 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Transformer for All Time Series: Representing and Training with Time-Dependent Heterogeneous Tabular Data
Feb 13, 2023There is a recent growing interest in applying Deep Learning techniques to tabular data, in order to replicate the success of other Artificial Intelligence areas in this structured domain. Specifically interesting is the case in which tabular data have a time dependence, such as, for instance financial transactions. However, the heterogeneity of the tabular values, in which categorical elements are mixed with numerical items, makes this adaptation difficult. In this paper we propose a Transformer architecture to represent heterogeneous time-dependent tabular data, in which numerical features are represented using a set of frequency functions and the whole network is uniformly trained with a unique loss function.
Input Perturbation Reduces Exposure Bias in Diffusion Models
Jan 27, 2023Denoising Diffusion Probabilistic Models have shown an impressive generation quality, although their long sampling chain leads to high computational costs. In this paper, we observe that a long sampling chain also leads to an error accumulation phenomenon, which is similar to the \textbf{exposure bias} problem in autoregressive text generation. Specifically, we note that there is a discrepancy between training and testing, since the former is conditioned on the ground truth samples, while the latter is conditioned on the previously generated results. To alleviate this problem, we propose a very simple but effective training regularization, consisting in perturbing the ground truth samples to simulate the inference time prediction errors. We empirically show that the proposed input perturbation leads to a significant improvement of the sample quality while reducing both the training and the inference times. For instance, on CelebA 64$\times$64, we achieve a new state-of-the-art FID score of 1.27, while saving 37.5% of the training time.
Smooth image-to-image translations with latent space interpolations
Oct 03, 2022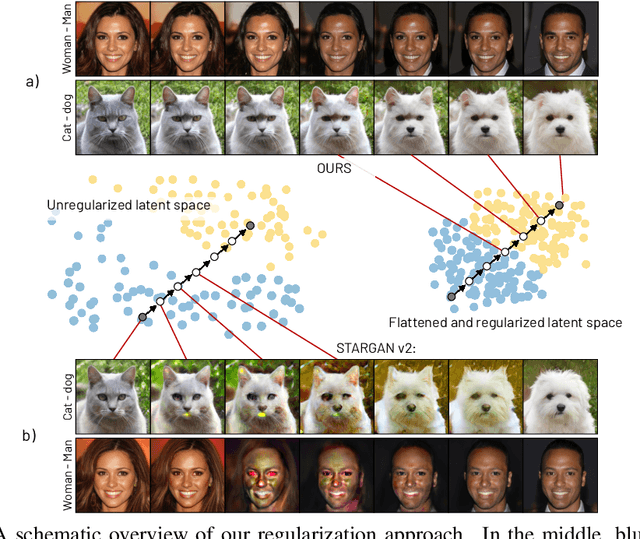
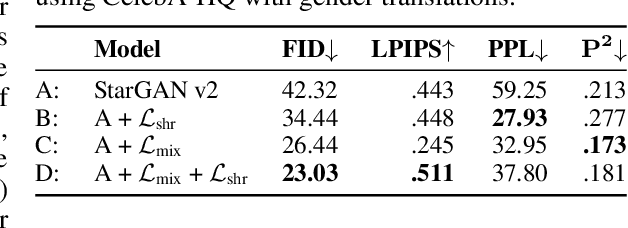
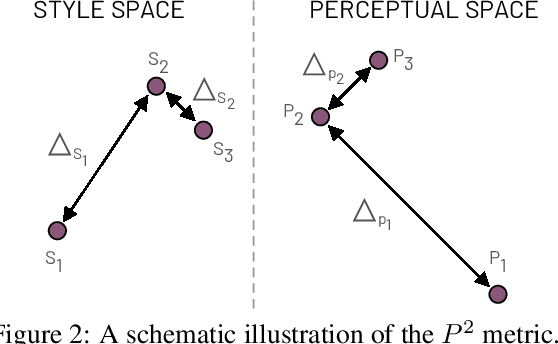
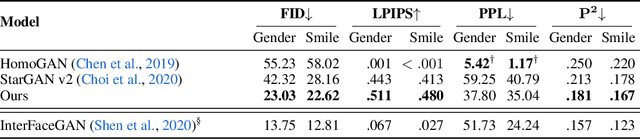
Multi-domain image-to-image (I2I) translations can transform a source image according to the style of a target domain. One important, desired characteristic of these transformations, is their graduality, which corresponds to a smooth change between the source and the target image when their respective latent-space representations are linearly interpolated. However, state-of-the-art methods usually perform poorly when evaluated using inter-domain interpolations, often producing abrupt changes in the appearance or non-realistic intermediate images. In this paper, we argue that one of the main reasons behind this problem is the lack of sufficient inter-domain training data and we propose two different regularization methods to alleviate this issue: a new shrinkage loss, which compacts the latent space, and a Mixup data-augmentation strategy, which flattens the style representations between domains. We also propose a new metric to quantitatively evaluate the degree of the interpolation smoothness, an aspect which is not sufficiently covered by the existing I2I translation metrics. Using both our proposed metric and standard evaluation protocols, we show that our regularization techniques can improve the state-of-the-art multi-domain I2I translations by a large margin. Our code will be made publicly available upon the acceptance of this article.
