 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Auxiliary or Adversarial Tasks Using Necessary Condition Analysis for Adversarial Multi-task Video Understanding
Aug 22, 2022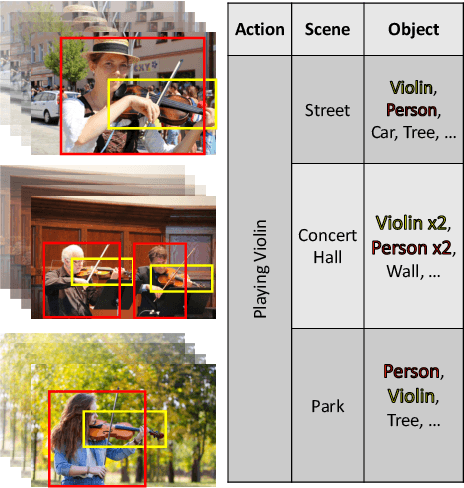
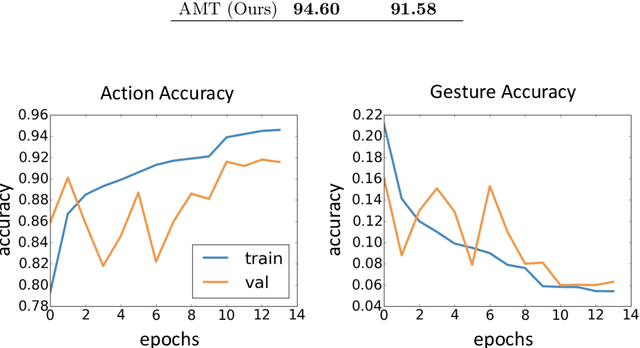
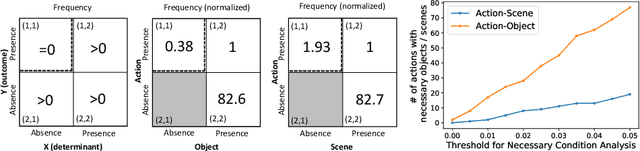
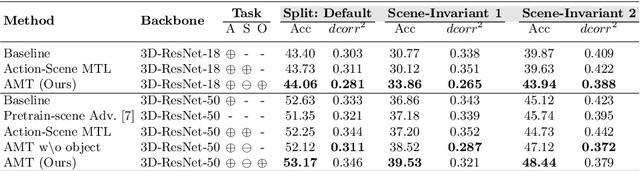
There has been an increasing interest in multi-task learning for video understanding in recent years. In this work, we propose a generalized notion of multi-task learning by incorporating both auxiliary tasks that the model should perform well on and adversarial tasks that the model should not perform well on. We employ Necessary Condition Analysis (NCA) as a data-driven approach for deciding what category these tasks should fall in. Our novel proposed framework, Adversarial Multi-Task Neural Networks (AMT), penalizes adversarial tasks, determined by NCA to be scene recognition in the Holistic Video Understanding (HVU) dataset, to improve action recognition. This upends the common assumption that the model should always be encouraged to do well on all tasks in multi-task learning. Simultaneously, AMT still retains all the benefits of multi-task learning as a generalization of existing methods and uses object recognition as an auxiliary task to aid action recognition. We introduce two challenging Scene-Invariant test splits of HVU, where the model is evaluated on action-scene co-occurrences not encountered in training. We show that our approach improves accuracy by ~3% and encourages the model to attend to action features instead of correlation-biasing scene features.
