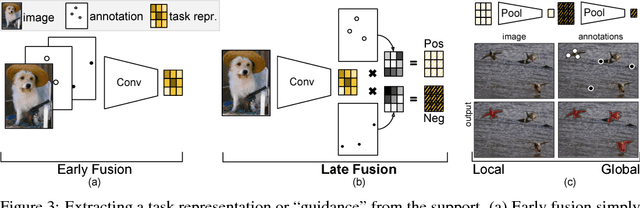

Learning-based methods for visual segmentation have made progress on particular types of segmentation tasks, but are limited by the necessary supervision, the narrow definitions of fixed tasks, and the lack of control during inference for correcting errors. To remedy the rigidity and annotation burden of standard approaches, we address the problem of few-shot segmentation: given few image and few pixel supervision, segment any images accordingly. We propose guided networks, which extract a latent task representation from any amount of supervision, and optimize our architecture end-to-end for fast, accurate few-shot segmentation. Our method can switch tasks without further optimization and quickly update when given more guidance. We report the first results for segmentation from one pixel per concept and show real-time interactive video segmentation. Our unified approach propagates pixel annotations across space for interactive segmentation, across time for video segmentation, and across scenes for semantic segmentation. Our guided segmentor is state-of-the-art in accuracy for the amount of annotation and time. See http://github.com/shelhamer/revolver for code, models, and more details.
Zero-Shot Visual Imitation
Apr 23, 2018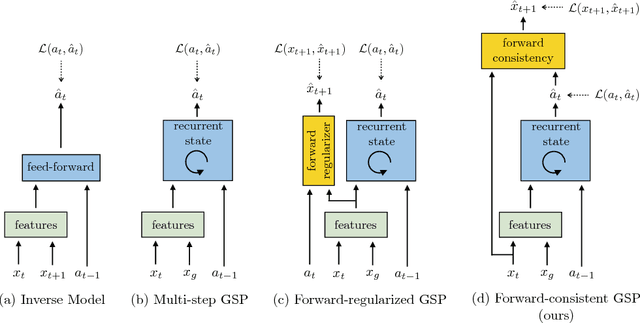
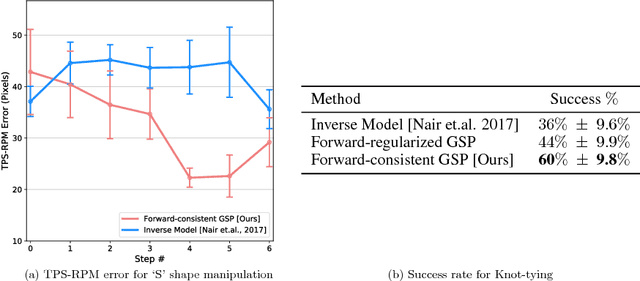


The current dominant paradigm for imitation learning relies on strong supervision of expert actions to learn both 'what' and 'how' to imitate. We pursue an alternative paradigm wherein an agent first explores the world without any expert supervision and then distills its experience into a goal-conditioned skill policy with a novel forward consistency loss. In our framework, the role of the expert is only to communicate the goals (i.e., what to imitate) during inference. The learned policy is then employed to mimic the expert (i.e., how to imitate) after seeing just a sequence of images demonstrating the desired task. Our method is 'zero-shot' in the sense that the agent never has access to expert actions during training or for the task demonstration at inference. We evaluate our zero-shot imitator in two real-world settings: complex rope manipulation with a Baxter robot and navigation in previously unseen office environments with a TurtleBot. Through further experiments in VizDoom simulation, we provide evidence that better mechanisms for exploration lead to learning a more capable policy which in turn improves end task performance. Videos, models, and more details are available at https://pathak22.github.io/zeroshot-imitation/
