 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralSim: Augmenting Differentiable Simulators with Neural Networks
Nov 09, 2020
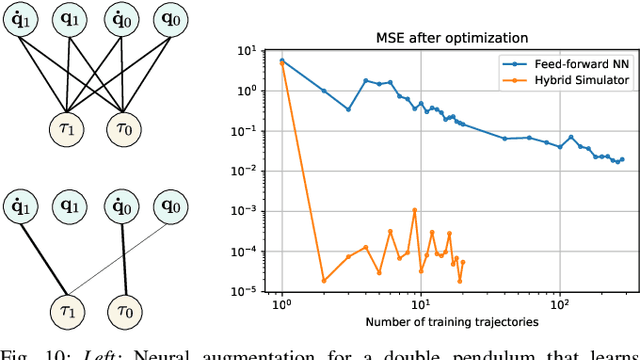
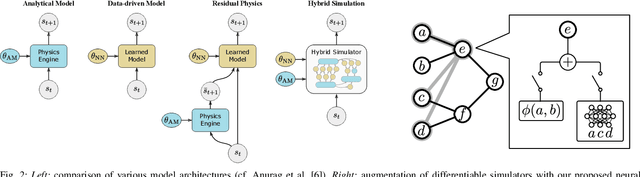
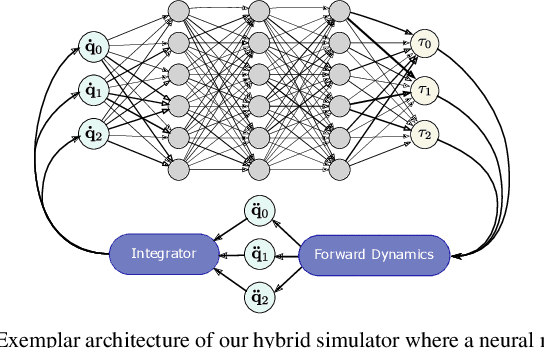
Differentiable simulators provide an avenue for closing the sim-to-real gap by enabling the use of efficient, gradient-based optimization algorithms to find the simulation parameters that best fit the observed sensor readings. Nonetheless, these analytical models can only predict the dynamical behavior of systems for which they have been designed. In this work, we study the augmentation of a novel differentiable rigid-body physics engine via neural networks that is able to learn nonlinear relationships between dynamic quantities and can thus learn effects not accounted for in traditional simulators.Such augmentations require less data to train and generalize better compared to entirely data-driven models. Through extensive experiments, we demonstrate the ability of our hybrid simulator to learn complex dynamics involving frictional contacts from real data, as well as match known models of viscous friction, and present an approach for automatically discovering useful augmentations. We show that, besides benefiting dynamics modeling, inserting neural networks can accelerate model-based control architectures. We observe a ten-fold speed-up when replacing the QP solver inside a model-predictive gait controller for quadruped robots with a neural network, allowing us to significantly improve control delays as we demonstrate in real-hardware experiments. We publish code, additional results and videos from our experiments on our project webpage at https://sites.google.com/usc.edu/neuralsim.
Augmenting Differentiable Simulators with Neural Networks to Close the Sim2Real Gap
Jul 12, 2020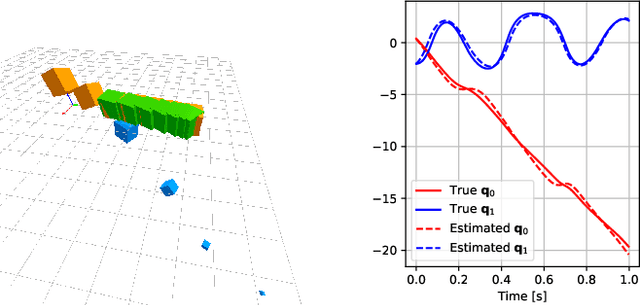
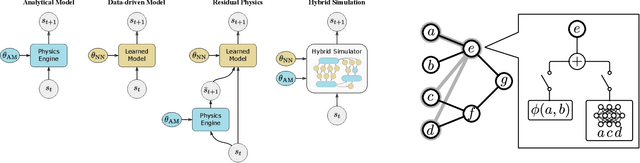

We present a differentiable simulation architecture for articulated rigid-body dynamics that enables the augmentation of analytical models with neural networks at any point of the computation. Through gradient-based optimization, identification of the simulation parameters and network weights is performed efficiently in preliminary experiments on a real-world dataset and in sim2sim transfer applications, while poor local optima are overcome through a random search approach.