Multiple Instance Neuroimage Transformer
Aug 19, 2022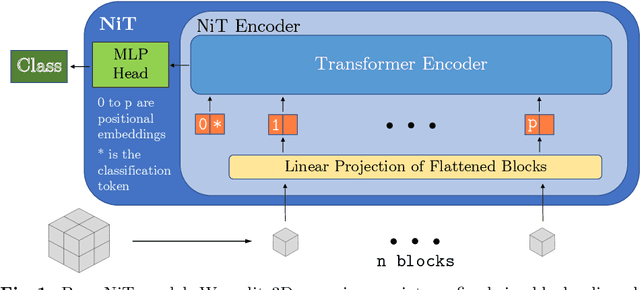
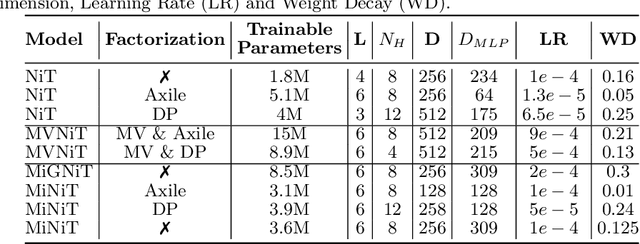
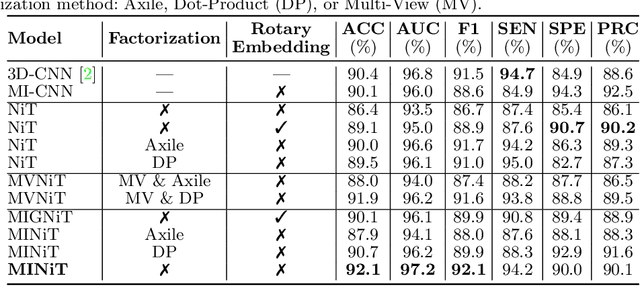
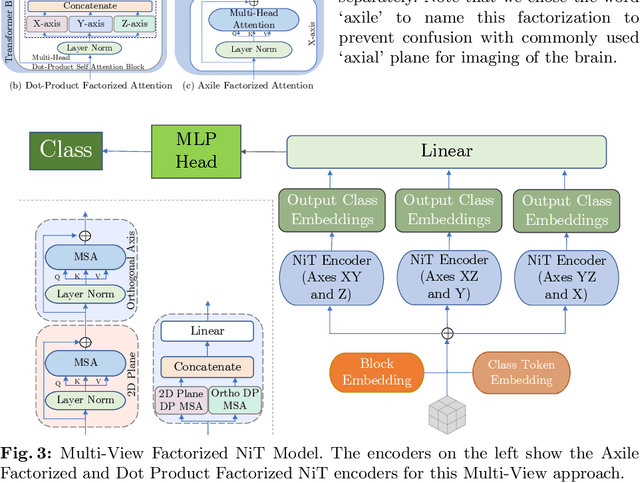
For the first time, we propose using a multiple instance learning based convolution-free transformer model, called Multiple Instance Neuroimage Transformer (MINiT), for the classification of T1weighted (T1w) MRIs. We first present several variants of transformer models adopted for neuroimages. These models extract non-overlapping 3D blocks from the input volume and perform multi-headed self-attention on a sequence of their linear projections. MINiT, on the other hand, treats each of the non-overlapping 3D blocks of the input MRI as its own instance, splitting it further into non-overlapping 3D patches, on which multi-headed self-attention is computed. As a proof-of-concept, we evaluate the efficacy of our model by training it to identify sex from T1w-MRIs of two public datasets: Adolescent Brain Cognitive Development (ABCD) and the National Consortium on Alcohol and Neurodevelopment in Adolescence (NCANDA). The learned attention maps highlight voxels contributing to identifying sex differences in brain morphometry. The code is available at https://github.com/singlaayush/MINIT.
TransDeepLab: Convolution-Free Transformer-based DeepLab v3+ for Medical Image Segmentation
Aug 01, 2022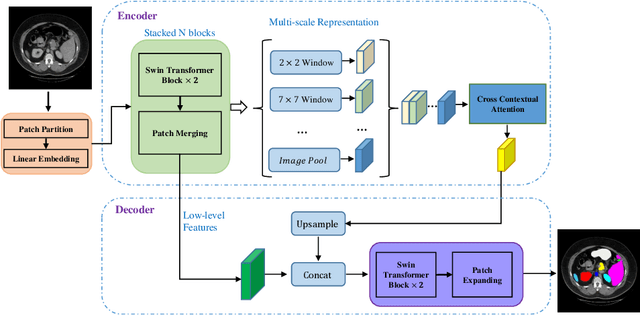
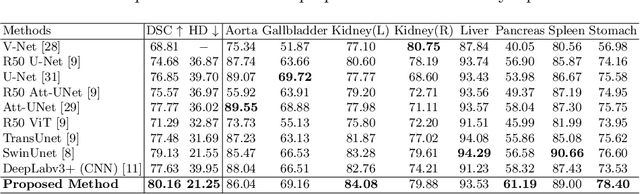
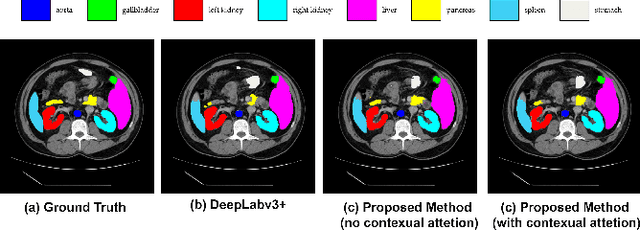
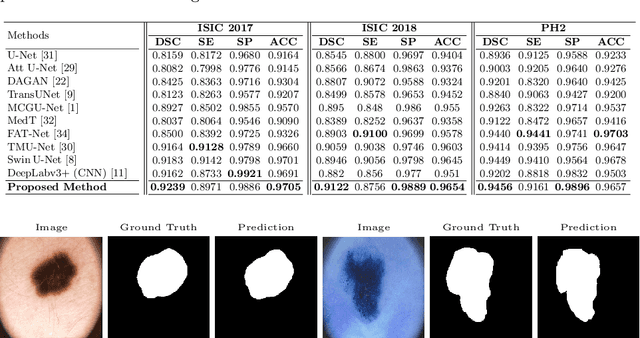
Convolutional neural networks (CNNs) have been the de facto standard in a diverse set of computer vision tasks for many years. Especially, deep neural networks based on seminal architectures such as U-shaped models with skip-connections or atrous convolution with pyramid pooling have been tailored to a wide range of medical image analysis tasks. The main advantage of such architectures is that they are prone to detaining versatile local features. However, as a general consensus, CNNs fail to capture long-range dependencies and spatial correlations due to the intrinsic property of confined receptive field size of convolution operations. Alternatively, Transformer, profiting from global information modelling that stems from the self-attention mechanism, has recently attained remarkable performance in natural language processing and