 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedNAR: Federated Optimization with Normalized Annealing Regularization
Oct 04, 2023



Weight decay is a standard technique to improve generalization performance in modern deep neural network optimization, and is also widely adopted in federated learning (FL) to prevent overfitting in local clients. In this paper, we first explore the choices of weight decay and identify that weight decay value appreciably influences the convergence of existing FL algorithms. While preventing overfitting is crucial, weight decay can introduce a different optimization goal towards the global objective, which is further amplified in FL due to multiple local updates and heterogeneous data distribution. To address this challenge, we develop {\it Federated optimization with Normalized Annealing Regularization} (FedNAR), a simple yet effective and versatile algorithmic plug-in that can be seamlessly integrated into any existing FL algorithms. Essentially, we regulate the magnitude of each update by performing co-clipping of the gradient and weight decay. We provide a comprehensive theoretical analysis of FedNAR's convergence rate and conduct extensive experiments on both vision and language datasets with different backbone federated optimization algorithms. Our experimental results consistently demonstrate that incorporating FedNAR into existing FL algorithms leads to accelerated convergence and heightened model accuracy. Moreover, FedNAR exhibits resilience in the face of various hyperparameter configurations. Specifically, FedNAR has the ability to self-adjust the weight decay when the initial specification is not optimal, while the accuracy of traditional FL algorithms would markedly decline. Our codes are released at \href{https://github.com/ljb121002/fednar}{https://github.com/ljb121002/fednar}.
Understanding Masked Autoencoders via Hierarchical Latent Variable Models
Jun 08, 2023Masked autoencoder (MAE), a simple and effective self-supervised learning framework based on the reconstruction of masked image regions, has recently achieved prominent success in a variety of vision tasks. Despite the emergence of intriguing empirical observations on MAE, a theoretically principled understanding is still lacking. In this work, we formally characterize and justify existing empirical insights and provide theoretical guarantees of MAE. We formulate the underlying data-generating process as a hierarchical latent variable model and show that under reasonable assumptions, MAE provably identifies a set of latent variables in the hierarchical model, explaining why MAE can extract high-level information from pixels. Further, we show how key hyperparameters in MAE (the masking ratio and the patch size) determine which true latent variables to be recovered, therefore influencing the level of semantic information in the representation. Specifically, extremely large or small masking ratios inevitably lead to low-level representations. Our theory offers coherent explanations of existing empirical observations and provides insights for potential empirical improvements and fundamental limitations of the masking-reconstruction paradigm. We conduct extensive experiments to validate our theoretical insights.
Cuttlefish: Low-Rank Model Training without All the Tuning
May 05, 2023Recent research has shown that training low-rank neural networks can effectively reduce the total number of trainable parameters without sacrificing predictive accuracy, resulting in end-to-end speedups. However, low-rank model training necessitates adjusting several additional factorization hyperparameters, such as the rank of the factorization at each layer. In this paper, we tackle this challenge by introducing Cuttlefish, an automated low-rank training approach that eliminates the need for tuning factorization hyperparameters. Cuttlefish leverages the observation that after a few epochs of full-rank training, the stable rank (i.e., an approximation of the true rank) of each layer stabilizes at a constant value. Cuttlefish switches from full-rank to low-rank training once the stable ranks of all layers have converged, setting the dimension of each factorization to its corresponding stable rank. Our results show that Cuttlefish generates models up to 5.6 times smaller than full-rank models, and attains up to a 1.2 times faster end-to-end training process while preserving comparable accuracy. Moreover, Cuttlefish outperforms state-of-the-art low-rank model training methods and other prominent baselines. The source code for our implementation can be found at: https://github.com/hwang595/Cuttlefish.
Federated Learning as Variational Inference: A Scalable Expectation Propagation Approach
Feb 08, 2023



The canonical formulation of federated learning treats it as a distributed optimization problem where the model parameters are optimized against a global loss function that decomposes across client loss functions. A recent alternative formulation instead treats federated learning as a distributed inference problem, where the goal is to infer a global posterior from partitioned client data (Al-Shedivat et al., 2021). This paper extends the inference view and describes a variational inference formulation of federated learning where the goal is to find a global variational posterior that well-approximates the true posterior. This naturally motivates an expectation propagation approach to federated learning (FedEP), where approximations to the global posterior are iteratively refined through probabilistic message-passing between the central server and the clients. We conduct an extensive empirical study across various algorithmic considerations and describe practical strategies for scaling up expectation propagation to the modern federated setting. We apply FedEP on standard federated learning benchmarks and find that it outperforms strong baselines in terms of both convergence speed and accuracy.
