 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Range-Equalizing Bias in Mean Opinion Score Ratings of Synthesized Speech
May 22, 2023Mean Opinion Score (MOS) is a popular measure for evaluating synthesized speech. However, the scores obtained in MOS tests are heavily dependent upon many contextual factors. One such factor is the overall range of quality of the samples presented in the test -- listeners tend to try to use the entire range of scoring options available to them regardless of this, a phenomenon which is known as range-equalizing bias. In this paper, we systematically investigate the effects of range-equalizing bias on MOS tests for synthesized speech by conducting a series of listening tests in which we progressively "zoom in" on a smaller number of systems in the higher-quality range. This allows us to better understand and quantify the effects of range-equalizing bias in MOS tests.
Improving Generalization Ability of Countermeasures for New Mismatch Scenario by Combining Multiple Advanced Regularization Terms
May 18, 2023The ability of countermeasure models to generalize from seen speech synthesis methods to unseen ones has been investigated in the ASVspoof challenge. However, a new mismatch scenario in which fake audio may be generated from real audio with unseen genres has not been studied thoroughly. To this end, we first use five different vocoders to create a new dataset called CN-Spoof based on the CN-Celeb1\&2 datasets. Then, we design two auxiliary objectives for regularization via meta-optimization and a genre alignment module, respectively, and combine them with the main anti-spoofing objective using learnable weights for multiple loss terms. The results on our cross-genre evaluation dataset for anti-spoofing show that the proposed method significantly improved the generalization ability of the countermeasures compared with the baseline system in the genre mismatch scenario.
Can Knowledge of End-to-End Text-to-Speech Models Improve Neural MIDI-to-Audio Synthesis Systems?
Nov 25, 2022



With the similarity between music and speech synthesis from symbolic input and the rapid development of text-to-speech (TTS) techniques, it is worthwhile to explore ways to improve the MIDI-to-audio performance by borrowing from TTS techniques. In this study, we analyze the shortcomings of a TTS-based MIDI-to-audio system and improve it in terms of feature computation, model selection, and training strategy, aiming to synthesize highly natural-sounding audio. Moreover, we conducted an extensive model evaluation through listening tests, pitch measurement, and spectrogram analysis. This work demonstrates not only synthesis of highly natural music but offers a thorough analytical approach and useful outcomes for the community. Our code and pre-trained models are open sourced at https://github.com/nii-yamagishilab/midi-to-audio.
The PartialSpoof Database and Countermeasures for the Detection of Short Generated Audio Segments Embedded in a Speech Utterance
Apr 28, 2022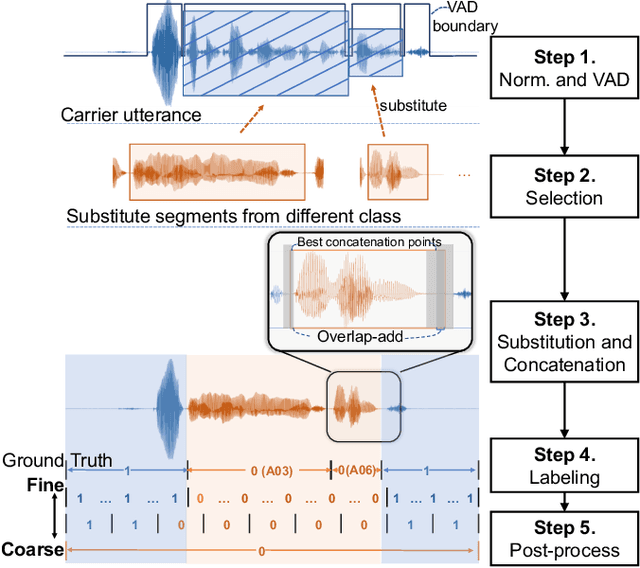
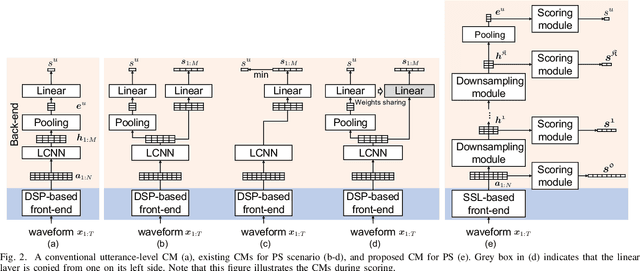