computer vision. Nevertheless, previous studies prove that both local and global features are critical for a deep model in dense prediction, such as segmenting complicated structures with disparate shapes and configurations. To this end, this paper proposes TransDeepLab, a novel DeepLab-like pure Transformer for medical image segmentation. Specifically, we exploit hierarchical Swin-Transformer with shifted windows to extend the DeepLabv3 and model the Atrous Spatial Pyramid Pooling (ASPP) module. A thorough search of the relevant literature yielded that we are the first to model the seminal DeepLab model with a pure Transformer-based model. Extensive experiments on various medical image segmentation tasks verify that our approach performs superior or on par with most contemporary works on an amalgamation of Vision Transformer and CNN-based methods, along with a significant reduction of model complexity. The codes and trained models are publicly available at https://github.com/rezazad68/transdeeplab
Bridging the Gap between Deep Learning and Hypothesis-Driven Analysis via Permutation Testing
Jul 28, 2022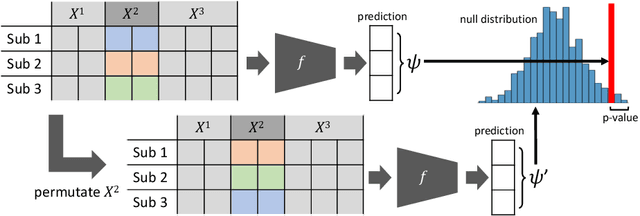
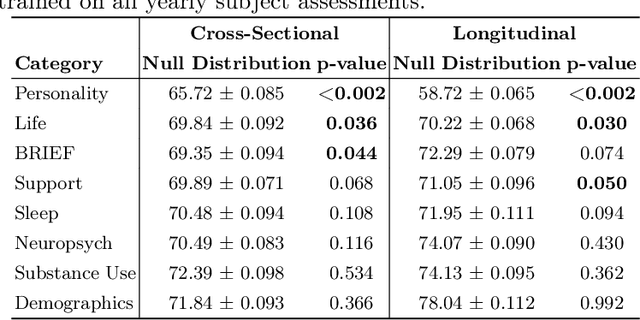

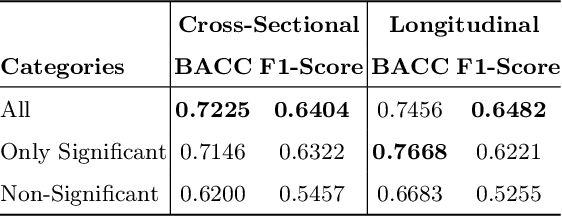
A fundamental approach in neuroscience research is to test hypotheses based on neuropsychological and behavioral measures, i.e., whether certain factors (e.g., related to life events) are associated with an outcome (e.g., depression). In recent years, deep learning has become a potential alternative approach for conducting such analyses by predicting an outcome from a collection of factors and identifying the most "informative" ones driving the prediction. However, this approach has had limited impact as its findings are not linked to statistical significance of factors supporting hypotheses. In this article, we proposed a flexible and scalable approach based on the concept of permutation testing that integrates hypothesis testing into the data-driven deep learning analysis. We apply our approach to the yearly self-reported assessments of 621 adolescent participants of the National Consortium of Alcohol and Neurodevelopment in Adolescence (NCANDA) to predict negative valence, a symptom of major depressive disorder according to the NIMH Research Domain Criteria (RDoC). Our method successfully identifies categories of risk factors that further explain the symptom.