Does compressing activations help model parallel training?
Jan 06, 2023Large-scale Transformer models are known for their exceptional performance in a range of tasks, but training them can be difficult due to the requirement for communication-intensive model parallelism. One way to improve training speed is to compress the message size in communication. Previous approaches have primarily focused on compressing gradients in a data parallelism setting, but compression in a model-parallel setting is an understudied area. We have discovered that model parallelism has fundamentally different characteristics than data parallelism. In this work, we present the first empirical study on the effectiveness of compression methods for model parallelism. We implement and evaluate three common classes of compression algorithms - pruning-based, learning-based, and quantization-based - using a popular Transformer training framework. We evaluate these methods across more than 160 settings and 8 popular datasets, taking into account different hyperparameters, hardware, and both fine-tuning and pre-training stages. We also provide analysis when the model is scaled up. Finally, we provide insights for future development of model parallelism compression algorithms.
Expeditious Saliency-guided Mix-up through Random Gradient Thresholding
Dec 17, 2022



Mix-up training approaches have proven to be effective in improving the generalization ability of Deep Neural Networks. Over the years, the research community expands mix-up methods into two directions, with extensive efforts to improve saliency-guided procedures but minimal focus on the arbitrary path, leaving the randomization domain unexplored. In this paper, inspired by the superior qualities of each direction over one another, we introduce a novel method that lies at the junction of the two routes. By combining the best elements of randomness and saliency utilization, our method balances speed, simplicity, and accuracy. We name our method R-Mix following the concept of "Random Mix-up". We demonstrate its effectiveness in generalization, weakly supervised object localization, calibration, and robustness to adversarial attacks. Finally, in order to address the question of whether there exists a better decision protocol, we train a Reinforcement Learning agent that decides the mix-up policies based on the classifier's performance, reducing dependency on human-designed objectives and hyperparameter tuning. Extensive experiments further show that the agent is capable of performing at the cutting-edge level, laying the foundation for a fully automatic mix-up. Our code is released at [https://github.com/minhlong94/Random-Mixup].
On Optimizing the Communication of Model Parallelism
Nov 10, 2022

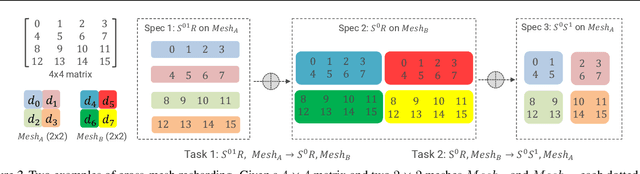
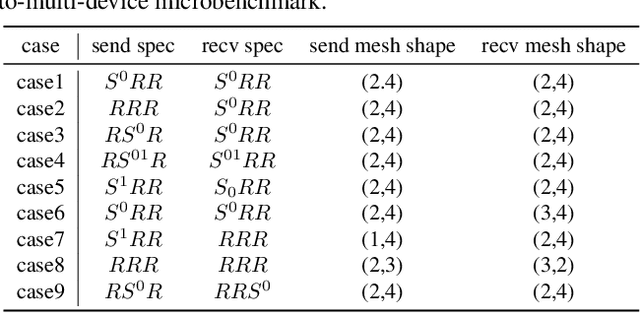
We study a novel and important communication pattern in large-scale model-parallel deep learning (DL), which we call cross-mesh resharding. This pattern emerges when the two paradigms of model parallelism - intra-operator and inter-operator parallelism - are combined to support large models on large clusters. In cross-mesh resharding, a sharded tensor needs to be sent from a source device mesh to a destination device mesh, on which the tensor may be distributed with the same or different layouts. We formalize this as a many-to-many multicast communication problem, and show that existing approaches either are sub-optimal or do not generalize to different network topologies or tensor layouts, which result from different model architectures and parallelism strategies. We then propose two contributions to address cross-mesh resharding: an efficient broadcast-based communication system, and an "overlapping-friendly" pipeline schedule. On microbenchmarks, our overall system outperforms existing ones by up to 10x across various tensor and mesh layouts. On end-to-end training of two large models, GPT-3 and U-Transformer, we improve throughput by 10% and 50%, respectively.