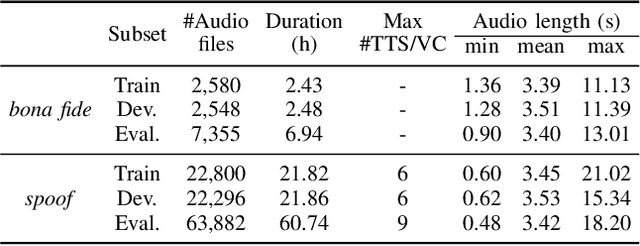
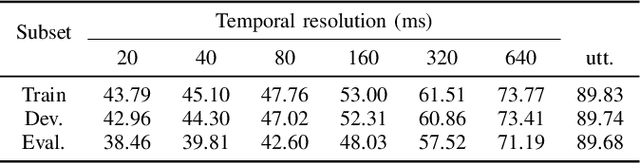
Automatic speaker verification is susceptible to various manipulations and spoofing, such as text-to-speech (TTS) synthesis, voice conversion (VC), replay, tampering, and so on. In this paper, we consider a new spoofing scenario called "Partial Spoof" (PS) in which synthesized or transformed audio segments are embedded into a bona fide speech utterance. While existing countermeasures (CMs) can detect fully spoofed utterances, there is a need for their adaptation or extension to the PS scenario to detect utterances in which only a part of the audio signal is generated and hence only a fraction of an utterance is spoofed. For improved explainability, such new CMs should ideally also be able to detect such short spoofed segments. Our previous study introduced the first version of a speech database suitable for training CMs for the PS scenario and showed that, although it is possible to train CMs to execute the two types of detection described above, there is much room for improvement. In this paper we propose various improvements to construct a significantly more accurate CM that can detect short generated spoofed audio segments at finer temporal resolutions. First, we introduce newly proposed self-supervised pre-trained models as enhanced feature extractors. Second, we extend the PartialSpoof database by adding segment labels for various temporal resolutions, ranging from 20 ms to 640 ms. Third, we propose a new CM and training strategies that enable the simultaneous use of the utterance-level and segment-level labels at different temporal resolutions. We also show that the proposed CM is capable of detecting spoofing at the utterance level with low error rates, not only in the PS scenario but also in a related logical access (LA) scenario. The equal error rates of utterance-level detection on the PartialSpoof and the ASVspoof 2019 LA database were 0.47% and 0.59%, respectively.
The VoiceMOS Challenge 2022
Mar 28, 2022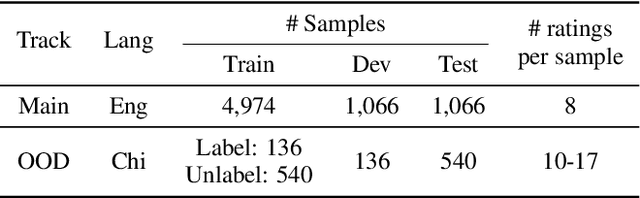
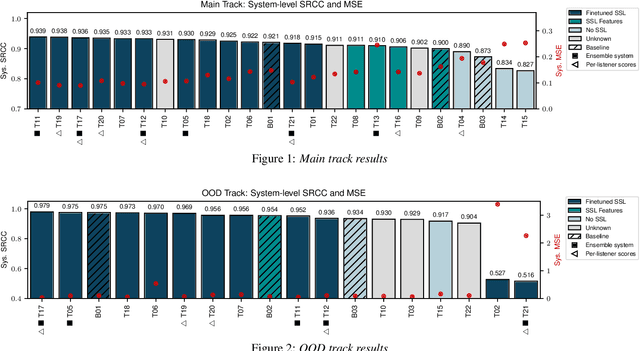
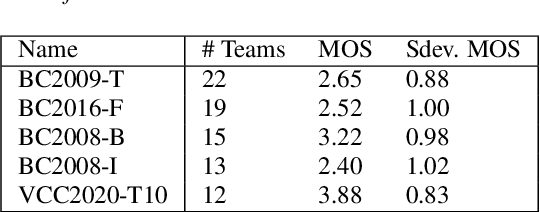
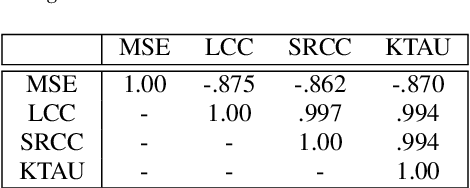
We present the first edition of the VoiceMOS Challenge, a scientific event that aims to promote the study of automatic prediction of the mean opinion score (MOS) of synthetic speech. This challenge drew 22 participating teams from academia and industry who tried a variety of approaches to tackle the problem of predicting human ratings of synthesized speech. The listening test data for the main track of the challenge consisted of samples from 187 different text-to-speech and voice conversion systems spanning over a decade of research, and the out-of-domain track consisted of data from more recent systems rated in a separate listening test. Results of the challenge show the effectiveness of fine-tuning self-supervised speech models for the MOS prediction task, as well as the difficulty of predicting MOS ratings for unseen speakers and listeners, and for unseen systems in the out-of-domain setting.