Unsupervised High-Resolution Portrait Gaze Correction and Animation
Jul 01, 2022



This paper proposes a gaze correction and animation method for high-resolution, unconstrained portrait images, which can be trained without the gaze angle and the head pose annotations. Common gaze-correction methods usually require annotating training data with precise gaze, and head pose information. Solving this problem using an unsupervised method remains an open problem, especially for high-resolution face images in the wild, which are not easy to annotate with gaze and head pose labels. To address this issue, we first create two new portrait datasets: CelebGaze and high-resolution CelebHQGaze. Second, we formulate the gaze correction task as an image inpainting problem, addressed using a Gaze Correction Module (GCM) and a Gaze Animation Module (GAM). Moreover, we propose an unsupervised training strategy, i.e., Synthesis-As-Training, to learn the correlation between the eye region features and the gaze angle. As a result, we can use the learned latent space for gaze animation with semantic interpolation in this space. Moreover, to alleviate both the memory and the computational costs in the training and the inference stage, we propose a Coarse-to-Fine Module (CFM) integrated with GCM and GAM. Extensive experiments validate the effectiveness of our method for both the gaze correction and the gaze animation tasks in both low and high-resolution face datasets in the wild and demonstrate the superiority of our method with respect to the state of the arts. Code is available at https://github.com/zhangqianhui/GazeAnimationV2
Spatial Entropy Regularization for Vision Transformers
Jun 09, 2022

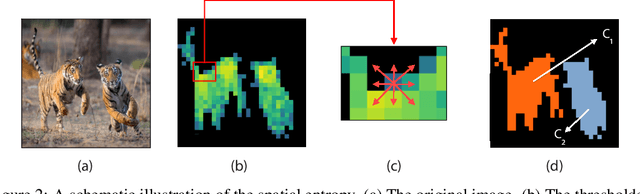
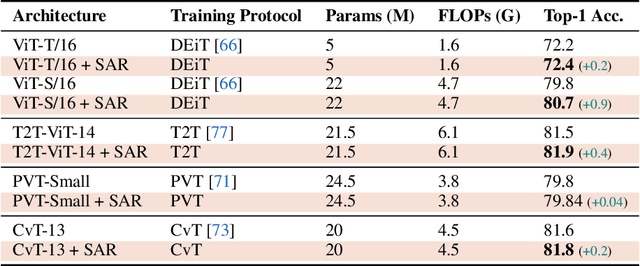
Recent work has shown that the attention maps of Vision Transformers (VTs), when trained with self-supervision, can contain a semantic segmentation structure which does not spontaneously emerge when training is supervised. In this paper, we explicitly encourage the emergence of this spatial clustering as a form of training regularization, this way including a self-supervised pretext task into the standard supervised learning. In more detail, we propose a VT regularization method based on a spatial formulation of the information entropy. By minimizing the proposed spatial entropy, we explicitly ask the VT to produce spatially ordered attention maps, this way including an object-based prior during training. Using extensive experiments, we show that the proposed regularization approach is beneficial with different training scenarios, datasets, downstream tasks and VT architectures. The code will be available upon acceptance.