MPCFormer: fast, performant and private Transformer inference with MPC
Nov 02, 2022Enabling private inference is crucial for many cloud inference services that are based on Transformer models. However, existing private inference solutions for Transformers can increase the inference latency by more than 60x or significantly compromise the quality of inference results. In this paper, we design the framework MPCFORMER using secure multi-party computation (MPC) and Knowledge Distillation (KD). It can be used in tandem with many specifically designed MPC-friendly approximations and trained Transformer models. MPCFORMER significantly speeds up Transformer model inference in MPC settings while achieving similar ML performance to the input model. We evaluate MPCFORMER with various settings in MPC. On the IMDb dataset, we achieve similar performance to BERTBASE, while being 5.3x faster. On the GLUE benchmark, we achieve 97% performance of BERTBASE with a 2.2x speedup. We show that MPCFORMER remains effective with different trained Transformer weights such as ROBERTABASE and larger models including BERTLarge. In particular, we achieve similar performance to BERTLARGE, while being 5.93x faster on the IMDb dataset.
ASDOT: Any-Shot Data-to-Text Generation with Pretrained Language Models
Oct 11, 2022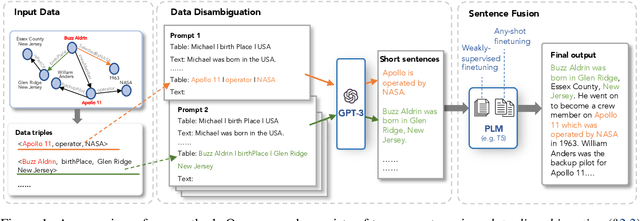
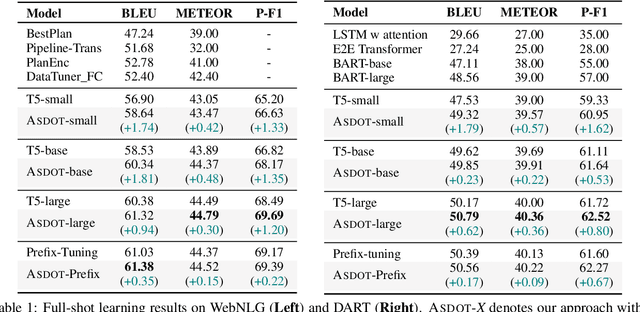
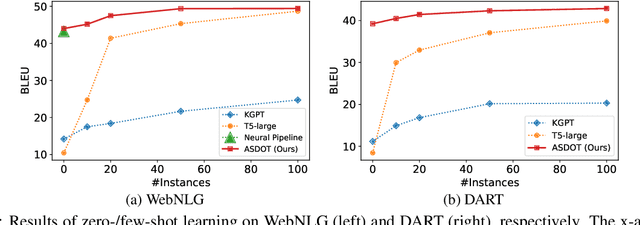
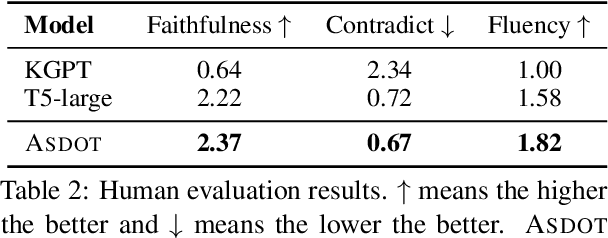
Data-to-text generation is challenging due to the great variety of the input data in terms of domains (e.g., finance vs sports) or schemata (e.g., diverse predicates). Recent end-to-end neural methods thus require substantial training examples to learn to disambiguate and describe the data. Yet, real-world data-to-text problems often suffer from various data-scarce issues: one may have access to only a handful of or no training examples, and/or have to rely on examples in a different domain or schema. To fill this gap, we propose Any-Shot Data-to-Text (ASDOT), a new approach flexibly applicable to diverse settings by making efficient use of any given (or no) examples. ASDOT consists of two steps, data disambiguation and sentence fusion, both of which are amenable to be solved with off-the-shelf pretrained language models (LMs) with optional finetuning. In the data disambiguation stage, we employ the prompted GPT-3 model to understand possibly ambiguous triples from the input data and convert each into a short sentence with reduced ambiguity. The sentence fusion stage then uses an LM like T5 to fuse all the resulting sentences into a coherent paragraph as the final description. We evaluate extensively on various datasets in different scenarios, including the zero-/few-/full-shot settings, and generalization to unseen predicates and out-of-domain data. Experimental results show that ASDOT consistently achieves significant improvement over baselines, e.g., a 30.81 BLEU gain on the DART dataset under the zero-shot setting.