A Penalty Approach for Normalizing Feature Distributions to Build Confounder-Free Models
Jul 11, 2022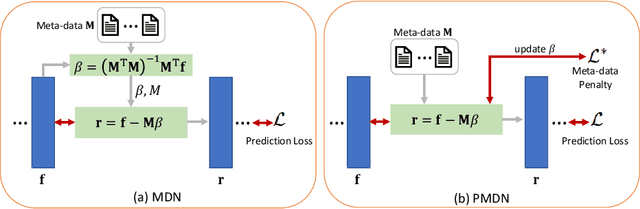

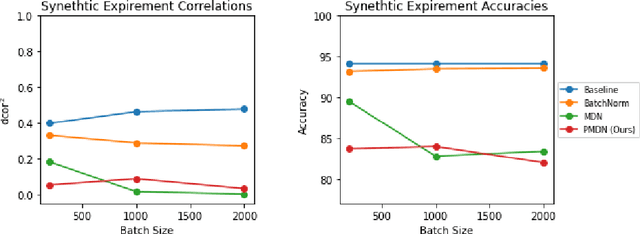
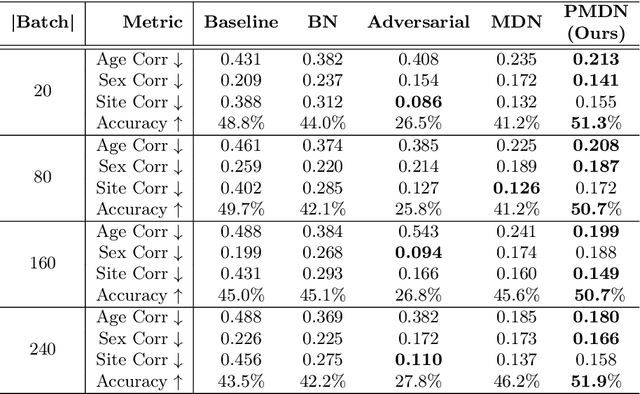
Translating machine learning algorithms into clinical applications requires addressing challenges related to interpretability, such as accounting for the effect of confounding variables (or metadata). Confounding variables affect the relationship between input training data and target outputs. When we train a model on such data, confounding variables will bias the distribution of the learned features. A recent promising solution, MetaData Normalization (MDN), estimates the linear relationship between the metadata and each feature based on a non-trainable closed-form solution. However, this estimation is confined by the sample size of a mini-batch and thereby may cause the approach to be unstable during training. In this paper, we extend the MDN method by applying a Penalty approach (referred to as PDMN). We cast the problem into a bi-level nested optimization problem. We then approximate this optimization problem using a penalty method so that the linear parameters within the MDN layer are trainable and learned on all samples. This enables PMDN to be plugged into any architectures, even those unfit to run batch-level operations, such as transformers and recurrent models. We show improvement in model accuracy and greater independence from confounders using PMDN over MDN in a synthetic experiment and a multi-label, multi-site dataset of magnetic resonance images (MRIs).