Learning Agile Robotic Locomotion Skills by Imitating Animals
Apr 02, 2020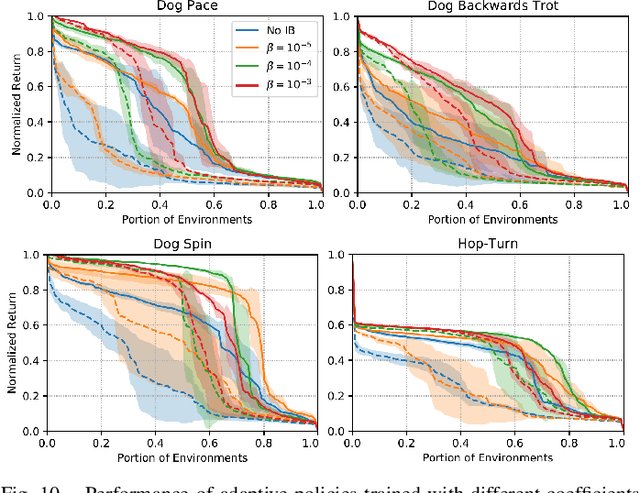
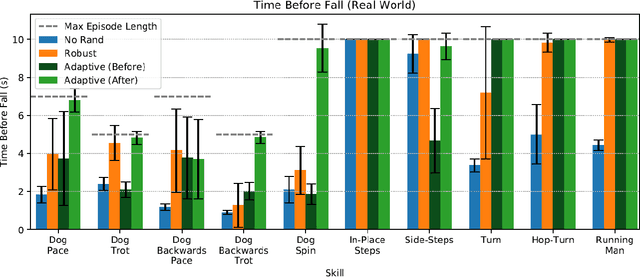
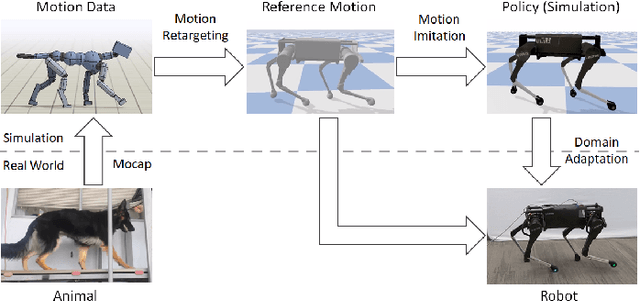
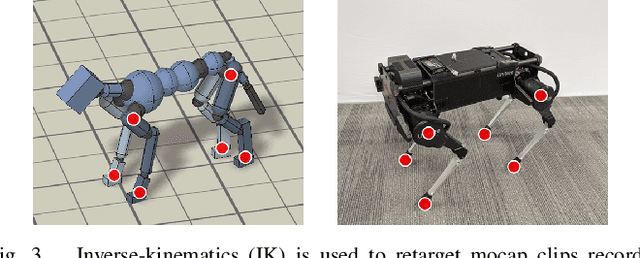
Reproducing the diverse and agile locomotion skills of animals has been a longstanding challenge in robotics. While manually-designed controllers have been able to emulate many complex behaviors, building such controllers involves a time-consuming and difficult development process, often requiring substantial expertise of the nuances of each skill. Reinforcement learning provides an appealing alternative for automating the manual effort involved in the development of controllers. However, designing learning objectives that elicit the desired behaviors from an agent can also require a great deal of skill-specific expertise. In this work, we present an imitation learning system that enables legged robots to learn agile locomotion skills by imitating real-world animals. We show that by leveraging reference motion data, a single learning-based approach is able to automatically synthesize controllers for a diverse repertoire behaviors for legged robots. By incorporating sample efficient domain adaptation techniques into the training process, our system is able to learn adaptive policies in simulation that can then be quickly adapted for real-world deployment. To demonstrate the effectiveness of our system, we train an 18-DoF quadruped robot to perform a variety of agile behaviors ranging from different locomotion gaits to dynamic hops and turns.