Language-Independent Speaker Anonymization Approach using Self-Supervised Pre-Trained Models
Mar 26, 2022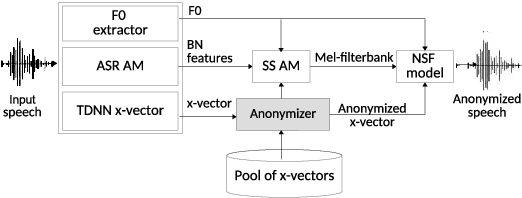
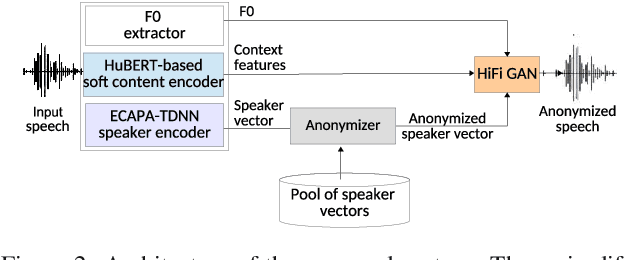

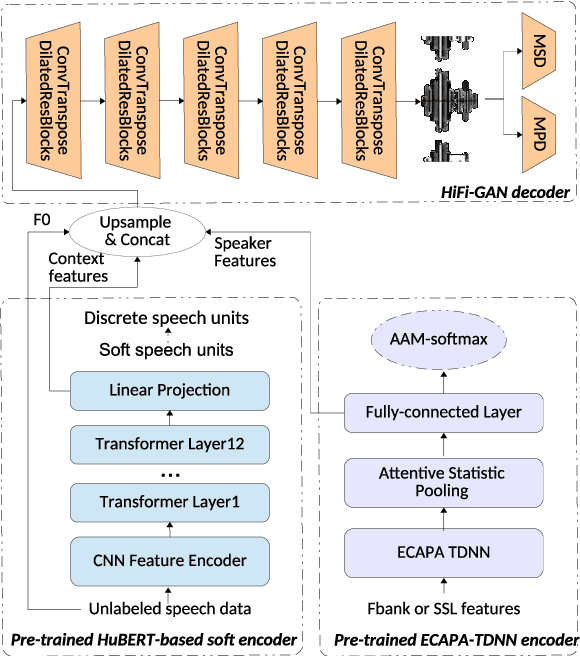
Speaker anonymization aims to protect the privacy of speakers while preserving spoken linguistic information from speech. Current mainstream neural network speaker anonymization systems are complicated, containing an F0 extractor, speaker encoder, automatic speech recognition acoustic model (ASR AM), speech synthesis acoustic model and speech waveform generation model. Moreover, as an ASR AM is language-dependent, trained on English data, it is hard to adapt it into another language. In this paper, we propose a simpler self-supervised learning (SSL)-based method for language-independent speaker anonymization without any explicit language-dependent model, which can be easily used for other languages. Extensive experiments were conducted on the VoicePrivacy Challenge 2020 datasets in English and AISHELL-3 datasets in Mandarin to demonstrate the effectiveness of our proposed SSL-based language-independent speaker anonymization method.