Temporal Alignment for History Representation in Reinforcement Learning
Apr 07, 2022



Environments in Reinforcement Learning are usually only partially observable. To address this problem, a possible solution is to provide the agent with information about the past. However, providing complete observations of numerous steps can be excessive. Inspired by human memory, we propose to represent history with only important changes in the environment and, in our approach, to obtain automatically this representation using self-supervision. Our method (TempAl) aligns temporally-close frames, revealing a general, slowly varying state of the environment. This procedure is based on contrastive loss, which pulls embeddings of nearby observations to each other while pushing away other samples from the batch. It can be interpreted as a metric that captures the temporal relations of observations. We propose to combine both common instantaneous and our history representation and we evaluate TempAl on all available Atari games from the Arcade Learning Environment. TempAl surpasses the instantaneous-only baseline in 35 environments out of 49. The source code of the method and of all the experiments is available at https://github.com/htdt/tempal.
3D-Aware Semantic-Guided Generative Model for Human Synthesis
Dec 02, 2021
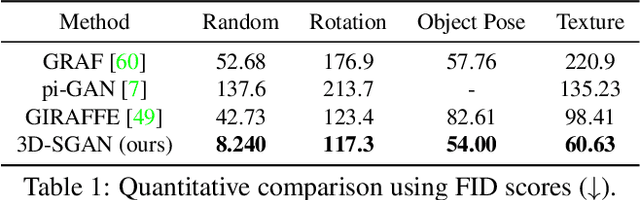
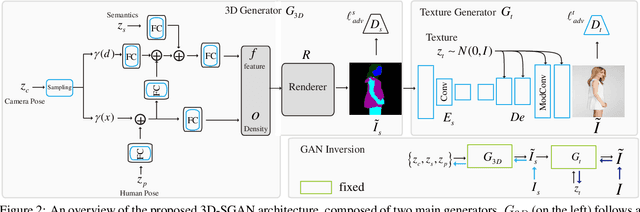
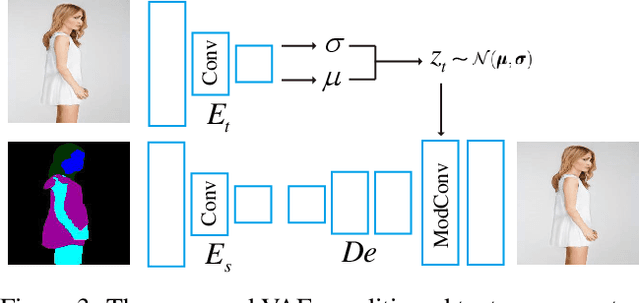
Generative Neural Radiance Field (GNeRF) models, which extract implicit 3D representations from 2D images, have recently been shown to produce realistic images representing rigid objects, such as human faces or cars. However, they usually struggle to generate high-quality images representing non-rigid objects, such as the human body, which is of a great interest for many computer graphics applications. This paper proposes a 3D-aware Semantic-Guided Generative Model (3D-SGAN) for human image synthesis, which integrates a GNeRF and a texture generator. The former learns an implicit 3D representation of the human body and outputs a set of 2D semantic segmentation masks. The latter transforms these semantic masks into a real image, adding a realistic texture to the human appearance. Without requiring additional 3D information, our model can learn 3D human representations with a photo-realistic controllable generation. Our experiments on the DeepFashion dataset show that 3D-SGAN significantly outperforms the most recent baselines.