Meta-DETR: Image-Level Few-Shot Detection with Inter-Class Correlation Exploitation
Jul 30, 2022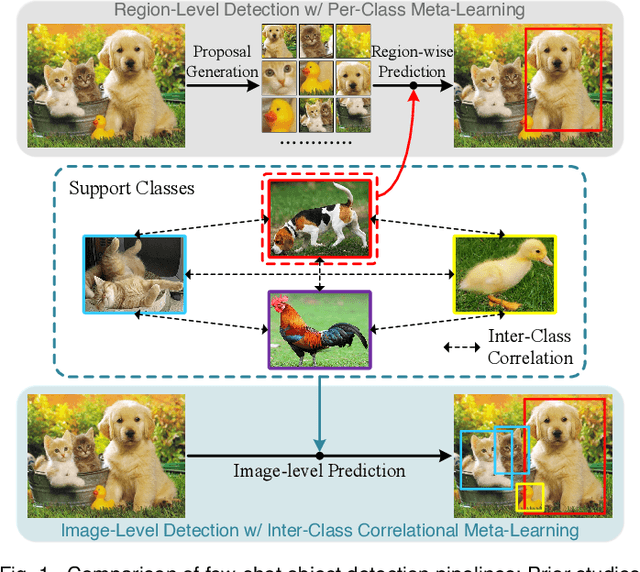
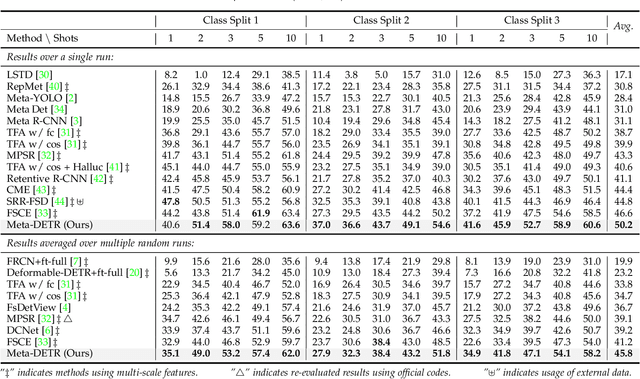
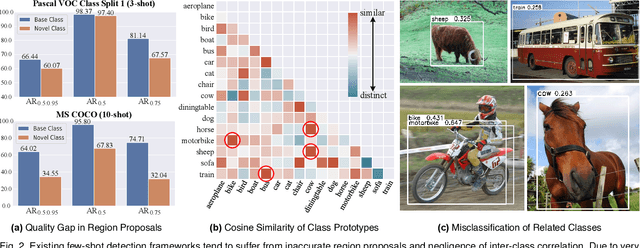
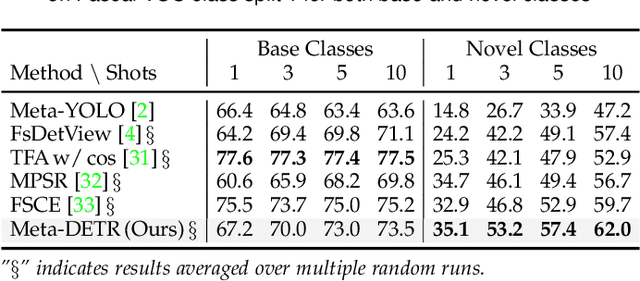
Few-shot object detection has been extensively investigated by incorporating meta-learning into region-based detection frameworks. Despite its success, the said paradigm is still constrained by several factors, such as (i) low-quality region proposals for novel classes and (ii) negligence of the inter-class correlation among different classes. Such limitations hinder the generalization of base-class knowledge for the detection of novel-class objects. In this work, we design Meta-DETR, which (i) is the first image-level few-shot detector, and (ii) introduces a novel inter-class correlational meta-learning strategy to capture and leverage the correlation among different classes for robust and accurate few-shot object detection. Meta-DETR works entirely at image level without any region proposals, which circumvents the constraint of inaccurate proposals in prevalent few-shot detection frameworks. In addition, the introduced correlational meta-learning enables Meta-DETR to simultaneously attend to multiple support classes within a single feedforward, which allows to capture the inter-class correlation among different classes, thus significantly reducing the misclassification over similar classes and enhancing knowledge generalization to novel classes. Experiments over multiple few-shot object detection benchmarks show that the proposed Meta-DETR outperforms state-of-the-art methods by large margins. The implementation codes are available at https://github.com/ZhangGongjie/Meta-DETR.