Deep Layer Aggregation
Jan 04, 2018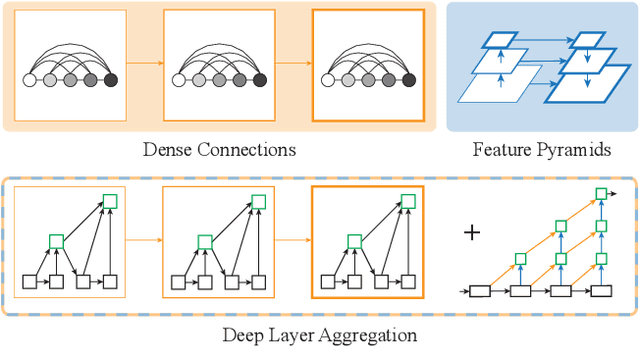
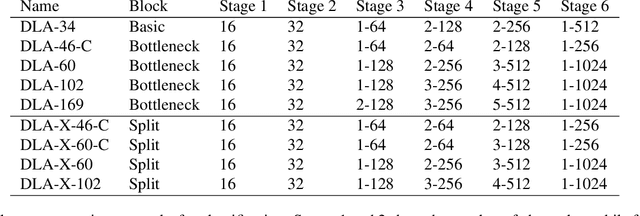
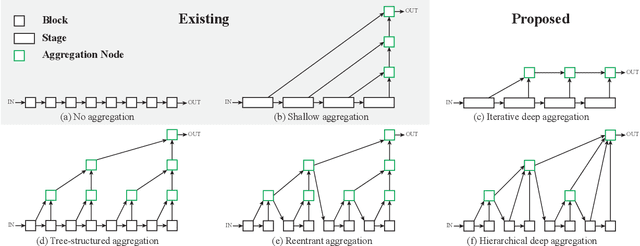
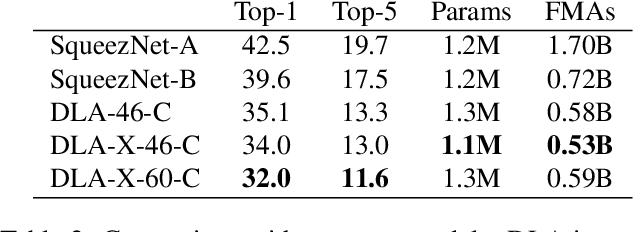
Visual recognition requires rich representations that span levels from low to high, scales from small to large, and resolutions from fine to coarse. Even with the depth of features in a convolutional network, a layer in isolation is not enough: compounding and aggregating these representations improves inference of what and where. Architectural efforts are exploring many dimensions for network backbones, designing deeper or wider architectures, but how to best aggregate layers and blocks across a network deserves further attention. Although skip connections have been incorporated to combine layers, these connections have been "shallow" themselves, and only fuse by simple, one-step operations. We augment standard architectures with deeper aggregation to better fuse information across layers. Our deep layer aggregation structures iteratively and hierarchically merge the feature hierarchy to make networks with better accuracy and fewer parameters. Experiments across architectures and tasks show that deep layer aggregation improves recognition and resolution compared to existing branching and merging schemes.
Loss is its own Reward: Self-Supervision for Reinforcement Learning
Mar 09, 2017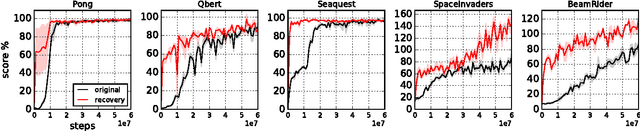
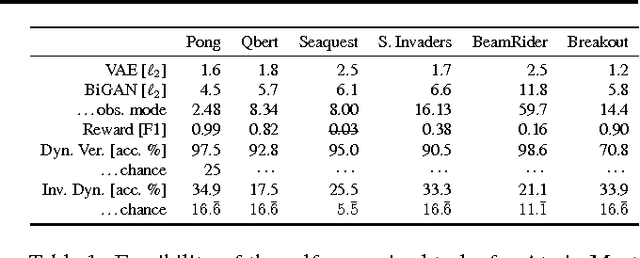
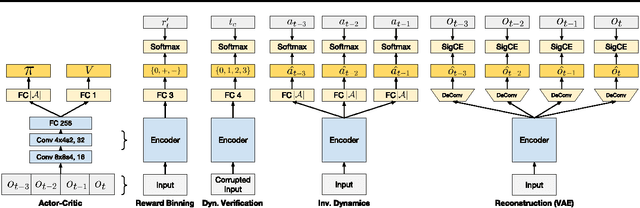
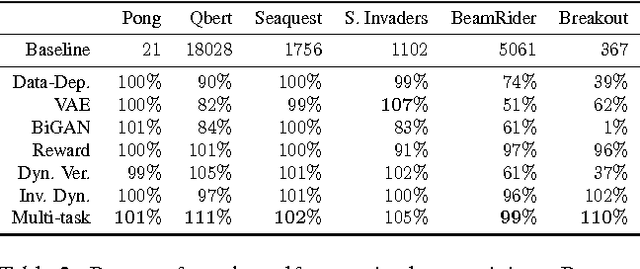
Reinforcement learning optimizes policies for expected cumulative reward. Need the supervision be so narrow? Reward is delayed and sparse for many tasks, making it a difficult and impoverished signal for end-to-end optimization. To augment reward, we consider a range of self-supervised tasks that incorporate states, actions, and successors to provide auxiliary losses. These losses offer ubiquitous and instantaneous supervision for representation learning even in the absence of reward. While current results show that learning from reward alone is feasible, pure reinforcement learning methods are constrained by computational and data efficiency issues that can be remedied by auxiliary losses. Self-supervised pre-training and joint optimization improve the data efficiency and policy returns of end-to-end reinforcement learning.