GaitForeMer: Self-Supervised Pre-Training of Transformers via Human Motion Forecasting for Few-Shot Gait Impairment Severity Estimation
Jun 30, 2022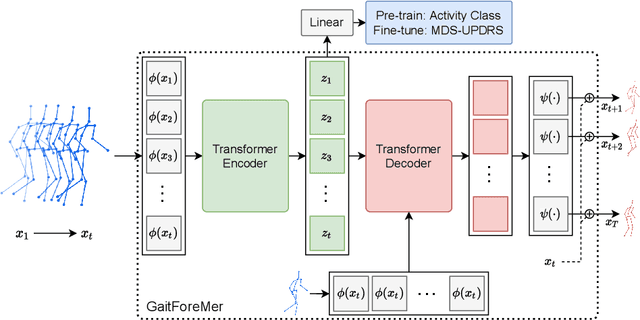


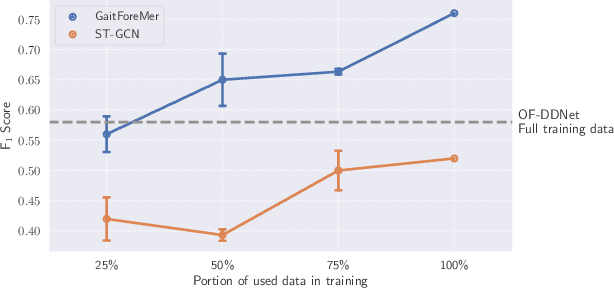
Parkinson's disease (PD) is a neurological disorder that has a variety of observable motor-related symptoms such as slow movement, tremor, muscular rigidity, and impaired posture. PD is typically diagnosed by evaluating the severity of motor impairments according to scoring systems such as the Movement Disorder Society Unified Parkinson's Disease Rating Scale (MDS-UPDRS). Automated severity prediction using video recordings of individuals provides a promising route for non-intrusive monitoring of motor impairments. However, the limited size of PD gait data hinders model ability and clinical potential. Because of this clinical data scarcity and inspired by the recent advances in self-supervised large-scale language models like GPT-3, we use human motion forecasting as an effective self-supervised pre-training task for the estimation of motor impairment severity. We introduce GaitForeMer, Gait Forecasting and impairment estimation transforMer, which is first pre-trained on public datasets to forecast gait movements and then applied to clinical data to predict MDS-UPDRS gait impairment severity. Our method outperforms previous approaches that rely solely on clinical data by a large margin, achieving an F1 score of 0.76, precision of 0.79, and recall of 0.75. Using GaitForeMer, we show how public human movement data repositories can assist clinical use cases through learning universal motion representations. The code is available at https://github.com/markendo/GaitForeMer .
Combining Counterfactuals With Shapley Values To Explain Image Models
Jun 14, 2022
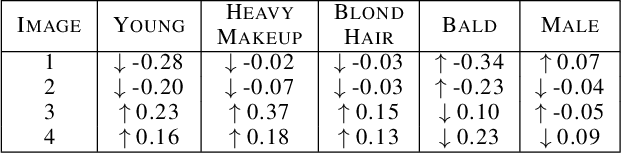
With the widespread use of sophisticated machine learning models in sensitive applications, understanding their decision-making has become an essential task. Models trained on tabular data have witnessed significant progress in explanations of their underlying decision making processes by virtue of having a small number of discrete features. However, applying these methods to high-dimensional inputs such as images is not a trivial task. Images are composed of pixels at an atomic level and do not carry any interpretability by themselves. In this work, we seek to use annotated high-level interpretable features of images to provide explanations. We leverage the Shapley value framework from Game Theory, which has garnered wide acceptance in general XAI problems. By developing a pipeline to generate counterfactuals and subsequently using it to estimate Shapley values, we obtain contrastive and interpretable explanations with strong axiomatic guarantees.