A Unified Objective for Novel Class Discovery
Aug 20, 2021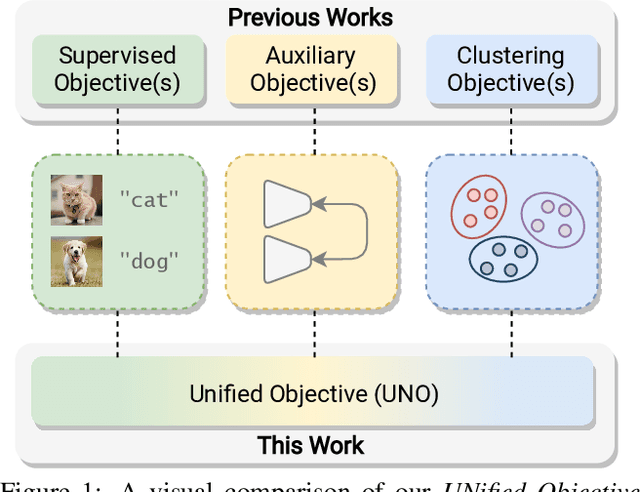
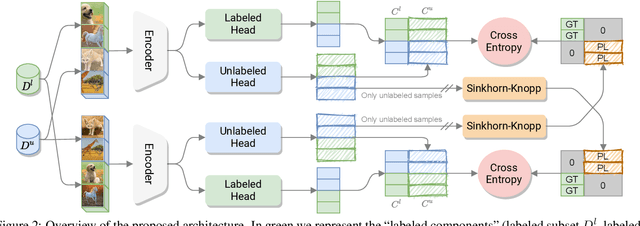
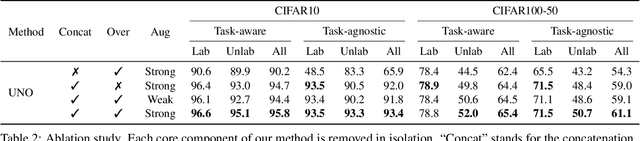
In this paper, we study the problem of Novel Class Discovery (NCD). NCD aims at inferring novel object categories in an unlabeled set by leveraging from prior knowledge of a labeled set containing different, but related classes. Existing approaches tackle this problem by considering multiple objective functions, usually involving specialized loss terms for the labeled and the unlabeled samples respectively, and often requiring auxiliary regularization terms. In this paper, we depart from this traditional scheme and introduce a UNified Objective function (UNO) for discovering novel classes, with the explicit purpose of favoring synergy between supervised and unsupervised learning. Using a multi-view self-labeling strategy, we generate pseudo-labels that can be treated homogeneously with ground truth labels. This leads to a single classification objective operating on both known and unknown classes. Despite its simplicity, UNO outperforms the state of the art by a significant margin on several benchmarks (~+10% on CIFAR-100 and +8% on ImageNet). The project page is available at: https://ncd-uno.github.io.