LDNet: Unified Listener Dependent Modeling in MOS Prediction for Synthetic Speech
Oct 18, 2021
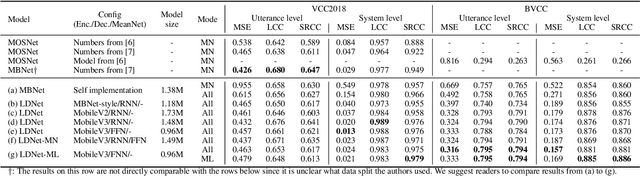
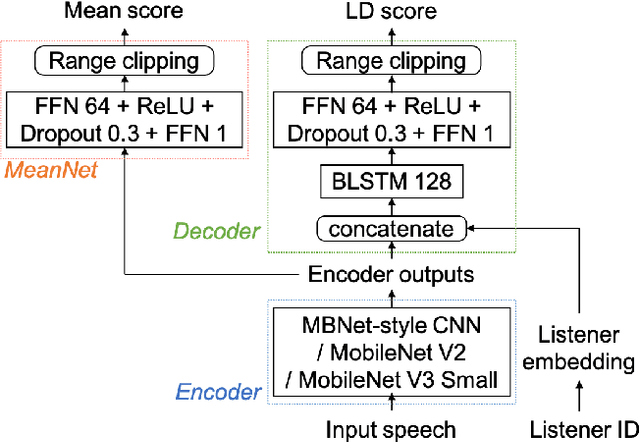
An effective approach to automatically predict the subjective rating for synthetic speech is to train on a listening test dataset with human-annotated scores. Although each speech sample in the dataset is rated by several listeners, most previous works only used the mean score as the training target. In this work, we present LDNet, a unified framework for mean opinion score (MOS) prediction that predicts the listener-wise perceived quality given the input speech and the listener identity. We reflect recent advances in LD modeling, including design choices of the model architecture, and propose two inference methods that provide more stable results and efficient computation. We conduct systematic experiments on the voice conversion challenge (VCC) 2018 benchmark and a newly collected large-scale MOS dataset, providing an in-depth analysis of the proposed framework. Results show that the mean listener inference method is a better way to utilize the mean scores, whose effectiveness is more obvious when having more ratings per sample.
Generalization Ability of MOS Prediction Networks
Oct 18, 2021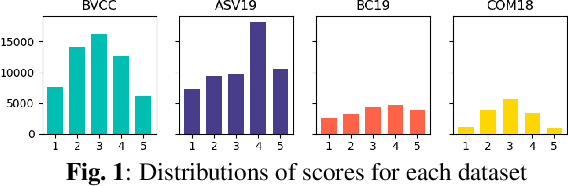
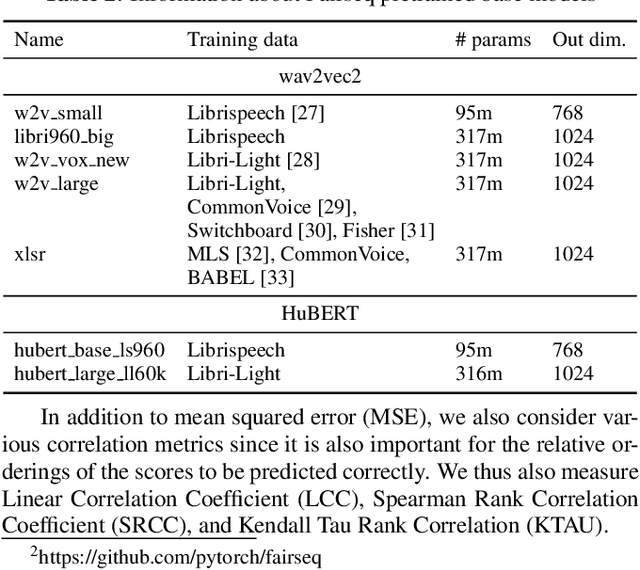
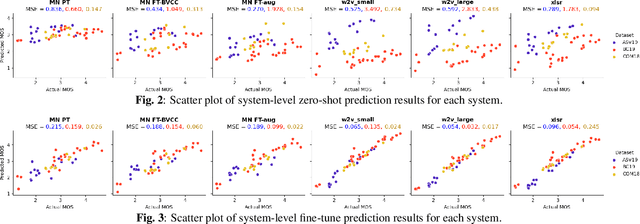
Automatic methods to predict listener opinions of synthesized speech remain elusive since listeners, systems being evaluated, characteristics of the speech, and even the instructions given and the rating scale all vary from test to test. While automatic predictors for metrics such as mean opinion score (MOS) can achieve high prediction accuracy on samples from the same test, they typically fail to generalize well to new listening test contexts. In this paper, using a variety of networks for MOS prediction including MOSNet and self-supervised speech models such as wav2vec2, we investigate their performance on data from different listening tests in both zero-shot and fine-tuned settings. We find that wav2vec2 models fine-tuned for MOS prediction have good generalization capability to out-of-domain data even for the most challenging case of utterance-level predictions in the zero-shot setting, and that fine-tuning to in-domain data can improve predictions. We also observe that unseen systems are especially challenging for MOS prediction models.