Explaining Image Classifiers Using Contrastive Counterfactuals in Generative Latent Spaces
Jun 10, 2022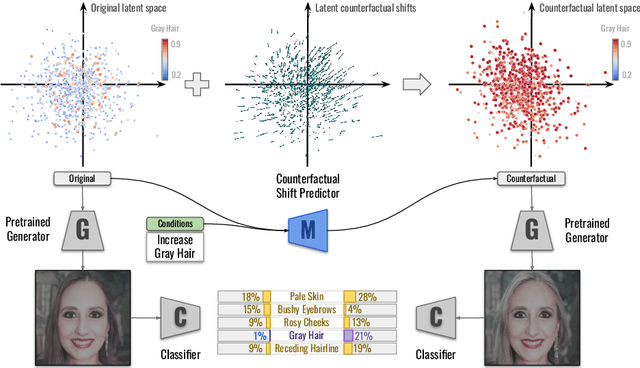


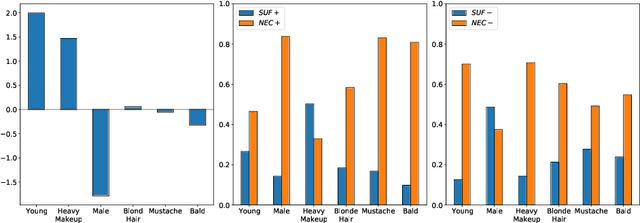
Despite their high accuracies, modern complex image classifiers cannot be trusted for sensitive tasks due to their unknown decision-making process and potential biases. Counterfactual explanations are very effective in providing transparency for these black-box algorithms. Nevertheless, generating counterfactuals that can have a consistent impact on classifier outputs and yet expose interpretable feature changes is a very challenging task. We introduce a novel method to generate causal and yet interpretable counterfactual explanations for image classifiers using pretrained generative models without any re-training or conditioning. The generative models in this technique are not bound to be trained on the same data as the target classifier. We use this framework to obtain contrastive and causal sufficiency and necessity scores as global explanations for black-box classifiers. On the task of face attribute classification, we show how different attributes influence the classifier output by providing both causal and contrastive feature attributions, and the corresponding counterfactual images.
PrivHAR: Recognizing Human Actions From Privacy-preserving Lens
Jun 08, 2022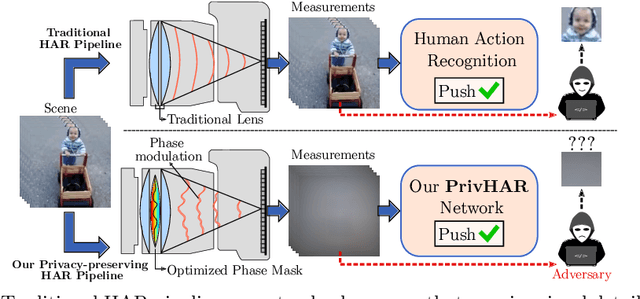
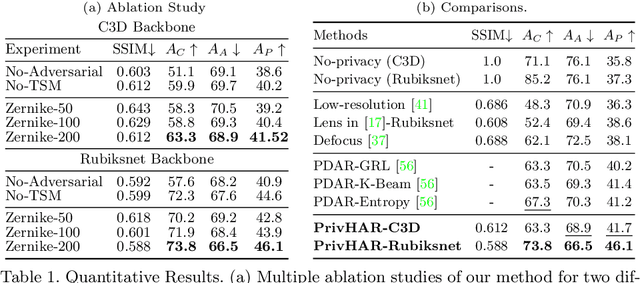
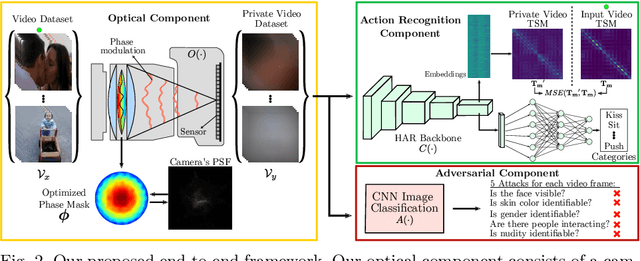
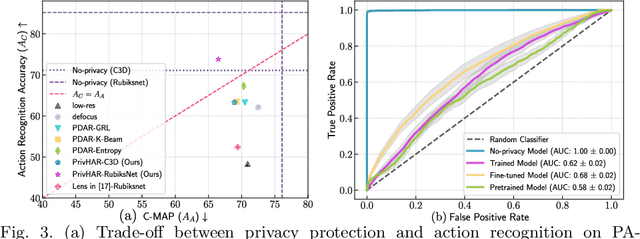
The accelerated use of digital cameras prompts an increasing concern about privacy and security, particularly in applications such as action recognition. In this paper, we propose an optimizing framework to provide robust visual privacy protection along the human action recognition pipeline. Our framework parameterizes the camera lens to successfully degrade the quality of the videos to inhibit privacy attributes and protect against adversarial attacks while maintaining relevant features for activity recognition. We validate our approach with extensive simulations and hardware experiments.