Policies Modulating Trajectory Generators
Oct 07, 2019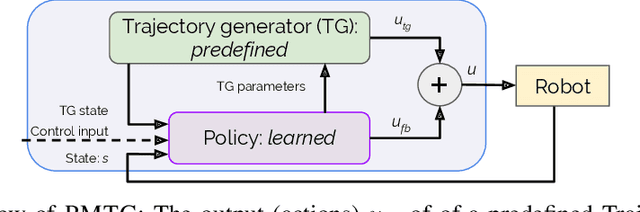
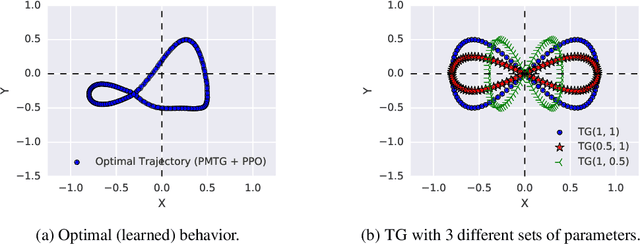
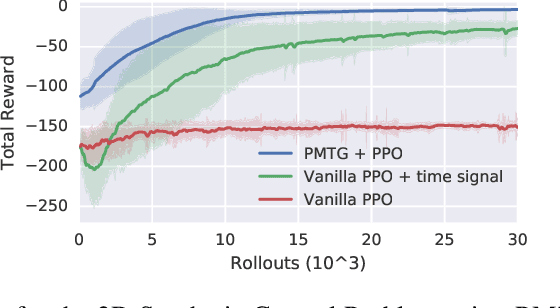
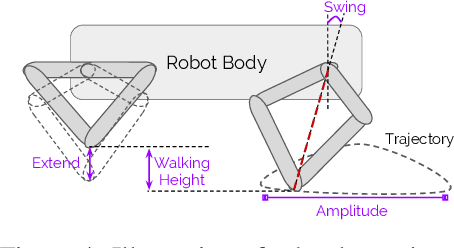
We propose an architecture for learning complex controllable behaviors by having simple Policies Modulate Trajectory Generators (PMTG), a powerful combination that can provide both memory and prior knowledge to the controller. The result is a flexible architecture that is applicable to a class of problems with periodic motion for which one has an insight into the class of trajectories that might lead to a desired behavior. We illustrate the basics of our architecture using a synthetic control problem, then go on to learn speed-controlled locomotion for a quadrupedal robot by using Deep Reinforcement Learning and Evolutionary Strategies. We demonstrate that a simple linear policy, when paired with a parametric Trajectory Generator for quadrupedal gaits, can induce walking behaviors with controllable speed from 4-dimensional IMU observations alone, and can be learned in under 1000 rollouts. We also transfer these policies to a real robot and show locomotion with controllable forward velocity.