On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis
Oct 04, 2021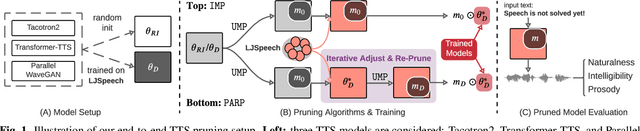
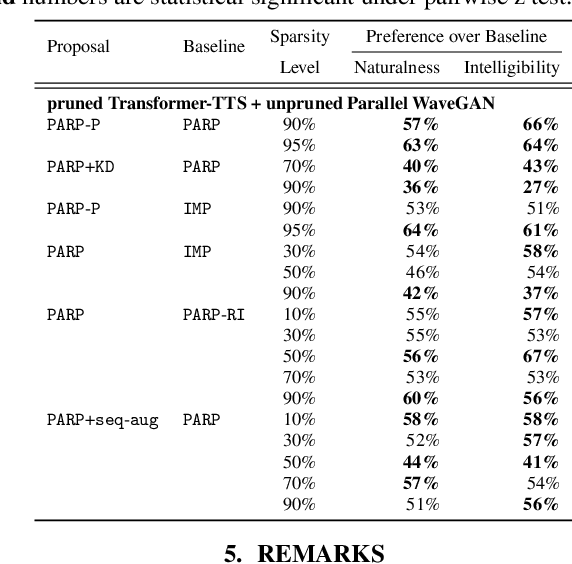
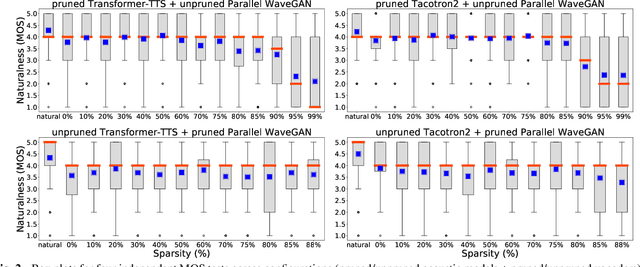
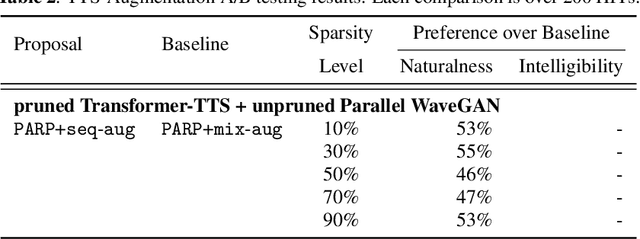
Are end-to-end text-to-speech (TTS) models over-parametrized? To what extent can these models be pruned, and what happens to their synthesis capabilities? This work serves as a starting point to explore pruning both spectrogram prediction networks and vocoders. We thoroughly investigate the tradeoffs between sparstiy and its subsequent effects on synthetic speech. Additionally, we explored several aspects of TTS pruning: amount of finetuning data versus sparsity, TTS-Augmentation to utilize unspoken text, and combining knowledge distillation and pruning. Our findings suggest that not only are end-to-end TTS models highly prunable, but also, perhaps surprisingly, pruned TTS models can produce synthetic speech with equal or higher naturalness and intelligibility, with similar prosody. All of our experiments are conducted on publicly available models, and findings in this work are backed by large-scale subjective tests and objective measures. Code and 200 pruned models are made available to facilitate future research on efficiency in TTS.