Smoothing the Disentangled Latent Style Space for Unsupervised Image-to-Image Translation
Jun 16, 2021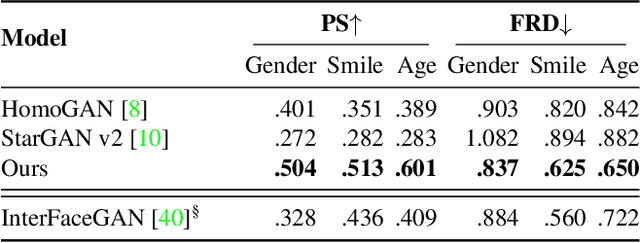
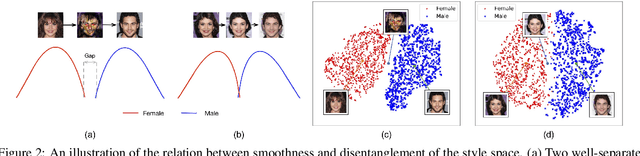
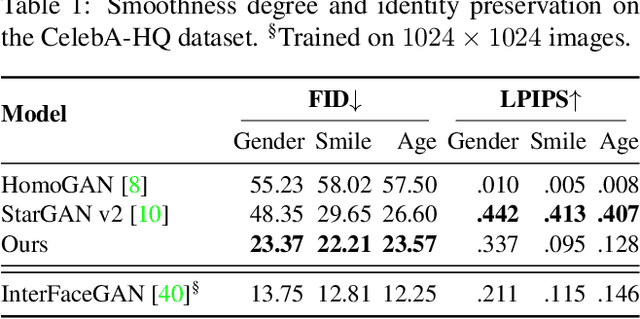

Image-to-Image (I2I) multi-domain translation models are usually evaluated also using the quality of their semantic interpolation results. However, state-of-the-art models frequently show abrupt changes in the image appearance during interpolation, and usually perform poorly in interpolations across domains. In this paper, we propose a new training protocol based on three specific losses which help a translation network to learn a smooth and disentangled latent style space in which: 1) Both intra- and inter-domain interpolations correspond to gradual changes in the generated images and 2) The content of the source image is better preserved during the translation. Moreover, we propose a novel evaluation metric to properly measure the smoothness of latent style space of I2I translation models. The proposed method can be plugged into existing translation approaches, and our extensive experiments on different datasets show that it can significantly boost the quality of the generated images and the graduality of the interpolations.
Efficient Training of Visual Transformers with Small-Size Datasets
Jun 07, 2021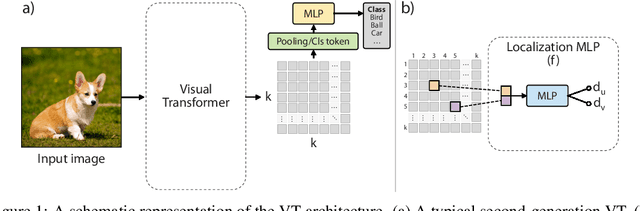
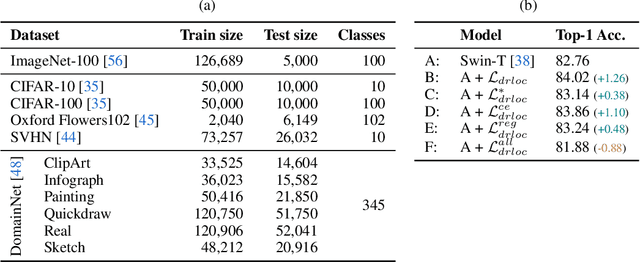
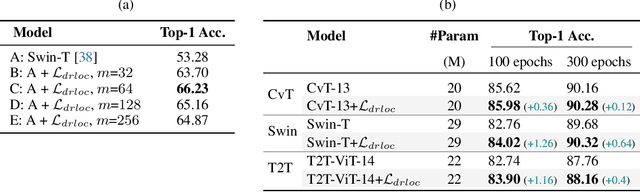

Visual Transformers (VTs) are emerging as an architectural paradigm alternative to Convolutional networks (CNNs). Differently from CNNs, VTs can capture global relations between image elements and they potentially have a larger representation capacity. However, the lack of the typical convolutional inductive bias makes these models more data-hungry than common CNNs. In fact, some local properties of the visual domain which are embedded in the CNN architectural design, in VTs should be learned from samples. In this paper, we empirically analyse different VTs, comparing their robustness in a small training-set regime, and we show that, despite having a comparable accuracy when trained on ImageNet, their performance on smaller datasets can be largely different. Moreover, we propose a self-supervised task which can extract additional information from images with only a negligible computational overhead. This task encourages the VTs to learn spatial relations within an image and makes the VT training much more robust when training data are scarce. Our task is used jointly with the standard (supervised) training and it does not depend on specific architectural choices, thus it can be easily plugged in the existing VTs. Using an extensive evaluation with different VTs and datasets, we show that our method can improve (sometimes dramatically) the final accuracy of the VTs. The code will be available upon acceptance.