Learning Fast Adaptation with Meta Strategy Optimization
Sep 28, 2019
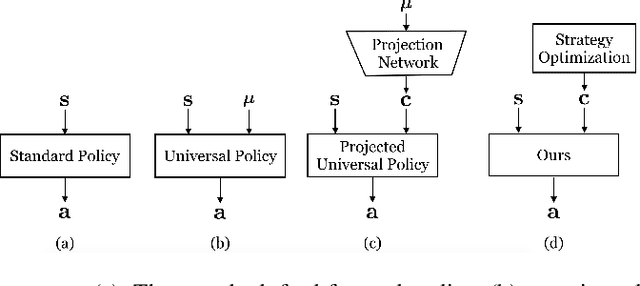
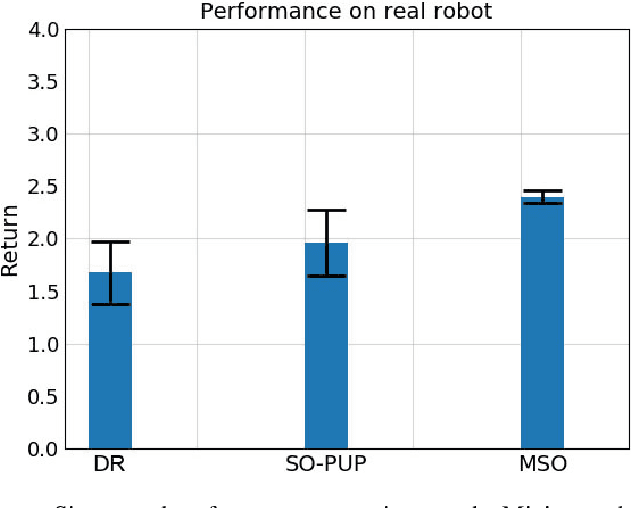
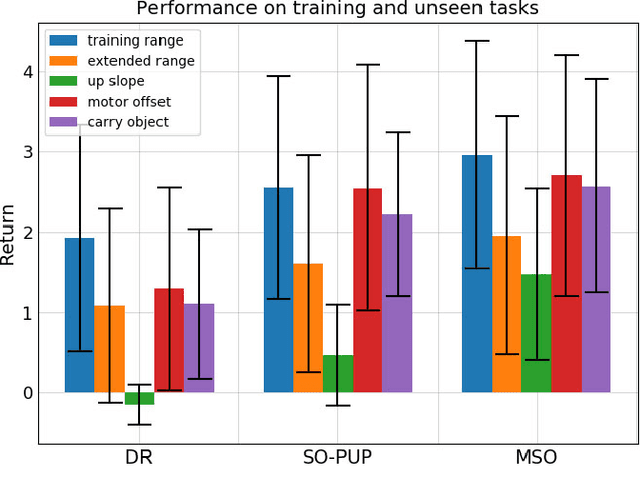
The ability to walk in new scenarios is a key milestone on the path toward real-world applications of legged robots. In this work, we introduce Meta Strategy Optimization, a meta-learning algorithm for training policies with latent variable inputs that can quickly adapt to new scenarios with a handful of trials in the target environment. The key idea behind MSO is to expose the same adaptation process, Strategy Optimization (SO), to both the training and testing phases. This allows MSO to effectively learn locomotion skills as well as a latent space that is suitable for fast adaptation. We evaluate our method on a real quadruped robot and demonstrate successful adaptation in various scenarios, including sim-to-real transfer, walking with a weakened motor, or climbing up a slope. Furthermore, we quantitatively analyze the generalization capability of the trained policy in simulated environments. Both real and simulated experiments show that our method outperforms previous methods in adaptation to novel tasks.