Multi-Task Learning in Utterance-Level and Segmental-Level Spoof Detection
Jul 29, 2021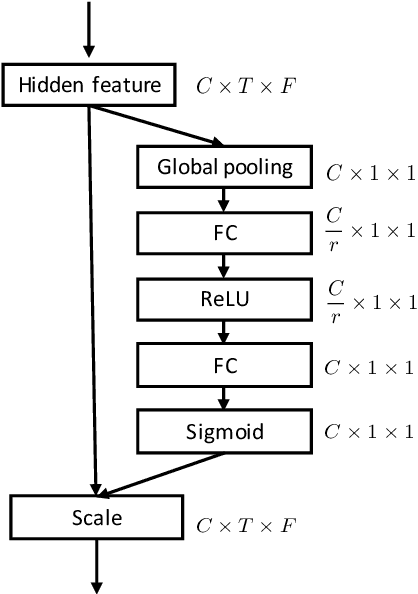
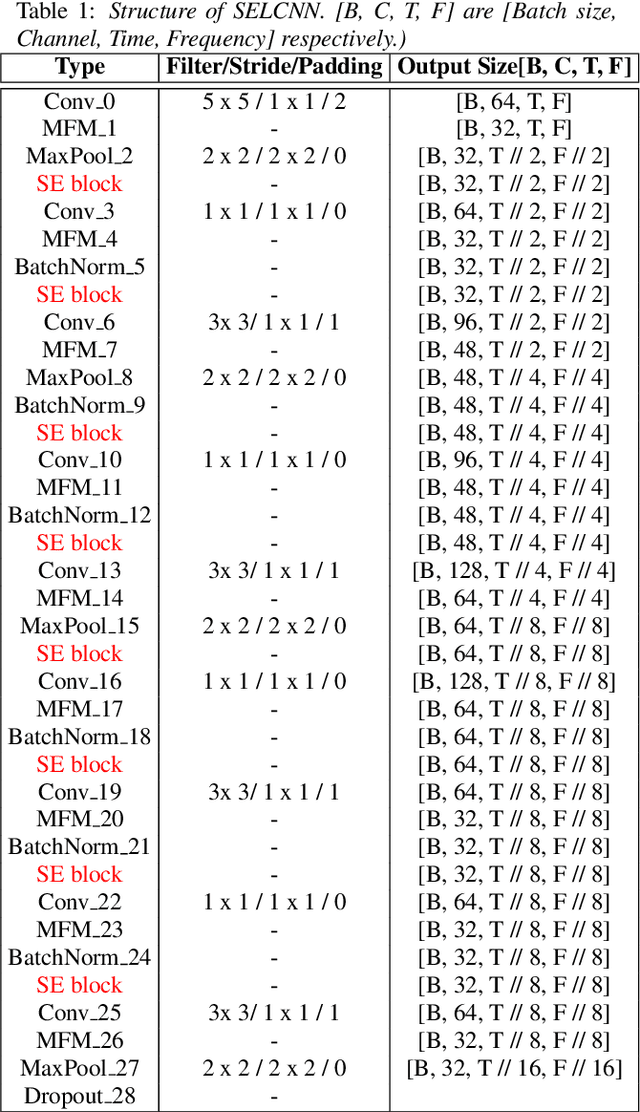

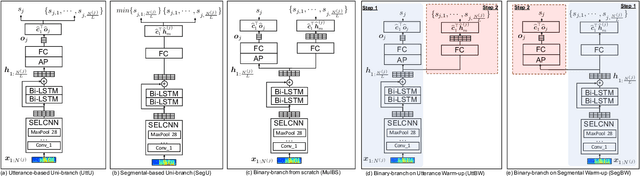
In this paper, we provide a series of multi-tasking benchmarks for simultaneously detecting spoofing at the segmental and utterance levels in the PartialSpoof database. First, we propose the SELCNN network, which inserts squeeze-and-excitation (SE) blocks into a light convolutional neural network (LCNN) to enhance the capacity of hidden feature selection. Then, we implement multi-task learning (MTL) frameworks with SELCNN followed by bidirectional long short-term memory (Bi-LSTM) as the basic model. We discuss MTL in PartialSpoof in terms of architecture (uni-branch/multi-branch) and training strategies (from-scratch/warm-up) step-by-step. Experiments show that the multi-task model performs better than single-task models. Also, in MTL, binary-branch architecture more adequately utilizes information from two levels than a uni-branch model. For the binary-branch architecture, fine-tuning a warm-up model works better than training from scratch. Models can handle both segment-level and utterance-level predictions simultaneously overall under binary-branch multi-task architecture. Furthermore, the multi-task model trained by fine-tuning a segmental warm-up model performs relatively better at both levels except on the evaluation set for segmental detection. Segmental detection should be explored further.