Clockwork Convnets for Video Semantic Segmentation
Aug 11, 2016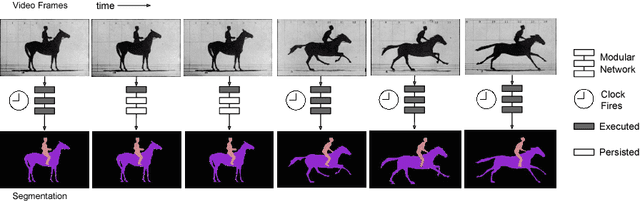
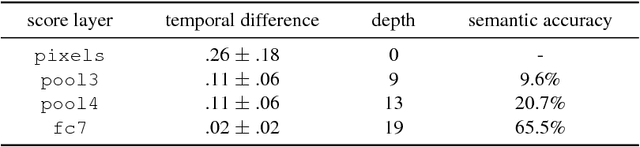
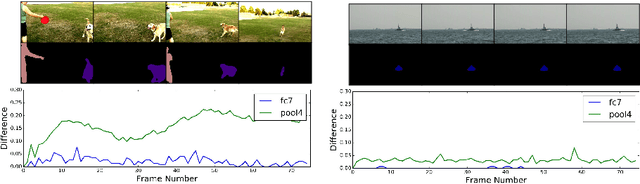
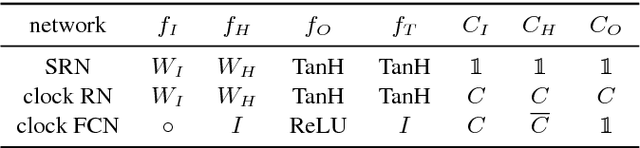
Recent years have seen tremendous progress in still-image segmentation; however the na\"ive application of these state-of-the-art algorithms to every video frame requires considerable computation and ignores the temporal continuity inherent in video. We propose a video recognition framework that relies on two key observations: 1) while pixels may change rapidly from frame to frame, the semantic content of a scene evolves more slowly, and 2) execution can be viewed as an aspect of architecture, yielding purpose-fit computation schedules for networks. We define a novel family of "clockwork" convnets driven by fixed or adaptive clock signals that schedule the processing of different layers at different update rates according to their semantic stability. We design a pipeline schedule to reduce latency for real-time recognition and a fixed-rate schedule to reduce overall computation. Finally, we extend clockwork scheduling to adaptive video processing by incorporating data-driven clocks that can be tuned on unlabeled video. The accuracy and efficiency of clockwork convnets are evaluated on the Youtube-Objects, NYUD, and Cityscapes video datasets.
Fully Convolutional Networks for Semantic Segmentation
May 20, 2016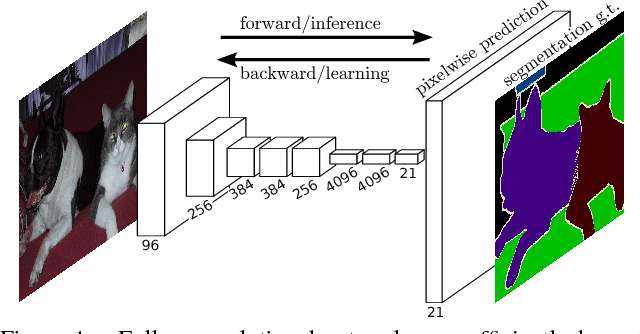
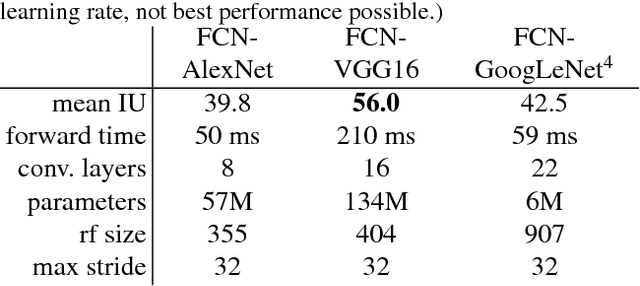
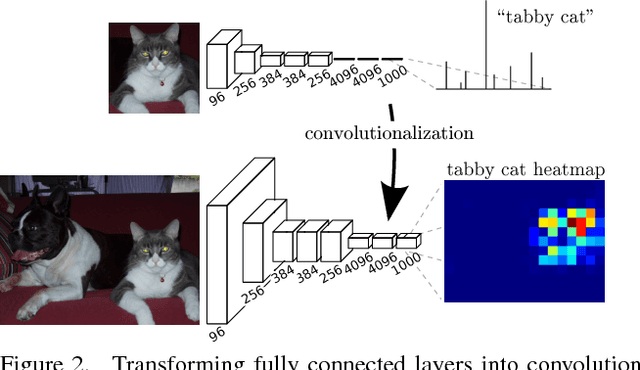
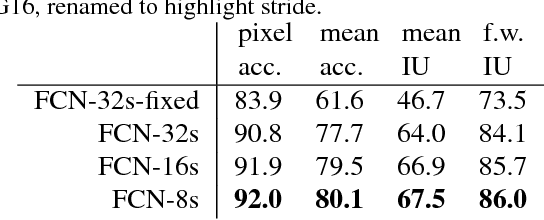
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.