Optimizing Simulations with Noise-Tolerant Structured Exploration
May 20, 2018

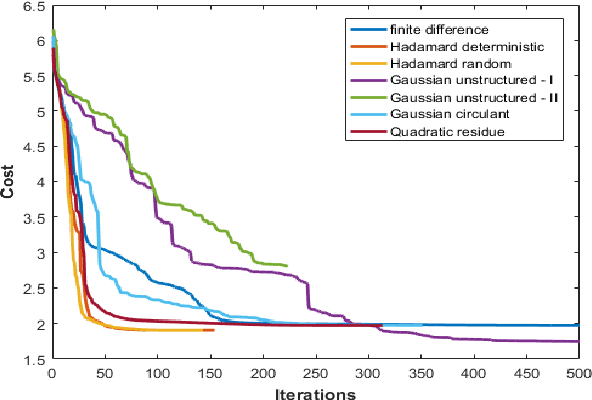
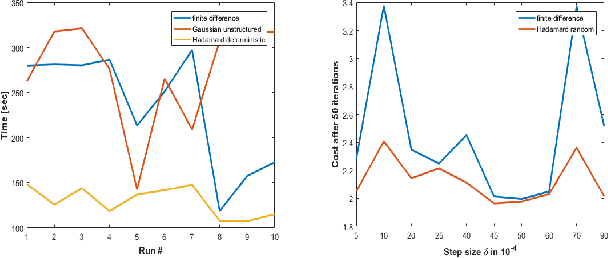
We propose a simple drop-in noise-tolerant replacement for the standard finite difference procedure used ubiquitously in blackbox optimization. In our approach, parameter perturbation directions are defined by a family of structured orthogonal matrices. We show that at the small cost of computing a Fast Walsh-Hadamard/Fourier Transform (FWHT/FFT), such structured finite differences consistently give higher quality approximation of gradients and Jacobians in comparison to vanilla approaches that use coordinate directions or random Gaussian perturbations. We find that trajectory optimizers like Iterative LQR and Differential Dynamic Programming require fewer iterations to solve several classic continuous control tasks when our methods are used to linearize noisy, blackbox dynamics instead of standard finite differences. By embedding structured exploration in a quasi-Newton optimizer (LBFGS), we are able to learn agile walking and turning policies for quadruped locomotion, that successfully transfer from simulation to actual hardware.We theoretically justify our methods via bounds on the quality of gradient reconstruction and provide a basis for applying them also to nonsmooth problems.
Sim-to-Real: Learning Agile Locomotion For Quadruped Robots
May 16, 2018

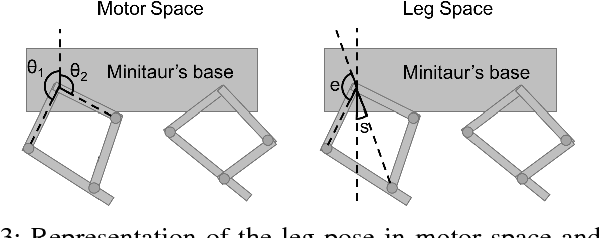
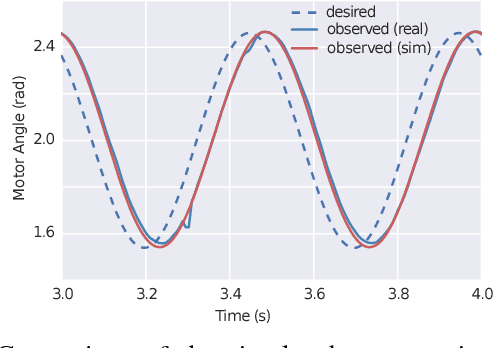
Designing agile locomotion for quadruped robots often requires extensive expertise and tedious manual tuning. In this paper, we present a system to automate this process by leveraging deep reinforcement learning techniques. Our system can learn quadruped locomotion from scratch using simple reward signals. In addition, users can provide an open loop reference to guide the learning process when more control over the learned gait is needed. The control policies are learned in a physics simulator and then deployed on real robots. In robotics, policies trained in simulation often do not transfer to the real world. We narrow this reality gap by improving the physics simulator and learning robust policies. We improve the simulation using system identification, developing an accurate actuator model and simulating latency. We learn robust controllers by randomizing the physical environments, adding perturbations and designing a compact observation space. We evaluate our system on two agile locomotion gaits: trotting and galloping. After learning in simulation, a quadruped robot can successfully perform both gaits in the real world.