Affective Medical Estimation and Decision Making via Visualized Learning and Deep Learning
May 09, 2022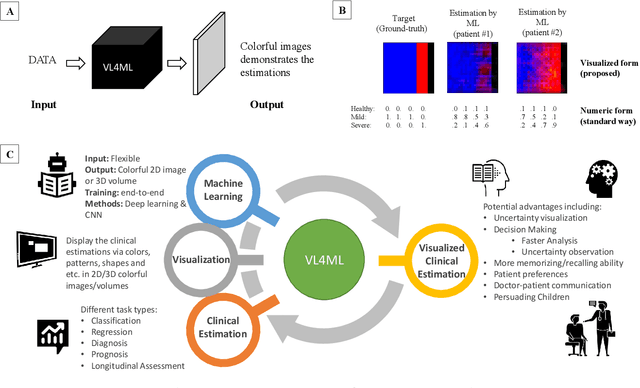
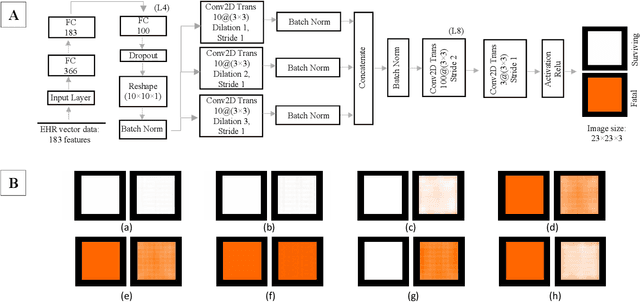
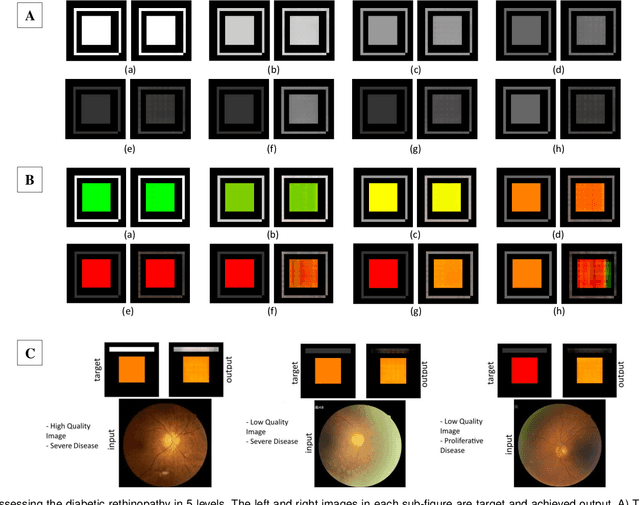
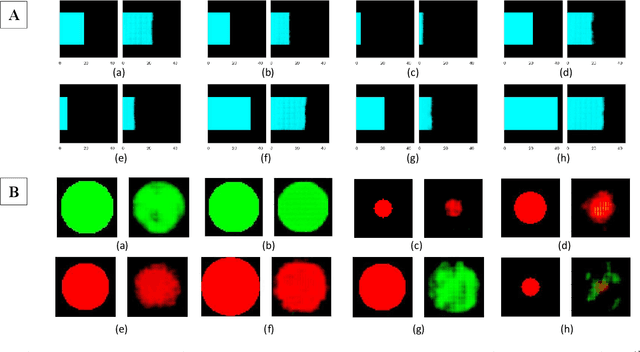
With the advent of sophisticated machine learning (ML) techniques and the promising results they yield, especially in medical applications, where they have been investigated for different tasks to enhance the decision-making process. Since visualization is such an effective tool for human comprehension, memorization, and judgment, we have presented a first-of-its-kind estimation approach we refer to as Visualized Learning for Machine Learning (VL4ML) that not only can serve to assist physicians and clinicians in making reasoned medical decisions, but it also allows to appreciate the uncertainty visualization, which could raise incertitude in making the appropriate classification or prediction. For the proof of concept, and to demonstrate the generalized nature of this visualized estimation approach, five different case studies are examined for different types of tasks including classification, regression, and longitudinal prediction. A survey analysis with more than 100 individuals is also conducted to assess users' feedback on this visualized estimation method. The experiments and the survey demonstrate the practical merits of the VL4ML that include: (1) appreciating visually clinical/medical estimations; (2) getting closer to the patients' preferences; (3) improving doctor-patient communication, and (4) visualizing the uncertainty introduced through the black box effect of the deployed ML algorithm. All the source codes are shared via a GitHub repository.